译 | 结合聚类与注意力机制的强化学习在个性化促销中的应用
本篇为翻译文章,原文为:Group-Relative Policy Optimization(GRPO) for Business Decision Systems
文章目录
- 引言
- 组相对策略优化 (GRPO)
- 演员-评论家框架 (Actor–Critic Framework)
- GRPO 机制
- 示例说明
- 算法步骤
- GRPO 为何对商业至关重要
- 集群自适应 GRPO:为特定细分市场定制策略头
- 集群自适应 GRPO 机制
- 集群自适应 GRPO 算法步骤
- Transformer-GRPO:利用基于注意力的表示增强策略学习
- Transformer-GRPO 算法步骤
- 代码实验与结果
- 最终思考
照片由 Stephen Dawson 拍摄于 Unsplash
引言
本文基于我早期的研究“通过离线策略强化学习探索商业用例中的聚类最优策略”,在该研究中,我使用离线客户日志和逆倾向得分(Inverse Propensity Scoring)比较了单头和聚类强化学习(RL)模型在个性化促销中的效果。
传统的 RL 方法(如 PPO)严重依赖评论家网络(critic networks),这增加了计算开销,并可能导致训练不稳定。受近期大型语言模型对齐(如 DeepSeek-LM)进展的启发,我探索了组相对策略优化(GRPO)——一种无评论家的替代方案,它使用简单的分组和行动基线来减少方差并加速收敛。GRPO 的简洁性带来了更快的学习速度和更低的资源消耗,使其在实际商业系统中尤具吸引力。
我旨在探究最初在语言任务中取得成功的 GRPO 是否也能帮助解决现实世界中的商业问题。在商业领域,公司通常需要同时处理多个目标——如增加利润、保持公平性和维护品牌调性——但仍需使用单一策略进行决策。GRPO 是一个自然的选择:它将每个目标或客户群体视为独立的“组”,并在一个稳定、简洁的框架内同时学习所有目标,而无需依赖评论家网络或手动调整奖励权重。
本文有三个目标。首先,我将用商业友好的语言解释 GRPO,将其定位为在有分组数据或聚类可用时,替代 PPO 或 A2C 的轻量级方案。其次,我将其应用于一个真实用例——优惠券策略个性化——其中分组基线明显带来了利润增长。第三,我将 GRPO 扩展到两个方向:
- 集群自适应 GRPO (Cluster-Adaptive GRPO),它将多个专家头与一个轻量级门控网络配对,将 IPS 估计的投资回报率(ROI)从 0.080.080.08 提升至 0.960.960.96。
- Transformer-GRPO,它换用一个紧凑的状态-动作 Transformer 以获得更丰富的表示,将 IPS 利润提升至 3.783.783.78,同时保持了 GRPO 的稳定性。
通过在整个过程中使用相同的数据集和评估设置,我们分离了每次改进的效果。本文的其余部分将从理论转向实现,并最后就何时在商业 RL 系统中使用聚类或 Transformer 值得增加额外复杂性提供指导。
组相对策略优化 (GRPO)
演员-评论家框架 (Actor–Critic Framework)
强化学习算法通常分为两类——基于价值(value-based)和基于策略梯度(policy-gradient)——每类都有其独特的方式来评估和改进决策质量。
基于价值的方法引入一个评论家 Qϕ(s,a)Q_\phi(s,a)Qϕ(s,a),训练它来近似真实的收益:
Qϕ(s,a)=E[Rt∣St=s,At=a]Q_\phi(s,a) = \mathbb{E}[R_t | S_t=s, A_t=a] Qϕ(s,a)=E[Rt∣St=s,At=a]
在实践中,我们通过最小化贝尔曼误差来拟合 QϕQ_\phiQϕ:
L(ϕ)=E[(Rt−Qϕ(St,At))2]\mathcal{L}(\phi) = \mathbb{E}[(R_t - Q_\phi(S_t, A_t))^2] L(ϕ)=E[(Rt−Qϕ(St,At))2]
一旦 QϕQ_\phiQϕ 准确,策略就简单地选择:
π(s)=argmaxaQϕ(s,a)\pi(s) = \arg\max_a Q_\phi(s,a) π(s)=argamaxQϕ(s,a)
在这种设置中,评论家的价值估计间接驱动策略的改进。
策略梯度方法跳过了学习一个完整的评论家。它们参数化一个随机策略 πθ(a∣s)\pi_\theta(a|s)πθ(a∣s),并直接调整其参数 θ\thetaθ 以攀登预期收益的曲面:
J(θ)=Es∼ρπ,a∼πθ[R(s,a)]J(\theta) = \mathbb{E}_{s \sim \rho^\pi, a \sim \pi_\theta}[R(s,a)] J(θ)=Es∼ρπ,a∼πθ[R(s,a)]
策略梯度为:
∇θJ(θ)=Es∼ρπ,a∼πθ[∇θlogπθ(a∣s)Aπ(s,a)]\nabla_\theta J(\theta) = \mathbb{E}_{s \sim \rho^\pi, a \sim \pi_\theta}[\nabla_\theta \log \pi_\theta(a|s) A^\pi(s,a)] ∇θJ(θ)=Es∼ρπ,a∼πθ[∇θlogπθ(a∣s)Aπ(s,a)]
其中 Aπ(s,a)A^\pi(s, a)Aπ(s,a) 衡量动作 aaa 在状态 sss 下比平均水平好多少。在演员-评论家变体中,一个学习到的评论家提供 QQQ 或 VVV。在纯策略梯度(REINFORCE)中,我们用任何无偏估计器替换 AAA——通常是:
A(s,a)=R−b(s)A(s,a) = R - b(s) A(s,a)=R−b(s)
使用一个简单的基线 b(s)b(s)b(s) 来减少方差,但从不偏置梯度。
总结如下:
- 基于价值 = 学习一个评论家 QQQ,然后通过 arg max 推导出一个策略。
- 策略梯度 = 直接通过 ∇θJ(θ)\nabla_\theta J(\theta)∇θJ(θ) 调整演员 πθ\pi_\thetaπθ,可选择使用基线,但从不需要完整的价值函数估计。
GRPO 机制
组相对策略优化(GRPO)坚定地属于策略梯度阵营,并继承了其基本的更新规则,但它在两个数学上决定性的方面与 PPO/PTR 家族不同。
首先,GRPO 是完全无评论家的。它不学习一个参数化的价值网络 VψV_\psiVψ,而只保留演员 πθ(a∣s)\pi_\theta(a|s)πθ(a∣s);策略梯度是相对于一个位于计算图之外的标量控制变量计算的。对于每个组 g∈{1,…,K}g \in \{1,\dots,K\}g∈{1,…,K} 和每个动作 a∈{0,1,2}a \in \{0, 1, 2\}a∈{0,1,2}(这里指:优惠券级别),GRPO 维护一个存储为浮点数的单一基线值 bg,ab_{g, a}bg,a。其中,
bg,a=E[R∣G=g,A=a]b_{g,a} = \mathbb{E}[R | G=g, A=a] bg,a=E[R∣G=g,A=a]
每个样本的优势计算如下:
Δi=Ri−bgi,ai\Delta_i = R_i - b_{g_i, a_i} Δi=Ri−bgi,ai
其次,这个查找表作为一个显式的控制变量。由于 bg,ab_{g, a}bg,a 是 (g,a)(g, a)(g,a) 的确定性函数且不依赖于 θ\thetaθ,我们有(证明在此省略):
