操作系统:共享内存通信(Shared Memory Systems)
目录
什么是共享内存通信?
共享内存的核心机制是怎样的?
共享内存通信是如何“发生”的?
🔐 为什么系统默认要禁止这种行为?
什么是生产者-消费者问题?
如何用共享内存解决生产者-消费者问题?
为什么需要同步?
共享内存 + 同步 的经典解决方案结构:
两种缓冲区模型(Two Kinds of Buffers)
Unbounded Buffer(无界缓冲区)
Bounded Buffer(有界缓冲区)
什么是共享内存通信?
共享内存通信是一种允许多个进程通过访问一块 共享内存区域 来通信的机制。
它属于进程间通信(IPC)的一种核心方式。
关于IPC的介绍可以参考:操作系统:进程间通信( Interprocess Communication,简称 IPC)-CSDN博客
共享内存的核心机制是怎样的?
默认情况下,操作系统做了什么?
在大多数现代操作系统中,每个进程都有自己的地址空间,这个空间是相互隔离的,目的是为了:
-
保证进程间互不干扰;
-
防止进程“偷窥”或篡改别人的数据;
-
提高系统安全性和稳定性。
📌 这意味着 —— 一个进程是无法直接访问另一个进程的内存的。
那共享内存是怎么做到“打破这个隔离”的?
通过 显式申请 + 系统许可,操作系统允许多个进程 “共享” 一块内存区域。
整个流程如下 :
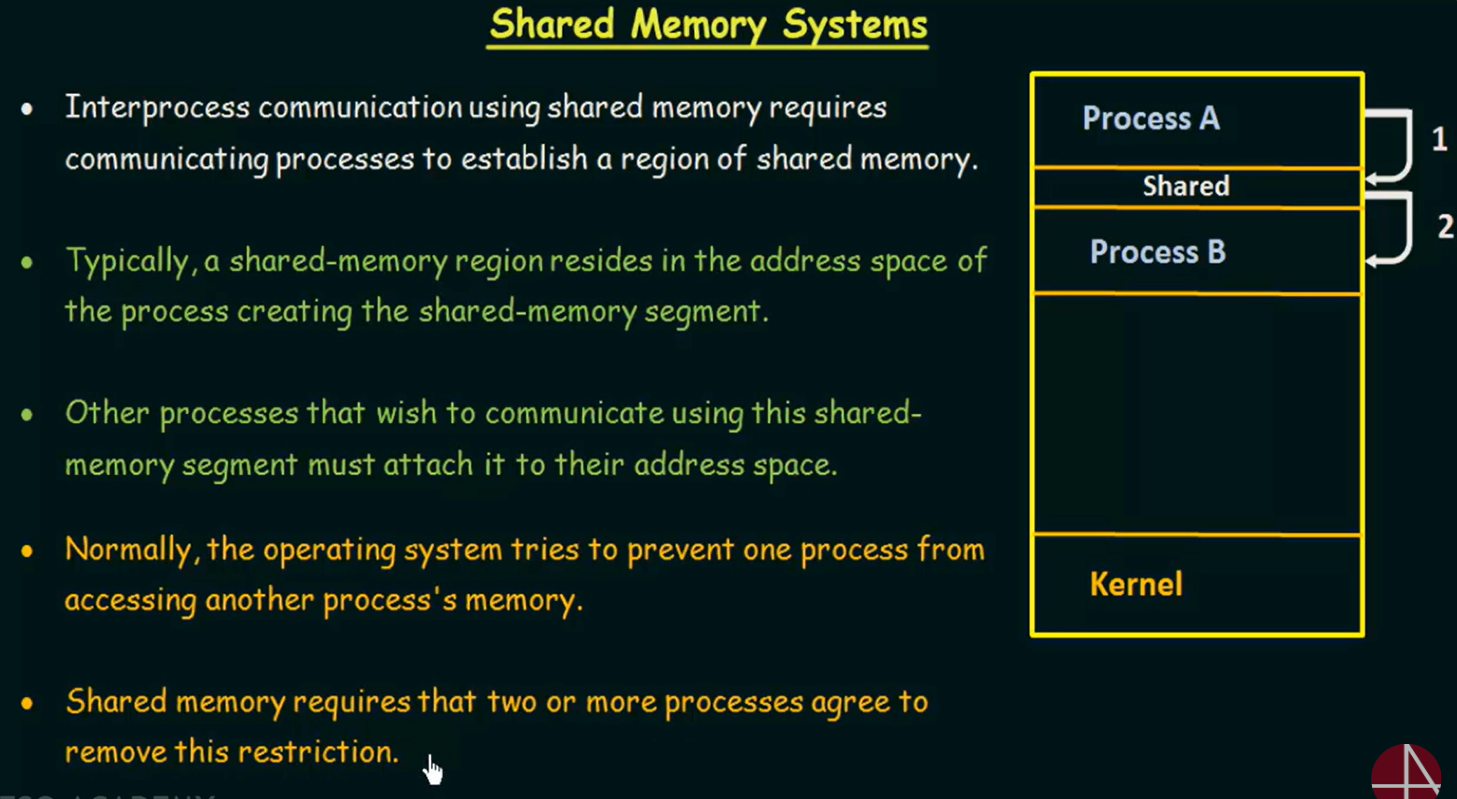
共享内存通信是如何“发生”的?
