精通分类:解析Scikit-learn中的KNN、朴素贝叶斯与决策树(含随机森林)
在机器学习领域,分类任务占据核心地位。Scikit-learn作为Python的机器学习利器,提供了丰富高效的分类算法。现在进行初步探讨三种经典算法:K最近邻(KNN)、朴素贝叶斯(Naive Bayes)和决策树(Decision Tree),并延伸至集成方法随机森林(Random Forest)
一、K最近邻(KNN):基于实例的惰性学习
算法原理
KNN是一种典型的惰性学习(Lazy Learning) 算法。其核心思想是:相似的数据点拥有相似的标签。预测新样本时,算法在训练集中找到与其最接近的K个邻居,通过投票(分类)或平均(回归)得出结果。
比如: 有10000个样本,选出7个到样本A的距离最近的,然后这7个样本中假设:类别1有2个,类别2有3个,类别3有2个.那么就认为A样本属于类别2,因为它的7个邻居中 类别2最多(近朱者赤近墨者黑)
再比如使用KNN算法预测《唐人街探案》电影属于哪种类型?分别计算每个电影和预测电影的距离然后求解:
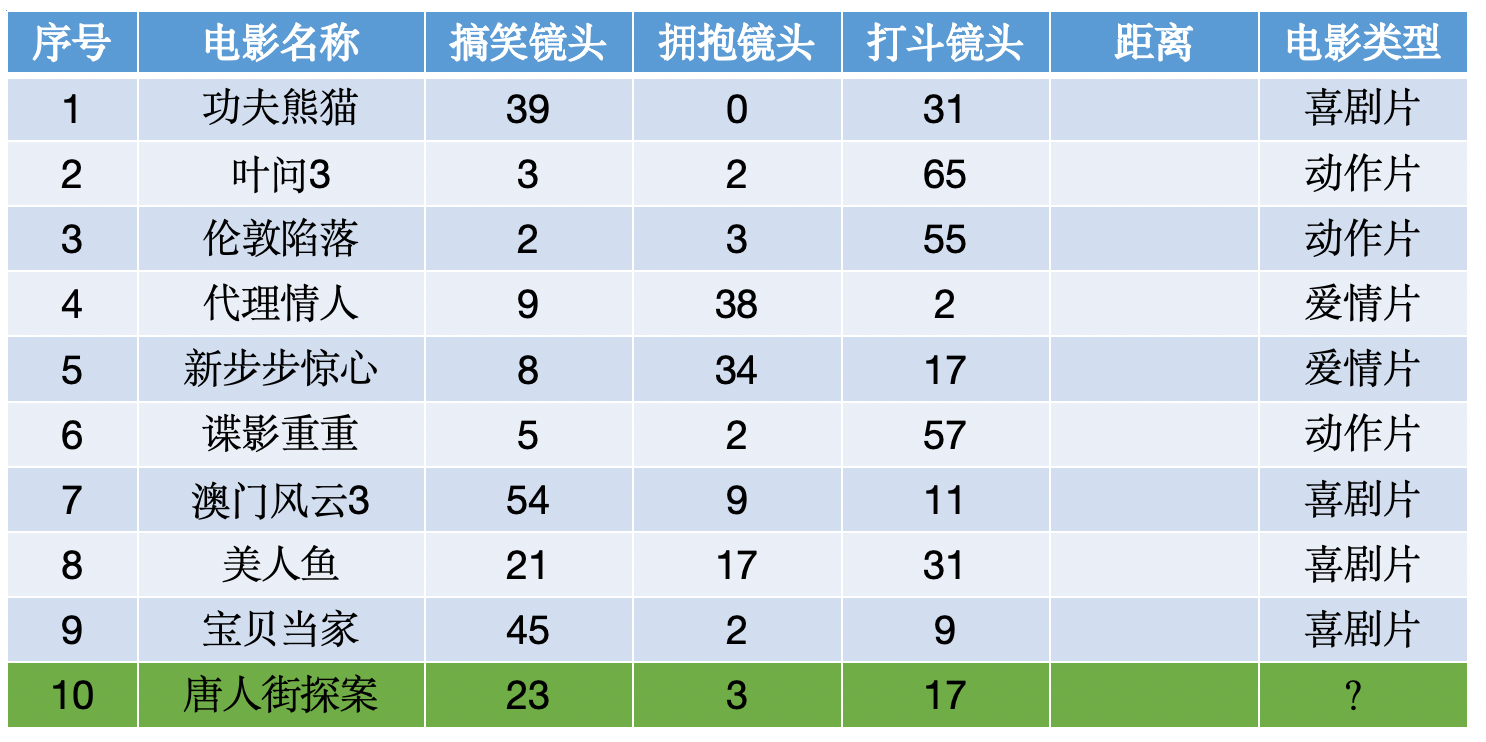
其中原理也很简单,模型会通过给出的其余电影的每种镜头数量来计算唐探和每一个的距离,选出前k个电影,再综合判断唐探的类型。
KNN算法API使用:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载数据
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)# 创建KNN模型(k=5,使用欧氏距离)
knn = KNeighborsClassifier(n_neighbors=5, metric='euclidean')
knn.fit(X_train, y_train)print("KNN准确率:", knn.score(X_test, y_test))
关键缺点与挑战
- 计算成本高:预测时需计算新样本与所有训练样本的距离,大数据集上效率低,使得KNN算法的训练成本低,预测成本高。因为训练只需要保存记录训练数据。
- 维度灾难:高维空间中距离度量失效,分类性能急剧下降。简而言之就是,当预测数据是极大的数据,如预测生物细胞特征差别等等,这一类数据往往特征差距数据量极大,当每一个样本的差距都上亿的,这种差距就没有代表性。就好像你拥有马爸爸的资产后掉了几块钱,几十块钱不会有多大心理波动。
- 特征缩放敏感:不同量纲的特征需标准化(如
StandardScaler)。 - 类别不平衡敏感:多数类易主导投票结果。
模型选择与调优
- K值选择:过小(k=1)导致过拟合、噪声敏感;过大使决策边界模糊。通过交叉验证,超参数搜索选择最优k:
from sklearn.model_selection import GridSearchCV param_grid = {'n_neighbors': range(1, 20)} grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5) grid_search.fit(X_train, y_train) print("最优K值:", grid_search.best_params_['n_neighbors']) - 距离度量:欧氏距离(连续特征)、曼哈顿距离(高维)、余弦相似度(文本)等。
- 加速策略:使用
KDTree或BallTree数据结构(通过algorithm参数指定)。
二、朴素贝叶斯:概率推理的高效引擎
算法原理与贝叶斯推理
假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示: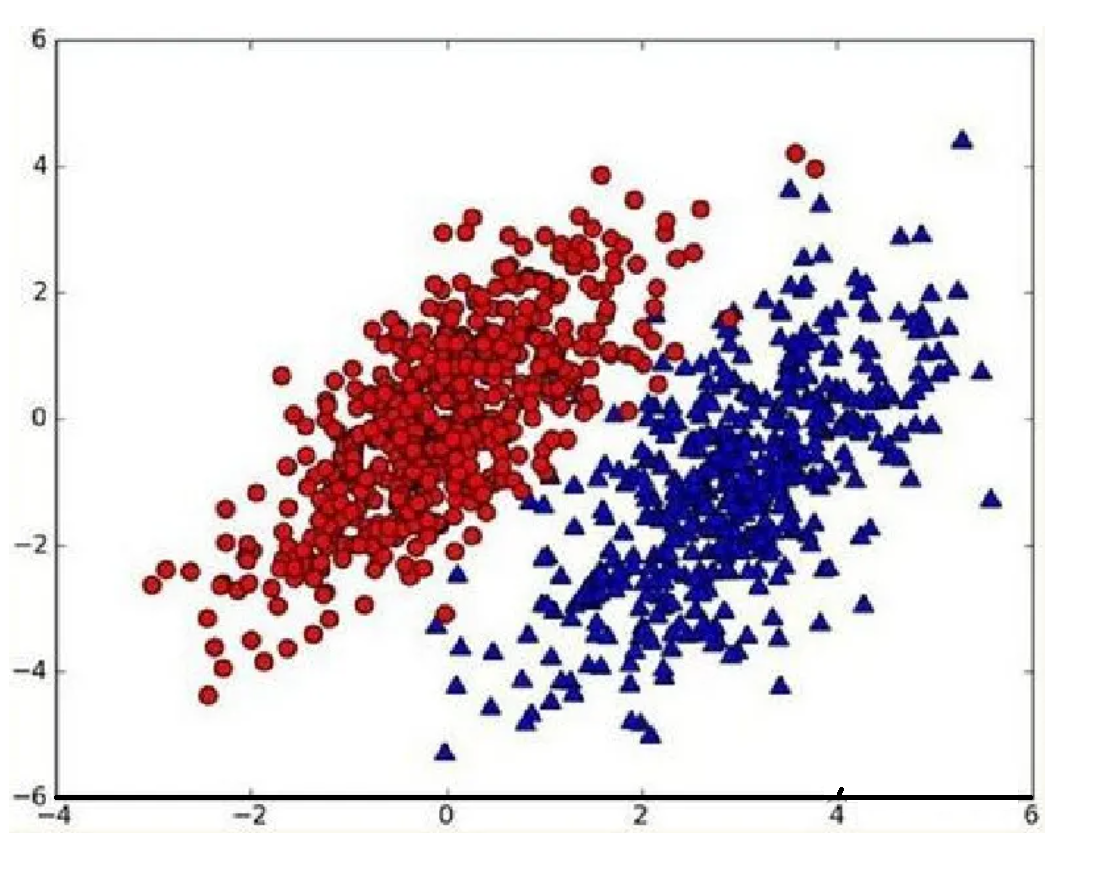
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
- 如果p1(x,y)>p2(x,y),那么类别为1
- 如果p1(x,y)<p2(x,y),那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。已经了解了贝叶斯决策理论的核心思想,那么接下来,就是学习如何计算p1和p2概率。
条件概率
在学习计算p1 和p2概率之前,我们需要了解什么是条件概率(Conditional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。
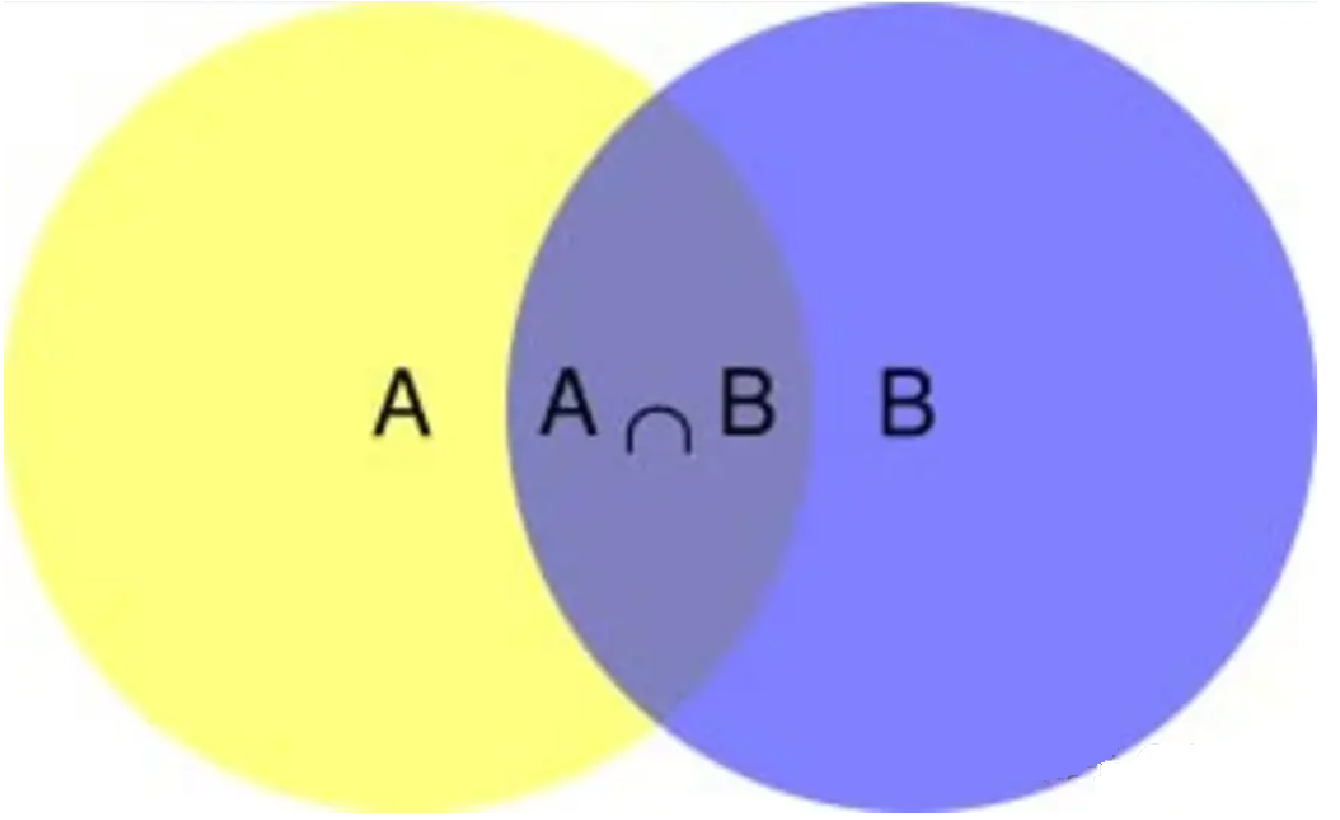
根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率就是P(A∩B)除以P(B)。
𝑃(𝐴|𝐵)=𝑃(𝐴∩𝐵)/𝑃(𝐵)
因此,
𝑃(𝐴∩𝐵)=𝑃(𝐴|𝐵)𝑃(𝐵)
同理可得,
𝑃(𝐴∩𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)
即
𝑃(𝐴|𝐵)=𝑃(B|A)𝑃(𝐴)/𝑃(𝐵)
这就是条件概率的计算公式。
贝叶斯推断
对条件概率公式进行变形,可以得到如下形式:
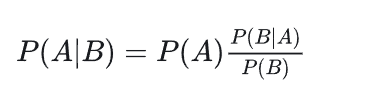
我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:
后验概率 = 先验概率x调整因子
这就是贝叶斯推断的含义。我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。