∇θEs,a∼πθ[logπθ(a∣s)(R−bg,a)]=Es,a∼πθ[∇θlogπθ(a∣s)(R−bg,a)]\nabla_\theta \mathbb{E}_{s,a \sim \pi_\theta}[\log \pi_\theta(a|s) (R - b_{g,a})] = \mathbb{E}_{s,a \sim \pi_\theta}[\nabla_\theta \log \pi_\theta(a|s) (R - b_{g,a})] ∇θEs,a∼πθ[logπθ(a∣s)(R−bg,a)]=Es,a∼πθ[∇θlogπθ(a∣s)(R−bg,a)]
因此减去它能保持梯度的无偏性:
∇θJ(θ)=Es,a∼πθ[∇θlogπθ(a∣s)(R−bg,a)]\nabla_\theta J(\theta) = \mathbb{E}_{s,a \sim \pi_\theta}[\nabla_\theta \log \pi_\theta(a|s) (R - b_{g,a})] ∇θJ(θ)=Es,a∼πθ[∇θlogπθ(a∣s)(R−bg,a)]
在代码中,这变成了一行:
adv = R - baseline[C, A]
loss = -(logp_a * adv.detach()).mean() - β * entropy
每个组-动作的基线 bg,ab_{g, a}bg,a 使用带上界钳位的指数加权移动平均进行实时更新:
bg,a←max(bg,a,(1−α)bg,a+αR)b_{g,a} \leftarrow \max(b_{g,a}, (1-\alpha)b_{g,a} + \alpha R) bg,a←max(bg,a,(1−α)bg,a+αR)
GRPO 使用一个简单的表格来跟踪每个组和动作的平均奖励,随时间缓慢更新,并且只允许其增加。这个表格扮演了与评论家相同的角色,通过减少训练噪声——但不需要额外的网络或冒着不稳定的风险。
简而言之,GRPO 只保留了通常的演员-评论家设置中的“演员”部分,完全去掉了评论家,并通过减去一个基线来获得稳定、高效的学习。
示例说明
GRPO 基于一个简单实用的想法,无论在数学上还是在日常商业中都很有意义。这里有一个简单的例子来说明它的工作原理。
一家咖啡连锁店在三个区域经营店铺:市中心、校园区和郊区。每天,咖啡师会选择三种优惠券之一——0元、3元或6元折扣——给下一位顾客。经理记录每次访问:社区、优惠券和所产生的利润。
随着数据的增长,一个关键问题出现了:“我们能否学习一个规则来帮助咖啡师为每位顾客选择最佳优惠券以最大化利润?”传统的强化学习可能会使用一个评论家网络来估计长期价值。GRPO 采取了一条更轻量的路线——它跳过了评论家,而是使用基于组的模式(如社区和优惠券)来指导决策,噪声更小,更新更简单。
对于每个社区-优惠券对,经理在一个袖珍分类账中创建一个单元格:
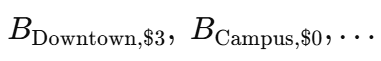
开始时,每个单元格都是零。当一条新的日记记录 (ni,ci,pi)(n_i, c_i, p_i)(ni,ci,pi) 进来时,她只更新一个数字:
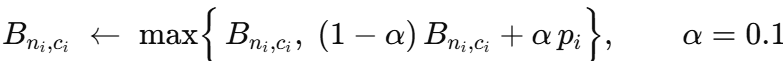
“max”规则确保了一次异常高的利润(比如来自一个大客户)可以提高基线,但绝不会降低它。
策略网络 πθ(c∣n,features)\pi_\theta(c|n, \text{features})πθ(c∣n,features) 根据顾客的上下文建议提供哪种优惠券。当添加一条新的日记条目时,学习只关注利润的“惊喜”部分:
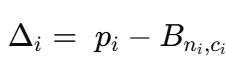
如果实际利润 pip_ipi 与该组和优惠券已有的预期相符,那么更新 Δi\Delta_iΔi 很小,只会轻微调整策略。但如果一张优惠券突然效果非常好——比如说,在校园区获得了一笔大利润——那么 Δi\Delta_iΔi 就会很大,网络会增加在类似的校园区案例中再次提供该优惠券的几率。
