1 RAG三问
1. 究竟什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索与生成式 AI 的技术框架。凡是和如何有效进行信息检索相关的技术都可以称作RAG。
RAG 的核心逻辑是 “先检索,再生成”,具体分为三个关键步骤:
-
用户提问处理
对用户输入的问题进行解析(如关键词提取、语义理解),转化为适合检索的查询向量。 -
知识检索
从预设的知识库(如文档、数据库、网页等)中,快速找到与问题相关的信息片段。这一步通常依赖向量数据库(如 Milvus、Pinecone),通过计算查询向量与知识库中内容向量的相似度,返回最相关的结果。 -
生成式回答
将检索到的相关信息作为 “上下文”,输入到大语言模型(如 GPT、LLaMA 等)中,让模型基于这些信息生成针对性的回答,而非仅依赖自身训练数据。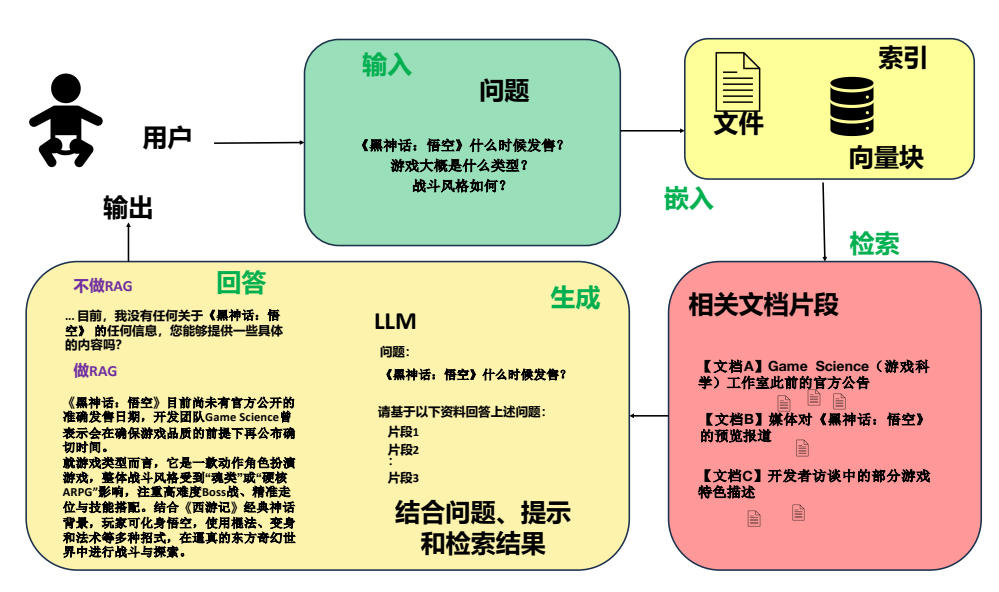
RAG 的关键组件
- 知识嵌入(Embedding):负责将文本知识转化为向量表示,捕捉语义信息。
- 向量数据库(Vector DB):存储由知识嵌入模块生成的向量表示。
- 检索器(Retriever):接收用户查询并将其转化为向量,然后从向量数据库中检索相似的文档。
- 生成器(Generator):基于检索到的相关上下文信息生成流畅且可信的回答。
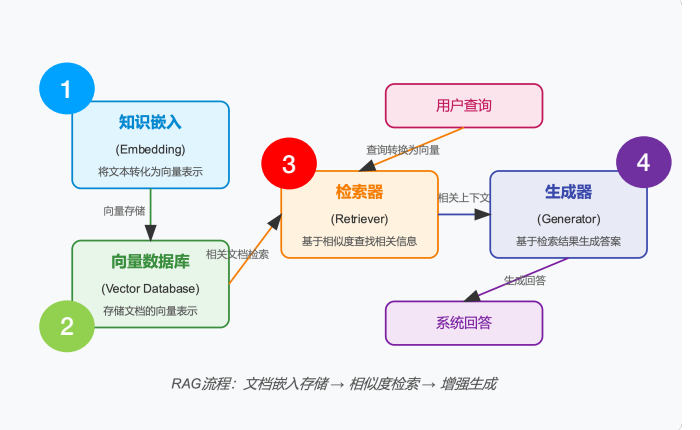
关键环节 #1 – 索引
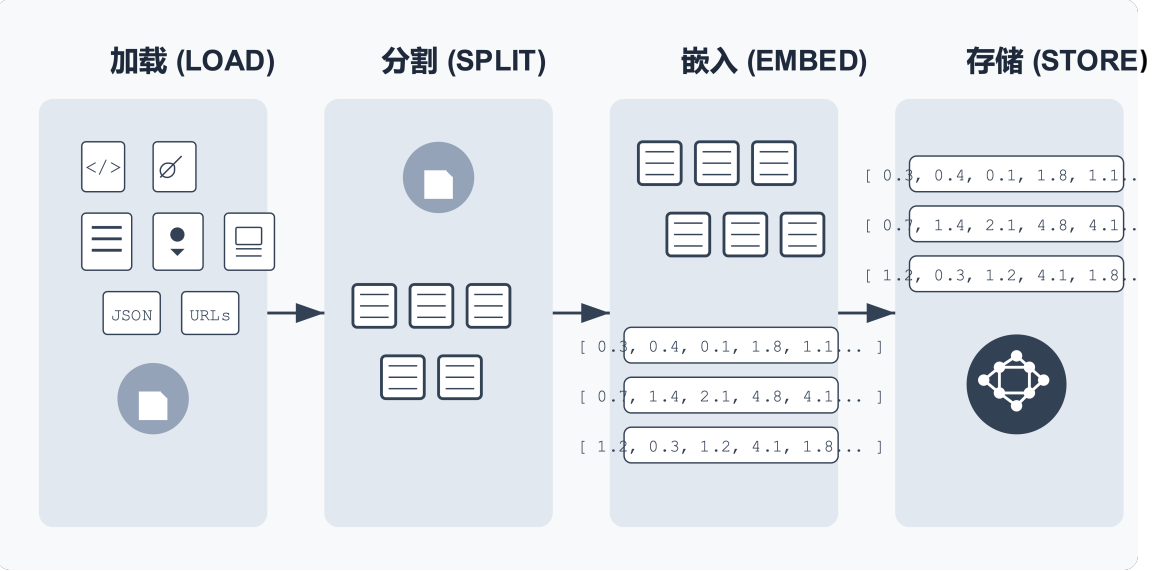
关键环节 #2 – 检索和生成
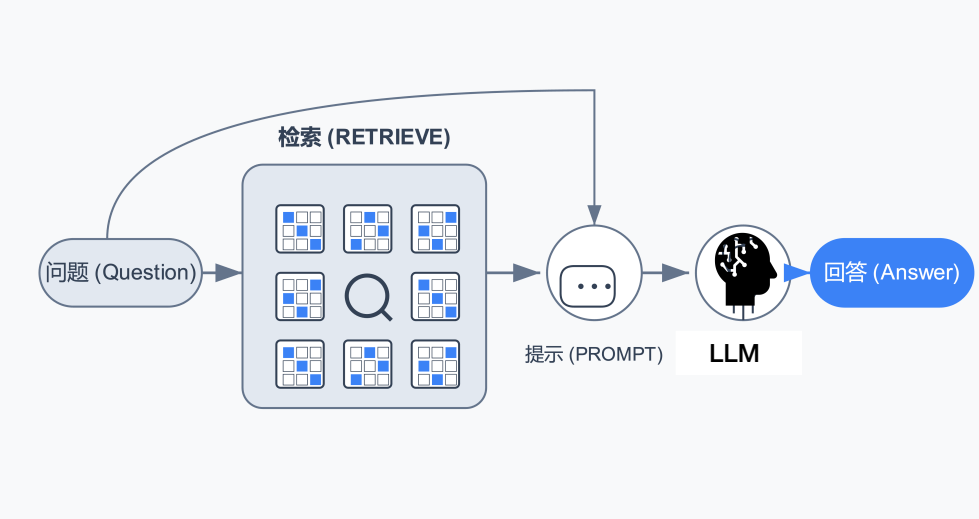
2. 如何快速上手RAG
1. 使用框架:LlamaIndex的5步示例
默认调用OpenAI嵌入模型和生成模型(gpt-3.5-turbo):
# 第一行代码:导入相关的库
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 第二行代码:加载数据
documents = SimpleDirectoryReader(input_files=["../90-文档-Data/黑悟空/设定.txt"]).load_data()
# 第三行代码:构建索引
index = VectorStoreIndex.from_documents(documents)
# 第四行代码:创建问答引擎
query_engine = index.as_query_engine()
# 第五行代码: 开始问答
print(query_engine.query("黑神话悟空中有哪些战斗工具?"))更换嵌入模型,从HuggingFace下载模型:
# 导入相关的库
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding # 需要pip install llama-index-embeddings-huggingface# 加载本地嵌入模型
# import os
# os.environ['HF_ENDPOINT']= 'https://hf-mirror.com' # 如果万一被屏蔽,可以设置镜像
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh" # 模型路径和名称(首次执行时会从HuggingFace下载))# 加载数据
documents = SimpleDirectoryReader(input_files=["90-文档-Data/黑悟空/设定.txt"]).load_data() # 构建索引
index = VectorStoreIndex.from_documents(documents,embed_model=embed_model
)# 创建问答引擎
query_engine = index.as_query_engine()# 开始问答
print(query_engine.query("黑神话悟空中有哪些战斗工具?"))更换生成模型:
# 导入相关的库
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding # 需要pip install llama-index-embeddings-huggingface
from llama_index.llms.deepseek import DeepSeek # 需要pip install llama-index-llms-deepseekfrom llama_index.core import Settings # 可以看看有哪些Setting
# https://docs.llamaindex.ai/en/stable/examples/llm/deepseek/
# Settings.llm = DeepSeek(model="deepseek-chat")
Settings.embed_model = HuggingFaceEmbedding("BAAI/bge-small-zh")
# Settings.llm = OpenAI(model="gpt-3.5-turbo")
# Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")# 加载环境变量
from dotenv import load_dotenv