假设有两个进程:进程 A(创建者) 和 进程 B(附加者)
步骤 1:创建共享内存段(由进程 A 发起)
-
进程 A 调用系统调用(如 Linux 的
shmget())申请一块共享内存; -
操作系统在 A 的地址空间中开辟一块共享内存区域;
-
系统返回一个“共享内存 ID”,用于标识这块内存;
这一步中,共享内存是存在于创建者进程 A 的地址空间内。
步骤 2:其他进程附加共享内存(进程 B 调用)
-
进程 B 想使用这块共享内存,必须通过共享内存 ID 调用
shmat()系统调用; -
这会把共享内存映射到进程 B 的地址空间中;
-
此时,进程 B 的虚拟地址空间中也出现了这块共享内存。
这样,A 和 B 虽然仍然是两个独立的进程,但它们都拥有对这块内存的访问权限,可以直接读写其中的数据。
步骤 3:读写数据(直接访问)
-
A 写数据到共享内存;
-
B 直接读取内存中的内容;
-
也可以反过来。
注意:这一步中系统不会“中转”任何数据,因为两个进程都映射到了同一块内存区域,它们访问的是“同一个地址”。
步骤 4:断开和释放(可选)
-
使用完成后,进程调用
shmdt()解除映射; -
最后创建者调用
shmctl()删除共享内存段; -
系统会回收资源,防止内存泄漏。
🔐 为什么系统默认要禁止这种行为?
因为共享内存会打破“进程地址空间隔离”的安全原则。
-
一个进程如果可以随意访问另一个进程的内存,就可能破坏其逻辑、造成崩溃,甚至带来安全风险(如注入攻击);
-
所以,只有在多个进程明确“同意”共享的前提下,系统才允许共享内存;
这也是为什么共享内存通常用于“受控环境下的合作进程”之间,而不是任何两个进程之间。
接下来我们讲一个共享内存通信中的经典问题:
🎯 Producer–Consumer Problem(生产者-消费者问题)
这个问题不仅帮助你理解共享内存的实际应用,还能深入理解进程同步(Synchronization)的核心思想。
什么是生产者-消费者问题?
在操作系统中,生产者-消费者问题描述的是两个进程之间的通信与协作问题:
-
生产者进程:不断“生产数据”。
-
消费者进程:不断“消费数据”。
问题在于:
生产者生产的数据,必须在“已经准备好”之后,才能被消费者读取;
同时,消费者不能读取一个“还没准备好”的数据,生产者也不能往“满的缓冲区”里写数据。
🧾 举个现实中的例子,以编译程序为例:
| 阶段 | 进程 | 操作 |
|---|---|---|
| 第一步 | 编译器(Producer) | 生成汇编代码 |
| 第二步 | 汇编器(Consumer + Producer) | 读取汇编代码,生成目标文件 |
| 第三步 | 链接器(Consumer) | 读取目标文件,生成可执行文件 |
在这个过程中:
-
上一步的输出是下一步的输入;
-
每一步都要等“数据准备好了”才能继续,不能太快也不能太慢;
-
所以它们之间必须有一个有序通信机制。

如何用共享内存解决生产者-消费者问题?
