通用算法与深度学习基础
秋招抱佛脚之作,由GPT提供内容大纲。
此博客每日更新,直至博主本人拿到满意的算法offer为止。
目录
1. 数学与概率统计
线性代数:矩阵乘法、特征值/特征向量、SVD、PCA 原理★★★★★
概率论:条件概率、贝叶斯公式、联合分布、期望/方差★★★★★
最大似然估计与最大后验估计★★★★★
信息论:熵、交叉熵、KL散度、互信息★★★★
优化理论:梯度下降、牛顿法、动量法、Adam、学习率调度★★★★★
凸优化与约束优化基础★★★
高数基础:偏导数链式法则、泰勒展开★★★
2. 机器学习基础
经典算法:逻辑回归、SVM、KNN、朴素贝叶斯、决策树★★★★★
集成方法:Random Forest、GBDT、XGBoost、LightGBM★★★★★
模型评估:ROC/AUC、Precision-Recall、F1-score、混淆矩阵★★★★★
欠拟合与过拟合解决方案:正则化、数据增强、早停★★★★★
特征工程:标准化/归一化、特征交互、降维(PCA、t-SNE)★★★★
超参数搜索:网格搜索、随机搜索、Bayesian Optimization★★★★
3. 深度学习核心
神经网络基本结构:前向传播/反向传播★★★★★
CNN:卷积/池化、padding、stride、感受野★★★★★
RNN / LSTM / GRU:序列建模原理★★★★
Transformer 架构:多头注意力、位置编码、残差连接★★★★★
残差网络、DenseNet 与梯度流问题★★★★★
归一化技术:BN vs LN vs GN★★★★★
激活函数对比:ReLU、LeakyReLU、GELU、SiLU★★★★
优化技巧:梯度裁剪、学习率 warmup、Lookahead★★★
正则化方法:Dropout、Weight Decay、Label Smoothing★★★★
4. 工程与部署能力
Python 数据处理:Numpy/Pandas 熟练度★★★★★
PyTorch 基础:Dataset、Dataloader、Module、Optimizer★★★★★
模型保存与加载、Checkpoint 管理★★★★★
GPU 加速与显存优化(混合精度、梯度累积)★★★★