然后,演员接收到这个调整后的信号:
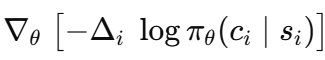
而基线更新则作为一个慢反馈循环,使未来的惊喜保持中心化。
在单个社区内,原始利润 pip_ipi 与其分类账条目 Bni,ciB_{n_i, c_i}Bni,ci 之间的相关性很高;减去基线可以消除很多噪声——比如随机的天气或不寻常的顾客——因此学习变得更加稳定。重要的是,这不会改变整体的学习方向,因为基线不依赖于策略的参数。
仅凭演员网络和一个简单的五行更新基线表,训练变得快速高效——只需通过一个 softmax MLP 进行一次快速的前向和后向传播。在真实的 A/B 测试中,校园区的咖啡师很快学会了更频繁地发放3元优惠券,正如数据所建议的那样。与此同时,市中心则坚持使用0元优惠券。所有这一切都无需评论家或调整复杂的价值损失项——这就是 GRPO 的好处。
算法步骤
初始化。
— 用 BGMM 对每个归一化的特征向量 sis_isi 进行聚类 → 得到聚类ID cic_ici。
— 随机初始化演员参数 θ\thetaθ。
— 对所有 k∈{0,1,2},a∈{0,1,2}k \in \{0,1,2\}, a \in \{0,1,2\}k∈{0,1,2},a∈{0,1,2},设置基线表 bk,a=0b_{k, a}=0bk,a=0。
小批量采样。
从离线日志中抽取一个大小为 B=2,048B = 2,048B=2,048 的集合 BBB:(si,ai,ri,ci)(s_i, a_i, r_i, c_i)(si,ai,ri,ci)。
梯度更新。
对每个样本计算:
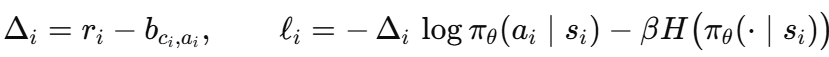
其中 H(⋅)H(\cdot)H(⋅) 是动作熵,β=10−3\beta = 10^{-3}β=10−3。
反向传播平均损失,并用 Adam 更新 θ\thetaθ。
基线刷新。
对相同的小批量进行更新:
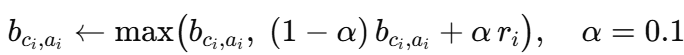
将这些部分组合起来,得到下面的循环:
while not converged: batch ← random_sample(logged_data, B) for (s,a,r,c) in batch: Δ = r - b[c,a] L += -(Δ * log πθ(a|s)) # accumulate loss b[c,a] = max( b[c,a], (1-α)*b[c,a] + α*r ) # update baseline L = L/B - β * entropy(batch) θ ← θ - η ∇θ L # Adam step
这就是 GRPO 所需的全部“评论家”。它仍然是一个简单的策略梯度方法,没有价值估计的复杂性——非常适合动作空间小但客户群体高度多样化的场景。
GRPO 为何对商业至关重要
在商业环境中,客户日志通常是不平衡的:单个表现最佳的优惠券可能贡献了大部分利润,而其他优惠券贡献甚微。这使得 RL 算法难以高效学习——奖励充满噪声,学习信号微弱。PPO 试图通过使用评论家和谨慎的更新来解决这个问题,但当反馈稀疏时,评论家常常会过拟合。
GRPO 采取了更简单的路径。它不试图估计完整的价值函数,而是只问一个实际问题:“这个优惠券以前对相似的客户效果如何?”这种基本的基于组的基线减少了随机性,而没有增加额外的模型复杂性,使得学习更快、更稳定。
这些好处表现得非常明显。一旦我们在基本的 GRPO 设置中加入了特定于集群的头和一个小型的门控网络,策略选择更优优惠券的能力就得到了提升。
集群自适应 GRPO:为特定细分市场定制策略头
集群自适应 GRPO 机制