import os# 加载 .env 文件中的环境变量
load_dotenv()# 创建 Deepseek LLM(通过API调用最新的DeepSeek大模型)
llm = DeepSeek(model="deepseek-reasoner", # 使用最新的推理模型R1api_key=os.getenv("DEEPSEEK_API_KEY") # 从环境变量获取API key
)# 加载数据
documents = SimpleDirectoryReader(input_files=["90-文档-Data/黑悟空/设定.txt"]).load_data() # 构建索引
index = VectorStoreIndex.from_documents(documents,# llm=llm # 设置构建索引时的语言模型(一般不需要)
)# 创建问答引擎
query_engine = index.as_query_engine(llm=llm # 设置生成模型)# 开始问答
print(query_engine.query("黑神话悟空中有哪些战斗工具?"))使用生成模型:
# 第一行代码:导入相关的库
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.deepseek import DeepSeek
from dotenv import load_dotenv
import os
#
# 加载环境变量
load_dotenv()
os.environ["DEEPSEEK_API_KEY"] = ''
print(os.getenv("DEEPSEEK_API_KEY"))
# 加载本地嵌入模型
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh")# 创建 Deepseek LLM
llm = DeepSeek(model="deepseek-chat",api_key=os.getenv("DEEPSEEK_API_KEY")
)# 第二行代码:加载数据
documents = SimpleDirectoryReader(input_files=["../90-文档-Data/黑悟空/设定.txt"]).load_data()# 第三行代码:构建索引
index = VectorStoreIndex.from_documents(documents,embed_model=embed_model
)# 第四行代码:创建问答引擎
query_engine = index.as_query_engine(llm=llm
)# 第五行代码: 开始问答
print(query_engine.query("黑神话悟空中有哪些战斗工具?"))
