[极客时间]LangChain 实战课 -----|(11) 记忆:通过Memory记住客户上次买花时的对话细节
在默认情况下,无论是 LLM 还是代理都是无状态的,每次模型的调用都是独立于其他交互的。也就是说,我们每次通过 API 开始和大语言模型展开一次新的对话,它都不知道你其实昨天或者前天曾经和它聊过天了。
你肯定会说,不可能啊,每次和 ChatGPT 聊天的时候,ChatGPT 明明白白地记得我之前交待过的事情。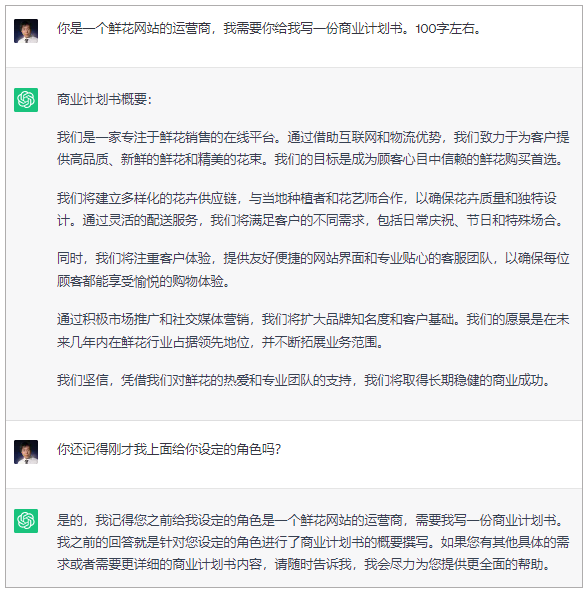
的确如此,ChatGPT 之所以能够记得你之前说过的话,正是因为它使用了记忆(Memory)机制,记录了之前的对话上下文,并且把这个上下文作为提示的一部分,在最新的调用中传递给了模型。
在聊天机器人的构建中,记忆机制非常重要。
使用 ConversationChain
不过,在开始介绍 LangChain 中记忆机制的具体实现之前,先重新看一下我们上一节课曾经见过的 ConversationChain。
这个 Chain 最主要的特点是,它提供了包含 AI 前缀和人类前缀的对话摘要格式,这个对话格式和记忆机制结合得非常紧密。
让我们看一个简单的示例,并打印出 ConversationChain 中的内置提示模板,你就会明白这个对话格式的意义了。
from langchain import OpenAI
from langchain.chains import ConversationChain# 初始化大语言模型
llm = OpenAI(temperature=0.5,model_name="gpt-3.5-turbo-instruct"
)# 初始化对话链
conv_chain = ConversationChain(llm=llm)# 打印对话的模板
print(conv_chain.prompt.template)
输出
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:
{history}
Human: {input}
AI:

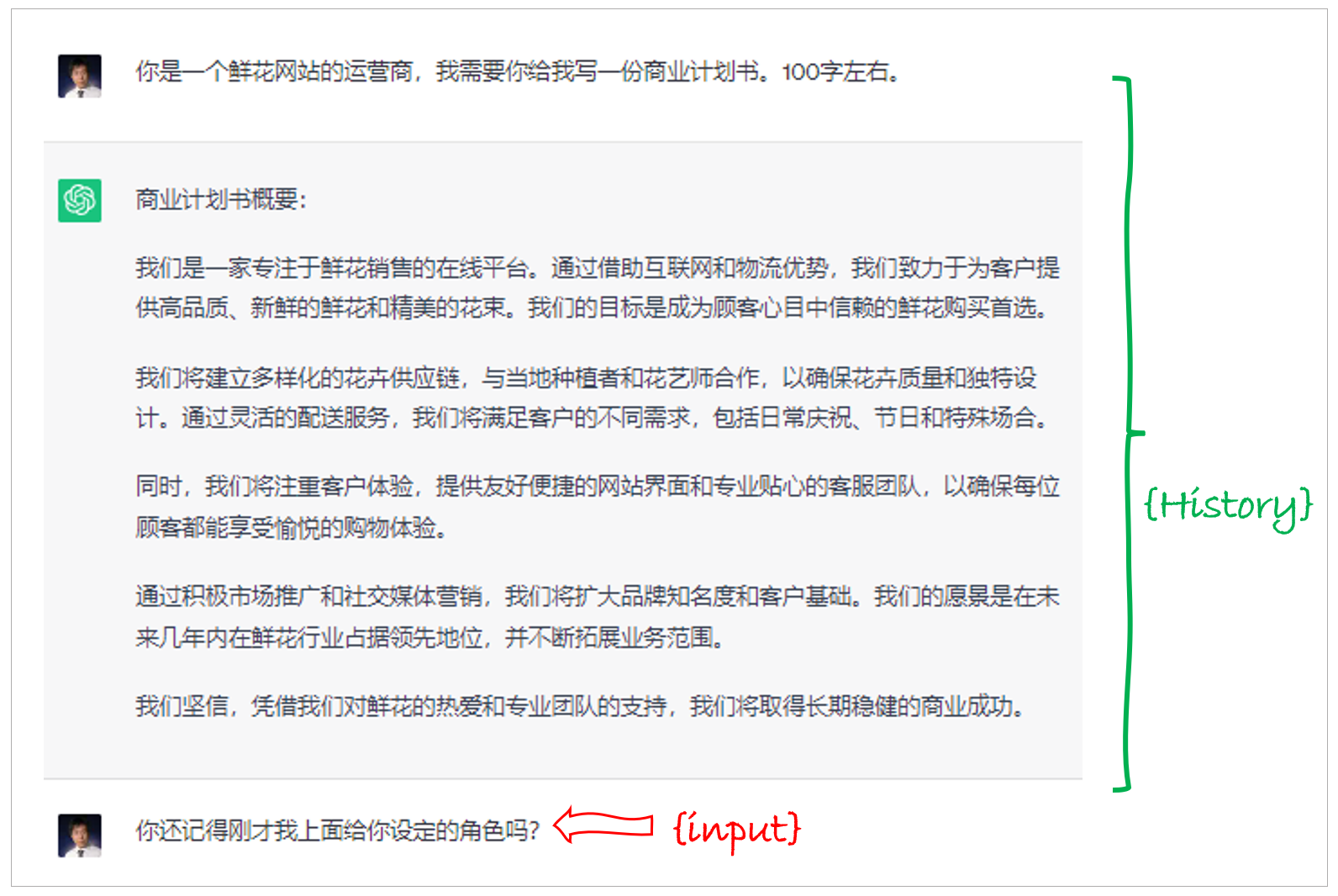
那么当有了 {history} 参数,以及 Human 和 AI 这两个前缀,我们就能够把历史对话信息存储在提示模板中,并作为新的提示内容在新一轮的对话过程中传递给模型。—— 这就是记忆机制的原理。下
面就让我们来在 ConversationChain 中加入记忆功能。
使用 ConversationBufferMemory
在 LangChain 中,通过 ConversationBufferMemory(缓冲记忆)可以实现最简单的记忆机制。
下面,我们就在对话链中引入 ConversationBufferMemory。
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory# 初始化大语言模型
llm = OpenAI(temperature=0.5,model_name="gpt-3.5-turbo-instruct")# 初始化对话链
conversation = ConversationChain(llm=llm,memory=ConversationBufferMemory()
)# 第一天的对话
# 回合1
conversation("我姐姐明天要过生日,我需要一束生日花束。")
print("第一次对话后的记忆:", conversation.memory.buffer)
输出
第一次对话后的记忆:
Human: 我姐姐明天要过生日,我需要一束生日花束。
AI: 哦,你姐姐明天要过生日,那太棒了!我可以帮你推荐一些生日花束,你想要什么样的?我知道有很多种,比如玫瑰、康乃馨、郁金香等等。
下面,我们继续对话,同时打印出此时提示模板的信息。

使用 ConversationBufferWindowMemory
说到记忆,我们人类的大脑也不是无穷无尽的。
所以说,有的时候事情太多,我们只能把有些遥远的记忆抹掉。毕竟,最新的经历最鲜活,也最重要。
ConversationBufferWindowMemory 是缓冲窗口记忆,它的思路就是只保存最新最近的几次人类和 AI 的互动。因此,它在之前的“缓冲记忆”基础上增加了一个窗口值 k。
这意味着我们只保留一定数量的过去互动,然后“忘记”之前的互动。
下面看一下示例。
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferWindowMemory# 创建大语言模型实例
llm = OpenAI(temperature=0.5,model_name="gpt-3.5-turbo-instruct")# 初始化对话链
conversation = ConversationChain(llm=llm,memory=ConversationBufferWindowMemory(k=1)
)# 第一天的对话
# 回合1
result = conversation("我姐姐明天要过生日,我需要一束生日花束。")
print(result)
# 回合2
result = conversation("她喜欢粉色玫瑰,颜色是粉色的。")
# print("\n第二次对话后的记忆:\n", conversation.memory.buffer)
print(result)# 第二天的对话
# 回合3
result = conversation("我又来了,还记得我昨天为什么要来买花吗?")
print(result)

