深度学习:预训练和warm up的区别
“预训练(Pre-training)”和“Warm-up(预热)”是深度学习中常见的两个训练策略,它们虽然都在训练初期起作用,但本质和目的完全不同。
一、预训练(Pre-training)
1. 定义
预训练是指:先在一个大规模数据集或相关任务上训练模型,以获取有用的参数初始化,然后再在目标任务上进行微调(Fine-tuning)。
2. 目的
加快收敛
避免从头开始训练
提高小数据集上的性能(通过迁移知识)
3. 举例
NLP领域(经典):
| 模型 | 预训练任务 | 微调任务 |
|---|---|---|
| BERT | Masked Language Model | 文本分类、问答、NER等 |
| GPT系列 | 下一个词预测(语言建模) | 对话、写作、代码生成等 |
CV领域(图像):
用 ResNet-50 在 ImageNet 上预训练,迁移到医疗图像/遥感图像等小样本任务中。
4. 形式
# 加载预训练权重 model.load_state_dict(torch.load("pretrained_model.pth")) # 再进行微调 train(model, task_dataset)
二、Warm-up(预热)
1. 定义
Warm-up 指的是:在训练初期,逐渐增加学习率,从一个较小值慢慢变大,直到达到设定的初始学习率。如下面例子中的线性warm up。
2. 目的
防止一开始梯度爆炸或震荡
提高训练稳定性,特别是Transformer类模型
3. 常见策略
(1) 线性 warm-up:
lr = base_lr × step / warmup_steps if step <= warmup_steps
(2) 结合衰减策略(如 transformer):
# 经典 Transformer warmup+inverse sqrt decay def get_lr(step, d_model=512, warmup=4000): return d_model**-0.5 * min(step**-0.5, step * warmup**-1.5)
4. 举例
PyTorch 中使用 warmup:
from transformers import get_linear_schedule_with_warmup
optimizer = AdamW(model.parameters(), lr=1e-4)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=10000)
for step in range(total_steps): optimizer.step() scheduler.step()三、对比总结
| 项目 | 预训练(Pre-training) | Warm-up(预热) |
|---|---|---|
| 作用阶段 | 训练前或训练初期 | 训练初期 |
| 针对对象 | 模型权重 | 学习率调度 |
| 目标 | 利用已有知识迁移,加快收敛 | 防止梯度不稳定,提高初始阶段鲁棒性 |
| 应用领域 | NLP、CV、大模型、元学习等 | Transformer、BERT、GAN、深度网络等 |
四、实际项目中如何配合使用?
预训练 + warm-up 经常联合使用(如 BERT)
示例:
加载预训练 BERT 模型
采用 warm-up + cosine decay 的学习率策略
微调分类任务(如情感分析)
在轨迹预测、分类或Transformer类任务,warm-up 几乎是标配;而预训练则要看你有没有现成的预训练模型或大规模源域数据。
五、PyTorch 实现的warm-up 学习率调度器(warm-up + 余弦退火)
下面是一个使用 PyTorch 实现的 warm-up 学习率调度器 的完整示例,适用于 Transformer、BERT 或任意深度模型训练时的预热策略。
示例:线性 warm-up + 余弦退火(Cosine Annealing)
import torch
import torch.nn as nn
import torch.optim as optim
import math
import matplotlib.pyplot as plt# 模拟模型
model = nn.Linear(512, 10)# 优化器
optimizer = optim.Adam(model.parameters(), lr=1e-3)# 训练总步数
num_training_steps = 10000# warm-up 步数(前10%步数用于 warm-up)
num_warmup_steps = int(0.1 * num_training_steps)# 自定义 warm-up + cosine 衰减调度器
def get_lr(step):if step < num_warmup_steps:return step / num_warmup_stepselse:# 余弦衰减,值在 [1, 0]progress = (step - num_warmup_steps) / (num_training_steps - num_warmup_steps)return 0.5 * (1.0 + math.cos(math.pi * progress))# 模拟训练流程
lrs = []
for step in range(1, num_training_steps + 1):# 当前的学习率(乘基础学习率)scale = get_lr(step)lr = scale * 1e-3for param_group in optimizer.param_groups:param_group['lr'] = lr# 模拟一次训练optimizer.step()lrs.append(lr)# 可视化学习率变化
plt.plot(lrs)
plt.title("Learning Rate Schedule (Warm-up + Cosine Decay)")
plt.xlabel("Step")
plt.ylabel("Learning Rate")
plt.grid(True)
plt.show()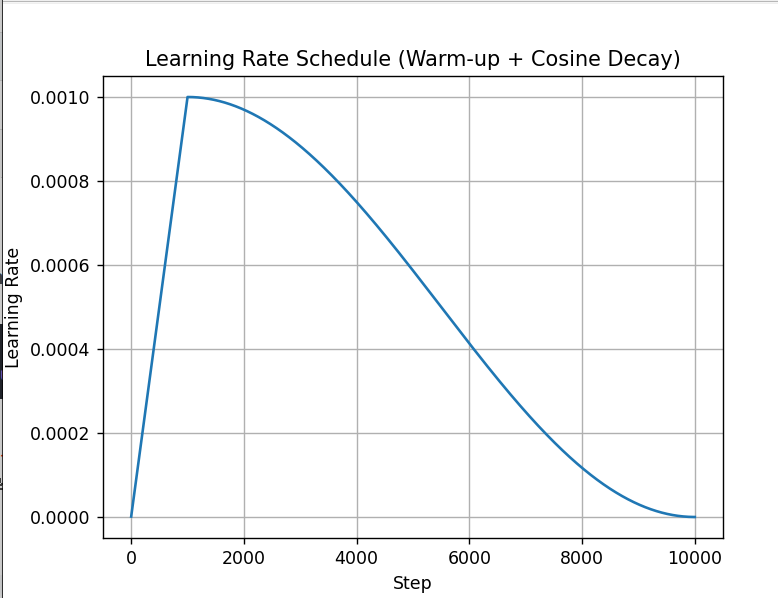
代码解释:
| 阶段 | 策略 |
|---|---|
| 前1000步 | 学习率从 0 线性上升到 1e-3 |
| 后9000步 | 学习率从 1e-3 余弦方式逐渐衰减到接近 0 |
线性 warm-up 的核心逻辑定义在 get_lr(step) 函数中的这部分:
if step < num_warmup_steps:return step / num_warmup_steps线性 warm-up 就是:在训练开始时,学习率从 0 按线性方式逐步升到设定的最大值,防止一开始梯度太大导致训练不稳定。
余弦退火(Cosine Annealing)是一种学习率调度策略,其核心目的是:
让学习率在训练后期逐渐减小,有节奏地收敛到接近 0,从而提升模型收敛的稳定性与最终精度。
为什么要用余弦退火?
训练初期: 需要较大的学习率来快速探索优化空间;
训练后期: 逐渐减小学习率,有助于模型精细调优、避免震荡;
相比线性衰减或固定学习率更有效,尤其在 Transformer、BERT、CV大模型中常用。