ICML 2025 | 深度剖析时序 Transformer:为何有效,瓶颈何在?
本文介绍帝国理工学院等机构在 ICML 2025 发表的最新研究成果。该研究并未提出新模型,而是对现有时间序列 Transformer 模型进行了一次深刻的拷问——为何结构更简单的 Transformer( PatchTST, iTransformer)在各大基准测试中,反而能优于设计更复杂的模型?
研究发现,当前主流基准数据集的性能主要由单变量内部的依赖关系主导,而跨变量间的影响较小。因此,模型的成功更多地得归功于Z-score 归一化和Skip connections等组件,它们极大地增强了模型捕捉单变量趋势的能力。本文通过引入互信息分析和可控的合成数据集,系统性地揭示了现有 Transformer 模型的真实能力和局限性,为未来设计更适用于真实、复杂场景的模型提供了重要见解。
另外,我整理了ICML 2025时间序列相关论文合集,感兴趣的dd我~
论文这里~

【论文标题】A Closer Look at Transformers for Time Series Forecasting: Understanding Why They Work and Where They Struggle
【论文链接】https://papers.cool/venue/kHEVCfES4Q@OpenReview
研究背景
Transformer 在时间序列预测领域取得了巨大成功。研究者们提出了多种 Token 化策略,Point-wise、Patch-wise和Variate-wise,以捕捉不同维度的数据依赖。虽然模型架构日益复杂,但是一些设计相对简单的模型,如仅关注单变量内部模式的 PatchTST 和专注于跨变量关系的 iTransformer,却在性能测试中稳定名列前茅。
这种现象引出了一系列关键问题:
为什么以时间点为单位进行建模的 Point-wise Transformer 效果普遍较差?
为什么关注单变量的 Intra-variate attention 和关注多变量的 Inter-variate attention 会取得相似的性能?
那些成功的简单 Transformer 模型,获得其卓越性能的真正原因是什么?
针对这些问题,此论文摒弃了提出新模型的思路,转而设计了一套系统的分析框架,目的是深入理解现有模型的工作机制和真正的优势所在。
核心贡献
本研究贡献可总结如下:
- 通过实验证明,在大多数标准基准上,模型的预测性能主要由捕捉单变量内部依赖的能力决定,而跨变量依赖的影响则小得多。这解释了为何不同注意力机制的模型能取得相似结果。
- 设计了一套基于Mutual Information的评估指标,用于量化模型对不同维度依赖的捕捉能力。同时,创建了可控的合成数据集,能够系统性地评估模型在不同依赖结构下的表现。
- 得出了时序模型的核心组件:研究发现,Z-score 实例归一化和编码器中的跳跃连接是推动模型成功的关键技术组件,而非复杂的注意力设计本身。
- 在真实的医疗健康数据集上验证了研究发现,指出基准数据集的自依赖和平稳特性是影响模型评估结果的重要因素,并为设计面向更复杂应用的 Transformer 提供了实践指导。
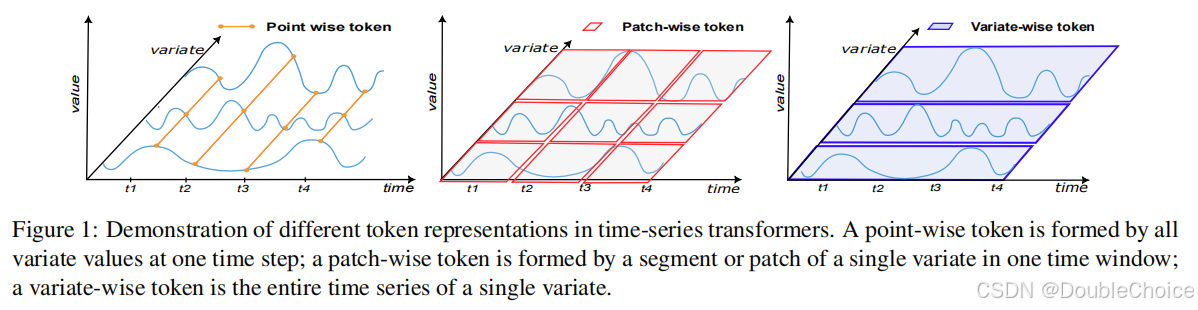
方法解析
本文的核心并非一个新模型,而是一套创新的分析框架。该框架旨在客观、定量地评估不同 TransformerTransformerTransformer 模型捕捉时间序列依赖关系的能力。
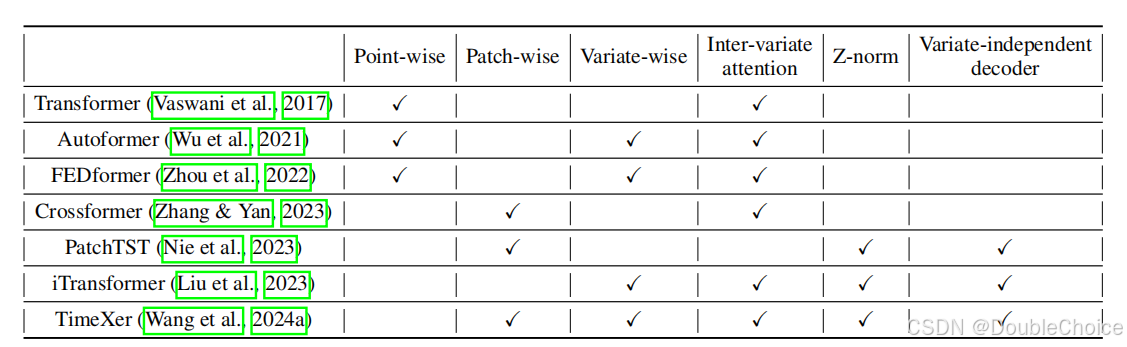
111. 互信息评估指标
为了衡量模型预测对输入各变量的依赖程度,作者提出了一种互信息分数 σij\sigma_{ij}σij。它通过计算在固定其他变量时,输入变量 iii 的变化对输出变量 jjj 预测值方差的影响来估计。
- Intra−MIIntra-MIIntra−MI ScoreScoreScore (σii\sigma_{ii}σii): 当 i=ji=ji=j 时,表示模型捕捉单变量自身依赖的能力。
- Inter−MIInter-MIInter−MI ScoreScoreScore (σij\sigma_{ij}σij, i≠ji \neq ji=j): 当 i≠ji \neq ji=j 时,表示模型捕捉跨变量依赖的能力。
这些指标与模型无关,可以公平地比较不同架构的 TransformerTransformerTransformer。
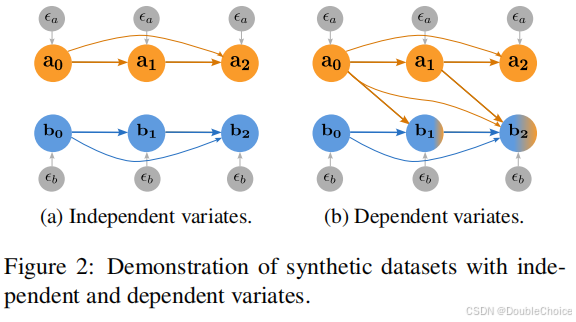
222. 可控合成数据集
为了摆脱基准数据集固有特性的限制,作者设计了可以精确控制依赖结构的合成数据集。如图 222 所示,数据集生成过程包含两个关键参数:
- 自相关强度 γ\gammaγ: 控制单个变量时间序列的平滑度和历史依赖性。
- 跨变量依赖强度 α\alphaα: 控制变量之间相互影响的程度。
