AAAI 2025多模态重大突破:SENA框架重塑多模态学习,零标注实现自进化
关注gongzhonghao【计算机sci论文精选】
目前AAAI顶会成果已从技术探索迈向产业落地,在未来,AAAI多模态将呈现三大趋势:一是技术深度融合;二是轻量化与泛化能力突破;三是伦理与可解释性发展。
随着多模态模型渗透医疗、自动驾驶等关键领域,如太原理工大学的视觉分割技术推动影像分析精度提升,其决策透明性需求日益凸显。今天小图给大家精选3篇AAAI有关多模态方向的论文,请注意查收!
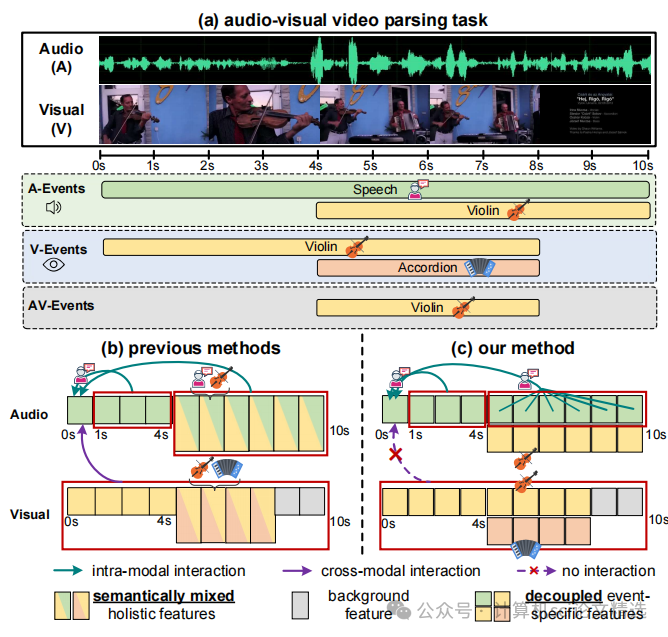
论文一:Multimodal Class-aware Semantic Enhancement Network for Audio-Visual Video Parsing
方法:
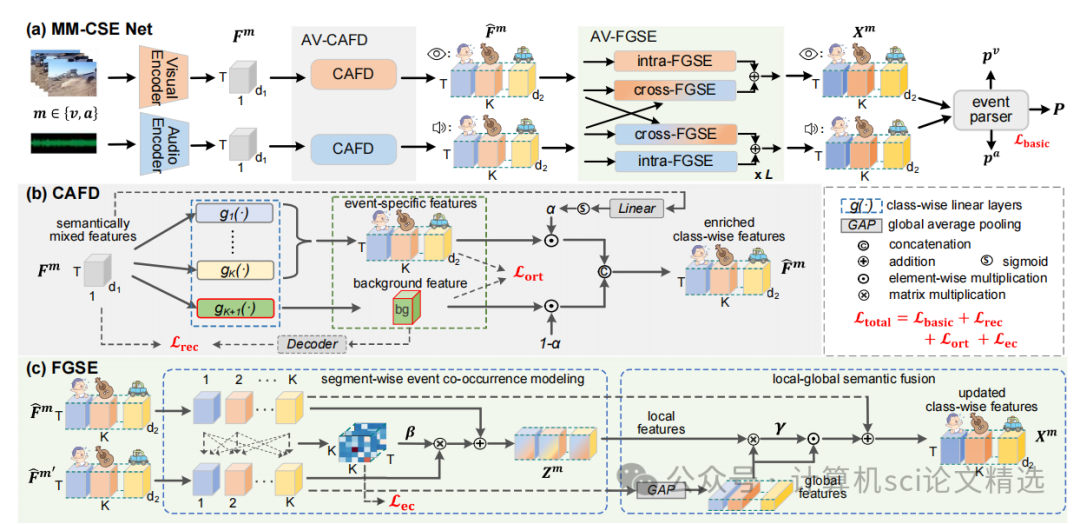
首先,通过CAFD模块对音频和视觉特征进行类感知解耦,生成事件特定和背景特征,并动态融合背景信息以增强事件语义。接着,利用FGSE模块中的SECM块建模相同时间戳内事件共现关系,并通过LGSF块融合局部段与全局视频语义,强化事件表征。最后,结合重构损失、正交损失和事件共现损失优化整体网络,减少跨模态干扰并提升解析性能。
创新点:
提出了Class-Aware Feature Decoupling 模块,将语义混合特征显式解耦为多个事件特定特征和一个专用背景特征,消除无关语义干扰。
