从训练到推理:Intel Extension for PyTorch混合精度优化完整指南
PyTorch作为当前主流的深度学习框架,在计算机视觉和自然语言处理领域得到了广泛应用。其动态计算图机制为构建复杂的深度神经网络提供了灵活性,同时支持CPU和GPU的异构计算环境。
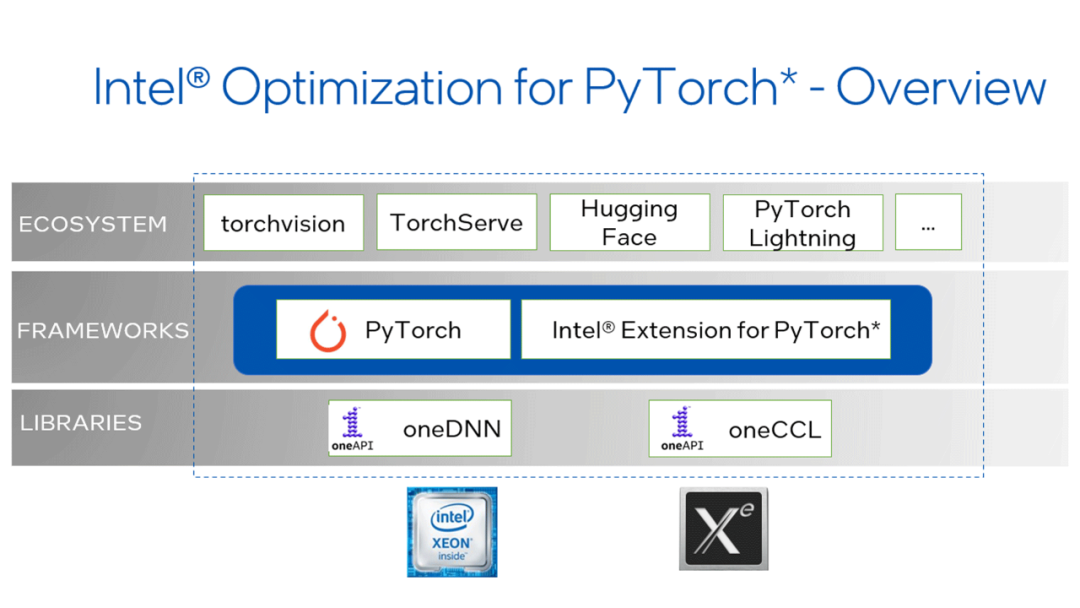
Intel Extension for PyTorch作为官方扩展,专门针对Intel硬件平台进行了深度优化。该扩展不仅提供了最新的性能优化特性,还支持在Intel离散GPU上进行高效的模型训练和推理。特别是其自动混合精度(Auto-Mixed Precision, AMP)功能,能够在保持模型精度的前提下显著提升计算性能。
本文将通过ResNet-50模型在CIFAR-10数据集上的训练和推理实例,详细介绍如何利用Intel Extension for PyTorch在Intel GPU环境下实现自动混合精度优化。
Intel Extension for PyTorch技术架构与优化机制
Intel Extension for PyTorch是Intel为PyTorch生态系统提供的专业级扩展库,旨在充分发挥Intel硬件的计算潜力。该扩展可以作为独立产品部署,也可以集成到Intel AI Tools套件中使用。开发者可以通过Python模块导入或C++库链接的方式来集成该扩展,其中Python用户只需导入intel_extension_for_pytorch模块即可动态启用优化功能。
从技术实现角度来看,Intel Extension for PyTorch分为两个主要分支:CPU优化分支提供针对Intel CPU架构的深度优化,其源代码维护在主分支中;GPU优化分支则专注于Intel GPU加速,相关代码位于xpu-main分支。这种分离式的开发架构确保了各平台优化的专业性和针对性。
该扩展的核心优势在于支持低精度数据格式和专用计算指令集。通过启用float32(FP32)和bfloat16(bf16)的自动混合精度计算,系统能够在保持数值稳定性的同时实现显著的性能提升。
自动混合精度技术原理与实现
自动混合精度是一种先进的数值计算优化技术,通过在训练和推理过程中动态选择合适的数据精度来提升计算效率。该技术的核心思想是利用bf16和float16等低精度数据类型减少内存占用和计算开销,同时在数值敏感的操作中保持高精度计算。
bfloat16格式是一种特殊的16位浮点数表示方法,虽然占用的内存空间仅为32位浮点数的一半,但其动态范围与float32基本相当。自动混合精度系统会自动分析计算图中的每个算子,智能地将数据类型转换为最适合的低精度格式,从而实现计算性能的整体优化。
在Intel Extension for PyTorch的实现中,Intel CPU和GPU平台都提供了完整的自动混合精度支持。对于GPU计算,torch.xpu.amp模块提供了运行时的自动数据类型转换功能。在训练阶段,系统支持torch.bfloat16格式,而在推理阶段,则同时支持torch.bfloat16和torch.float16两种低精度格式。当torch.xpu.amp功能启用时,bfloat16被设置为默认的低精度浮点数据类型。
代码实现与技术细节
本节将通过完整的代码示例展示如何使用Intel Extension for PyTorch实现ResNet-50模型的自动混合精度训练和推理。整个实现过程充分利用了Intel Xe Matrix Extensions(Intel XMX)对bf16和int8数据类型的硬件加速支持。
环境配置与依赖导入
首先需要导入必要的依赖包并配置超参数。这些设置将为后续的模型训练和推理提供基础环境。
import os
from time import time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
import intel_extension_for_pytorch as ipex
from tqdm import tqdm # 超参数配置
LR = 0.01
MOMENTUM = 0.9
DATA = 'datasets/cifar10/'
epochs=1 batch_size=128
数据集准备与预处理
CIFAR-10数据集的加载和预处理是训练流程的重要组成部分。通过torchvision.datasets模块可以方便地获取标准数据集,并应用适当的数据变换来满足ResNet-50模型的输入要求。
transform = torchvision.transforms.Compose([ torchvision.transforms.Resize((224, 224)), torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]) train_dataset = torchvision.datasets.CIFAR10( root=DATA, train=True, transform=transform, download=True,
) train_loader = torch.utils.data.DataLoader( dataset=train_dataset, batch_size=batch_size
) test_dataset = torchvision.datasets.CIFAR10( root=DATA, train=False, download=True, transform=transform
) test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
模型训练函数实现
trainModel函数是整个训练流程的核心,它支持在不同设备(CPU/GPU)和不同精度(FP32/bf16)下进行模型训练。
