Linux核心转储(Core Dump)原理、配置与调试实践
核心转储(Core Dump)是操作系统在程序异常终止时生成的一个文件,包含了程序崩溃时的内存状态、寄存器值、堆栈信息等关键数据。它是调试程序崩溃原因的重要工具。
目录
一、 核心转储
1、核心转储的概念
2、名称由来
3、核心转储包含的内容
4、核心转储的作用
5、生成核心转储的条件
6、云服务器中的核心转储配置(重要!!!)
1. 检查当前 core dump 设置
2. 临时开启 core dump(仅当前终端会话有效)
3. 临时关闭core文件(当前会话有效):
4. core文件默认可能被禁止,需要管理员权限开启
5. core文件可能包含敏感信息,应注意处理
6. 查看当前所有的资源限制配置
7. 启用核心转储
8. 问题根源深度分析
9. 命令执行顺序解析
10. 为什么要重定向到这个文件?
11.core_pattern 功能说明表
补充说明
验证命令
12. 为什么不能直接修改?
13. 持久化设置
14. 验证是否生效:应该显示 core.%p
3、核心转储的工作原理
4、核心转储的用途
5、注意事项
二、如何运用核心转储进行调试
1、示例分析
2、调试步骤
3、核心转储调试的优势
4、注意事项
三、Core Dump 标志
1、核心概念
2、进程终止状态的结构
status位的含义
3、示例代码解析
如何启用 core dump
4、实际应用
5、注意事项
一、 核心转储
1、核心转储的概念
核心转储(Core Dump)是指当进程因某些信号而异常终止时,操作系统将该进程的内存状态、寄存器值、堆栈信息等关键数据保存到一个磁盘文件中。这个文件通常命名为core或core.pid(pid为进程ID)。
2、名称由来
"核心"(Core)一词源于早期的磁芯存储器技术,现在泛指内存;"转储"(Dump)指的是将内存内容完整导出到磁盘文件。
3、核心转储包含的内容
-
程序内存映像:包括代码段、数据段、堆和栈
-
处理器寄存器状态:程序计数器、栈指针等
-
线程信息:多线程程序中各线程的状态
-
操作系统信息:信号信息、内存映射等
-
调试符号(如果编译时包含)
4、核心转储的作用
-
事后调试:无需重现崩溃场景即可分析问题
-
远程诊断:可将核心文件发送给开发者分析
-
长期保存:保存崩溃现场供后续分析
-
自动化分析:可用于自动化崩溃报告系统
5、生成核心转储的条件
-
系统配置允许生成:
-
ulimit -c设置不为0 -
/proc/sys/kernel/core_pattern配置正确
-
-
程序未主动阻止:
-
