Druid数据库连接池
原生的jdbc,每次查询都会创建新的连接对象
package com.ruoyi.deno;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;/*** User: ldj* Date: 2025/7/31* Time: 19:20* Description: No Description*/
public class JdbcExample {public static void main(String[] args) {Connection conn = null;Statement stmt = null;ResultSet rs = null;try {// 1. 加载JDBC驱动程序Class.forName("com.mysql.cj.jdbc.Driver");// 2. 建立连接String url = "jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8";String user = "root";String password = "password";conn = DriverManager.getConnection(url, user, password);// 3. 创建Statement对象stmt = conn.createStatement();// 4. 执行查询String sql = "SELECT id, name FROM employees";rs = stmt.executeQuery(sql);// 5. 处理结果集while (rs.next()) {int id = rs.getInt("id");String name = rs.getString("name");System.out.println("ID: " + id + ", Name: " + name);}} catch (Exception e) {e.printStackTrace();} finally {// 6. 关闭资源try { if (rs != null) rs.close(); } catch (Exception e) { /* ignored */ }try { if (stmt != null) stmt.close(); } catch (Exception e) { /* ignored */ }try { if (conn != null) conn.close(); } catch (Exception e) { /* ignored */ }}}
}
使用连接池后,会复用连接对象
package com.ruoyi.deno;import com.alibaba.druid.pool.DruidDataSource;import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;/*** User: ldj* Date: 2025/7/31* Time: 19:22* Description: No Description*/
public class DruidJdbcExample {private static DruidDataSource dataSource;static {dataSource = new DruidDataSource();dataSource.setUrl("jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8");dataSource.setUsername("root");dataSource.setPassword("password");// 其他配置...}public static void main(String[] args) throws Exception {Connection conn = null;PreparedStatement pstmt = null;ResultSet rs = null;try {// 从连接池中获取连接 (是代理对象Proxy)conn = dataSource.getConnection();// 准备SQL语句String sql = "SELECT id, name FROM employees WHERE id = ?";pstmt = conn.prepareStatement(sql);pstmt.setInt(1, 1); // 设置参数// 执行查询rs = pstmt.executeQuery();// 处理结果集while (rs.next()) {int id = rs.getInt("id");String name = rs.getString("name");System.out.println("ID: " + id + ", Name: " + name);}} finally {// 关闭资源if (rs != null) rs.close();if (pstmt != null) pstmt.close();// 注意这里的close()实际上是把连接归还给连接池 (因为 Druid 返回给你的 Connection 对象,是一个“伪装者”(代理对象),它把 .close() 这个动作“偷梁换柱”了)if (conn != null) conn.close();}}
}
补充:springboot 整合Druid的配置文件,这里有扩展的功能读写分离、开启慢sql记录,按照以往的做法是直接修改MySQL 配置文件 (my.cnf 或 my.ini)
你可以编辑 MySQL 的配置文件来启用慢查询日志
[mysqld]
slow_query_log = 1
slow_query_log_file = /path/to/your/slow-query.log
long_query_time = 2 # 设置慢查询的时间阈值,单位秒
log_queries_not_using_indexes = 1 # 是否记录未使用索引的查询现在不需要那样干了,直接在application.yml修改就行
# 数据源配置
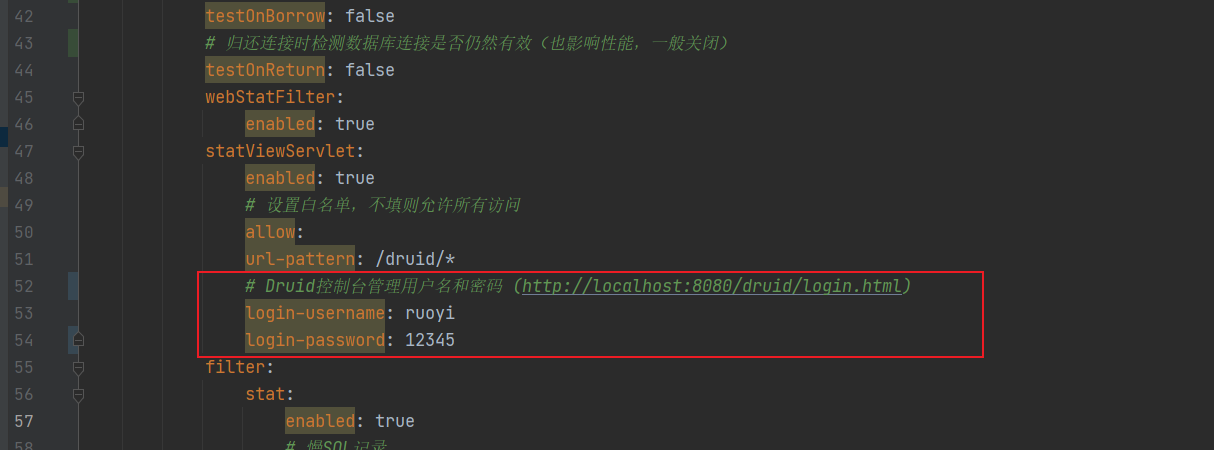
