【Linux】初识make/makefile

本篇简单介绍一下 make和makefile,进行 make和makefile的一个入门。
1.基本使用
- make:是一个指令
- makefile:是一个文件(m大小写都行)
 myproc依赖myproc.c,要通过gcc -o myproc myproc.c这种依赖方法。依赖方法的前面是tab键,不是空格。
myproc依赖myproc.c,要通过gcc -o myproc myproc.c这种依赖方法。依赖方法的前面是tab键,不是空格。
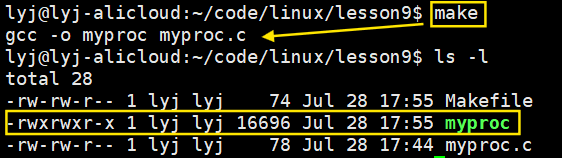
- make命令扫描makefile文件时,从上往下扫描,默认形成第一个目标文件。
//Makefile文件内
myproc:myproc.cgcc -o myproc myproc.c
.PHONY:clean
clean:rm -f myproc 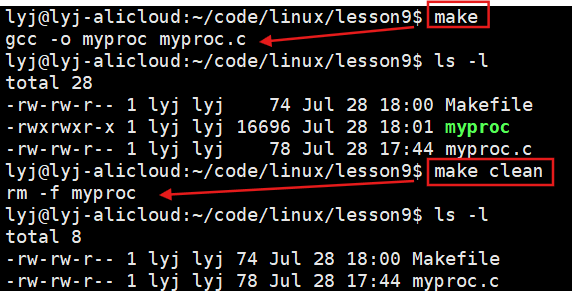
//clean和myproc交换顺序
.PHONY:clean
clean:rm -f myproc
myproc:myproc.cgcc -o myproc myproc.c 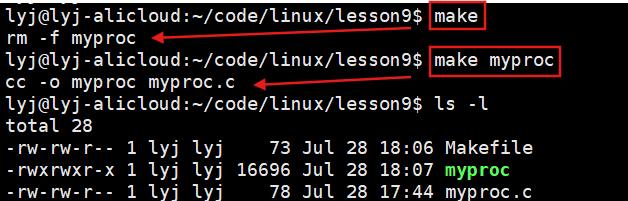
- .PHONY:clean:伪目标,对应的依赖方法和依赖关系总是被执行
clean被.PHONY修饰了,指令就能执行多次
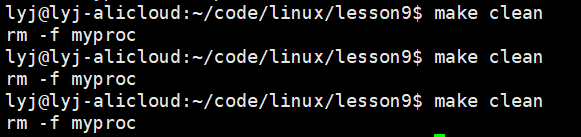
myproc没有被.PHONY修饰,指令就只能执行一次
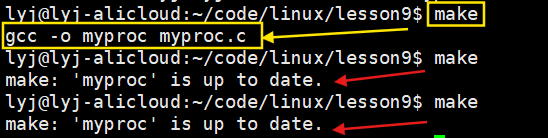
可执行程序不建议用.PHONY修饰,这里不总被执行,就是默认旧代码不做重新编译