朴素贝叶斯推断
理解了贝叶斯推断,那么让我们继续看看朴素贝叶斯。贝叶斯和朴素贝叶斯的概念是不同的,区别就在于“朴素”二字,朴素贝叶斯对条件概率分布做了条件独立性的假设。 比如下面的公式,假设有n个特征:
根据贝叶斯定理,后验概率 P(a|X) 可以表示为:
P(a∣X)=P(X∣a)P(a)P(X)P(a|X) = \frac{P(X|a)P(a)}{P(X)}P(a∣X)=P(X)P(X∣a)P(a)
其中:
- P(X|a) 是给定类别 ( a ) 下观测到特征向量 X=(x1, x2, …, xn) 的概率;
- P(a) 是类别 a 的先验概率;
- P(X) 是观测到特征向量 X 的边缘概率,通常作为归一化常数处理。
朴素贝叶斯分类器的关键假设是特征之间的条件独立性,即给定类别 a ,特征 xix_ixi 和 xjx_jxj (其中 i≠ji \neq ji=j 相互独立。)
因此,我们可以将联合概率 P(X|a) 分解为各个特征的概率乘积:
P(X∣a)=P(x1,x2,...,xn∣a)=P(x1∣a)P(x2∣a)...P(xn∣a)P(X|a) = P(x_1, x_2, ..., x_n|a) = P(x_1|a)P(x_2|a)...P(x_n|a)P(X∣a)=P(x1,x2,...,xn∣a)=P(x1∣a)P(x2∣a)...P(xn∣a)
将这个条件独立性假设应用于贝叶斯公式,我们得到:
P(a∣X)=P(x1∣a)P(x2∣a)...P(xn∣a)P(a)P(X)P(a|X) = \frac{P(x_1|a)P(x_2|a)...P(x_n|a)P(a)}{P(X)}P(a∣X)=P(X)P(x1∣a)P(x2∣a)...P(xn∣a)P(a)
这样,朴素贝叶斯分类器就可以通过计算每种可能类别的条件概率和先验概率,然后选择具有最高概率的类别作为预测结果。
sklearn中的朴素贝叶斯分类器
- GaussianNB:假设连续特征服从高斯分布。
- MultinomialNB:适用于离散计数(如文本词频)。
- BernoulliNB:二值特征(如文本是否出现某词)。
平滑系数(Laplace Smoothing)
解决零概率问题:当训练集中某特征未在某个类中出现时,P(特征|类)=0会导致整个后验概率为0。
平滑技术通过在计数中添加一个常数α(通常为1)避免此问题:
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer# 文本分类示例
texts = ["good movie", "not good", "bad plot"]
y = [1, 0, 0] # 1:正面, 0:负面vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)# 使用平滑系数alpha=1.0(默认)