使用 ConversationSummaryMemory

from langchain.chains.conversation.memory import ConversationSummaryMemory# 初始化对话链
conversation = ConversationChain(llm=llm,memory=ConversationSummaryMemory(llm=llm)
)
而且,总结的过程中并没有区分近期的对话和长期的对话(通常情况下近期的对话更重要),所以我们还要继续寻找新的记忆管理方法。
使用 ConversationSummaryBufferMemory
我要为你介绍的最后一种记忆机制是 ConversationSummaryBufferMemory,即对话总结缓冲记忆,它是一种混合记忆模型,结合了上述各种记忆机制,包括 ConversationSummaryMemory 和 ConversationBufferWindowMemory 的特点。
这种模型旨在在对话中总结早期的互动,同时尽量保留最近互动中的原始内容。它是通过 max_token_limit 这个参数做到这一点的。当最新的对话文字长度在 300 字之内的时候,LangChain 会记忆原始对话内容;当对话文字超出了这个参数的长度,那么模型就会把所有超过预设长度的内容进行总结,以节省 Token 数量。
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory# 初始化对话链
conversation = ConversationChain(llm=llm,memory=ConversationSummaryBufferMemory(llm=llm,max_token_limit=300))

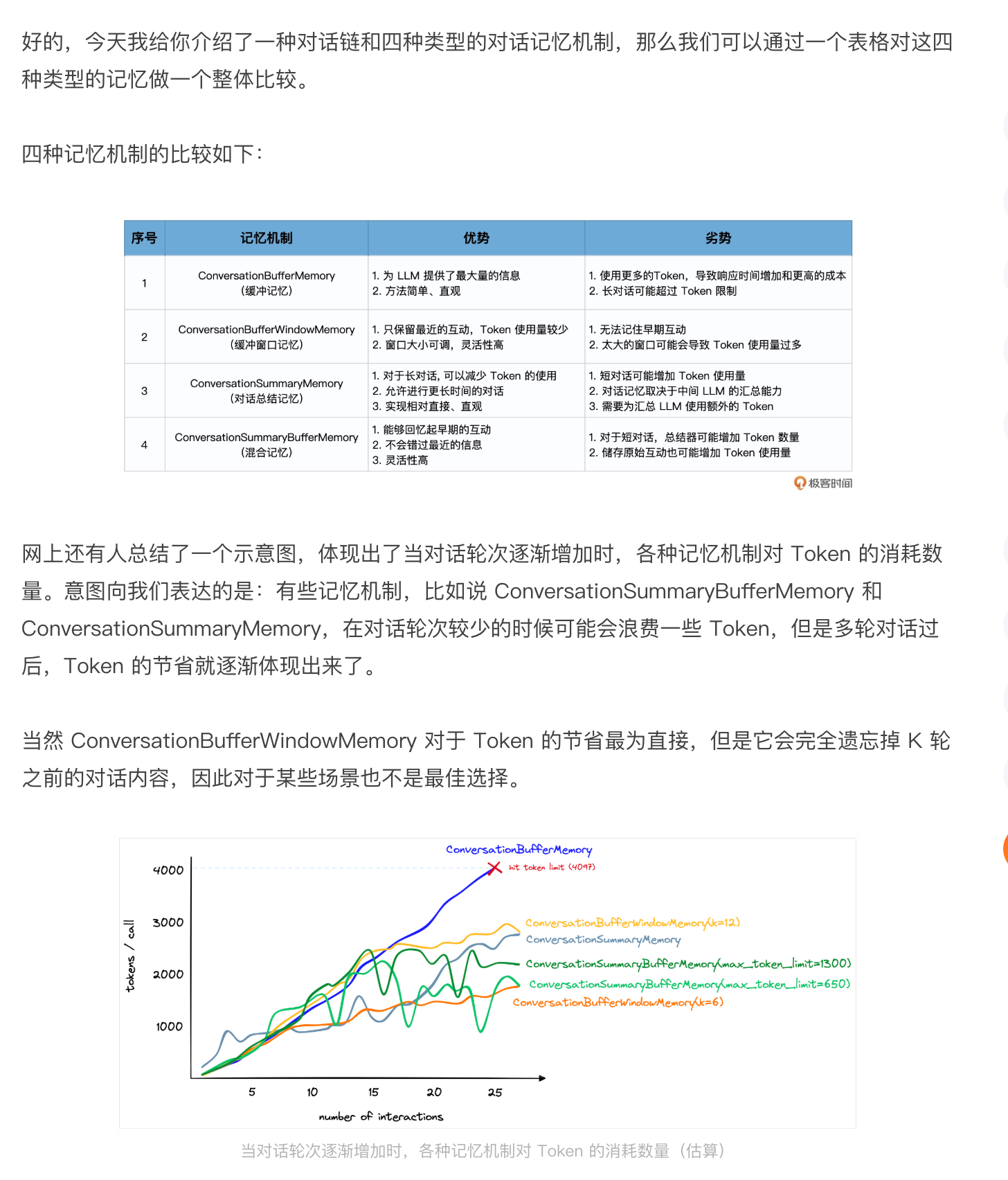
总结
思考题
