Linux 系统管理-13-系统负载监控
文章目录
- 系统负载监控
- 系统负载介绍
- 查看系统负载
- 负载解读
- top 命令
- stress 工具
- 压力测试-CPU
- 压力测试-内存
- 压力测试-磁盘
- 网络测试
- 监控总结
系统负载监控
系统负载介绍
系统负载平均值:Linux内核以活动请求数的指数移动平均值来表示。
- 活动请求数不仅包含运行中进程,还包含等待IO的进程,对应于R和D。等待IO包括处于睡眠等待预期磁盘和网络响应的任务。
- 指数移动平均值是一个数学公式,可以平滑趋势数据的高值和低值,更加准确地表示一段时间内系统负载,并确定系统负载是随着时间增加还是减少。
- 根据所有CPU活动请求数,每5秒计算一次Load Average。通过汇总这些值,可以得到最近1分钟,5分钟和15分钟内的指数移动平均值。
- 一些UNIX系统仅考虑CPU使用率或运行队列长度。Linux中负载平均值中还包含了对IO的考量,遇到负载平均值很高但CPU活动很低时,检查磁盘和网络活动。
- Linux将各个物理CPU核心和微处理器超线程计为独立执行单元。每个独立的执行单元拥有独立的请求队列。
查看系统负载
# 查看CPU
[laoma@centos7 ~]$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2 # cpu数量为2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 1
socket: 2
NUMA 节点: 1
厂商 ID: GenuineIntel
CPU 系列: 6
型号: 94
型号名称: Intel(R) Core(TM) i5-6300HQ CPU @ 2.30GHz
步进: 3
CPU MHz: 2304.001
BogoMIPS: 4608.00
......# 查看负载
[laoma@centos7 ~]$ uptime13:47:10 up 5:01, 2 users, load average: 0.00, 0.01, 0.05# 给系统加负载
[laoma@centos7 ~]$ md5sum /dev/zero &
[1] 4912
[laoma@centos7 ~]$ md5sum /dev/zero &
[2] 4913# 等30秒左右
[laoma@centos7 ~]$ uptime13:48:57 up 5:03, 2 users, load average: 1.02, 0.28, 0.13
负载解读
示例:4核心的CPU
-
负载为: 2.92 4.48 5.20
-
每个cpu负载为:0.73(2.92/4) 1.12(4.48/4) 1.30(5.20/4)
比较理想的值为 75% 左右。
top 命令
作用:动态查看进程信息,包括不同状态任务数量,CPU消耗和内存消耗。
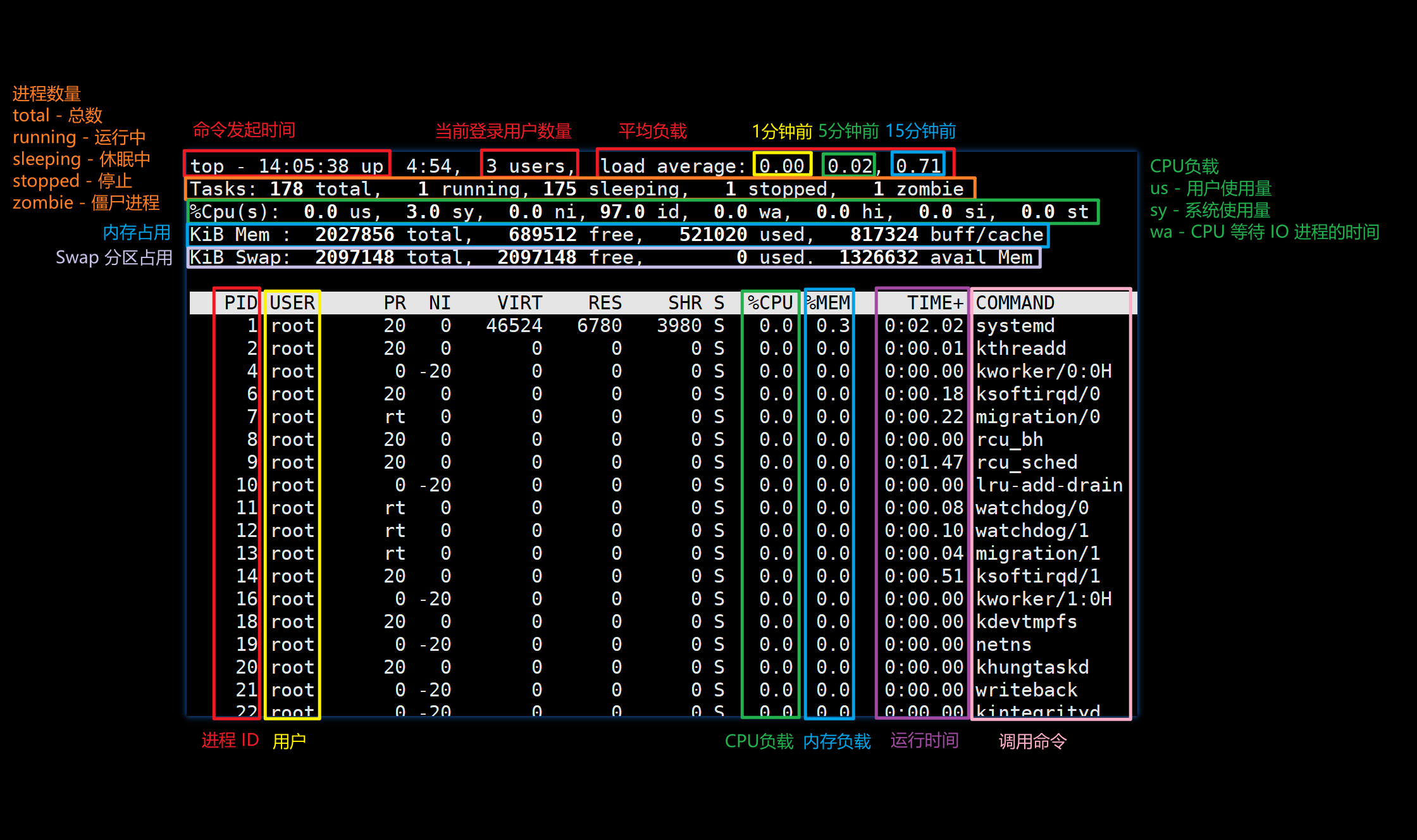