未调用
setrlimit(RLIMIT_CORE, &zero_rlimit) -
未捕获导致崩溃的信号
-
-
有足够的磁盘空间和写入权限
6、云服务器中的核心转储配置(重要!!!)
在大多数云服务器环境中,出于安全和存储空间的考虑,核心转储功能默认是关闭的。我们可以通过以下方式管理和配置:
1. 检查当前 core dump 设置
ulimit -c-
如果输出是
unlimited,表示 core dump 已开启,允许生成任意大小的 core dump 文件。 -
如果输出是
0,表示 core dump 被禁用。
2. 临时开启 core dump(仅当前终端会话有效)
ulimit -c unlimited此命令仅对当前 Shell 会话有效,关闭终端后失效。
从 ulimit -a 输出来看,core file size 的值为 unlimited,这意味着 core dump 功能是开启的,并且允许生成任意大小的 core dump 文件:
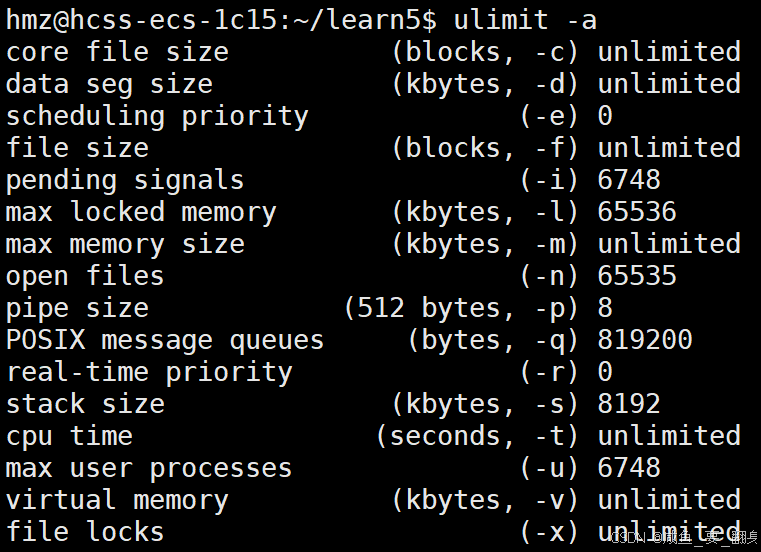
3. 临时关闭core文件(当前会话有效):
ulimit -c 04. core文件默认可能被禁止,需要管理员权限开启
5. core文件可能包含敏感信息,应注意处理
理解这些信号产生方式对于程序开发和系统管理至关重要,特别是在处理程序异常和调试时。
6. 查看当前所有的资源限制配置
ulimit -a 命令用于查看当前 Shell 进程及其子进程的 资源限制配置(Resource Limits)。这些限制由 Linux 内核和 Shell 共同管理,控制进程对系统资源的使用,防止单个进程过度消耗资源导致系统不稳定。
ulimit -a输出示例:
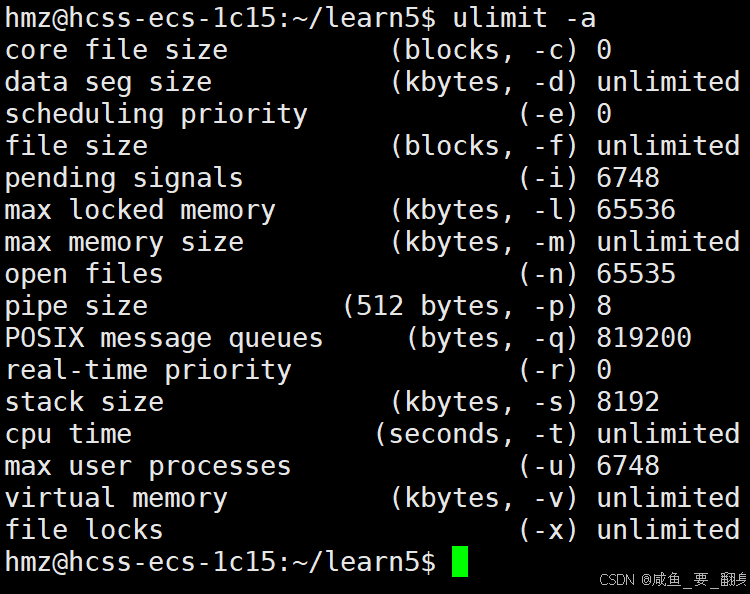
其中core file size为0表示核心转储功能被禁用(已经关闭了)。
7. 启用核心转储
我们可以通过ulimit -c size命令来设置core文件的大小:
ulimit -c unlimited # 设置核心转储文件大小为无限制ulimit -c 1024 # 设置核心转储文件最大为1024KB说明:
ulimit命令改变的是Shell进程的Resource Limit,但demo1进程的PCB是由Shell进程复制而来的,所以也具有和Shell进程相同的Resource Limit值。
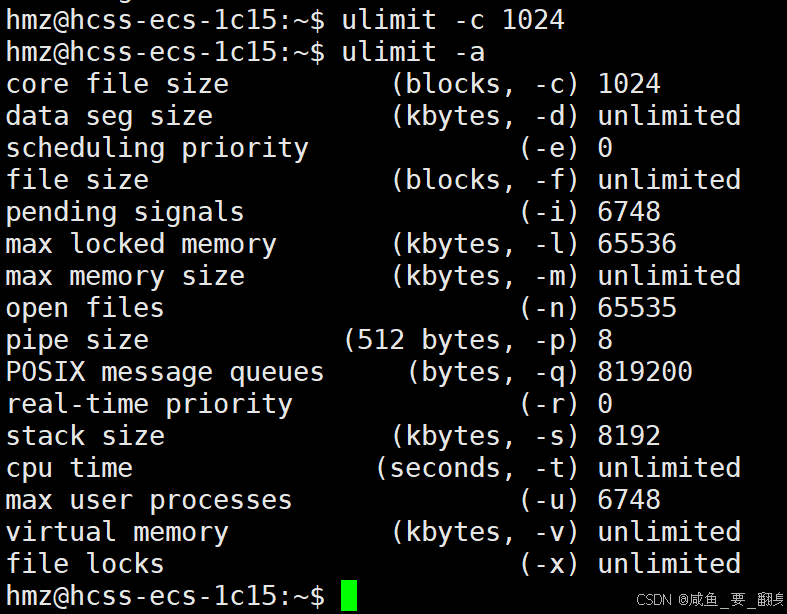
输入查看core dump配置的命令,可见已经成功设置!!!
