【目标检测】d-fine模型部署
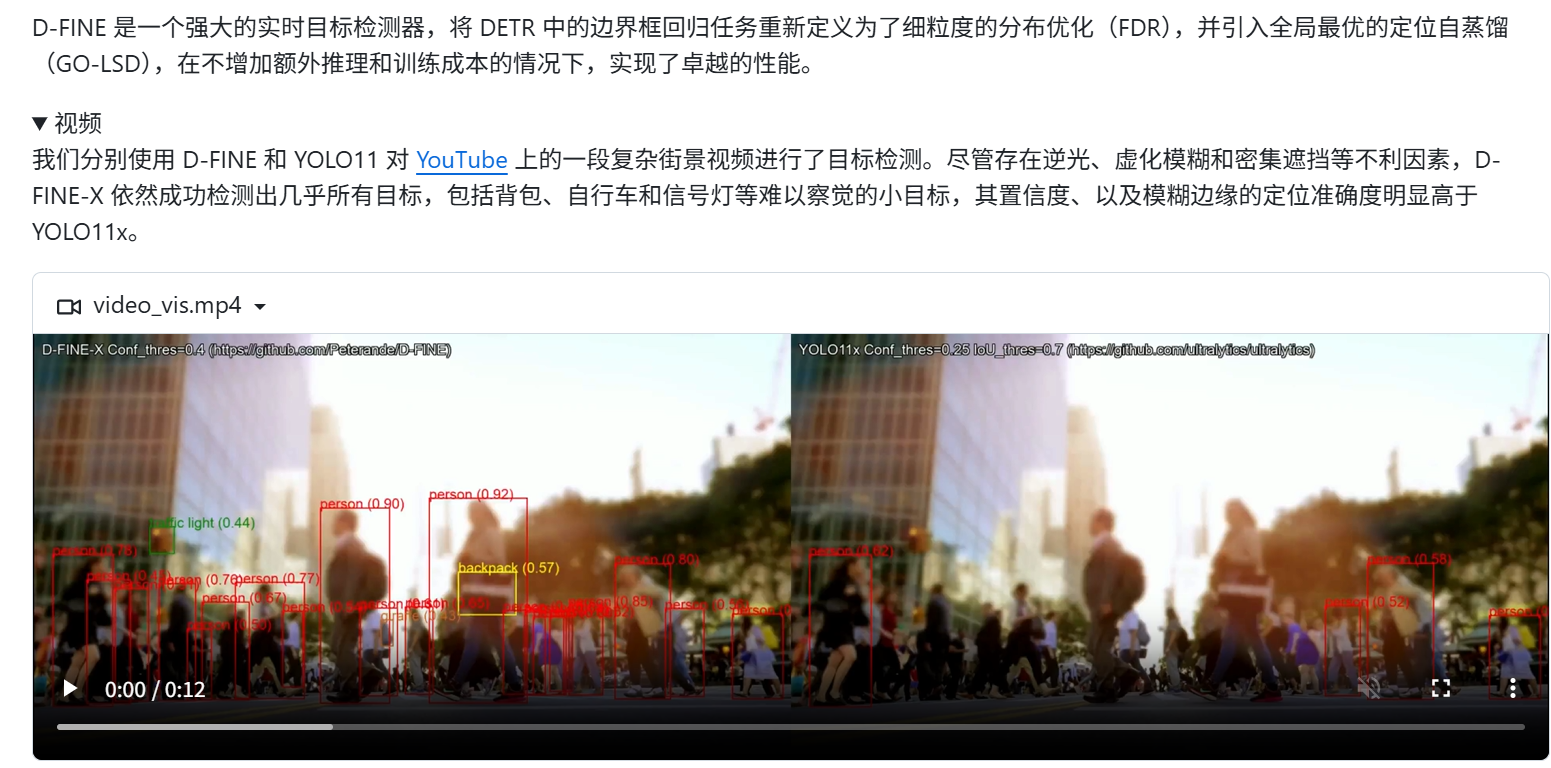
官网介绍显示,d-fine模型效果很好,例如下图中,非常模糊的人也能被识别出来。官网教程有些细节没写,这里补充一下。
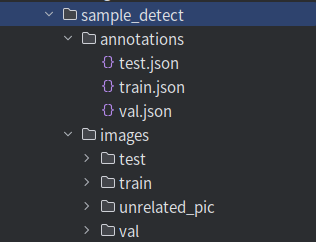
1.数据格式
数据长这样(图中的unrrelated_pic无用)。
具体的格式可以由大模型生成。我这里有数据转化的代码,我的原始数据长这样。
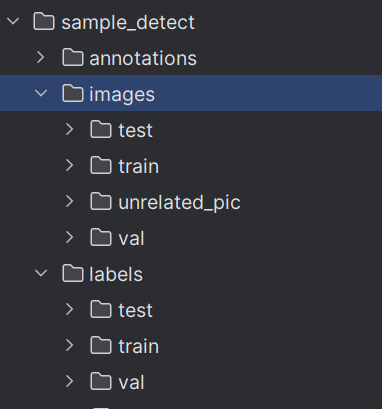
在sample_detect文件夹下,请只关注images和labels两个文件夹,annotations是转化代码生成的文件。images文件夹下有train、test、val三个文件夹,直接放图片即可,labels文件夹下有对应的所有图片的txt标注文件,类似于yolo。
代码运行时,请修改CLASS_NAMES 、ROOT_DIR 和convert_txt_to_coco即可。
import os
import json
import cv2 # 使用 OpenCV 读取图片尺寸
from tqdm import tqdm # 显示进度条,提供更好的用户体验# --- 1. 配置信息 ---# 你的类别名称,ID会从1开始分配(COCO标准中,0通常是背景)
# 请务必按照你的 a.txt 文件中的 class_id 顺序来填写
CLASS_NAMES = ["xxx"]# 数据集根目录
ROOT_DIR = r'F:\yyy'# --- 2. 核心转换函数 ---def convert_txt_to_coco(root_dir, dataset_split):"""将 YOLO 格式的 TXT 标注文件转换为 COCO JSON 格式。Args:root_dir (str): 数据集根目录,包含 images 和 labels 文件夹。dataset_split (str): 'train' 或 'val',指定要转换的数据子集。"""print(f"--- 开始转换 {dataset_split} 数据集 ---")# 定义输入路径img_dir = os.path.join(root_dir, 'images', dataset_split)txt_dir = os.path.join(root_dir, 'labels', dataset_split)# 定义输出文件路径output_dir = os.path.join(root_dir, 'annotations')os.makedirs(output_dir, exist_ok=True)json_path = os.path.join(output_dir, f'{dataset_split}.json')# --- 初始化 COCO JSON 结构 ---coco_data = {"info": {"description": f"Custom dataset converted from TXT to COCO format - {dataset_split}","version": "1.0","year": 2025,"contributor": "YourName", # 请替换为你的名字"date_created": "2025/07/24"},"licenses": [],"images": [],"annotations": [],"categories": []}# ---填充类别信息 (categories) ---# COCO 的 category_id 通常从 1 开始for i, name in enumerate(CLASS_NAMES):coco_data['categories'].append({"id": i + 1,"name": name,"supercategory": "object"})# --- 核心转换逻辑 ---image_id_counter = 1annotation_id_counter = 1# 遍历所有图片文件image_files = [f for f in os.listdir(img_dir) if f.lower().endswith(('.jpg', '.jpeg', '.png'))]for image_filename in tqdm(image_files, desc=f"处理 {dataset_split} 图片"):# 构造对应的 txt 文件路径base_filename = os.path.splitext(image_filename)[0]txt_filename = base_filename + '.txt'txt_filepath = os.path.join(txt_dir, txt_filename)# 读取图片获取尺寸img_path = os.path.join(img_dir, image_filename)try:# 使用 imread 读取图片,即使是灰度图也能正常获取宽高img = cv2.imread(img_path)if img is None:print(f"警告:无法读取图片 {img_path},跳过该文件。")continueimg_height, img_width, _ = img.shapeexcept Exception as e:print(f"错误:读取图片 {img_path} 失败,原因为: {e}。跳过该文件。")continue# --- 填充图片信息 (images) ---coco_data['images'].append({"id": image_id_counter,"file_name": image_filename,"width": img_width,"height": img_height})# --- 填充标注信息 (annotations) ---if os.path.exists(txt_filepath):with open(txt_filepath, 'r') as f:for line in f.readlines():try:class_id, x_center_norm, y_center_norm, width_norm, height_norm = map(float,line.strip().split())# 将 YOLO 格式 (归一化) 转换为 COCO 格式 (绝对像素值)# bbox: [x_min, y_min, width, height]bbox_width = width_norm * img_widthbbox_height = height_norm * img_heightx_min = (x_center_norm * img_width) - (bbox_width / 2)y_min = (y_center_norm * img_height) - (bbox_height / 2)# 计算面积area = bbox_width * bbox_heightcoco_data['annotations'].append({"id": annotation_id_counter,"image_id": image_id_counter,"category_id": int(class_id) + 1, # TXT中class_id从0开始,COCO从1开始"bbox": [round(x_min, 2), round(y_min, 2), round(bbox_width, 2), round(bbox_height, 2)],"area": round(area, 2),"iscrowd": 0,"segmentation": [] # 对于bbox,segmentation通常为空})annotation_id_counter += 1except ValueError:print(f"警告:文件 {txt_filename} 中的行格式不正确: '{line.strip()}'")image_id_counter += 1# --- 保存为 JSON 文件 ---with open(json_path, 'w') as f:json.dump(coco_data, f, indent=4)print(f"--- 转换完成!JSON 文件已保存至: {json_path} ---")print(f"总计图片数: {len(coco_data['images'])}")print(f"总计标注数: {len(coco_data['annotations'])}")# --- 3. 执行转换 ---
if __name__ == '__main__':# 转换训练集convert_txt_to_coco(ROOT_DIR, 'train')# # 转换验证集# convert_txt_to_coco(ROOT_DIR, 'val')
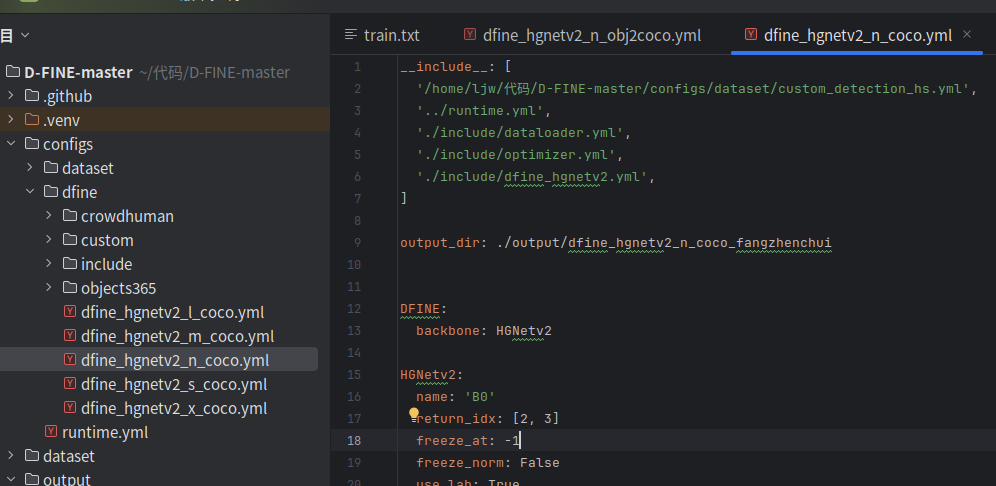
2.配置文件
你需要修改图中的文件,即“D-FINE-master/configs/dfine/dfine_hgnetv2_n_coco.yml”。你也可以选择其他尺寸的模型。
你需要修改代码中的第2、4行才能完成数据加载,他们都在configs文件夹下。batch_size需要在这几个文件中都去修改一下。num_classes这个参数也很坑,默认777,改了之后会报错。其他训练参数也在对应的文件中。
3.运行代码
完成配置后,即可执行下面的命令单卡部署
CUDA_VISIBLE_DEVICES=0,1 python train.py -c /home/xxx/代码/D-FINE-master/configs/dfine/dfine_hgnetv2_n_coco.yml --use-amp --seed=0 -t /home/xxx/代码/D-FINE-master/pretrain_model/dfine_n_coco.pth
双卡部署时,请参照原作者readme文件中,torchrun相关方法,并使用sudo nvidia-smi -pm 1确保多张显卡开启。
运行成功截图如下:
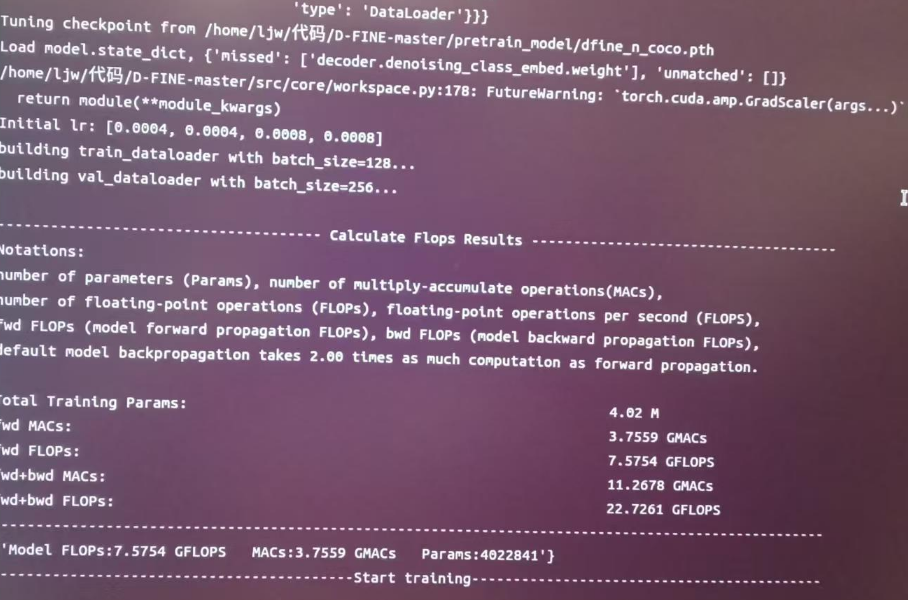
4.注意事项
推理的时候,在D-FINE-master/tools/inference文件夹下,需要配一个新环境,但是这个环境会与训练时候的环境冲突,请格外小心,做好备份或者另开一个环境。