def trainModel(train_loader, modelName="myModel", device="cpu", dataType="fp32"):
模型初始化与架构调整
训练过程首先需要初始化预训练的ResNet-50模型,并针对CIFAR-10数据集的10个类别对最后的分类层进行调整。
model = torchvision.models.resnet50(pretrained=True) model.fc = torch.nn.Linear(2048,10) lin_layer = model.fc new_layer = torch.nn.Sequential( lin_layer, torch.nn.Softmax(dim=1) ) model.fc = new_layer
损失函数与优化器配置
选择合适的损失函数和优化策略对训练效果具有重要影响。这里采用交叉熵损失函数和SGD优化器的组合。
criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=LR, momentum=MOMENTUM) model.train()
设备配置与XPU迁移
当选择GPU训练时,需要将模型和损失函数迁移到XPU设备上,以利用Intel GPU的计算能力。
if device == "GPU": model = model.to("xpu:0") criterion = criterion.to("xpu:0")
Intel Extension优化配置
根据指定的数据类型配置Intel Extension for PyTorch的优化选项,支持FP32和bf16两种精度模式。
if "bf16" == dataType: model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.bfloat16) else: model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.float32)
训练循环与混合精度实现
训练循环的核心在于正确实现自动混合精度的前向传播和反向传播过程。
num_batches = len(train_loader) * epochs for i in range(epochs): running_loss = 0.0 for batch_idx, (data, target) in enumerate(train_loader): optimizer.zero_grad() # XPU设备数据迁移 if device == "GPU": data = data.to("xpu:0") target = target.to("xpu:0") # 自动混合精度计算路径 if "bf16" == dataType: with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16): output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() running_loss += loss.item() else: output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() running_loss += loss.item() # 训练进度监控 if 0 == (batch_idx+1) % 50: print("Batch %d/%d complete" %(batch_idx+1, num_batches)) print(f' average loss: {running_loss / 50:.3f}') running_loss = 0.0
模型检查点保存
训练完成后,需要保存模型的状态字典和优化器状态,以便后续的推理和继续训练。
torch.save({ 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), }, 'checkpoint_%s.pth' %modelName) print(f'\n Training finished and model is saved as checkpoint_{modelName}.pth') return None
模型训练执行
使用配置好的训练函数在不同设备和精度设置下训练模型,为后续的性能对比提供基础。
trainModel(train_loader, modelName="gpu_rn50", device="gpu", dataType="fp32") trainModel(train_loader, modelName="gpu_rn50", device="gpu", dataType="bf16") trainModel(train_loader, modelName="cpu_rn50", device="cpu", dataType="fp32")
模型加载与恢复功能
为了支持训练好的模型的加载和使用,需要实现一个自定义的模型加载函数。
def load_model(cp_file = 'checkpoint_rn50.pth'): model = torchvision.models.resnet50() model.fc = torch.nn.Linear(2048,10) lin_layer = model.fc new_layer = torch.nn.Sequential( lin_layer, torch.nn.Softmax(dim=1) ) model.fc = new_layer checkpoint = torch.load(cp_file) model.load_state_dict(checkpoint['model_state_dict']) return model
Intel Extension JIT优化