core文件的大小设置完毕后,就相当于将核心转储功能打开了。此时如果我们再使用Ctrl+\对进程进行终止,就会发现终止进程后会显示core dumped。一般情况来说是会在当前路径下生成一个core文件,该文件以一串数字为后缀,而这一串数字实际上就是发生这一次核心转储的进程的PID。但是我使用的是华为云服务器,生成的地方不同,core dump文件的生成路径不是默认在当前目录的!!!而是在下面这个文件路径中!!!
我们在开启核心转储后,然后执行下面这条命令,状态命令是临时修改的(重启会失效),最后再重新执行这个可执行文件进行Ctrl+\终止进程,生成核心转储文件(core dump)
sudo bash -c 'echo "core.%p" > /proc/sys/kernel/core_pattern'8. 问题根源深度分析
-
权限问题:
/proc/sys/kernel/core_pattern是系统级文件,需要root权限才能修改 -
Shell重定向特性:即使使用
sudo,重定向操作(>)仍以当前用户权限执行 -
华为云可能的安全限制:某些云平台对/proc文件系统有额外保护
9. 命令执行顺序解析
执行流程如下:
-
sudo首先获取 root 权限 -
bash -c启动一个新的 Bash 子 shell -
'echo "core.%p" > /proc/sys/kernel/core_pattern'在新 shell 中执行:-
echo "core.%p"输出字符串core.%p -
>将输出重定向到/proc/sys/kernel/core_pattern -
由于整个命令在
sudo权限下执行,重定向也能以 root 权限完成
-
10. 为什么要重定向到这个文件?
/proc/sys/kernel/core_pattern 是 Linux 内核的一个特殊接口文件,用于控制 core dump 行为:
11.core_pattern 功能说明表
| 功能 | 说明 | 示例 |
|---|---|---|
| 定义生成路径 | 决定 core dump 文件的存放位置(绝对路径或相对路径) | /var/coredump/core.%p |
| 控制命名格式 | 通过占位符自定义文件名: • %p:进程 PID• %e:可执行文件名• %t:时间戳 | core.%e.%p → core.bash.12345 |
| 启用/禁用 | • 空值:禁用 core dump • 以 <code>|</code> 开头的值:禁用并调用处理程序 | ""(空字符串)或 <code>|/path/to/handler</code> |
| 高级处理 | 通过 <code>|</code> 指定外部程序处理 core dump(如压缩、上传、分析) | <code>|/usr/bin/gzip -c > /tmp/core.gz</code> |
补充说明
-
路径规则
-
绝对路径(如
/var/coredump/core):文件会保存在指定目录。 -
相对路径(如
core.%p):文件生成在程序运行时的工作目录。
-
-
常用占位符
占位符 说明 %%单个 %字符%p进程 PID %e可执行文件名(无路径) %t崩溃时间戳(UNIX 时间) %u用户 ID -
特殊值
-
若设置为
core,可能触发某些系统的默认行为(如生成core.PID文件)。 -
若设置为
|/path/to/program,core dump 会通过管道传输给指定程序处理(不会生成文件)。
-
验证命令
# 查看当前配置
cat /proc/sys/kernel/core_pattern# 测试生成 core dump(触发段错误)
kill -SIGSEGV $$
12. 为什么不能直接修改?