2. 使用框架:LangChain的RAG实现
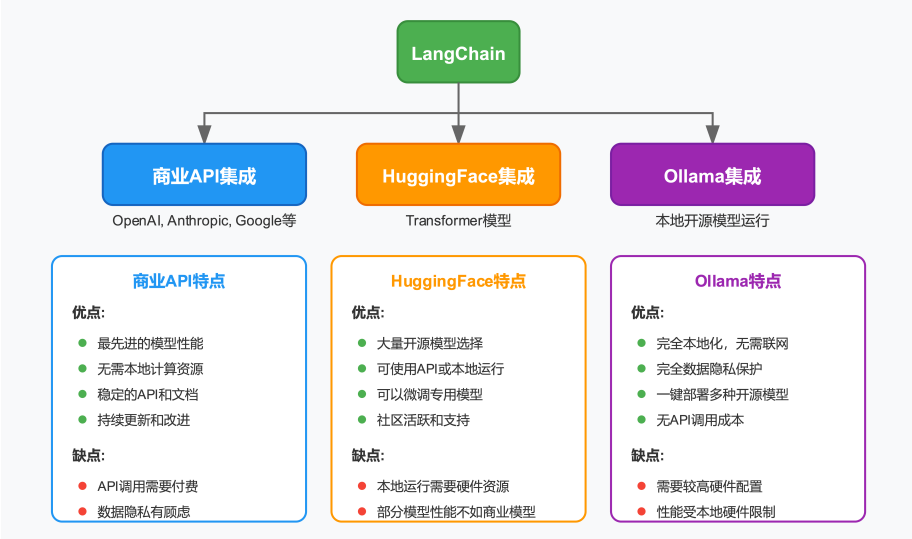
# 1. 加载文档
import os
from dotenv import load_dotenv# 加载环境变量
load_dotenv()from langchain_community.document_loaders import WebBaseLoader # pip install langchain-communityloader = WebBaseLoader(web_paths=("https://baike.baidu.com/item/%E9%BB%91%E7%A5%9E%E8%AF%9D%EF%BC%9A%E6%82%9F%E7%A9%BA/53303078",)
)
docs = loader.load()# 2. 文档分块
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)# 3. 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddings # pip install langchain-huggingfaceembeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True}
)# 4. 创建向量存储
from langchain_core.vectorstores import InMemoryVectorStorevector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(all_splits)# 5. 构建用户查询
question = "黑悟空有哪些游戏场景?"# 6. 在向量存储中搜索相关文档,并准备上下文内容
retrieved_docs = vector_store.similarity_search(question, k=3)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)# 7. 构建提示模板
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_template("""基于以下上下文,回答问题。如果上下文中没有相关信息,请说"我无法从提供的上下文中找到相关信息"。上下文: {context}问题: {question}回答:""")# 8. 使用大语言模型生成答案
from langchain_deepseek import ChatDeepSeek # pip install langchain-deepseekllm = ChatDeepSeek(model="deepseek-chat", # DeepSeek API 支持的模型名称temperature=0.7, # 控制输出的随机性max_tokens=2048, # 最大输出长度api_key=os.getenv("DEEPSEEK_API_KEY") # 从环境变量加载API key
)
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print(answer)使用langchain_openai实现:
需要指定base_url
# 1. 加载文档
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader(web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()# 2. 文档分块
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)# 3. 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddingsembeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True}
)# 4. 创建向量存储
from langchain_core.vectorstores import InMemoryVectorStorevector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(all_splits)# 5. 构建用户查询
question = "黑悟空有哪些游戏场景?"# 6. 在向量存储中搜索相关文档,并准备上下文内容
retrieved_docs = vector_store.similarity_search(question, k=3)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)# 7. 构建提示模板
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_template("""基于以下上下文,回答问题。如果上下文中没有相关信息,请说"我无法从提供的上下文中找到相关信息"。上下文: {context}问题: {question}回答:""")# 8. 使用大语言模型生成答案
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="deepseek-reasoner", # DeepSeek API 支持的模型名称base_url="https://api.deepseek.com/v1",temperature=0.7, # 控制输出的随机性(0-1之间,越大越随机)max_tokens=2048, # 最大输出长度top_p=0.95, # 控制输出的多样性(0-1之间)presence_penalty=0.0, # 重复惩罚系数(-2.0到2.0之间)frequency_penalty=0.0, # 频率惩罚系数(-2.0到2.0之间)api_key=os.getenv("DEEPSEEK_API_KEY") # 从环境变量加载API key
)
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print(answer)使用huggingface加载模型:
# 1. 加载文档
from langchain_community.document_loaders import WebBaseLoader # pip install beautifulsoup4loader = WebBaseLoader(web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()# 2. 文档分块
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)# 3. 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddingsembeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True}
)# 4. 创建向量存储
from langchain_core.vectorstores import InMemoryVectorStorevector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(all_splits)# 5. 构建用户查询