nb = MultinomialNB(alpha=1.0)
nb.fit(X, y)test_text = ["good plot"]
test_X = vectorizer.transform(test_text)
print("预测类别:", nb.predict(test_X)) # 输出: [1]
三、决策树:直观的规则生成器
决策树的建立:核心是特征选择
选择最佳分裂特征以最大化数据“纯度”提升。常用准则:
信息增益(Information Gain)
基于信息熵(Entropy):
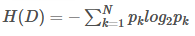
信息增益 = ![Entropy(父节点) - Σ[(|Dᵥ|/|D|) * Entropy(子节点ᵥ)]](https://i-blog.csdnimg.cn/direct/cb3fd1a5a43d484fa2066af99b560716.png)
偏向选择取值较多的特征。
信息增益决策树倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息,算法只能对描述属性为离散型属性的数据集构造决策树。
根据以下信息构建一棵预测是否贷款的决策树。我们可以看到有4个影响因素:职业,年龄,收入和学历。
| 职业 | 年龄 | 收入 | 学历 | 是否贷款 | |
|---|---|---|---|---|---|
| 1 | 工人 | 36 | 5500 | 高中 | 否 |
| 2 | 工人 | 42 | 2800 | 初中 | 是 |
| 3 | 白领 | 45 | 3300 | 小学 | 是 |
| 4 | 白领 | 25 | 10000 | 本科 | 是 |
| 5 | 白领 | 32 | 8000 | 硕士 | 否 |
| 6 | 白领 | 28 | 13000 | 博士 | 是 |
第一步,计算根节点的信息熵
上表根据是否贷款把样本分成2类样本,"是"占4/6=2/3, "否"占2/6=1/3,
所以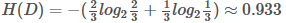
第二步,计算属性的信息增益
<1> "职业"属性的信息增益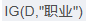
在职业中,工人占1/3, 工人中,是否代款各占1/2, 所以有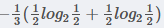
,
在职业中,白领占2/3, 白领中,是贷款占3/4, 不贷款占1/4, 所以有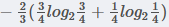