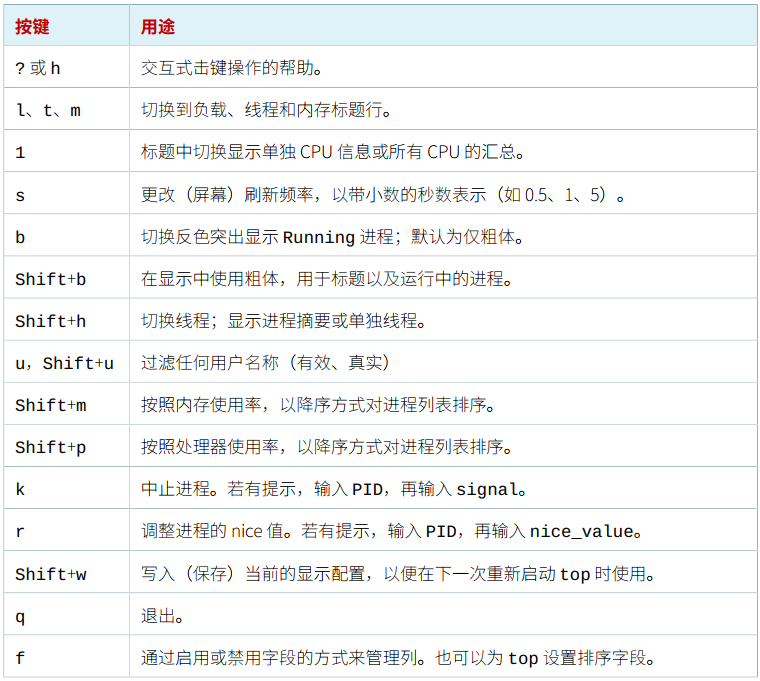
top命令快捷键
常用的命令:数字1,P,M,k,q,h。
stress 工具
Linux 中的 stress 工具用于对系统进行压力测试,可模拟 CPU、内存、I/O 和磁盘等资源的高负载状态。通过指定参数(如 -c 压 CPU、-m 压内存)可创建负载,帮助发现系统在压力下的稳定性问题,常用于性能调优或硬件验证。
# 安装
[root@centos7 ~]# yum install -y stress# 帮助信息
[root@centos7 ~ 14:15:51]# stress --help
`stress' imposes certain types of compute stress on your systemUsage: stress [OPTION [ARG]] ...-?, --help show this help statement--version show version statement-v, --verbose be verbose-q, --quiet be quiet-n, --dry-run show what would have been done-t, --timeout N timeout after N seconds--backoff N wait factor of N microseconds before work starts-c, --cpu N spawn N workers spinning on sqrt()-i, --io N spawn N workers spinning on sync()-m, --vm N spawn N workers spinning on malloc()/free()--vm-bytes B malloc B bytes per vm worker (default is 256MB)--vm-stride B touch a byte every B bytes (default is 4096)--vm-hang N sleep N secs before free (default none, 0 is inf)--vm-keep redirty memory instead of freeing and reallocating-d, --hdd N spawn N workers spinning on write()/unlink()--hdd-bytes B write B bytes per hdd worker (default is 1GB)Example: stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10sNote: Numbers may be suffixed with s,m,h,d,y (time) or B,K,M,G (size).