模型部署:ONNX、TensorRT、TorchScript★★★★
Linux/Git/Docker 基础★★★
1. 数学与概率统计
(1)线性代数:矩阵乘法、特征值/特征向量、SVD、PCA 原理★★★★★
矩阵乘法:
如图,矩阵,
相乘,可得到矩阵
C矩阵中c1的计算:
普遍地,
结果矩阵 C 第 i 行第 j 列元素 = 左矩阵A的第 i 行元素逐个乘右矩阵 B 第 j 列的元素的结果之和。
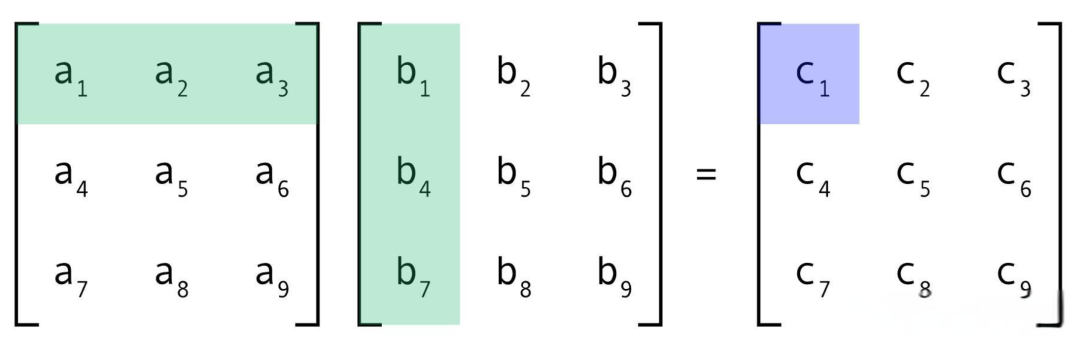
关于矩阵乘法的本质,可以理解为是一系列线性变换的复合,具体可参考此视频:
3Blue1Brown:线性代数的本质 - 04 - 矩阵乘法与线性变换复合
特征值/特征向量:
数学上定义,当 时,
是
的特征向量,
是
的特征值。
我们来通俗地理解一下。由于上面我们说到了矩阵相乘的本质是进行线性变换(向量也可以看作是一个 n 行 1 列的矩阵),而几何上,线性变换可能对向量进行旋转、缩放、剪切等操作,那么有:
- 特征向量:在变换中方向不变的向量(仅被拉伸或压缩)。
- 特征值:对应的缩放因子

举个例子,在上图中,向量经过变换
之后方向不变,只是长度增加,故
是
的特征向量,特征值则是2。
SVD 奇异值分解:
此处参考 知乎链接

奇异值分解是 LoRA微调的理论基础。正因为矩阵可以分解为,后续才可以用
和
两个参数量显著减小的矩阵,对网络参数进行更新,得到接近全量更新的结果。
PCA(priority component analysis)主成分分析:
对高维数据进行降维
参考链接 知乎 - 主成分分析

(2)概率论:条件概率、贝叶斯公式、联合分布、期望/方差★★★★★
条件概率:
贝叶斯公式:
联合分布:
期望:对数据取值和取值概率相乘并进行求和。
方差:可用来衡量数据分布散度。方差越小,数据分布越集中。
(3)最大似然估计与最大后验估计★★★★★
最大似然估计:
最大后验估计:
(4)信息论:熵、交叉熵、KL散度、互信息★★★★☆
(5)优化理论:梯度下降、牛顿法、动量法、Adam、学习率调度★★★★★
梯度下降:
牛顿法:
动量法:
Adam:
(6)凸优化与约束优化基础★★★☆☆