所以有 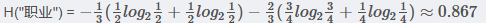
最后得到职业属性的信息增益为:
<2>" 年龄"属性的信息增益(以35岁为界)

<3> "收入"属性的信息增益(以10000为界,大于等于10000为一类)
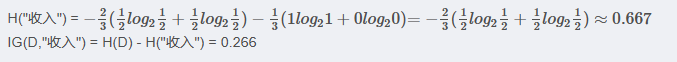
<4> "学历"属性的信息增益(以高中为界, 大于等于高中的为一类)
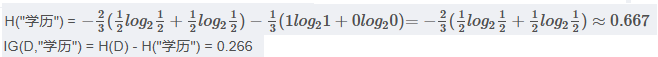
注意: 以上年龄使用35为界,收入使用10000为界,学历使用高中为界,实计API使用中,会有一个参数"深度", 属性中具体以多少为界会被根据深度调整。
第三步, 划分属性
对比属性信息增益发现,"收入"和"学历"相等,并且是最高的,所以我们就可以选择"学历"或"收入"作为第一个
决策树的节点, 接下来我们继续重复1,2的做法继续寻找合适的属性节点
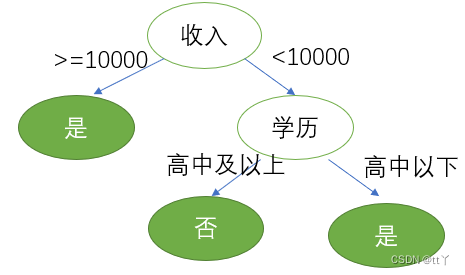
基于基尼指数决策树的建立(了解)
基尼指数**(Gini Index)是决策树算法中用于评估数据集纯度的一种度量,基尼指数衡量的是数据集的不纯度,或者说分类的不确定性。在构建决策树时,基尼指数被用来决定如何对数据集进行最优划分,以减少不纯度。
基尼指数的计算
对于一个二分类问题,如果一个节点包含的样本属于正类的概率是 §,则属于负类的概率是 (1-p)。那么,这个节点的基尼指数 (Gini§) 定义为:
Gini(p)=1−p2−(1−p)2=2p(1−p)Gini(p) = 1 - p^2 - (1-p)^2 = 2p(1-p)Gini(p)=1−p2−(1−p)2=2p(1−p)
对于多分类问题,如果一个节点包含的样本属于第 k 类的概率是 pkp_kpk,则节点的基尼指数定义为:
Gini(p)=1−∑k=1Kpk2Gini(p) = 1 - \sum_{k=1}^{K} p_k^2Gini(p)=1−∑k=1Kpk2
基尼指数的意义
- 当一个节点的所有样本都属于同一类别时,基尼指数为 0,表示纯度最高。
- 当一个节点的样本均匀分布在所有类别时,基尼指数最大,表示纯度最低。
决策树优点:
可视化 - 可解释能力-对算力要求低
决策树缺点:
易产生过拟合,所以不要把深度调整太大了。
决策树API使用
class sklearn.tree.DecisionTreeClassifier(…)
参数:
criterion “gini” "entropy” 默认为=“gini”
当criterion取值为"gini"时采用 基尼不纯度(Gini impurity)算法构造决策树,
当criterion取值为"entropy”时采用信息增益( information gain)算法构造决策树.
