【AI落地应用实战】基于 Amazon Bedrock + DeepSeek构建 GraphRAG 应用程序
目录
- 一、架构解析
- 二、环境准备
- 三、实践流程
- 3.1、构建RAG 知识库
- 3.2、配置模型权限
- 3.3、测试使用
- 3.4、清理资源
- 四、总结
新用户可获得高达 200 美元的服务抵扣金
亚马逊云科技新用户可以免费使用亚马逊云科技免费套餐(Amazon Free Tier)。注册即可获得 100
美元的服务抵扣金,在探索关键亚马逊云科技服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用亚马逊云科技服务,最长可达 6
个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项亚马逊云科技服务的访问权限。
在当今竞争激烈的商业环境中,企业越来越倾向于采用人工智能优先的策略以保持竞争力和提高效率。随着生成式人工智能的应用日益普及,其解决问题的能力也在不断增强。面对日益复杂的待解决难题,图作为一种数据模型,能够高效地对关系进行建模,并从相互关联的数据和实体中提取有意义的见解。
在本篇博文中,我们将探索如何利用基于图的检索增强生成(GraphRAG)技术在 Amazon Bedrock 知识库中构建智能应用。
一、架构解析
与传统的基于相似度分数检索文档的向量搜索不同,知识图谱通过编码实体之间的关系,使大型语言模型(LLMs)能够以具有上下文感知能力的方式检索信息。而GraphRAG 的核心价值在于提升知识检索和推理能力,其通过利用知识图谱,将信息结构化为实体及其相互关系来实现这一点。与仅依赖于向量搜索或关键词匹配的传统 RAG 方法不同,GraphRAG 支持多跳推理(不同上下文片段之间的逻辑连接)、更好的实体链接以及上下文检索。
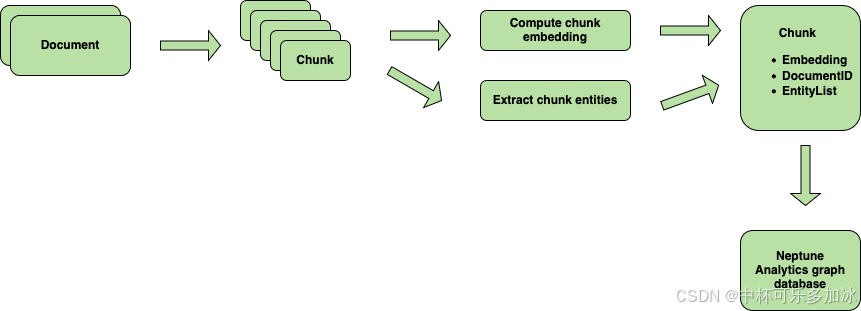