集群自适应 GRPO 扩展了基本的 GRPO 方法,为每个客户细分市场提供其自己的“专家”策略——然后学习一个轻量级的路由器,在推理时选择合适的专家。想象一下三个客户细分——预算型、中档型和高端型购物者——每个群体对0元、3元或6元优惠券的反应都不同。集群自适应 GRPO 不是强迫一个单一的策略覆盖所有情况,而是为每个细分市场构建三个独立的 soft-max 头,并配备一个小型门控网络,为每个新客户决定使用哪个头。
为了让每个头都有一个良好的开端,我们首先用监督学习对它们各自细分市场的日志数据进行预热。具体来说,对于细分市场 kkk,我们最小化:
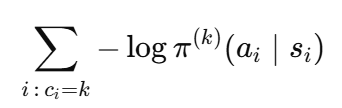
进行五个快速的 epoch,其中 π(k)\pi^{(k)}π(k) 是头 kkk。这种预拟合确保了每个专家在更难的 RL 微调开始之前,就已经大致了解了在其细分市场中哪些优惠券在历史上表现良好。
预热后,每个头进入一个标准的 GRPO 循环,但只处理其细分市场的小批量样本。对于一个大小为 BBB 的小批量,我们收集 {si,ai,ri,ci}\{s_i, a_i, r_i, c_i\}{si,ai,ri,ci}。对于头 kkk,令
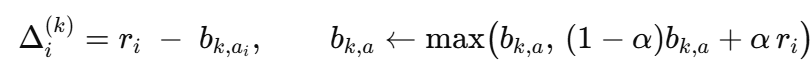
头 kkk 的策略梯度损失为
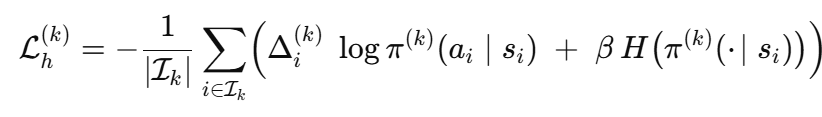
其中 IkI_kIk 是 ci=kc_i = kci=k 的样本索引。这鼓励头 kkk 在其已经表现良好的地方进行专业化,而熵项 HHH 则保持探索的活力。
与此同时,门控网络 γϕ(s)\gamma_\phi(s)γϕ(s) 计算 KKK 个细分市场的 softmax。我们通过结合两个信号来训练它:
一个策略梯度项,使用相同的 Δi\Delta_iΔi,但使用门控选择正确细分市场的对数概率:
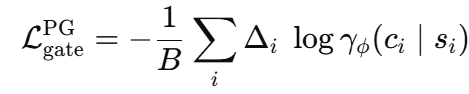
一个小的交叉熵项:
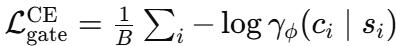
它在早期推动门控向 BGMM 标签靠拢。
总的门控损失为:
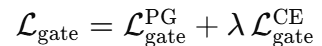
(其中 λ≈0.2\lambda \approx 0.2λ≈0.2)平衡了纯 RL 信号和监督指导,稳定了训练。
通过将多个专业化的头与一个混合损失的门控配对,集群自适应 GRPO 充分利用了两者的优点:量身定制的细分策略加上统一的路由机制,所有这些仍然是无评论家的,并使用每个细分-动作的基线来减少方差。
集群自适应 GRPO 算法步骤
BGMM 聚类: 将日志中的特征向量 sis_isi 聚类成 KKK 个细分 cic_ici。
预热头: 对每个细分 kkk,通过监督交叉熵在其自己的数据上训练 π(k)\pi^{(k)}π(k)。
基线初始化: 对所有细分 kkk 和动作 aaa,初始化 bk,a=0b_{k, a} = 0bk,a=0。
头更新(每个训练步骤):
- 采样小批量 {si,ai,ri,ci}i=1B\{s_i, a_i, r_i, c_i\}_{i=1}^B{si,ai,ri,ci}i=1B。
- 对每个 kkk,计算
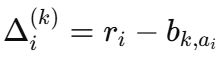
在那些 $c_i = k$ 的样本上。
- 通过对 Lh(k)L_h(k)Lh(k) 进行梯度下降来更新头。
- 用 EMA + max 刷新基线 bk,aib_{k, a_i}bk,ai。
门控更新: 在一个新的小批量上,计算:

然后更新 γϕ\gamma_\phiγϕ。
重复直到收敛。
[BGMM 聚类] → [预热头] ↓
┌────────────────────────────────────┐
│ for step = 1…N: │