直接运行 sudo echo "..." > /proc/sys/... 会失败的原因:
-
Shell 的权限分离:
-
sudo只提升echo的权限 -
重定向操作
>仍由当前用户的 shell 执行 -
/proc/sys/下的文件需要 root 权限写入
-
13. 持久化设置
这个修改是临时的(重启会失效),要永久生效应该:
# 编辑配置文件
sudo nano /etc/sysctl.conf
# 添加一行
kernel.core_pattern=core.%p
# 应用配置
sudo sysctl -p14. 验证是否生效:应该显示 core.%p
cat /proc/sys/kernel/core_pattern所以,文件生成路径可通过/proc/sys/kernel/core_pattern配置。
3、核心转储的工作原理
-
继承机制:子进程会继承父进程的资源限制(Resource Limit),包括核心转储设置
-
信号触发:特定信号(如SIGQUIT、SIGSEGV等)会触发核心转储
-
信息保存:系统保存进程地址空间内容、寄存器状态、内存映射等信息
4、核心转储的用途
核心转储在程序调试和问题诊断中具有重要作用:
-
事后调试:即使程序已经终止,仍可通过core文件分析崩溃时的状态
-
问题复现:保存了程序崩溃瞬间的完整内存状态,便于复现问题
-
错误定位:结合调试器(如gdb)可以:
-
查看崩溃时的调用栈
-
检查变量值
-
分析内存状态
-
定位段错误(Segmentation Fault)的具体位置
-
5、注意事项
-
安全性:core文件可能包含敏感信息,应妥善保管
-
存储空间:大型程序生成的core文件可能很大,需注意磁盘空间
-
生产环境:生产环境中通常限制core文件大小或禁用此功能
-
信号差异:不是所有终止信号都会产生core文件(如SIGINT不会,SIGQUIT会)
核心转储是Linux系统提供给开发者的重要调试工具,合理使用可以显著提高定位和解决程序崩溃问题的效率。
二、如何运用核心转储进行调试
核心转储(core dump)是程序异常终止时操作系统生成的一个包含程序内存状态的文件,它可以帮助开发者进行事后调试(post-mortem debugging)。