通过调整这两个参数,可以模拟从完全独立到强耦合的各种多变量时间序列场景,从而系统性地测试模型的“长板”和“短板”。
333. 模型消融实验
作者对 iTransformer 等模型进行了深入的消融研究,例如:
- 移除编码器中的跳跃连接(w/ow/ow/o SCSCSC)。
- 将与变量无关的解码器替换为与变量相关的解码器(VD−DeVD-DeVD−De)。
- 测试 Z−scoreZ-scoreZ−score 归一化的有无。
实验验证
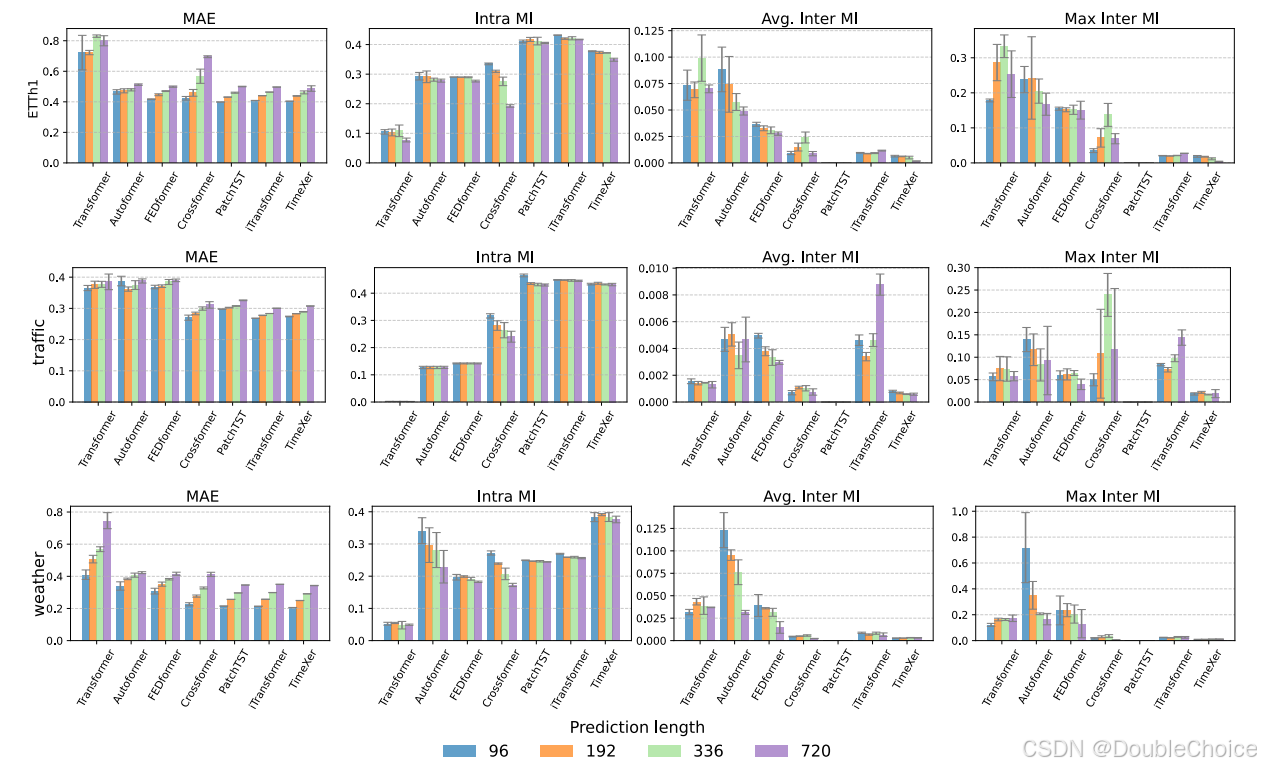
在 ETTh1、Traffic等多个基准数据集上:
- Point-wise模型,Transformer, Autoformer的Intra-MI分数最低,其预测误差也最高。这表明它们难以有效捕捉单变量的时间模式。
- Patch-wise 和 Variate-wise模型,PatchTST, iTransformer, TimeXer具有非常高的Intra-MI分数和优越的性能。尽管 iTransformer设计用于捕捉跨变量关系,但其 Inter-MI 分数在这些数据集上并不突出,其成功仍然主要依赖于对单变量模式的建模。
这一结果有力地支持了“基准数据集由单变量依赖主导”的结论。
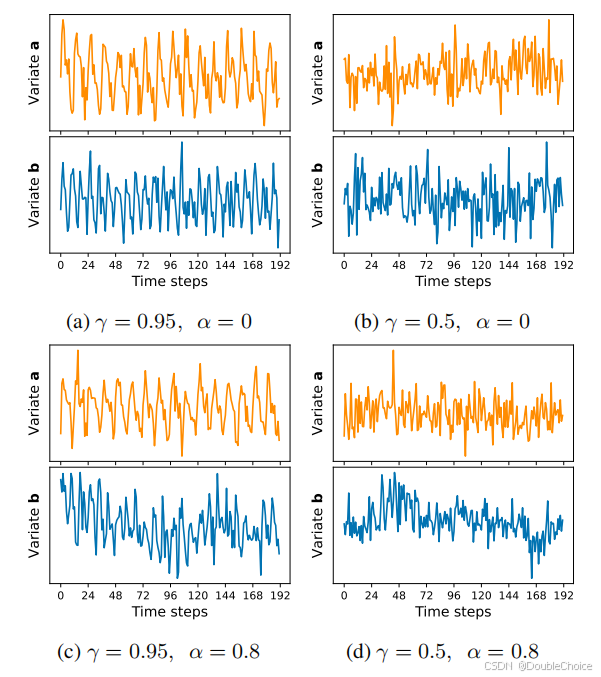
合成数据集上的实验进一步证实了这一点。当跨变量依赖很弱时,α≤0.4\alpha \le 0.4α≤0.4,各模型性能相近。但当跨变量依赖性显著增强时,α=0.8\alpha=0.8α=0.8,专门为跨维度交互设计的Crossformer开始展现出明显的优势,而PatchTST和iTransformer则表现不佳。
此外,消融实验表明,移除跳跃连接会导致性能在基准上急剧下降,而在 Z-score归一化上的测试则发现,该技术对平稳的基准数据集至关重要,但可能会损害模型在非平稳数据上的表现。
总结
本文通过一套严谨的分析框架,揭示了当前时间序列 Transformer研究中的一个重要“盲点”:模型的成功在很大程度上被基准数据集的内在特性以及简单而有效的技术组件,Z-score归一化、跳跃连接所驱动,而非表面上宣传的复杂注意力机制。这提醒研究者们需要重新审视模型的评估方式,并开发更多样化、更接近现实世界的基准,以推动领域向解决真正复杂问题迈进。
一言概括之,时序Transformer的成功秘诀,可能不在于花哨的注意力,而在于对单变量趋势的精准捕捉和数据归一化的巧妙运用。