question = "黑悟空有哪些游戏场景?"# 6. 在向量存储中搜索相关文档,并准备上下文内容
retrieved_docs = vector_store.similarity_search(question, k=3)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)# 7. 构建提示模板
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_template("""基于以下上下文,用中文回答问题。如果上下文中没有相关信息,请说"我无法从提供的上下文中找到相关信息"。上下文: {context}问题: {question}回答:""")# 8. 使用大语言模型生成答案
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch# 加载模型和分词器
model_name = "Qwen/Qwen2.5-1.5B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, # device_map='auto')# 创建pipeline
pipe = pipeline("text-generation",model=model,tokenizer=tokenizer,max_new_tokens=512,temperature=0.7,top_p=0.95,repetition_penalty=1.1,# low_cpu_mem_usage=True
)# 创建LangChain的HuggingFace Pipeline包装器
llm = HuggingFacePipeline(pipeline=pipe)answer = llm.invoke(prompt.format(question=question, context=docs_content))
print(answer)使用ollama运行模型(无需key):
1. 安装Ollama Server:- Windows: 访问 https://ollama.com/download 下载安装包- Linux/Mac: 运行 curl -fsSL https://ollama.com/install.sh | sh2. 下载并运行模型:- 打开终端,运行以下命令下载模型:ollama pull qwen:7b # 下载通义千问7B模型# 或ollama pull llama2:7b # 下载Llama2 7B模型# 或ollama pull mistral:7b # 下载Mistral 7B模型3. 设置环境变量:- 在.env文件中添加:OLLAMA_MODEL=qwen:7b # 或其他已下载的模型名称
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()# 2. 文档分块
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)# 3. 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddingsembeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True}
)# 4. 创建向量存储
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(all_splits)# 5. 构建用户查询
question = "黑悟空有哪些游戏场景?"# 6. 在向量存储中搜索相关文档,并准备上下文内容
retrieved_docs = vector_store.similarity_search(question, k=3)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)# 7. 构建提示模板
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("""基于以下上下文,回答问题。如果上下文中没有相关信息,请说"我无法从提供的上下文中找到相关信息"。上下文: {context}问题: {question}回答:""")# 8. 使用大语言模型生成答案
from langchain_ollama import ChatOllama # pip install langchain-ollama
llm = ChatOllama(model=os.getenv("OLLAMA_MODEL"))
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print(answer.content)
3. 使用框架:用LCEL链重构
管道式数据流像使用 Unix 命令管道 (|) 一样,将不同的处理逻辑串联在一起
# 1. 加载文档
from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader(web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()# 2. 分割文档
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)# 3. 设置嵌入模型
from langchain_openai import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()# 4. 创建向量存储
from langchain_core.vectorstores import InMemoryVectorStorevectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(all_splits)# 5. 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})# 6. 创建提示模板
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_template("""
基于以下上下文,回答问题。如果上下文中没有相关信息,
请说"我无法从提供的上下文中找到相关信息"。
上下文: {context}
问题: {question}
回答:""")# 7. 设置语言模型和输出解析器
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthroughllm = ChatOpenAI(model="gpt-3.5-turbo")# 8. 构建 LCEL 链
# 管道式数据流像使用 Unix 命令管道 (|) 一样,将不同的处理逻辑串联在一起
chain = ({"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)), "question": RunnablePassthrough()} | prompt | llm | StrOutputParser()
) # 查看每个阶段的输入输出# 9. 执行查询
question = "黑悟空有哪些游戏场景?"