max_depth int, 默认为=None 树的最大深度可视化决策树
function sklearn.tree.export_graphviz(estimator, out_file=“iris_tree.dot”, feature_names=iris.feature_names)
参数:
estimator决策树预估器
out_file生成的文档
feature_names节点特征属性名
功能:
把生成的文档打开,复制出内容粘贴到"http://webgraphviz.com/"中,点击"generate Graph"会生成一个树型的决策树图
这里使用决策树对sklearn本地分类数据集鸢尾花进行分类来作为实例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier, export_graphviz# 1)获取数据集
iris = load_iris()# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)#3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy")estimator.fit(x_train, y_train)# 5)模型评估,计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)# 6)预测
index=estimator.predict([[2,2,3,1]])
print("预测:\n",index,iris.target_names,iris.target_names[index])# 可视化决策树
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
把文件"iris_tree.dot"内容粘贴到"http://webgraphviz.com/"点击"generate Graph"决策树图
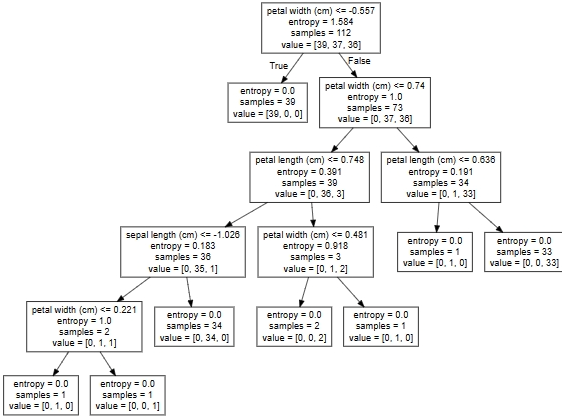
关键参数解析
max_depth:控制树复杂度,防止过拟合的核心参数。min_samples_split/min_samples_leaf:限制节点继续分裂的条件。ccp_alpha:代价复杂度剪枝参数(Post-pruning)。
四、集成学习之随机森林:决策树的威力升级
算法原理
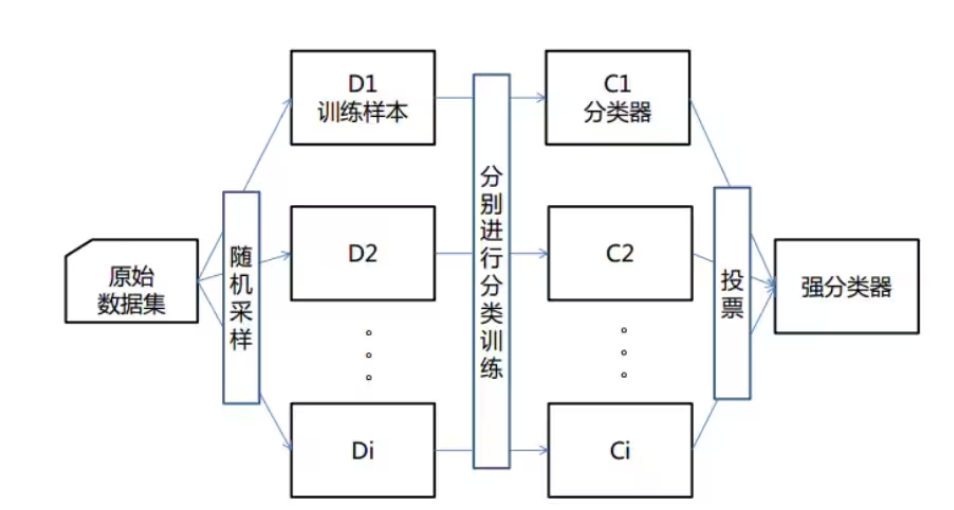
- 随机: 特征随机,训练集随机
- 样本:对于一个总体训练集T,T中共有N个样本,每次有放回地随机选择n个样本。用这n个样本来训练一个决策树。
- 特征:假设训练集的特征个数为d,每次仅选择k(k<d)个来构建决策树。
- 森林: 多个决策树分类器构成的分类器, 因为随机,所以可以生成多个决策树
- 处理具有高维特征的输入样本,而且不需要降维
- 使用平均或者投票来提高预测精度和控制过拟合
核心思想
- Bagging(Bootstrap Aggregating):
从训练集有放回随机抽样生成多个子集,分别训练基模型。 - 随机特征子空间:
每个决策树分裂时,仅考虑随机选取的一部分特征(如max_features='sqrt')。
为什么有效?