Amazon Bedrock 知识库的 GraphRAG 功能使得大型语言模型能够理解实体、事实和概念之间的关系,从而使响应更加符合上下文且更具可解释性。通过将数据表示为节点(实体)和节点之间的边(关系),构建图模型。基于 Amazon Bedrock 知识库的 GraphRAG 应用程序中,这里设计了一个简化的流程,将原始文档转换为丰富的、相互关联的知识图。
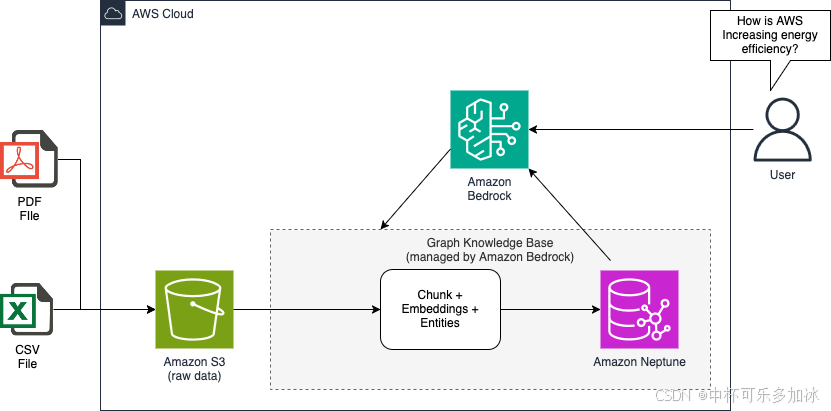
它的工作原理如下:
- 文档提取:用户可以手动将文档上传到 Amazon S3 或设置自动提取管道。
- 块、实体提取和嵌入生成:在知识库中,首先使用固定大小的分块或可自定义的方法将文档拆分为块,然后为每个块计算嵌入。最后,系统会提示 LLM 从每个块中提取关键实体,创建一个包含实体列表、块嵌入、块文本和文档 ID 的 GraphDocument。
- 图构建:嵌入以及提取的实体及其关系用于构建知识图谱。构建的图形数据,包括节点(实体)和边缘(关系),会自动插入到 Amazon Neptune 中。
