C++手撕简单KNN
背景
很久以前,“小H,这个方向你来做一下吧,反正大家都没做过。” LD就是这样说道,就让小H一个完全不懂机器学习的人去做这个任务。
“什么是机器学习啊?”小H小小的脑袋里面有大大的疑惑,一番搜索之后找到了某些入门视频就开始看了,最早看到的就是K邻近算法了,那就先用这个试试。
概念
KNN(K-Nearest Neighbors,K - 近邻算法)是一种简单、直观的监督学习算法,主要用于分类任务,也可用于回归任务(本文只做回归任务的讨论)。它的核心思想是:“物以类聚,人以群分”,即一个样本的类别(或数值)可以由它周围最近的 K 个邻居的类别(或数值)来决定。(-来自豆包)
原理
- 要知道谁和当前需要预测的最近,那就要知道所有人到自己的距离,常用的距离就有欧氏距离、曼哈顿距离
- 确定K值,我们只要K个最近的。当然不同的K值可能有不同的效果,所以后面需要不断调整找到最优的K值。
- 投票!找到已有的K个邻居,统计他们的类别,选出类别最多的作为预测结果
代码
python
当然小H还是知道机器学习大家都是用python写的,所以也上网学习了一下,然后搞出以下的东西:
df = pd.read_csv(file_path)
#print(df.shape)
X = df.iloc[:,:88].values
y = df.iloc[:,88].valuesX_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42,stratify=y)train_df = pd.DataFrame(X_train)
train_df['label']=y_train#print(train_df['label'].value_counts())
min_count = train_df['label'].value_counts().min()balanced_train_df = pd.DataFrame()for label in train_df['label'].unique():# 按标签筛选样本label_samples = train_df[train_df['label'] == label]# 随机选择min_count个样本downsampled = label_samples.sample(n=min_count, random_state=42)# 添加到平衡后的数据集balanced_train_df = pd.concat([balanced_train_df, downsampled], ignore_index=True)#print(balanced_train_df['label'].value_counts())
X_train_balanced = balanced_train_df.iloc[:, :-1].values
y_train_balanced = balanced_train_df['label'].valuesscaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train_balanced)
X_test_scaled = scaler.transform(X_test)best_k = 2
knn = KNeighborsClassifier(n_neighbors=best_k,n_jobs=-1)
knn.fit(X_train_scaled, y_train_balanced)默认采用的是欧氏距离,为了防止某个参数影响太大(看欧氏距离公式可知)所以数据输入前要进行归一化,由于小H得到的数据分布很不均衡,所以对过多的数据进行降采样(可能是这个名词吧,实际上就是把数据较多的数据随机丢弃一些),因为你想数据多的标签就很容易被选到了。
best_K是小H经过(1-20)尝试后得到比较好的结果试出来的。如下图(当然他是一个很糟糕的图片):
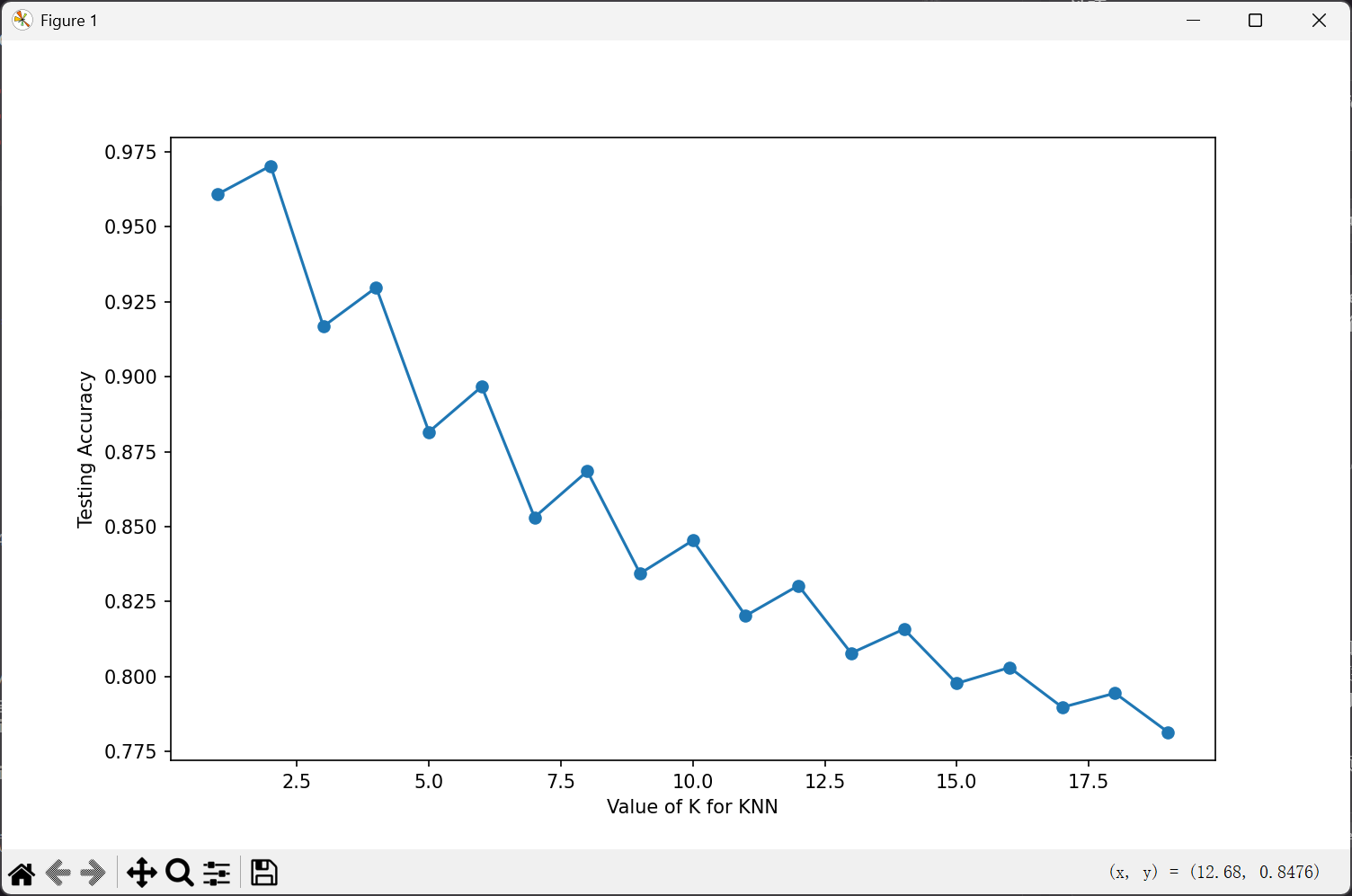
到这里小H就兴高采烈拿着其他测试数据过来一试,糟糕,ACC只有60%,那这个方案就宣告OVER了。