高数基础:偏导数链式法则、泰勒展开★★★☆☆
2. 机器学习基础
(1)经典算法:逻辑回归、SVM、KNN、朴素贝叶斯、决策树★★★★★
逻辑回归:
SVM:
KNN(K-nearest neighbours):K最邻近算法,选取已知类别的数据中和当前数据 x 距离最近的 K个点,根据这K个点的类别,来判断点 x 所属的类别
集成方法:Random Forest、GBDT、XGBoost、LightGBM★★★★★
模型评估:ROC/AUC、Precision-Recall、F1-score、混淆矩阵★★★★★
ROC/AUC:
Precision:准确率,预测正确的样本数 ➗ 总样本数
Recall:召回率,
欠拟合与过拟合解决方案:正则化、数据增强、早停★★★★★
欠拟合:模型在当前数据集的拟合不佳,即通常所说的训练未收敛(?),可以理解为模型在当前数据集上的表现不好。
过拟合:模型被过度限制在当前数据集的特征空间,导致对训练集外的数据预测准确率下降,通常由训练轮数过大导致,表现为train loss下降或不变,val loss上升
特征工程:标准化/归一化、特征交互、降维(PCA、t-SNE)★★★★☆
超参数搜索:网格搜索、随机搜索、Bayesian Optimization ★★★★☆
3. 深度学习核心
神经网络基本结构:前向传播/反向传播★★★★★
前向传播:
反向传播:
CNN:卷积/池化、padding、stride、感受野★★★★★
卷积:
池化:
padding:填充
stride:
感受野:
RNN / LSTM / GRU:序列建模原理★★★★☆
参考链接:CSDN - 长短时记忆网络
RNN:循环神经网络。 t 时的输出 由 t 时刻的输入 x_t 和 t-1 时的隐藏状态决定
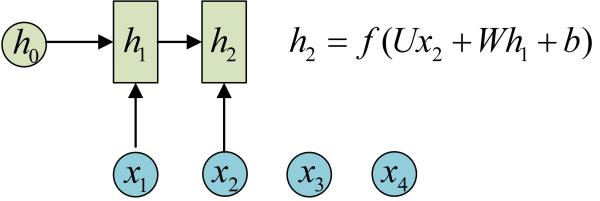
为什么叫“循环”神经网络嘞?因为它还可以表示成这样:

在这个结构中,每个神经网络的模块,读取某个输入
和上一时间步的隐藏状态
,并输出一个值
。“循环”之处在于,每个
都经过 共享的 模块
,产生下一个隐藏状态,再次输入模块
。
LSTM(Long-short term memory):长短时记忆网络