- LLM 驱动的应用程序:最后,用户可以通过 Amazon Bedrock 利用 LLM 来查询图表并检索文档中的相关信息。这可以实现强大的上下文感知响应,从整个摄取文档语料库中获取见解。
二、环境准备
在开始部署之前,需要准备一个亚马逊云科技账号,首先进入亚马逊云科技官网,点击注册账号,输入邮箱并验证。
点击下一步,输入用户名和密码:
填写手机号,信用卡或者借记卡号进行绑定并选择手机验证方式,亚马逊云科技提供了多种付款方式,包括信用卡和预付费等选项,以满足不同用户的需求。

除此之外,还需要创建一个 S3 存储桶以将文件存储在亚马逊云科技上,然后将PDF 和 XLS 私有知识库文件上传到 S3 存储桶中。
三、实践流程
3.1、构建RAG 知识库
下面开始构建RAG的知识库,首先打开亚马逊云科技控制台,搜索Amazon Bedrock,在导航窗格的知识库下,选择创建,然后进入Knowledge Bases。
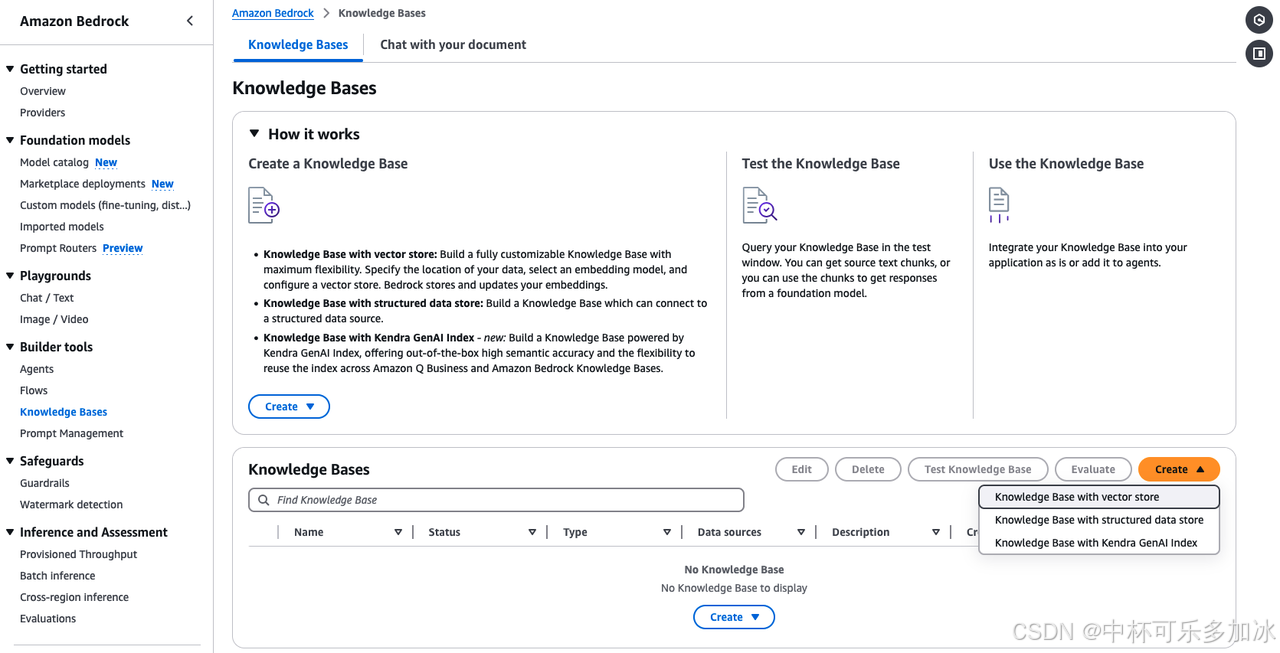