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.cj.jdbc.Driverdruid:# 主库数据源 (修改自己的地址、账号、密码)master:url: jdbc:mysql://192.168.208.110:3306/ruoyi?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8username: rootpassword: root# 从库数据源slave:# 从数据源开关/默认关闭enabled: falseurl: username: password: # 初始连接数initialSize: 5# 最小连接池数量minIdle: 10# 最大连接池数量maxActive: 20# 配置获取连接等待超时的时间maxWait: 60000# 配置连接超时时间connectTimeout: 30000# 配置网络超时时间socketTimeout: 60000# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒timeBetweenEvictionRunsMillis: 60000# 配置一个连接在池中最小生存的时间,单位是毫秒minEvictableIdleTimeMillis: 300000# 配置一个连接在池中最大生存的时间,单位是毫秒maxEvictableIdleTimeMillis: 900000# 配置检测连接是否有效 'SELECT 1 FROM DUAL' 是 Oracle/MySQL 的通用心跳语句validationQuery: SELECT 1 FROM DUAL# 空闲时检测连接是否有效(推荐开启)testWhileIdle: true# 从池中取出连接时检测数据库连接是否仍然有效(影响性能,通常关闭)testOnBorrow: false# 归还连接时检测数据库连接是否仍然有效(也影响性能,一般关闭)testOnReturn: falsewebStatFilter: enabled: truestatViewServlet:enabled: true# 设置白名单,不填则允许所有访问allow:url-pattern: /druid/*# Druid控制台管理用户名和密码 (http://localhost:8080/druid/login.html)login-username: ruoyilogin-password: 12345filter:stat:enabled: true# 慢SQL记录log-slow-sql: trueslow-sql-millis: 1000merge-sql: truewall:config:multi-statement-allow: true整合spring-boot注意的地方:排除SpringBoot数据源自动配置类
/*** 启动程序** @author ruoyi* DataSourceAutoConfiguration 检查你有没有配置数据库连接(如 spring.datasource.url, username, password)* 如果有,就自动创建一个 DataSource Bean(通常是 HikariCP 连接池), 让你的应用可以直接使用数据库(比如配合 JPA、MyBatis 等)* 我现在使用的Druid的连接池,不要SpringBoot默认的配置的 HikariCP*/
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class RuoYiApplication {public static void main(String[] args) {// System.setProperty("spring.devtools.restart.enabled", "false");SpringApplication.run(RuoYiApplication.class, args);System.out.println("(♥◠‿◠)ノ゙ 若依启动成功 ლ(´ڡ`ლ)゙ \n" +" .-------. ____ __ \n" +" | _ _ \\ \\ \\ / / \n" +" | ( ' ) | \\ _. / ' \n" +" |(_ o _) / _( )_ .' \n" +" | (_,_).' __ ___(_ o _)' \n" +" | |\\ \\ | || |(_,_)' \n" +" | | \\ `' /| `-' / \n" +" | | \\ / \\ / \n" +" ''-' `'-' `-..-' ");}
}
场景1:如果你已经写了一个配置类来创建 DataSource Bean:
@Configuration
public class DataSourceConfig {@Beanpublic DataSource dataSource() {DruidDataSource dataSource = new DruidDataSource();dataSource.setUrl("jdbc:mysql://localhost:3306/mydb");dataSource.setUsername("root");dataSource.setPassword("123456");return dataSource;}
}这时候,Spring Boot 的 DataSourceAutoConfiguration 也想创建一个 DataSource(默认是 Hikari),就会导致:
❌ 报错:有多个 DataSource Bean,不知道该注入哪一个
场景2:只要你引入了 spring-boot-starter-jdbc 或 mybatis-spring-boot-starter或者mybatis-plus,Spring Boot 就会尝试自动配置数据源。如果没有排除,启动时会报错:
❌
Failed to configure a DataSource: 'url' attribute is not specified
解决办法:排除自动配置,告诉 Spring Boot:“别管数据库了,我自己来!”
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})Druid 还提供功能非常强大的可视化监控面板,账号和密码自定义(http://localhost:8080/druid/login.html)