压力测试-CPU
# 消耗2个CPU
[root@centos7 ~ 14:17:19]# stress -c 2
stress: info: [2595] dispatching hogs: 2 cpu, 0 io, 0 vm, 0 hdd# top 监控
top - 14:18:22 up 47 min, 2 users, load average: 1.37, 0.50, 0.47
Tasks: 187 total, 4 running, 183 sleeping, 0 stopped, 0 zombie
%Cpu(s):100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 4026124 total, 1535676 free, 490668 used, 1999780 buff/cache
KiB Swap: 4063228 total, 4063228 free, 0 used. 3277584 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2596 root 20 0 7312 100 0 R 100.0 0.0 1:01.42 stress 2597 root 20 0 7312 100 0 R 100.0 0.0 1:01.25 stress 2594 root 20 0 162100 2320 1588 R 0.6 0.1 0:00.12 top
......
压力测试-内存
# 消耗前内存
[root@centos7 ~ 14:21:06]# free -mtotal used free shared buff/cache available
Mem: 3931 478 1500 14 1952 3201
Swap: 3967 0 3967# 消耗 1G 内存
[root@centos7 ~ 14:19:11]# stress -m 1 --vm-bytes 1G
stress: info: [2623] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd# 消耗后内存
[root@centos7 ~ 14:21:44]# free -mtotal used free shared buff/cache available
Mem: 3931 1403 575 14 1952 2274
Swap: 3967 0 3967
压力测试-磁盘
# 消耗磁盘IO
[root@centos7 ~ 14:22:21]# stress -d 1 --hdd-bytes 2G# 监视活动状态百分比,%util
[root@centos7 ~ 14:23:31]# sar -dp 1
......
14时23分29秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
14时23分30秒 sda 2699.00 0.00 2762752.00 1023.62 6.11 2.26 0.29 79.50
14时23分30秒 sr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时23分30秒 centos-root 2698.00 0.00 2761728.00 1023.62 6.11 2.26 0.29 79.50
14时23分30秒 centos-swap 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时23分30秒 centos-home 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
......
网络测试
# 传送一个大size的文件
[root@centos7 ~ 14:27:17]# wget http://192.168.43.100/isos/CentOS-7-x86_64-DVD-2207-02.iso# 监控带宽
[root@centos7 ~ 14:29:13]# sar -n DEV 1
......
14时29分07秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
14时29分08秒 ens32 69961.00 5404.00 96338.71 513.95 0.00 0.00 0.00
14时29分08秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时29分08秒 virbr0-nic 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时29分08秒 virbr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
......
监控总结
以下是针对 Linux 系统监控的几条实用建议,涵盖关键监控维度和最佳实践:
- 核心指标实时监控
重点跟踪 CPU 使用率(用户态 / 系统态占比)、内存占用(含缓存 /swap 使用率)、磁盘 I/O(读写吞吐量、IOPS)和网络流量(带宽利用率、连接数)。可通过top/htop(实时)、vmstat/iostat(系统级)等工具快速查看。 - 部署专业监控工具
对于服务器集群或长期监控需求,建议使用 Prometheus + Grafana(可视化强)、Zabbix(全功能监控)或 Nagios(轻量告警)等工具,实现指标集中收集、趋势分析和历史数据查询。 - 设置关键阈值告警
针对核心指标配置告警阈值(如 CPU 持续 5 分钟超 80%、磁盘空间不足 10%),通过邮件、短信或即时通讯工具推送告警,避免故障扩大。注意避免告警风暴(可设置告警合并或延迟)。 - 监控进程与服务状态
定期检查关键服务(如 Nginx、MySQL)的运行状态、进程数及资源消耗,可通过systemctl status或自定义脚本实现。对异常退出的进程,结合日志排查崩溃原因。 - 日志集中管理与分析
将系统日志(/var/log/messages)、应用日志集中存储(如使用 ELK 栈),关注错误信息(ERROR级别)、登录异常(/var/log/auth.log)和磁盘错误(dmesg | grep error),必要时配置日志告警规则。 - 磁盘健康监控
除空间使用率外,需关注磁盘坏块(smartctl工具检测 S.M.A.R.T 信息)和文件系统完整性(定期运行fsck,非挂载状态下),避免硬件故障导致数据丢失。 - 网络与安全监控
监控端口开放状态(netstat/ss)、异常连接(尤其是外部 IP 的高频访问)和防火墙规则生效情况。可结合tcpdump抓包分析可疑流量。 - 定期性能基线分析
记录系统正常运行时的指标基线(如平均负载、内存使用峰值),当指标偏离基线时及时排查,避免微小异常累积成故障。 - 自动化监控脚本
对个性化需求(如特定目录文件数、应用响应时间),编写 Shell 或 Python 脚本定期执行检查,输出结果至监控系统或直接触发告警。 - 监控权限与安全
限制监控工具的权限(如仅授予读取日志和指标的权限),加密传输监控数据,防止监控系统本身成为安全薄弱点。
通过分层监控(基础指标→服务状态→业务性能)和主动预警,可显著提升系统稳定性和故障响应效率。