接着,在出现的选项中选择 “具有矢量存储的知识库”,之后再点击 “创建” 按钮,在该界面中,输入知识库名称,例如 knowledge-base-graphrag-demo,也可以添加可选的说明来进一步描述该知识库。在设置服务角色时,选择 “创建并使用新的服务角色”。
数据源的选择设定为 Amazon S3,并将其他所有选项都保留为默认值,随后点击 “下一步” 以继续操作。接下来输入数据源名称,这里输入 knowledge-base-graphrag-data-source。
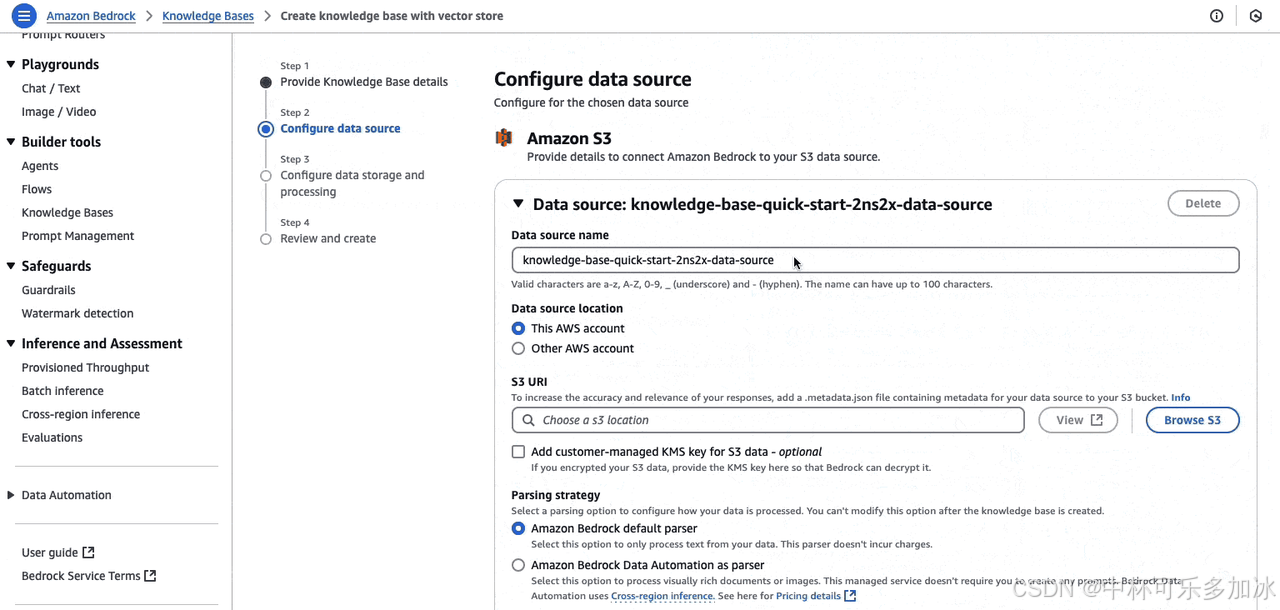
然后通过点击 “浏览 S3” 来选择相应的 S3 存储桶。如果账户中尚未有 S3 存储桶,则需要先创建一个,并确保将所有必要的文件都上传至该存储桶。完成 S3 存储桶的创建及文件上传后,选中该存储桶,比如名为 blog-graphrag-s3的存储桶,再次保留其他所有设置为默认值,并点击 “下一步” 按钮。
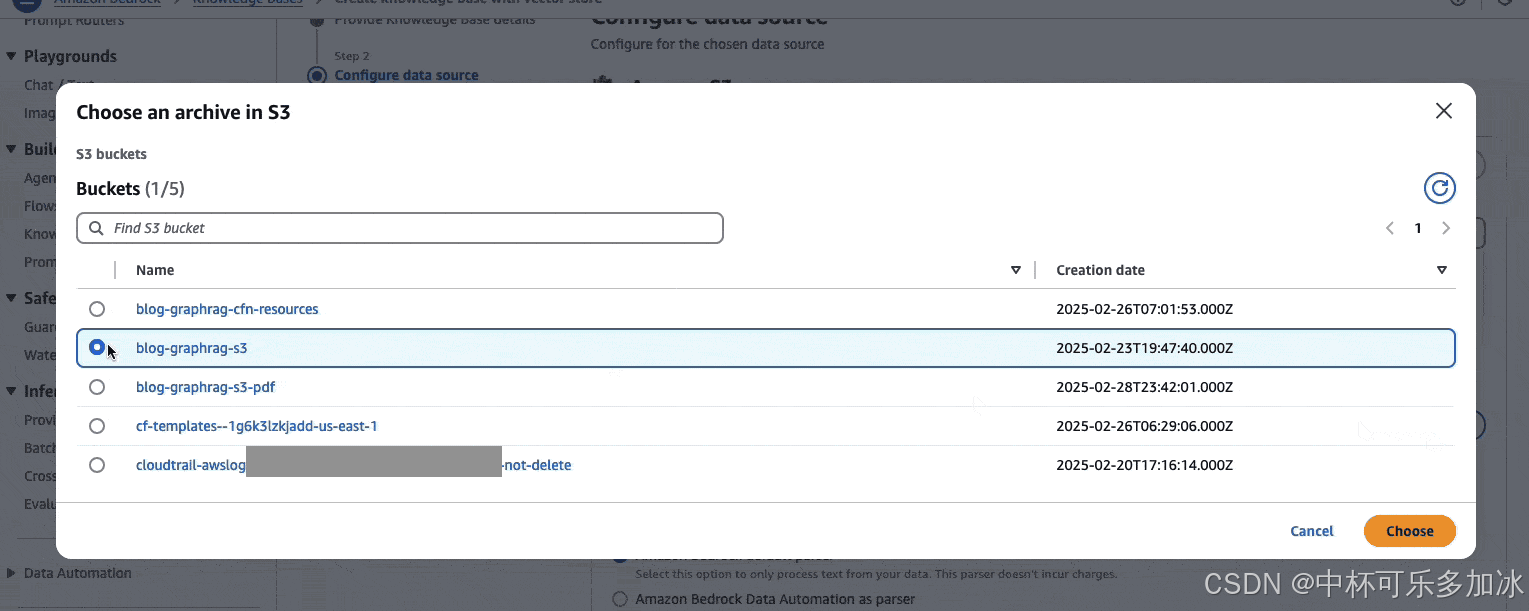