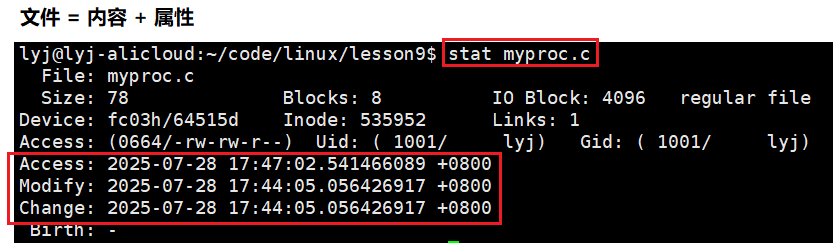
- 修改文件内容:Modify时间和Change时间都会变
- 修改文件属性:只会改变Change时间
- 查看或访问文件:更新Access时间,但并不是每看一次就更新一次。
make怎么知道代码的新旧?对比可执行程序和源文件的Modify时间。
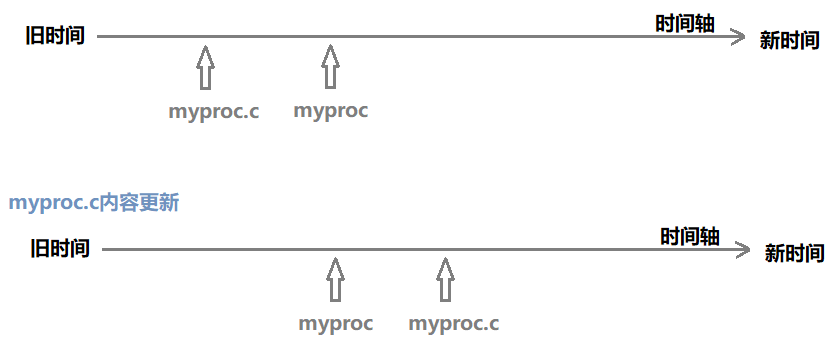
myproc.c内容改变会导致 myproc.c 的Modify时间改变,变得比myproc的Modify时间新,此时make就可以执行,执行后更新myproc的内容,导致myproc的Modify时间又比myproc.c 的新
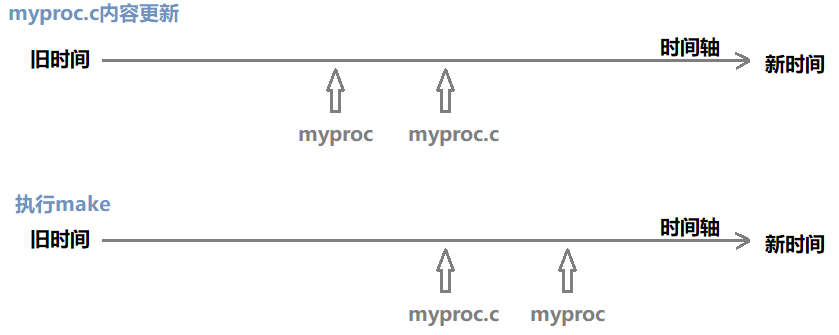
- touch 已存在文件:同时更新文件的三个时间
由此可见,.PHONY的作用本质也就是忽略Modify时间的对比
现在我们只有myproc.c文件。
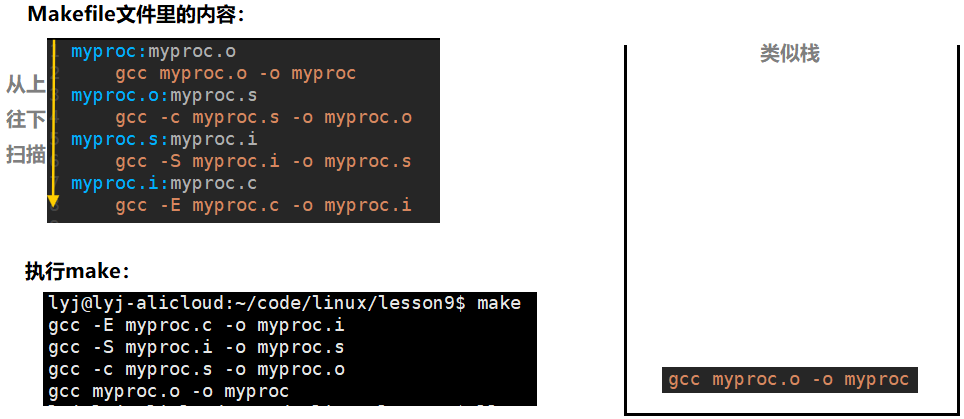
myproc依赖 myproc.o,没有myproc.o,就先把myproc的依赖方法放到一个类似栈的地方,继续往下扫描;myproc.o依赖myproc.s,没有myproc.s,就先把myproc.o的依赖方法往栈里面放,继续往下扫描;myproc.s依赖myproc.i,没有myproc.i,就先把myproc.s的依赖方法往栈里面放,继续往下扫描
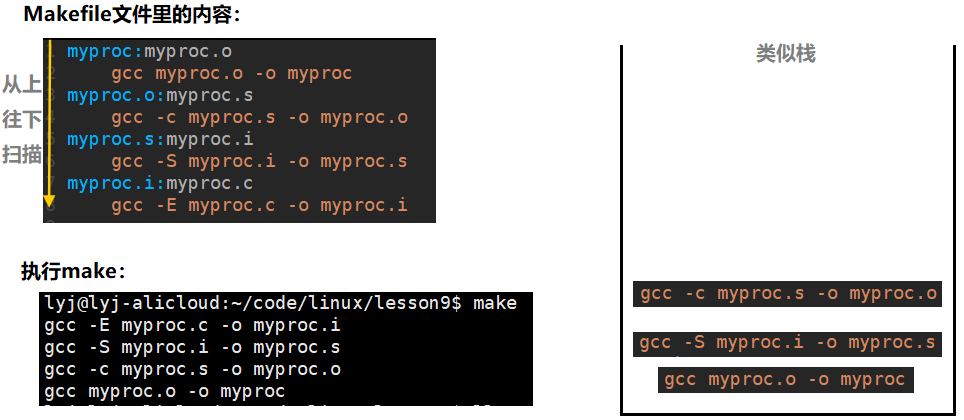
myproc.i依赖myproc.c,有myproc.c,就执行myproc.i的依赖方法,栈里的依赖方法依次出栈并执行。