response = chain.invoke(question) # 同步,可以换成异步执行
print(response)使用ollama:
# 1. 加载文档
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader(web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()# 2. 分割文档
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)# 3. 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddingsembeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True}
)# 4. 创建向量存储
from langchain_core.vectorstores import InMemoryVectorStorevectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(all_splits)# 5. 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})# 6. 创建提示模板
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_template("""
基于以下上下文,回答问题。如果上下文中没有相关信息,
请说"我无法从提供的上下文中找到相关信息"。
上下文: {context}
问题: {question}
回答:""")# 7. 设置语言模型和输出解析器
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthroughllm = ChatOllama(model=os.getenv("OLLAMA_MODEL"))# 8. 构建 LCEL 链
# 管道式数据流像使用 Unix 命令管道 (|) 一样,将不同的处理逻辑串联在一起
chain = ({# 检索器输入:问题字符串, 输出:Document列表# lambda函数输入:Document列表, 输出:合并后的文本字符串"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)),# RunnablePassthrough输入:问题字符串, 输出:原样传递问题字符串"question": RunnablePassthrough()}# prompt输入:字典{"context":文本,"question":问题}, 输出:格式化后的提示模板字符串| prompt# llm输入:提示模板字符串, 输出:ChatMessage对象| llm# StrOutputParser输入:ChatMessage对象, 输出:回答文本字符串| StrOutputParser()
)# 查看每个阶段的输入输出
question = "测试问题"# 1. 检索器阶段
retriever_output = retriever.invoke(question)
print("检索器输出:", retriever_output)# 2. 合并文档阶段
context = "\n\n".join(doc.page_content for doc in retriever_output)
print("合并文档输出:", context)# 3. 提示模板阶段
prompt_output = prompt.invoke({"context": context, "question": question})
print("提示模板输出:", prompt_output)# 4. LLM阶段
llm_output = llm.invoke(prompt_output)
print("LLM输出:", llm_output)# 5. 解析器阶段
final_output = StrOutputParser().invoke(llm_output)
print("最终输出:", final_output)# 9. 执行查询
question = "黑悟空有哪些游戏场景?"
response = chain.invoke(question) # 同步,可以换成异步执行
4. 使用框架:用LangGraph重构
LangGraph的优势:
1. 基于状态(State)驱动的执行模型
2. DAG(有向无环图)任务流
3. 任务模块化
4. 灵活的控制流
5. 并行执行
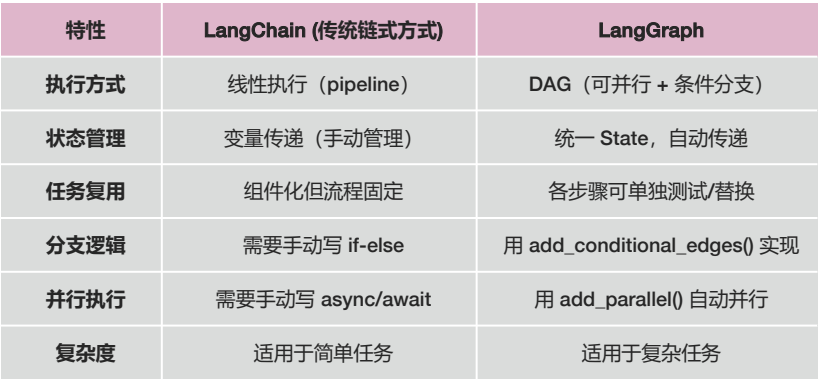
# 1. 加载文档
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()# 2. 文档分块
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)# 3. 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True}
)# 4. 创建向量存储aa
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(all_splits)# 5. 定义RAG提示词
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")# 6. 定义应用状态
from typing import List
from typing_extensions import TypedDict
from langchain_core.documents import Document
class State(TypedDict):question: strcontext: List[Document]answer: str# 7. 定义检索步骤
def retrieve(state: State):retrieved_docs = vector_store.similarity_search(state["question"])return {"context": retrieved_docs}# 8. 定义生成步骤
def generate(state: State):from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4")docs_content = "\n\n".join(doc.page_content for doc in state["context"])messages = prompt.invoke({"question": state["question"], "context": docs_content})response = llm.invoke(messages)return {"answer": response.content}# 9. 构建和编译应用
from langgraph.graph import START, StateGraph # pip install langgraph
graph = (StateGraph(State).add_sequence([retrieve, generate]).add_edge(START, "retrieve").compile()
)# 10. 运行查询
question = "黑悟空有哪些游戏场景?"
response = graph.invoke({"question": question})
print(f"\n问题: {question}")
print(f"答案: {response['answer']}")
使用ollama
# 1. 加载文档
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_paths=("https://zh.wikipedia.org/wiki/黑神话:悟空",)
)
docs = loader.load()# 2. 文档分块
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)# 3. 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True}
)# 4. 创建向量存储aa
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
vector_store.add_documents(all_splits)# 5. 定义RAG提示词
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")# 6. 定义应用状态
from typing import List
from typing_extensions import TypedDict
from langchain_core.documents import Document
class State(TypedDict):question: strcontext: List[Document]answer: str# 7. 定义检索步骤
def retrieve(state: State):retrieved_docs = vector_store.similarity_search(state["question"])return {"context": retrieved_docs}# 8. 定义生成步骤
def generate(state: State):from langchain_ollama import ChatOllamallm = ChatOllama(model=os.getenv("OLLAMA_MODEL"))docs_content = "\n\n".join(doc.page_content for doc in state["context"])messages = prompt.invoke({"question": state["question"], "context": docs_content})response = llm.invoke(messages)return {"answer": response.content}# 9. 构建和编译应用
from langgraph.graph import START, StateGraph # pip install langgraph
graph = (StateGraph(State).add_sequence([retrieve, generate]).add_edge(START, "retrieve").compile()
)# 10. 运行查询
question = "黑悟空有哪些游戏场景?"