│ 采样批次 {(s_i,a_i,r_i,c_i)} │
│ ┌── 头更新 ──────────────┐ │
│ │ for each k: │ │
│ │ Δ_i = r_i − b[k,a_i] ││
│ │ 通过 REINFORCE 更新 π^(k) ││
│ │ 刷新 b[k,a_i] ││
│ └───────────────────────────────┘│
│ ┌── 门控更新 ─────────────┐ │
│ │ Δ_i = r_i − b[c_i,a_i] │ │
│ │ L_pg = −Δ_i·log γ(c_i|s_i) │ │
│ │ L_ce = −log γ(c_i|s_i) │ │
│ │ 通过 L_pg+λL_ce 更新 γ │ │
│ └───────────────────────────────┘│
└────────────────────────────────────┘ ↓
[细分自适应策略和门控]
Transformer-GRPO:利用基于注意力的表示增强策略学习
原始的 GRPO 通过减去一个智能基线来移除评论家,但仍使用一个简单的神经网络(MLP)将客户特征转化为动作分数。当特征很少且行为简单时,这没有问题,但现实世界的用户画像通常涉及复杂的模式——比如浏览分数仅对高收入用户重要,或者优惠券响应随星期几而变化。
为了更好地捕捉这些交互作用而不增加一个完整的价值网络,我们将 MLP 升级为一个基于注意力的编码器,创建了 Transformer-GRPO。策略头仍然是唯一通过梯度下降训练的部分,基线仍然是一个快速的标量更新。唯一的变化是状态-动作信息的嵌入方式,这使得模型能够学习更细致的决策,而不会增加不稳定性。
Transformer-GRPO 的关键思想是将每个可能的优惠券视为其自己的可学习令牌,与客户的特征向量一起添加。以下是其工作步骤。
首先,客户的特征 s∈Rds \in \mathbb{R}^ds∈Rd 被映射到一个密集向量:
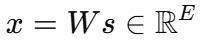
使用一个投影矩阵 WWW。我们还定义一个嵌入矩阵:
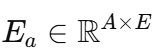
其中每一行对应于 AAA 个可能的优惠券值之一。
现在,对于每个前向传播,我们形成一个短序列(像一个句子),由客户向量和添加到每个优惠券嵌入的相同向量组成:
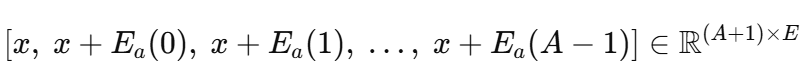
这个序列通过一个两层的 Transformer 编码器。第一个令牌代表单独的客户,而接下来的 AAA 个令牌中的每一个代表一个不同的优惠券“叠加”在客户上。由于自注意力机制将第一个令牌(纯状态)与每个动作增强的令牌混合,分配给令牌 aaa 的输出向量现在编码了该特定优惠券在此客户背景下的行为方式。
编码后,我们丢弃纯客户令牌,只取 AAA 个转换后的与优惠券相关的令牌。将它们平均在一起,然后使用 LayerNorm 进行归一化,形成一个最终的特征向量 hhh:
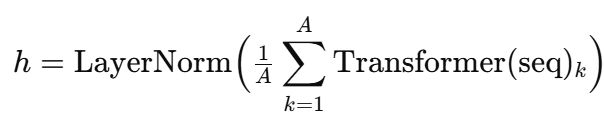
这个向量 hhh 总结了客户与整套优惠券选项的交互方式。然后将其通过一个线性层,产生最终的 logits ℓ∈RA\ell \in \mathbb{R}^Aℓ∈RA,代表每个动作(优惠券)的偏好分数,用于采样或动作选择。
为什么在这个商业案例中要费心使用 Transformer?在标准的 GRPO 中,我们将状态展平并使用一个简单的 MLP 来预测动作。这可行,但它无法捕捉不同优惠券对不同客户的不同行为。例如,“6元折扣”可能只对周末购物者有效,而“3元折扣”更适合工作日的流量。通过直接嵌入每个优惠券-状态对,并让自注意力机制对它们进行比较,Transformer 可以检测到这种条件模式。这使得策略更加精确,尤其是在数据嘈杂或不平衡的情况下,并帮助智能体从更少的例子中更快地学习。