2.进一步推导演变
- makefile里也可以添加变量
//Makefile文件里
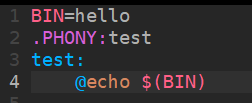
BIN=hello
.PHONY:test
test:echo $(BIN)
这里的BIN就是一个变量,$()就是把变量转为实际的内容的,echo后面跟的$(BIN)就能打印这个变量BIN的内容,就是打印hello。

在echo前面加上@,make的时候就不会回显(这里是@的第一个功能)。
![]()
我们可以定义很多变量
//Makefile文件
BIN=myproc
CC=gcc
SRC=myproc.c
FLAGS=-o.PHONY:test
test:@echo $(BIN)@echo $(CC)@echo $(SRC)@echo $(FLAGS) 有了这些变量我们就可以写一个“模板”出来
BIN=myproc
CC=gcc
SRC=myproc.c
FLAGS=-o$(BIN):$(SRC)$(CC) $(FLAGS) $(BIN) $(SRC)
执行make的结果显示如下:

之前还写过一个clean,把这个clean也写成一个“模板”
BIN=myproc
CC=gcc
SRC=myproc.c
FLAGS=-o
RM=rm -f$(BIN):$(SRC)$(CC) $(FLAGS) $(BIN) $(SRC).PHONY:clean
clean:$(RM) $(BIN)
执行make clean的结果显示如下:

在一组依赖关系中,目标文件可以用@表示(这里是@的第二个功能),依赖文件列表用^表示,如果有多个依赖文件,^表示所有文件,所以前面的写法还可以简化成如下:
$(BIN):$(SRC)$(CC) $(FLAGS) $@ $^

- 依赖关系只有一个,但依赖方法可以有多种
我们再添加一个依赖方法,并且设置成不要回显。
BIN=myproc
CC=gcc
SRC=myproc.c
FLAGS=-o
RM=rm -f$(BIN):$(SRC)@$(CC) $(FLAGS) $@ $^ @echo "$(SRC) to $(BIN), linking...".PHONY:clean
clean:@$(RM) $(BIN)@echo "remove $(BIN)..."
此时clean和myproc都有两个依赖方法了,并且不回显,来看一下效果。

我们一般不会直接从源文件(.c文件)编成可执行文件,一般把源文件先编成.o文件,然后把所有的.o文件再连接,编成可执行。
BIN=myproc
CC=gcc
SRC=myproc.c
OBJ=myproc.o # .o文件
LFLAGS=-o #连接时用到的选项
FLAGS=-c #编译时用到的选项
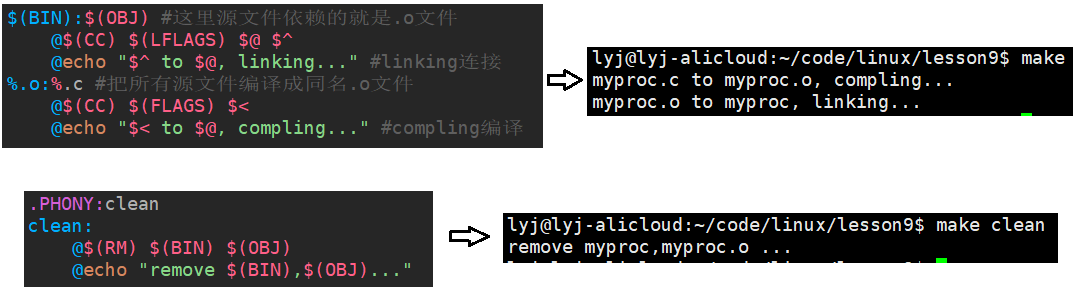
RM=rm -f$(BIN):$(OBJ) #这里源文件依赖的就是.o文件$(CC) $(LFLAGS) $@ $^
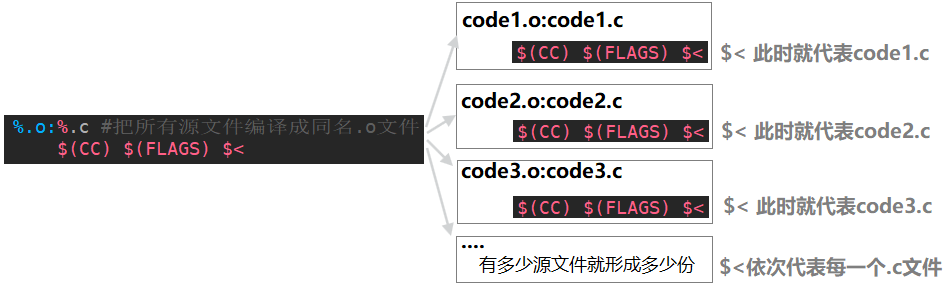
%.o:%.c #把所有源文件编译成同名.o文件$(CC) $(FLAGS) $<.PHONY:clean
clean:$(RM) $(BIN) $(OBJ)
上面的代码中,%.o和%.c,其中%就类似于Makefile里的通配符,把当前路径下的所有的.o文件或者.c文件依次展开。如果我们有100个.c文件,makefile会根据我们写的依赖关系(%.o:%.c),把这组依赖关系和依赖方法形成100份
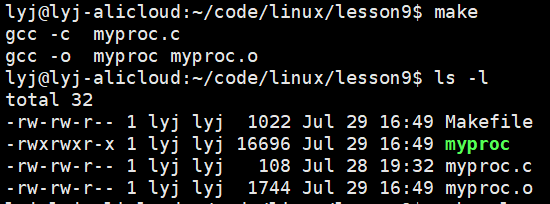
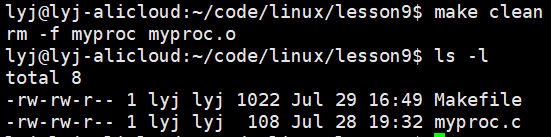
我们也可以加上@让make执行不回显
3.扩展一点语法
- SRC=$(shell ls *.c)
SRC是Makefile里的变量, shell ls *.c 的意思就是在shell中的ls命令下所有的.c文件,这整句话的意思就是,把当前目录下所有的.c文件给SCR。