response = graph.invoke({"question": question})
print(f"\n问题: {question}")
print(f"答案: {response['answer']}")
3. 如何优化RAG系统
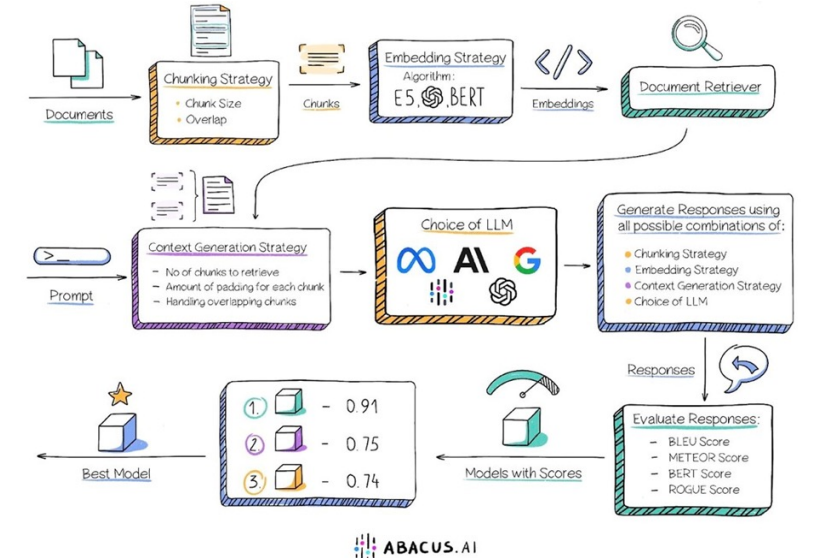
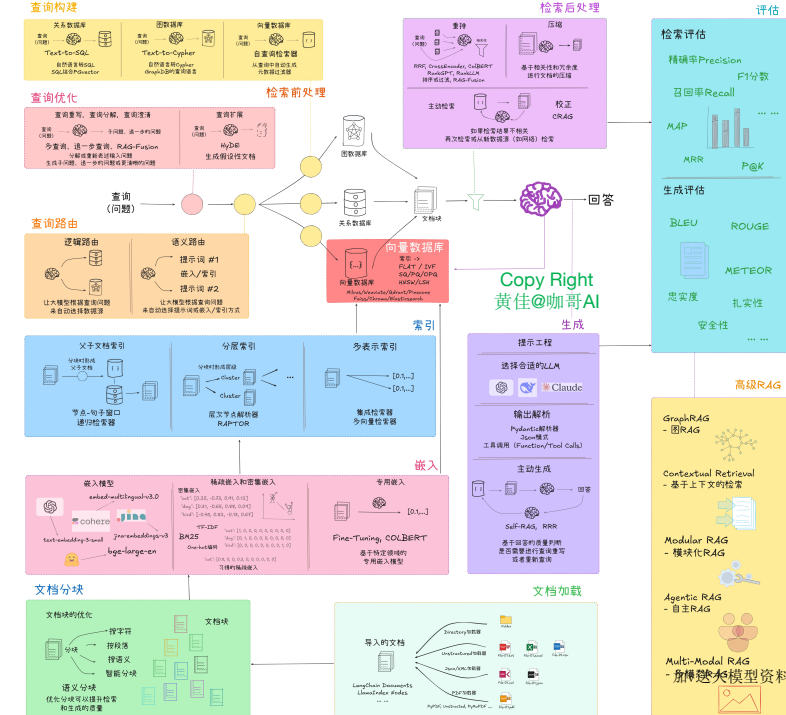
参考资料:https://github.com/huangjia2019/rag-in-action.git