- 降低方差:通过平均多个独立训练的树,减少模型对训练数据的敏感度。
- 提高泛化能力:特征随机性增加了模型的多样性。
sklearn实现与优势
from sklearn.ensemble import RandomForestClassifierrf = RandomForestClassifier(n_estimators=100, # 森林中树的数量criterion='gini', # 分裂准则max_depth=None, # 树可生长到最大深度(常不限制,靠其他参数剪枝)min_samples_split=2,min_samples_leaf=1,max_features='auto', # 通常为 'sqrt' (特征总数的平方根)bootstrap=True, # 使用bootstrap抽样oob_score=True, # 使用袋外样本评估模型n_jobs=-1, # 使用所有CPU核心random_state=42
)
rf.fit(X_train, y_train)print("袋外估计准确率:", rf.oob_score_)
关键优势
- 显著提升预测准确性(相比单棵决策树)。
- 自带特征重要性评估(
rf.feature_importances_)。 - 对部分特征缺失、异常值不敏感。
- 袋外样本(OOB)提供内置验证。
五、算法对比与选择指南
| 特性 | KNN | 朴素贝叶斯 | 决策树 | 随机森林 |
|---|---|---|---|---|
| 学习类型 | 惰性学习 | 渴望学习 | 渴望学习 | 集成学习(渴望) |
| 训练速度 | 快(无显式训练) | 非常快 | 快 | 较慢(需训练多棵树) |
| 预测速度 | 慢(需计算距离) | 快 | 快 | 中等(取决于树数量) |
| 可解释性 | 低 | 中等(概率) | 高(规则清晰) | 低(整体模型) |
| 对数据假设 | 无 | 强(特征独立) | 无 | 无 |
| 处理高维数据 | 差(维度灾难) | 好(文本分类表现佳) | 中等 | 好 |
| 抗噪声/过拟合 | 敏感(需调k) | 稳健(依赖分布假设) | 易过拟合(需剪枝) | 强(Bagging+随机) |
| 主要调优参数 | n_neighbors, metric | alpha (平滑系数) | max_depth, min_* | n_estimators, max_features |
场景推荐:
- 追求极致速度/文本分类:朴素贝叶斯(特别是
MultinomialNB)。 - 需要可解释性/简单规则:决策树(
max_depth不宜过大)。 - 平衡精度与效率/通用场景:随机森林(首选)。
- 小数据集/低维/需简单基准:KNN(注意标准化和k选择)。
结语
掌握KNN、朴素贝叶斯、决策树及随机森林的原理与实战技巧,是构建高效分类系统的基石。理解算法背后的假设、优缺点及适用场景,结合Scikit-learn强大的API和调优工具(如GridSearchCV),能针对实际问题游刃有余地选择与优化模型。没有“最好”的算法,只有“最合适”的算法。持续探索不同模型在数据上的表现,是机器学习工程师的精进之道。
代码实践提示:本文所有代码示例均基于
scikit-learn 1.3+版本,运行前请确保安装正确依赖(pip install scikit-learn matplotlib)。可视化决策树需额外安装graphviz。