在后续的设置中,选择 “选择模型”,并从选项中挑选嵌入模型,这里以选择 Titan 文本嵌入 V2 模型为例。在矢量数据库部分,于矢量存储创建方法处选择 “快速创建新的矢量存储”,对于矢量存储的具体选择,则是选定 Amazon Neptune Analytics(GraphRAG),然后点击 “下一步” 继续。

需要留意的是,知识库在 Amazon Bedrock 上的创建过程可能会耗费几分钟时间,等待片刻,待知识库成功创建完成后,其状态显示为 “可用”即成功创建了GraphRAG知识库。
3.2、配置模型权限
在开始测试知识库之前,需要配置模型。这里,首先进入Bedrock控制台,在这里我们可以看到Amazon Bedrock支持多个基础模型(foundation model),其中包括Amazon Titan,Claude,Jurassic,Command,Stable Diffusion 以及 Llama2。
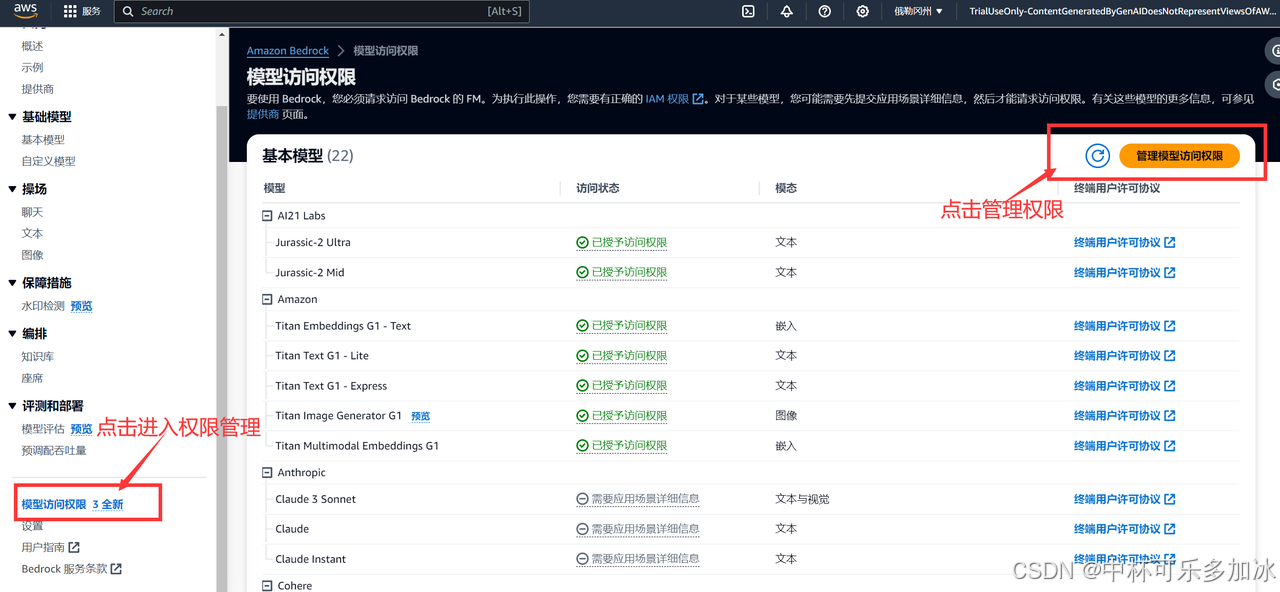