Just-In-Time(JIT)编译优化是提升推理性能的重要技术。该函数结合了Intel Extension的优化功能和PyTorch的JIT编译机制。
def ipex_jit_optimize(model, dataType = "fp32" , device="CPU"): model.eval() if device=="GPU": model = model.to("xpu:0") if dataType=="bf16": model = ipex.optimize(model, dtype=torch.bfloat16) else: model = ipex.optimize(model, dtype = torch.float32) with torch.no_grad(): d = torch.rand(1, 3, 224, 224) if device=="GPU": d = d.to("xpu:0") if dataType=="bf16": with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16): jit_model = torch.jit.trace(model, d) # JIT跟踪优化模型 jit_model = torch.jit.freeze(jit_model) # JIT冻结跟踪模型 else: jit_model = torch.jit.trace(model, d) # JIT跟踪优化模型 jit_model = torch.jit.freeze(jit_model) # JIT冻结跟踪模型 return jit_model
推理性能评估
推理性能评估函数用于测量模型的准确率和推理延迟,这是评价优化效果的重要指标。
def inferModel(model, test_loader, device="cpu" , dataType='fp32'): correct = 0 total = 0 if device == "GPU": model = model.to("xpu:0") infer_time = 0 with torch.no_grad(): num_batches = len(test_loader) batches=0 for i, data in tqdm(enumerate(test_loader)): torch.xpu.synchronize() start_time = time() images, labels = data if device =="GPU": images = images.to("xpu:0") outputs = model(images) outputs = outputs.to("cpu") _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() torch.xpu.synchronize() end_time = time() if i>=3 and i<=num_batches-3: infer_time += (end_time-start_time) batches += 1 if i == num_batches - 3: break accuracy = 100 * correct / total return accuracy, infer_time*1000/(batches*batch_size)
综合评估函数
综合评估函数将模型加载、JIT优化和推理评估整合在一起,提供完整的性能测试流程。
def Eval_model(cp_file='checkpoint_model.pth', dataType="fp32" , device="GPU" ): model = load_model(cp_file) model = ipex_jit_optimize(model, dataType , device) accuracy, latency = inferModel(model, test_loader, device, dataType ) print(f' Model accuracy:{accuracy} and Average Inference latency:{latency}') return accuracy, latency
性能测试与结果分析
通过在不同配置下运行评估函数,可以全面比较各种优化策略的效果。
Eval_model(cp_file = 'checkpoint_gpu_rn50.pth', dataType = "fp32", device="GPU") Eval_model(cp_file = 'checkpoint_gpu_rn50.pth', dataType = "bf16", device="GPU") Eval_model(cp_file = 'checkpoint_cpu_rn50.pth', dataType = "fp32", device="CPU")
总结
本代码示例建议在Linux操作系统和Jupyter Notebook环境中运行,以获得最佳的开发和调试体验。实验结果表明,通过Intel Extension for PyTorch实现的自动混合精度优化能够在保持模型精度的前提下显著提升训练和推理性能。特别是在配备Intel XMX技术的GPU环境下,bf16格式的计算性能提升尤为明显。
实验数据显示,采用自动混合精度bf16格式相比传统FP32格式在推理速度上有显著改善,同时在CPU和GPU平台上都能观察到性能收益。这证明了Intel Extension for PyTorch在异构计算环境下的优化效果和实用价值。
对于实际部署应用,建议开发者根据具体的硬件配置和精度要求选择合适的优化策略,并通过充分的性能测试来验证优化效果。
https://avoid.overfit.cn/post/f0352687c2a643ad8e4b505fbf51cd4b