这个图片可能是因为KNN只适用于维度较低的数据集,可能造成了维度灾难,导致基本只依赖于前面1,2的数据。
不过看起来也没太多内容,所以小H决定用最爱的C++也简单实现一下。
C++
struct Sample{std::vector<double> features;int label;Sample(std::vector<double> feat,int lab):features(std::move(feat)),label(lab){}
};class KNNClassifier{
public:explicit KNNClassifier(int k=3):K(k){if(k<=0){throw std::invalid_argument("k is not acc");}}~KNNClassifier(){;}void fit(const std::vector<Sample>& data){train_data=data;}int predict(const Sample& sample) const{if(train_data.empty()){throw std::runtime_error("haven't train_data");}if(sample.features.empty()){throw std::invalid_argument("error features");}std::vector<std::pair<double,int>> dist_label;for(const auto& train_sample:train_data){double dist = euclideanDistance(sample,train_sample);dist_label.emplace_back(std::make_pair(dist,train_sample.label));}std::sort(dist_label.begin(),dist_label.end(),[](const auto& a,const auto& b){return a.first<b.first;});std::map<int,int> label_count;for(int i=0;i<K;++i){label_count[dist_label[i].second]++;}int best_label = -1;int max_count = 0;for(const auto& [label,count]:label_count){if(count > max_count){max_count = count;best_label = label;}}return best_label;}std::vector<int> predict(const std::vector<Sample>& samples) const {std::vector<int> results;for (const auto& sample : samples) {results.push_back(predict(sample));}return results;}private:const int K;std::vector<Sample> train_data;// 采用欧氏距离double euclideanDistance(const Sample& a,const Sample& b) const{if(a.features.size()!=b.features.size()){throw std::invalid_argument("feature nums error");}double dist = 0.0;for(size_t i=0;i<a.features.size();i++){dist += std::pow(a.features[i]-b.features[i],2);}return std::sqrt(dist);}};虽然这个方向失败了,不过机器学习对于小H来说还是一个基本完全未知的领域,怎么数据清理、怎么样选取模型、怎么样调整参数,其实我完全都不懂!
本章如果代码上有任何问题可以和博主说一下QAQ。