1、示例分析
我们有以下示例代码 myproc.c:
#include <stdio.h>
#include <unistd.h>int main()
{printf("I am running...\n");sleep(3);int a = 1/0; // 除零错误return 0;
}2、调试步骤
-
编译程序(确保包含调试信息):
gcc -g myproc.c -o myproc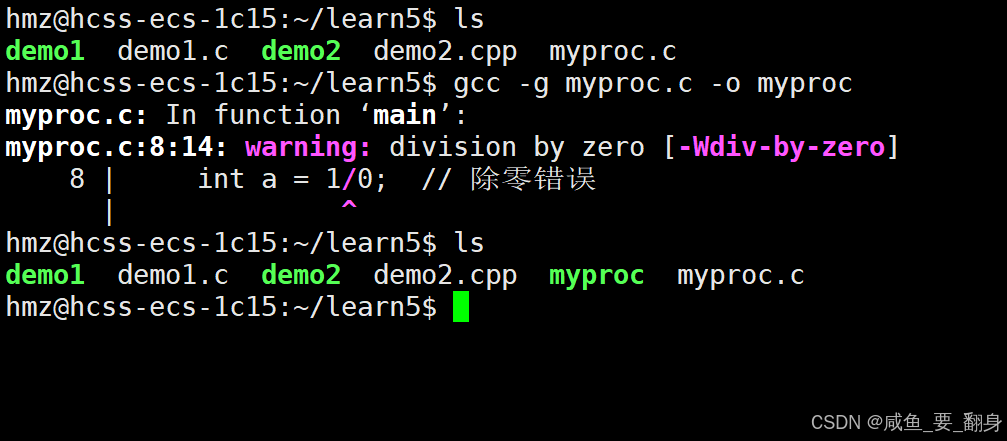
-
运行程序:
./myproc输出:
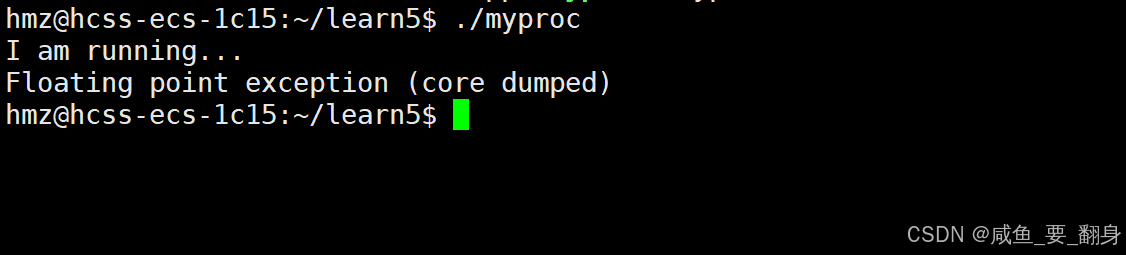
-
查看生成的核心转储文件:

可以看到生成了
core.493097文件(数字是进程ID) -
使用GDB或者CGDB加载核心转储文件:
gdb myproc core.493097或者分步加载:
gdb myproc (gdb) core-file core.493097 -
分析错误:
GDB会显示程序终止时的状态: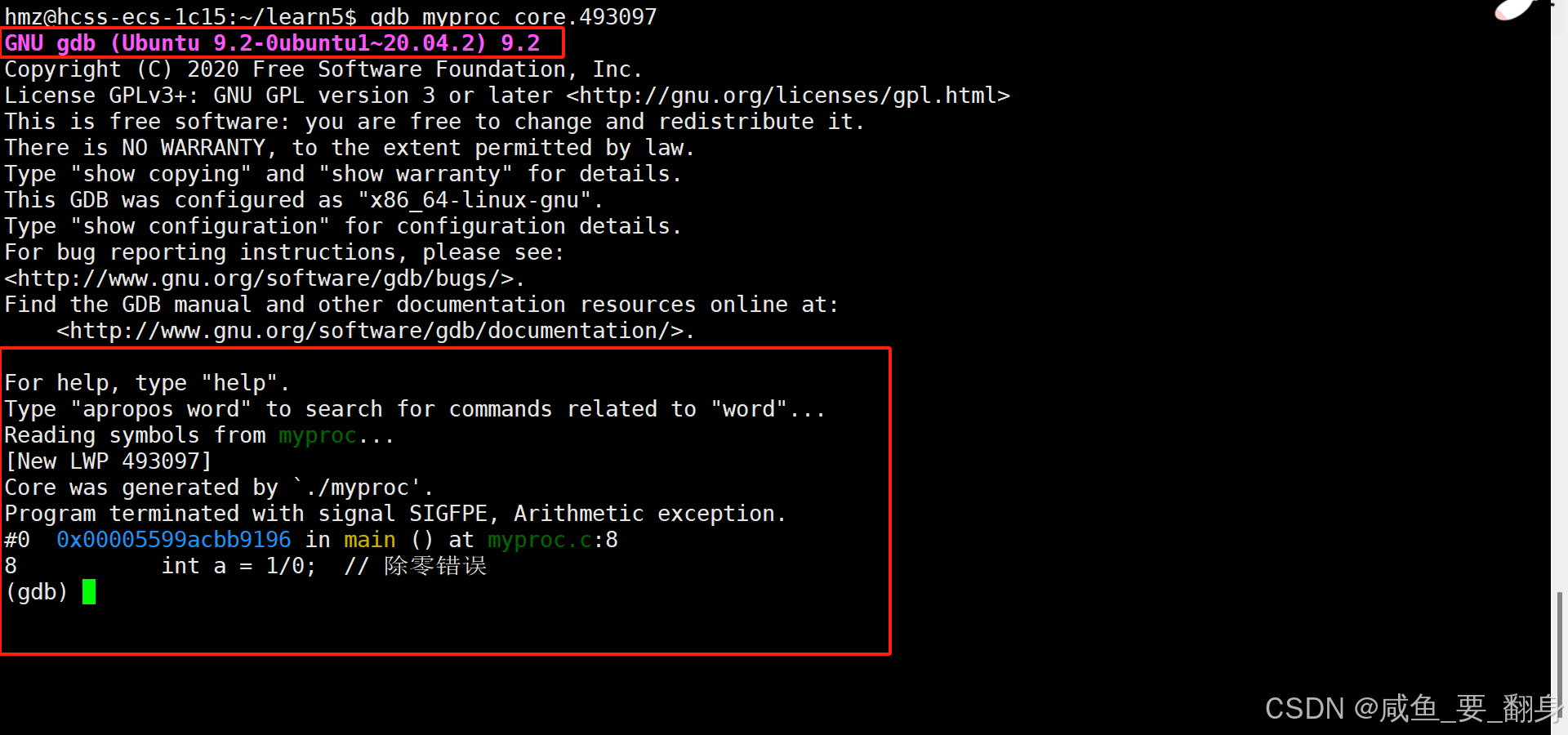
这里明确指出:
-
程序因8号信号(算术异常)终止
-
错误发生在
myproc.c第8行 -
具体错误是除零操作
-
3、核心转储调试的优势
-
无需重现错误:可以直接分析程序崩溃时的状态
-
完整上下文:可以查看崩溃时的变量值、调用栈等信息
-
事后分析:适合生产环境中难以直接调试的场景
4、注意事项
-
确保系统允许生成核心转储文件:
ulimit -c unlimited -
如果核心转储文件没有生成,可能因为:
-
系统限制了核心文件大小
-
程序运行目录没有写入权限
-
系统配置禁止生成核心文件
-
-
编译时务必加上
-g选项以包含调试信息 -
核心文件可能会很大,特别是在处理大型程序时
通过核心转储调试,开发者可以高效地定位程序崩溃的原因,特别是在难以重现的偶发错误场景中,这种事后调试方法尤为有用。
三、Core Dump 标志
1、核心概念
Core dump 标志是进程终止状态信息中的一个重要组成部分,它表示进程在异常终止时是否生成了核心转储文件。(重要!!!)