设计了FGSE模块,包含SECM和LGSF块,精细建模事件共现和跨时间语义融合。
引入了新的事件共现损失联合重建损失和正交损失,优化特征解耦和共现学习。
论文链接:
https://arxiv.org/abs/2412.11248
图灵学术论文辅导
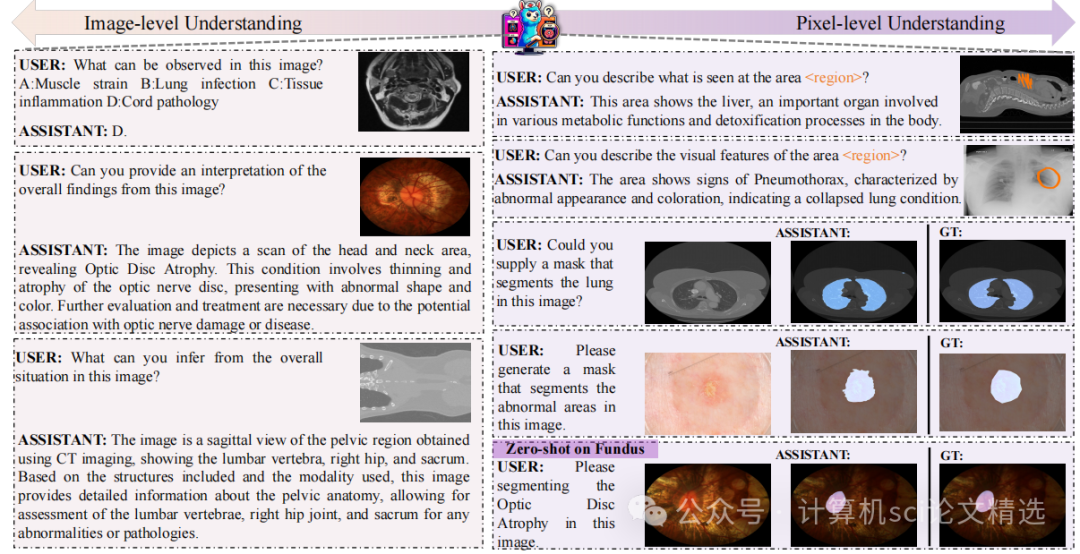
论文二:Towards a Multimodal Large Language Model with Pixel-Level Insight for Biomedicine
方法:
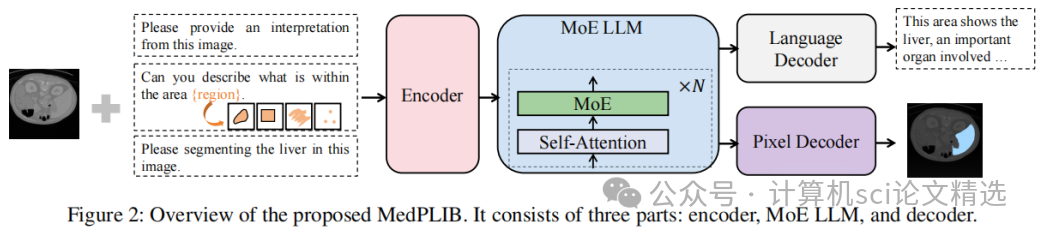
作者设计了三层架构,通过视觉提示编码器和词汇扩展技术统一处理图像、文本及像素级输入,实现灵活的多模态交互。接着,提出多阶段MoE训练策略:分阶段独立训练视觉语言专家和像素定位专家,最后通过动态路由机制融合专家知识,显著提升任务协作效率。最后,基于LLM生成与人工校验构建MeCoVQA数据集,通过结构化元数据生成复杂医学问答,为模型提供跨模态细粒度监督。
创新点:
首创像素级医学MLLM框架:MedPLIB支持视觉问答、任意像素级提示和像素级定位,实现跨模态细粒度交互。
创新性MoE多阶段训练策略:通过分离训练视觉语言专家和像素定位专家,再融合微调,在控制计算成本的同时协调多任务学习。