训练仍然严格无评论家。对于一个小批量 (si,ai,ri)(s_i, a_i, r_i)(si,ai,ri),我们计算中心化的优势:
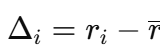
其中 rˉ\bar{r}rˉ 是批次均值,并形成 REINFORCE 损失:
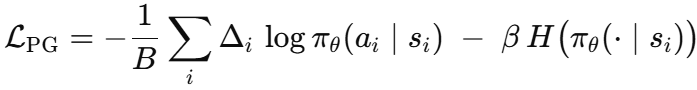
通过演员和 Transformer 编码器的反向传播负责捕捉那些由注意力驱动的关系,而从未引入任何评论家或价值头。
这种设计借用了 GRPO 的中心化奖励基线,但将表示学习完全委托给了自注意力机制。
Transformer-GRPO 算法步骤
- 缓冲区预热: 执行一个随机或 ϵ\epsilonϵ-greedy 策略 10,00010,00010,000 次展示,记录 (s,a,r)(s, a, r)(s,a,r)。
- 小批量采样: 从缓冲区中抽取 B=1,536B = 1,536B=1,536 个三元组。
- 前向传播: 构建状态-动作序列,运行 Transformer,获得 logits、概率和对数概率。
- 优势计算: 减去小批量平均奖励。
- 梯度步骤: 应用带熵奖励的 REINFORCE,并用 Adam 更新演员参数。
- 无基线的在线策略填充: 通过在线策略 πθ\pi_\thetaπθ 收集 400400400 个新样本,将它们附加到循环缓冲区,并重复直到收敛。
┌──────────────────────────────────────┐
│ 1. 用随机 π 初始化缓冲区 │
└──────────────┬───────────────────────┘ │ ▼
┌──────────────────────────────────────┐
│ 2. 从缓冲区采样小批量 (s,a,r) │
└──────────────┬───────────────────────┘ │ ▼
┌──────────────────────────────────────┐
│ 3. 构建令牌 [x,x+E₀,…,x+E₂] │
│ → Transformer → logits ℓ │
└──────────────┬───────────────────────┘ │ ▼
┌──────────────────────────────────────┐
│ 4. Δ = r - r̄ ; L = -Δ·logπ - βH │
└──────────────┬───────────────────────┘ │ ▼
┌──────────────────────────────────────┐
│ 5. 对 θ (仅演员) 进行 Adam 步骤 │
└──────────────┬───────────────────────┘ │ ▼
┌──────────────────────────────────────┐
│ 6. 推出 400 个在线策略样本 │
│ 附加到缓冲区,返回步骤 2 │
└──────────────────────────────────────┘
通过向 GRPO 添加一个基于注意力的编码器——同时保持其无评论家——我们可以捕捉复杂的特征交互,而不会失去其核心的简洁性或稳定性。
代码实验与结果
以下代码在同一个促销数据集上训练了三种无评论家的强化学习变体。在使用 BGMM 对客户进行聚类后,方法A运行标准的单头 GRPO,方法B引入了带门控机制的特定于集群的头,方法C用一个 Transformer 替换了 MLP 编码器,该 Transformer 联合关注状态和动作令牌。每个训练循环都会打印临时的 ROI,并以基于 IPS 的性能评估结束。