2、进程终止状态的结构
在Linux进程控制中,waitpid函数用于父进程等待子进程的状态变化:
pid_t waitpid(pid_t pid, int *status, int options); 在 Linux 系统中,waitpid 函数获取的 status 值,该参数是一个输出型参数,用于获取子进程的退出状态。虽然status是一个整型变量,但其不同比特位代表了不同的信息(我们主要关注低16位):

status位的含义
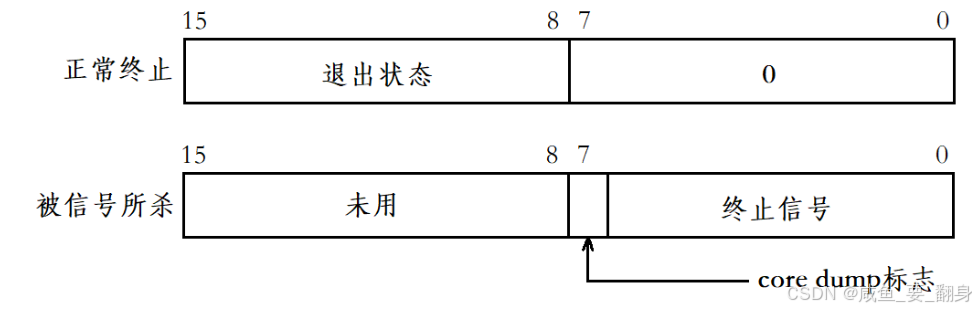
1. 正常终止:
- 次低8位(bit 8-15)表示进程的退出状态(退出码)
- 低7位(0-6位):0
- 第7位(core dump标志):0
2. 信号终止:
- 低7位(bit 0-6)表示终止信号
- 第8位(第7位 即 bit 7)是core dump标志,指示进程终止时是否进行了核心转储(1表示生成了core dump)
- 高8位(8-15位):未使用
3、示例代码解析
打开Linux的核心转储功能,并编写下列代码。代码中父进程使用fork函数创建了一个子进程,子进程所执行的代码当中存在野指针问题,当子进程执行到*p = 100时,必然会被操作系统所终止并在终止时进行核心转储。此时父进程使用waitpid函数便可获取到子进程退出时的状态,根据status的第7个比特位便可得知子进程在被终止时是否进行了核心转储。
下面的代码展示了如何检测 core dump 标志:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>int main()
{if (fork() == 0){//childprintf("I am running...\n");int *p = NULL;*p = 100;exit(0);}//fatherint status = 0;waitpid(-1, &status, 0);printf("exitCode:%d, coreDump:%d, signal:%d\n",(status >> 8) & 0xff, (status >> 7) & 1, status & 0x7f);return 0;
}
如何启用 core dump
-
检查当前 core dump 设置:
ulimit -c -
设置 core 文件大小限制(如设置为1024KB):
ulimit -c 1024 -
运行程序后,如果发生段错误等会导致 core dump 的情况,会在当前目录生成 core 文件:

4、实际应用
-
调试:core dump 文件可以帮助开发者分析程序崩溃时的状态
-
错误分析:通过检查 core dump 标志可以判断程序是否异常终止
-
信号处理:某些信号(如 SIGSEGV)默认会产生 core dump
5、注意事项
-
在某些系统上,可能需要额外配置才能生成 core 文件
-
core 文件可能包含敏感信息,生产环境应谨慎处理
-
core 文件可能会很大,需要合理设置大小限制
通过理解 core dump 标志,开发者可以更好地诊断和处理程序异常终止的情况。