我们可以用一块共享内存区域作为“缓冲区”,供两个进程使用:
-
生产者往缓冲区中写入数据;
-
消费者从缓冲区中读取数据。
为了让两者并发运行而不冲突,需要这个缓冲区支持:
-
同时被写入一个数据和被读取另一个数据;
-
避免消费者读取空位置,或生产者写入满位置。
引入 “缓冲区” 的概念
这块共享内存通常被设计成一个有限大小的循环缓冲区(circular buffer),例如大小为 N:
[空][空][空][空][空] ← 初始状态↑ ↑in out
-
in指针:指向下一个可以写入的位置(由生产者维护) -
out指针:指向下一个可以读取的位置(由消费者维护)

为什么需要同步?
尽管共享内存速度快,但它不保证访问的顺序,因此容易出错:
会出错的场景:
-
消费者先运行,从还没写入的内存中读取数据(数据还不存在);
-
两个生产者同时写入同一个位置(数据覆盖);
-
生产者写太快,把缓冲区写满,结果覆盖还没消费的数据。
这时候,就必须引入同步机制来协调两者行为。
共享内存 + 同步 的经典解决方案结构:
要素 1:缓冲区
→ 共享内存区域(一个数组)
要素 2:两个指针(或索引)
-
in:下一个写入位置 -
out:下一个读取位置
要素 3:计数器(用于同步)
-
count:当前缓冲区中可用的数据项数量 -
或
empty和full:可用空位数量 / 已填数据数量
要素 4:互斥锁(mutex)
防止读写指针在同一时间被两个进程同时修改
经典同步实现(伪代码)
我们使用:
-
mutex:互斥锁,防止同时修改共享数据 -
empty:可写入的空位数量(初始值为缓冲区大小) -
full:可读取的已填数据数量(初始值为 0)
👨🏭 Producer 伪代码
do {produce_item(item);wait(empty); // 等待有空位wait(mutex); // 加锁buffer[in] = item;in = (in + 1) % N;signal(mutex); // 解锁signal(full); // 通知消费者:有新数据了
} while (true);
👩💻 Consumer 伪代码
do {wait(full); // 等待有数据wait(mutex); // 加锁item = buffer[out];out = (out + 1) % N;signal(mutex); // 解锁signal(empty); // 通知生产者:空位多了一个consume_item(item);
} while (true);
我们接着刚才讲的 Producer–Consumer Problem(生产者–消费者问题),这次要深入了解两个非常重要的缓冲区概念,它们直接影响通信的效率与设计方式:
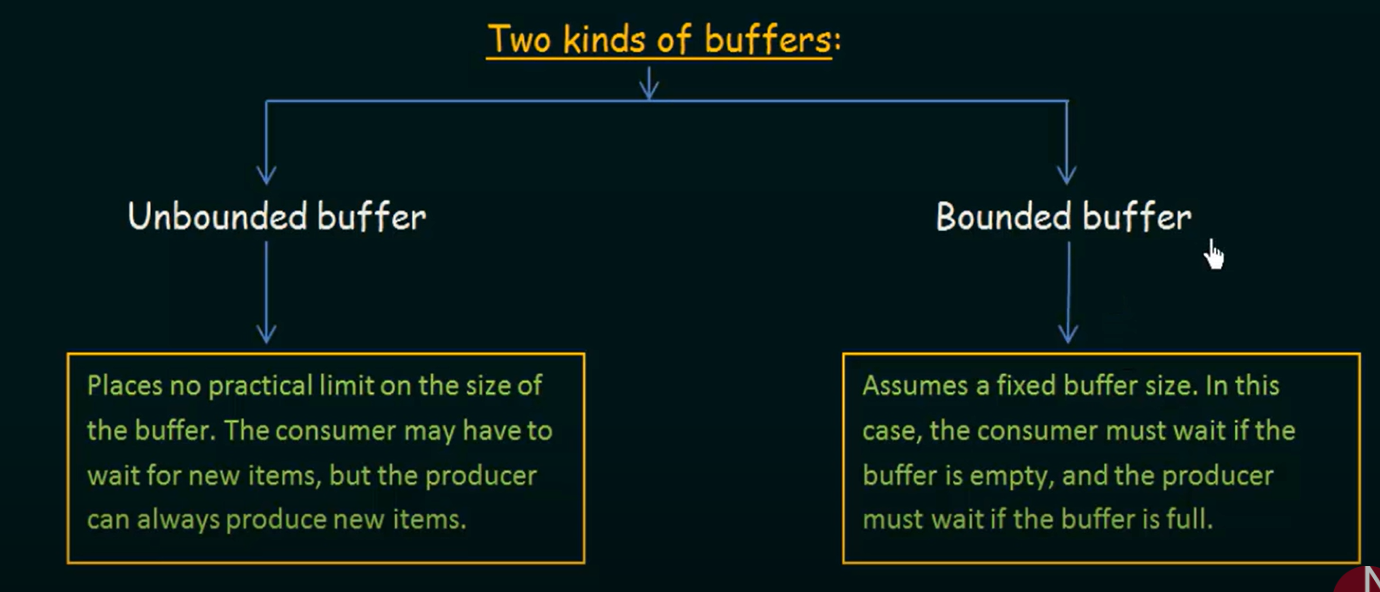