代码片段如下所示。
for step in range(1, 5001): Δ = r - b[c,a] loss = -Δ · log πθ(a|s) - β H warm-start heads with CE
for step in range(1, 10001): update head_k on its cluster update gate with hybrid PG + CE for epoch in range(80): logits = actor( Transformer(state+action) ) loss = centred-reward REINFORCE + entropy
以下是打印的输出结果:
===Method A Pure-GRPO===
First 10 FULL actions : [0 0 0 0 0 0 0 0 0 0]
IPS ROI : 0.08
===Method B Cluster-Adaptive GRPO===
First 10 CA actions : [2 2 2 2 2 2 2 2 2 2]
IPS ROI : 0.96
===Method C Transformer-GRPO===
First 10 greedy actions: [0 0 0 0 0 0 0 0 0 0]
IPS ROI : 3.78
方法A的单头 GRPO 策略很快就选择了最安全的选择——“0元折扣”——因为它必须在所有客户类型中进行泛化。没有特定于集群的基线,它无法利用个别细分市场的机会,导致只有很小的 IPS 增益。这凸显了商业中的一个常见问题:统一的策略往往会牺牲利润。
方法B通过为每个客户集群分配一个专用的策略头,并使用一个轻量级的门控网络在它们之间进行选择来解决这个问题。交叉熵预训练为每个专家提供了一个合理的起始区域,而 GRPO 的组相对更新则优化了每个专家的行为。由此产生的 IPS——比方法A高出近一个数量级——表明即使是简单的细分和并行学习也能在保持无评论家的情况下带来显著的利润提升。
方法C用一个 Transformer 编码器取代了手动聚类,该编码器将每个优惠券视为一个可学习的令牌。这些令牌联合关注客户状态和彼此,揭示了 MLP 错过的上下文敏感模式。尽管此版本使用共享的批次均值基线而不是每个集群的基线,但更丰富的编码器弥补了这一点,产生了最高的总体 IPS。这表明注意力可以自动学习软性细分,尽管其权衡是可解释性降低:一些动作乍一看似乎保守,但在更深的特征区域,模型会选择性地部署更高的折扣。
最终思考
我探讨了一个无评论家的算法——组相对策略优化(GRPO),最初用于 LLM 微调——是否能推动真实的商业影响。从 GRPO 简单的组-动作基线开始,我们展示了添加特定于集群的头和门控机制如何提升策略性能。用 Transformer 替换 MLP 进一步捕捉了更丰富的客户-优惠券交互。这个循序渐进的路径展示了 GRPO 如何从基础扩展到复杂,同时保持训练的稳定和高效。
总的来说,我的实验展示了一个配方:
- 从轻量级开始,使用一个策略头和组-动作基线。
- 分层专业化,通过为每个集群训练独立的头和一个小型门控来路由客户。
- 部署注意力,当手动细分效果不佳时,让模型学习其自己细致的分组。
展望未来,现实世界的部署通常需要混合策略——将折扣与定价、追加销售或服务流程相结合。GRPO 可以演变成一个分层的专家混合系统,其中顶层路由器选择策略模块(例如,忠诚度、捆绑销售),而专业化的头则优化具体行动。随着自适应聚类和多目标优化的进步,GRPO 可以作为个性化、实时商业系统的通用决策引擎。
完整的数据集和源代码可在以下地址获取:https://github.com/datalev001/GRPO_exp