登录后,还需要对Amazon Bedrock中的模型进行授权,对于某些模型,可能首先需要提交用例详细信息,然后才能请求访问。这里点击模型访问权限——管理模型访问权限:
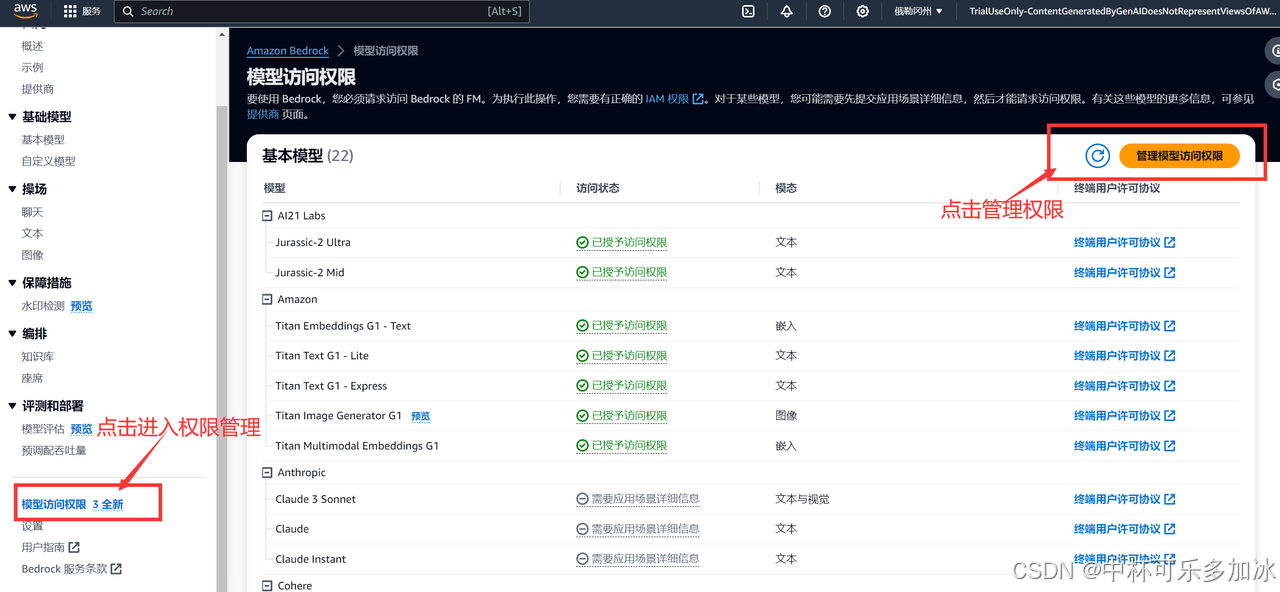
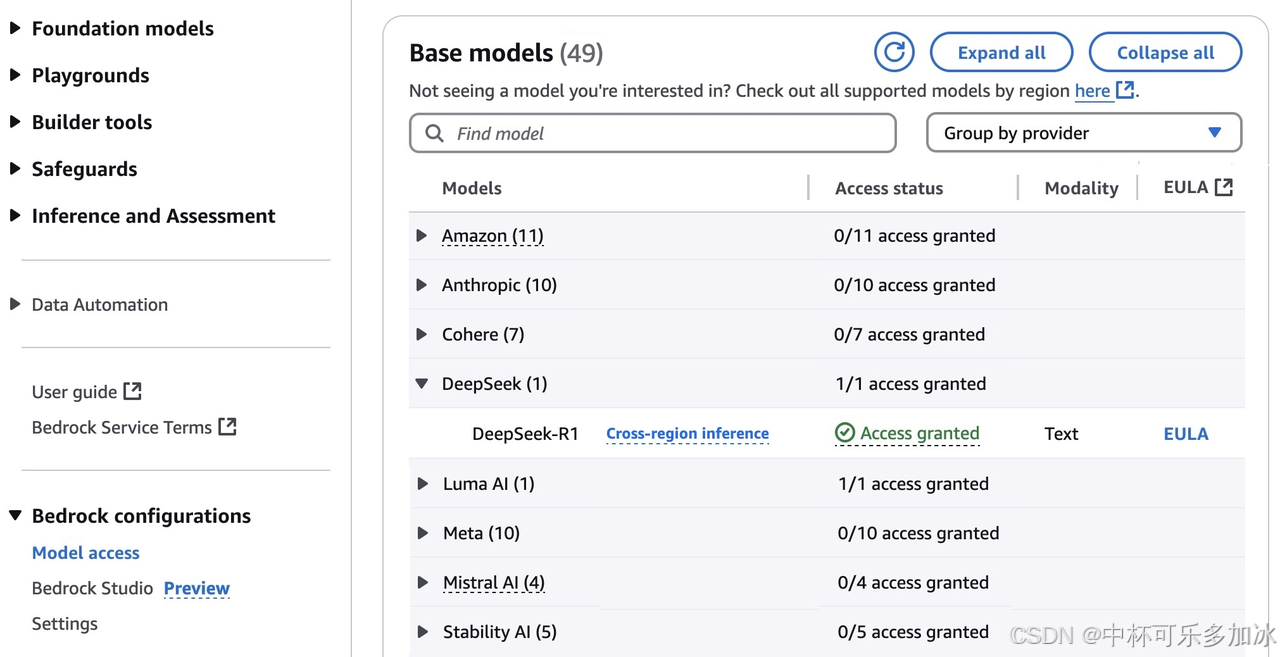
勾选打开deepseek:
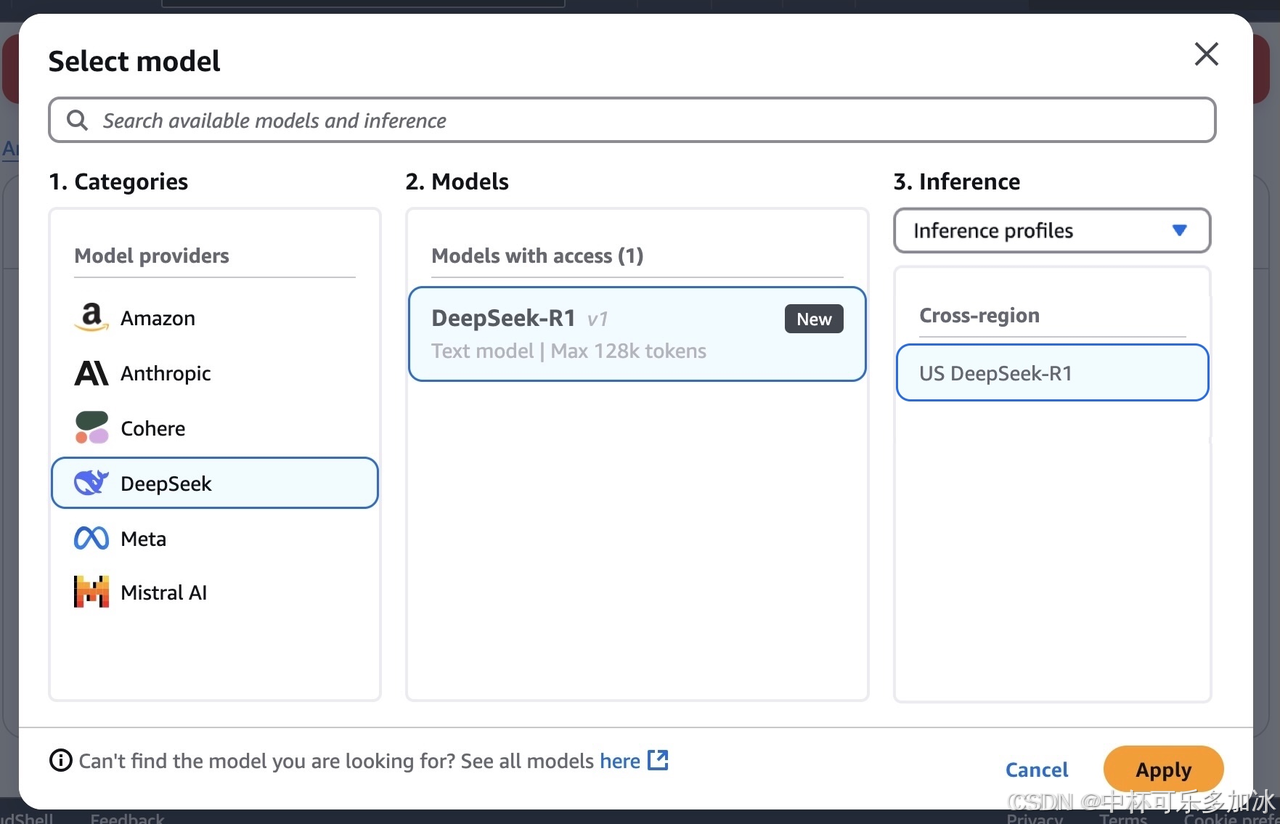
接下来在 Amazon Bedrock 中测试 DeepSeek-R1 模型了,请在左侧菜单窗格的 Playgrounds 下选择 聊天/文本。然后在左上角选择选择模型,在类别中选择 DeepSeek,在模型中选择 DeepSeek-R1。选择应用。
3.3、测试使用
完成知识库的配置和模型的配置后,就可以正式开始使用了,点击Knowledge Bases选择我们刚刚创建好的知识库,然后,就可以在最右侧进行使用了,比如这里,我们提出了一个更复杂的问题,即亚马逊云科技如何提高能效?