RNN 的结构如此清晰明了,看上去天然适用于序列类输入(例如文本或音频),然而实际上, 在递归神经网络中,获得小梯度更新的层会停止学习—— 那些通常是较早的层。
由于这些层不学习,RNN会忘记它在较长序列中以前看到的内容,因此RNN只具有短时记忆,即对于时刻 t ,上一时间步的输入 对当前时刻的输入x_{t} 的影响显然会强于
。如果一条序列足够长,那它们将很难将信息从较早的时间步传送到后面的时间步。
而LSTM——一种RNN特殊的类型,可以学习长期依赖信息。LSTM和基线RNN并没有特别大的结构不同,但是它们用了不同的函数来计算隐状态。
LSTM的“记忆”我们叫做细胞/cells,它的输入为前状态和当前输入x_t。这些“细胞”会决定哪些之前的信息和状态需要保留/记住,而哪些要被抹去。实际的应用中发现,这种方式可以有效地保存很长时间之前的关联信息。
LSTM有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个sigmoid神经网络层和一个pointwise乘法的非线性操作。
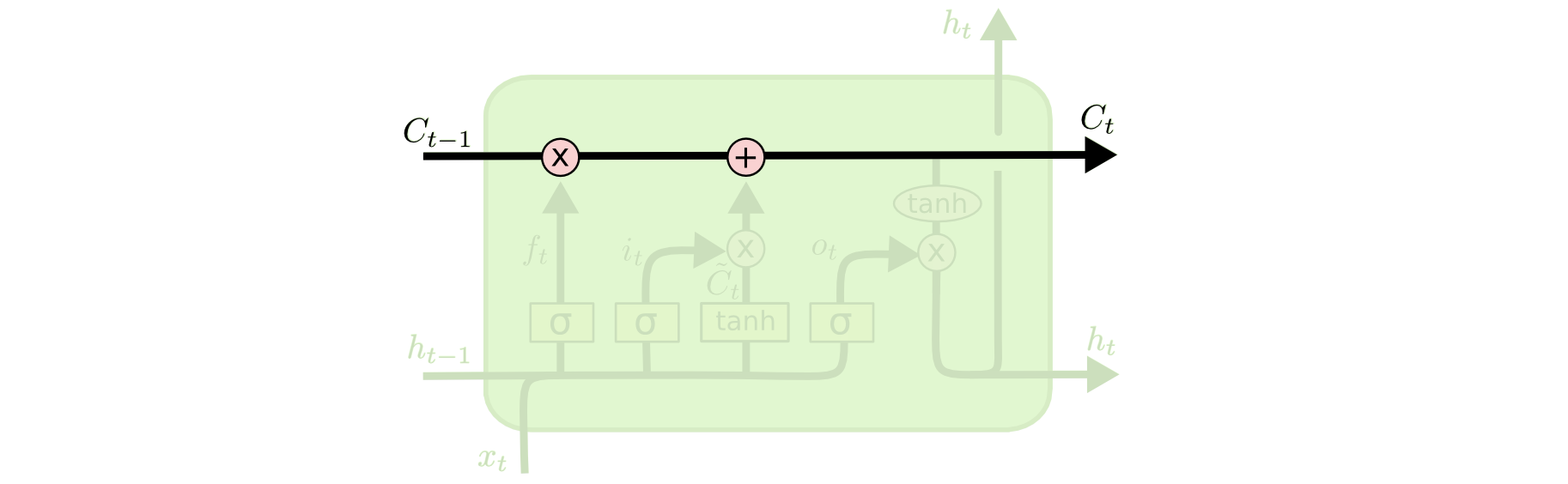
LSTM内部包括三种类型的门结构:遗忘门/忘记门、输入门和输出门,来保护和控制细胞状态。
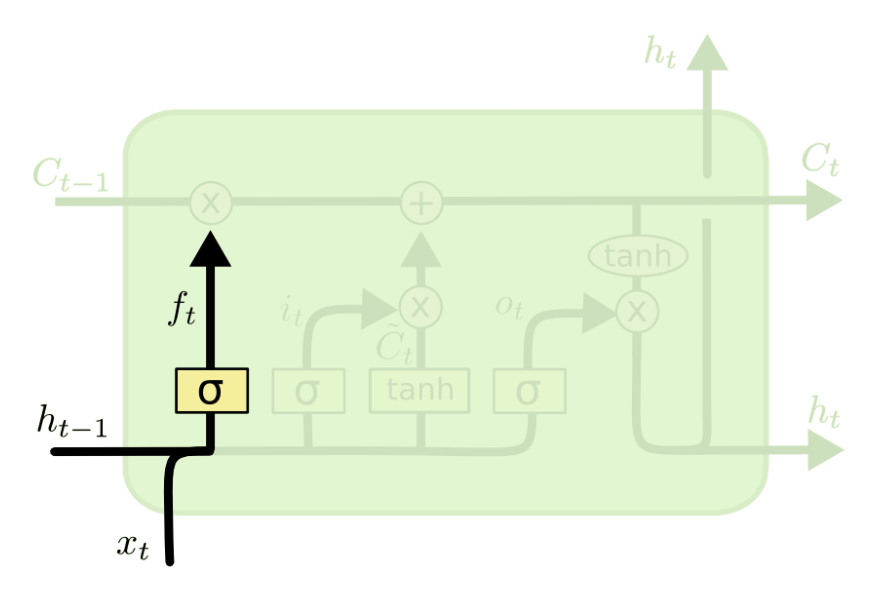 遗忘门:选择性遗忘之前的内容‘
遗忘门:选择性遗忘之前的内容‘![]()
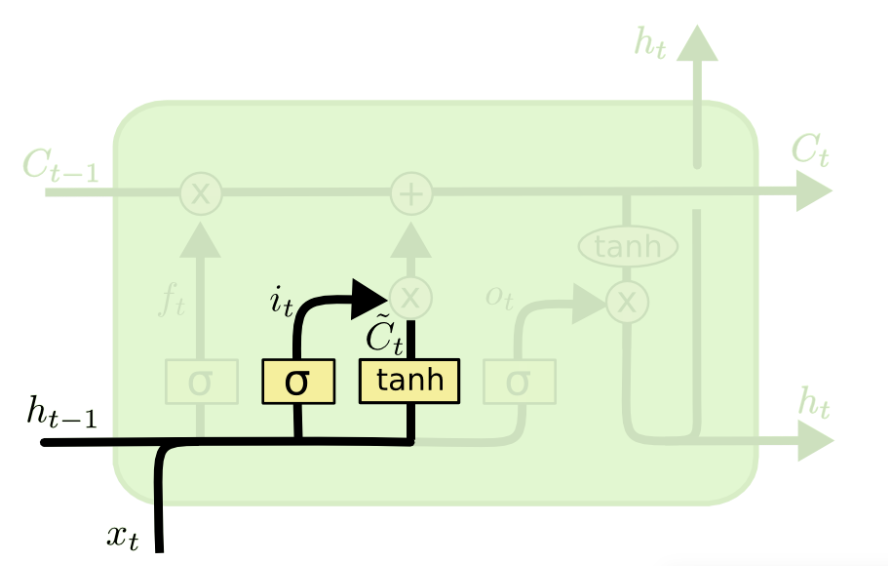 记忆门:决定保留哪些内容
记忆门:决定保留哪些内容
这里包含两个部分:
- 第一,sigmoid层称“输入门层”决定我们要更新什么值;
- 第二,一个tanh层创建一个新的候选值向量
,会被加入到状态中
其中 ,
,
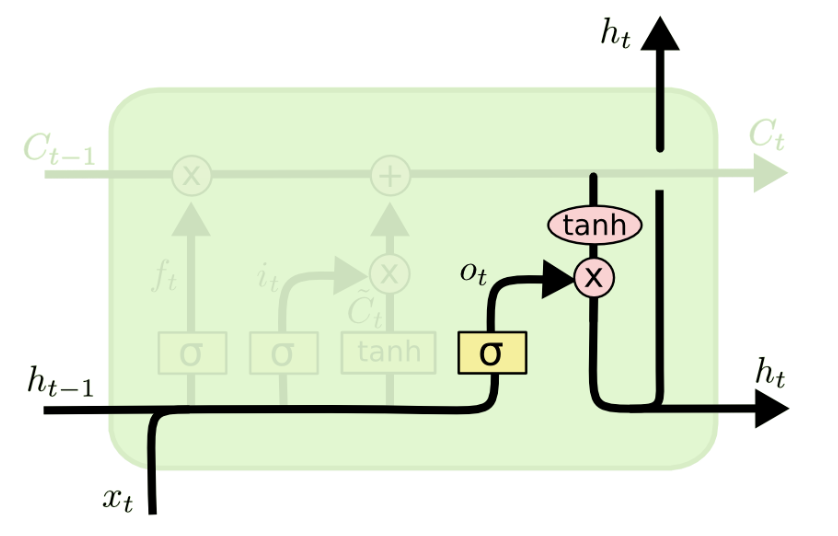 输出门:在当前时间步细胞状态
输出门:在当前时间步细胞状态 的参与下(注意!这里不是上一时间步的细胞状态,因为其已经和通过遗忘门、记忆门的运算结果进行了运算),根据前一时间步隐藏状态
和当前时间步输入
得到新的隐藏状态。