- SRC=$(wildcard *.c)
这个和前面是一样的功能,只不过用的是 wildcard 来获取当前目录下的所有.c文件
- OBJ=$(SRC:.c=.o)
OBJ是变量,我们需要所有源文件的.o文件,SRC:.c=.o 的意思就是把SRC里的.c文件名字不变都换成同名.o文件,从而得到所有的同名.o文件,整句话的意思就是把换成的所有.o文件给OBJ变量。
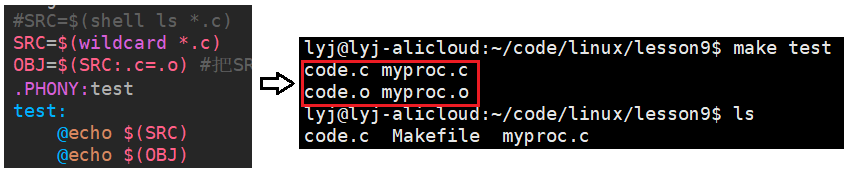
有了上面的方法,当我们的源文件很多的时候,就不需要一个一个手写文件名了。
BIN=myproc
CC=gcc
#SRC=$(shell ls *.c)
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o) #把SRC里的.c文件换成.o文件
LFLAGS=-o #link连接时用到的选项
FLAGS=-c #编译时用到的选项
RM=rm -f$(BIN):$(OBJ) #这里源文件依赖的就是.o文件@$(CC) $(LFLAGS) $@ $^ @echo "$^ to $@, linking..." #linking连接
%.o:%.c #把所有源文件编译成同名.o文件@$(CC) $(FLAGS) $<@echo "$< to $@, compling..." #compling编译.PHONY:clean
clean:@$(RM) $(BIN) $(OBJ)@echo "remove $(BIN) $(OBJ)..."
比如说现在有3个源文件,如下。
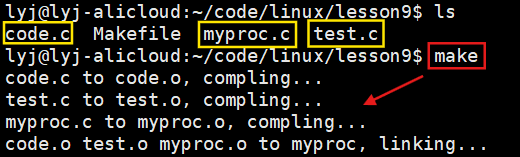
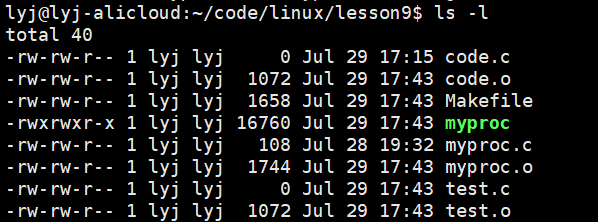
就实现了所有的.c文件先编译成.o文件,然后把所有的.o文件一起链接形成可执行文件。
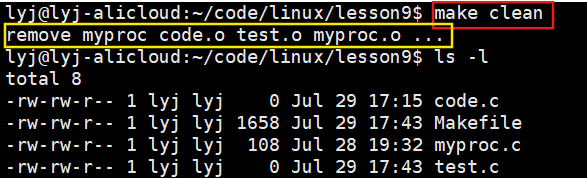
清理的时候全部一起清理。
本次分享就到这里,我们下篇见~