两种缓冲区模型(Two Kinds of Buffers)
生产者和消费者通过 共享缓冲区 传递数据。这个缓冲区有两种设计方式:
1. Unbounded Buffer(无界缓冲区)
2. Bounded Buffer(有界缓冲区)
这两者的区别主要体现在:缓冲区容量是否有限,生产者能否一直生产?消费者能否一直消费?
Unbounded Buffer(无界缓冲区)
无界缓冲区是逻辑上“无限大”的队列,生产者可以一直把数据放进缓冲区,不用考虑空间问题。
即使消费者处理很慢,生产者也不会被迫停下来。
| 特性 | 说明 |
|---|---|
| 没有容量限制 | 生产者可以无限制地添加数据 |
| 可能造成内存风险 | 如果消费者太慢,会不断占用内存 |
| 生产者永不等待 | 不会因为“空间不够”而阻塞 |
| 消费者可能等待 | 如果缓冲区暂时是空的,消费者需要等待 |
举个例子:
假设你在写一封非常长的邮件(生产者),但朋友很慢才打开看(消费者):
-
你可以一直写,不管他什么时候读;
-
但如果你写太快,占用的“草稿箱”内存可能会爆掉。
Bounded Buffer(有界缓冲区)
有界缓冲区是大小固定的数组或队列,例如:最多只能保存 10 个数据项。
如果缓冲区满了,生产者就必须等待;如果缓冲区空了,消费者也要等待。
| 特性 | 说明 |
|---|---|
| 容量固定 | 系统在设计时就规定缓冲区大小(如 N 个位置) |
| 生产者可能等待 | 当缓冲区满时,生产者必须暂停,等消费者取走数据 |
| 消费者可能等待 | 当缓冲区空时,消费者必须等待新数据 |
| 安全性更高 | 不会无限占用内存,系统资源可控 |
举个例子:
你家餐桌上最多只能放 5 盘菜(缓冲区):
-
厨师(生产者)如果把菜做太快,桌子满了,他就只能等;
-
吃饭的人(消费者)如果吃得太慢,也得加快速度,否则桌子放不下新菜。
| 比较项 | Unbounded Buffer | Bounded Buffer |
|---|---|---|
| 容量限制 | 没有限制(理论上无限大) | 固定大小(例如 N 个位置) |
| 生产者是否会阻塞 | 否 | 会(当缓冲区满) |
| 消费者是否会阻塞 | 是(当缓冲区空) | 是(当缓冲区空) |
| 实现复杂度 | 相对简单(只需考虑同步) | 更复杂(需同步+容量控制) |
| 系统资源管理 | 不可控,可能爆内存 | 可控,资源使用有上限 |
| 应用场景 | 数据量小或资源丰富、调试阶段 | 嵌入式系统、高并发服务、生产环境 |
🔚 结语:在实际操作系统中,大多数应用场景都会使用 有界缓冲区,因为内存不是无限的,需要严格控制资源使用。而 无界缓冲区更像是一个理想化的模型,适合在理论分析或特定高资源环境下使用。