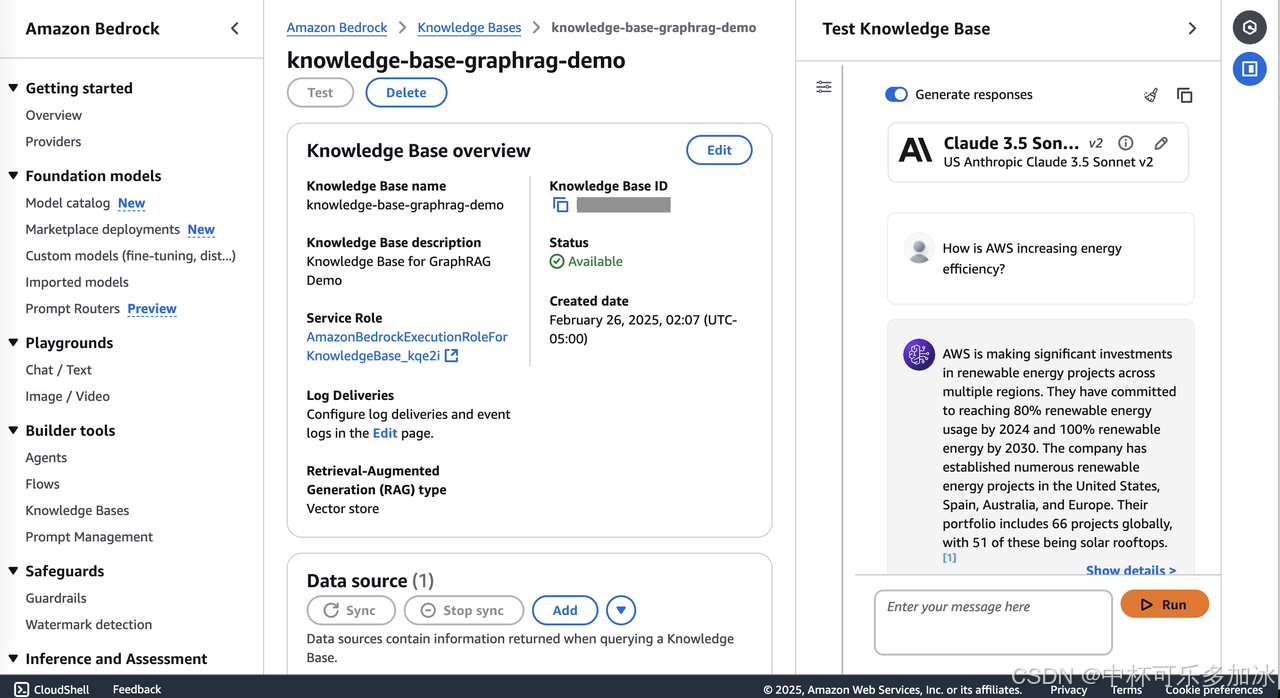
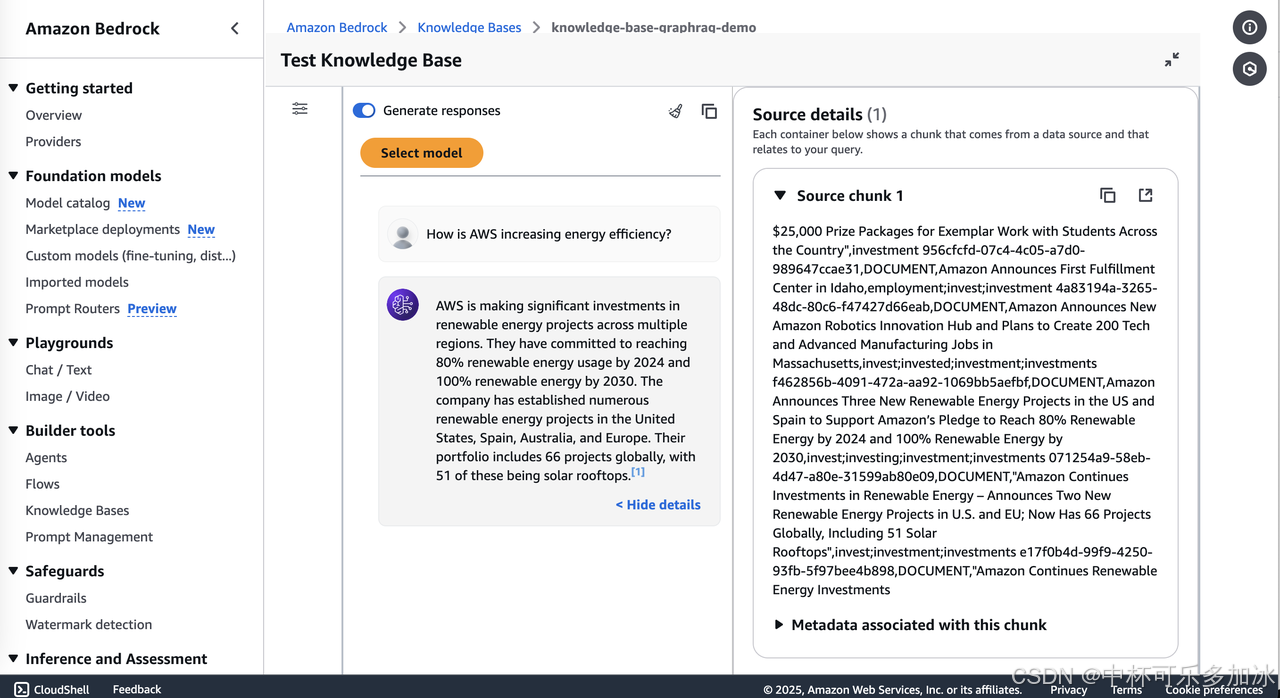
RAG程序根据知识库的内容,回答了亚马逊云科技在可再生能源项目上的投资情况,包括其在不同地区建立的项目数量、类型等详细信息。选择 Show details (显示详细信息),可以看到与其关联的知识库条目。
3.4、清理资源
实验结束后要记得清理资源,如果决定不再使用服务的话,记得要在控制台关闭服务,从 Amazon S3 存储桶中删除知识库:blog-graphrag-s3以防超过免费额度产生扣费:
四、总结
总结来说,GraphRAG 技术在 Amazon Bedrock 知识库中的应用,为企业提供了一种高效、智能的数据处理和知识提取方式。这一技术不仅能够提升信息检索的准确性和相关性,还能够通过强大的上下文感知能力,为用户提供进一步的洞察能力。随着企业对数据驱动决策的依赖不断增加,GraphRAG 技术无疑将在未来的商业环境中扮演越来越重要的角色。