你可以理解为循环神经网络的输出本质上是时刻 t 的隐藏状态。
更新细胞状态(仅用到遗忘门和输入门,放在这里是为了将三个门先介绍清楚):
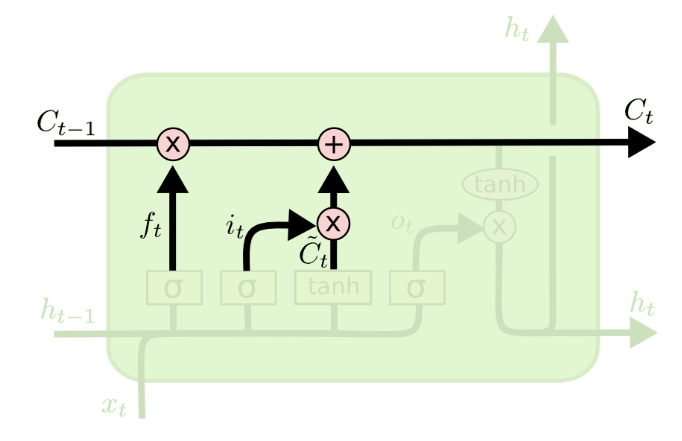 细胞状态与遗忘门的输出相乘,决定忘记哪些内容;
细胞状态与遗忘门的输出相乘,决定忘记哪些内容;
![]() 然后与输入门的输入相加,决定记住哪些新内容。
然后与输入门的输入相加,决定记住哪些新内容。
GRU (Gated Recurrent Unit) 门控循环单元:

将LSTM的忘记门和输入门合成了一个单一的更新门,同时还混合了细胞状态和隐藏状态。
为了便于理解,把上图右侧中的前三个公式展开一下

![]()

这里面有个小问题,r_t 和 z_t 都是对 、
做的Sigmoid非线性映射,那区别在哪呢?原因在于GRU把忘记门和输入门合二为一了,而 z_t 是属于要记住的,反过来 1-z_t 则是属于忘记的,相当于对输入
、
做了一些更改/变化,而 r_t 则相当于先见之明的把输入、在 z_t / 1-z_t 对其做更改/变化之前,先事先存一份原始的,最终在 h_t 那做一个tanh变化。
Transformer 架构:多头注意力、位置编码、残差连接★★★★★
残差网络、DenseNet 与梯度流问题★★★★★
归一化技术:BN vs LN vs GN★★★★★
激活函数对比:ReLU、LeakyReLU、GELU、SiLU★★★★☆
优化技巧:梯度裁剪、学习率 warmup、Lookahead★★★☆☆
正则化方法:Dropout、Weight Decay、Label Smoothing★★★★☆
4. 工程与部署能力
-
Python 数据处理:Numpy/Pandas 熟练度★★★★★
-
PyTorch 基础:Dataset、Dataloader、Module、Optimizer★★★★★
-
模型保存与加载、Checkpoint 管理★★★★★
-
GPU 加速与显存优化(混合精度、梯度累积)★★★★☆
-
模型部署:ONNX、TensorRT、TorchScript★★★★☆
-
Linux/Git/Docker 基础★★★☆☆