构建大规模医学数据集MeCoVQA:涵盖8种模态的31万样本,首次整合复杂医学问答、区域理解与像素定位任务。
论文链接:
https://arxiv.org/abs/2412.09278
图灵学术论文辅导
论文三:Beyond Human Data: Aligning Multimodal Large Language Models by Iterative Self-Evolution
方法:
设计图像驱动自提问机制,模型基于未标注图像生成初始问题后,通过内容校验模块过滤无关或不可答问题并再生,同时引入描述性问题丰富语义覆盖,确保问题可靠性。接着,提出答案自增强流程,同时采用扩散噪声污染图像生成负例答案,形成高判别性偏好对以优化对齐效果。
最后,在优化阶段引入图像内容对齐损失函数,通过最大化生成描述的似然概率约束模型注意力至图像实体,并与DPO损失联合训练,实现偏好对齐与幻觉抑制的双重增强。
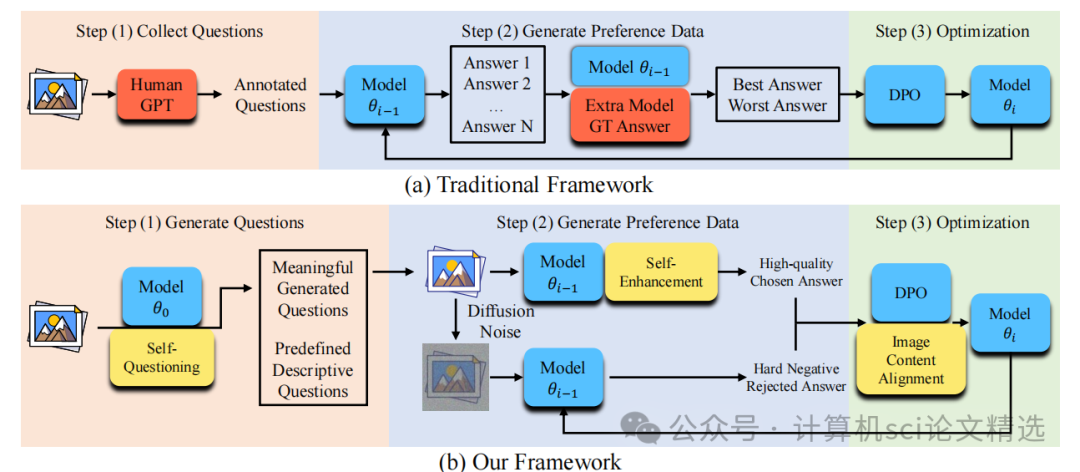
创新点:
通过内容相关性校验与再生机制,确保生成问题与图像强相关且可解答,奠定高质量数据基础。
利用图像描述动态优化正例答案质量,结合噪声图像生成负例答案,构建强判别性偏好对。
联合DPO损失最大化图像描述似然,强制模型关注真实内容,显著减少幻觉现象。

论文链接:
https://arxiv.org/abs/2412.15650
本文选自gongzhonghao【计算机sci论文精选】