Java-数构排序
1.排序的概念
排序就是使得一串记录,按照其中的某个或者某些关键字的大小,递增或者递减的排列起来的操作。
稳定性:假如在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对序列不变,仍然在原序列中,即r[i]=r[j],且r[i]在r[j]之前,而在排序后之后两者顺序不变则称这种排序算法稳定。
内部排序:数据元素全部放在内存中排序
外部排序:数据元素过多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
2.常见排序算法实现
2.1插入排序
2.1.1直接插入排序
public static void insertSort(int[] array){for (int i = 1; i < array.length; i++) {int tmp=array[i];int j = i-1;for (; j >0 ; j--) {if(array[j]>tmp){array[j+1]=array[j];}else {break;}array[j+1]=tmp;}}}代码思路:定义两个下标,i和j,i从数组第二个元素开始,j=i-1。将当前i的元素寄存tmp,与前面的元素进行比较,若数据元素大于tmp,将前序元素覆盖当前元素,并且继续往前遍历;若数据元素小于tmp则将当前空出的元素的地方用tmp补充。若j一直遍历到小于0,遍历完了那么也将空缺位置用tmp填充。
2.1.2希尔排序
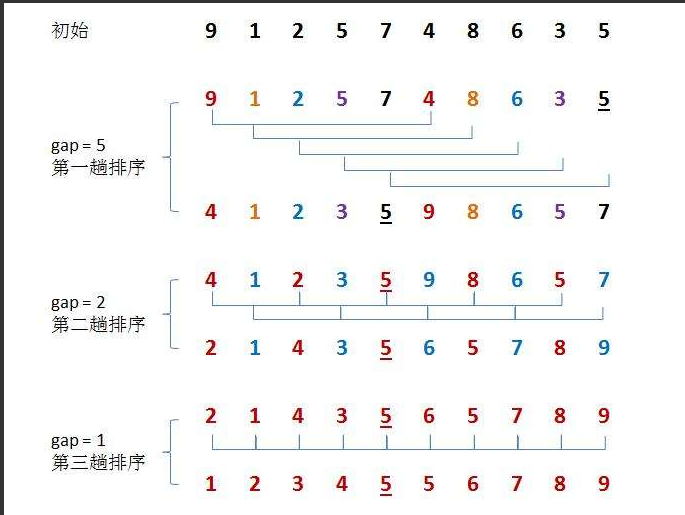
public static void shellSort(int[] array){int gap= array.length;;while(gap>1){gap/=2;shell(array,gap);}}private static void shell(int[] array, int gap) {for (int i = gap; i < array.length; i++) {int tmp=array[i];int j = i-gap;for (; j >0 ; j-=gap) {if(array[j]>tmp){array[j+gap]=array[j];}else {break;}array[j+gap]=tmp;}}}代码思路:直接排序可以看作gap==1的时候的情况,所以可以将直接排序的代码进行修改。j下标每次移动值的区间应该为gap。gap每次排序后不断缩小,可以让每次除以2.
2.2选择排序
2.2.1直接选择排序
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
public static void selectSort(int[] array){for (int i = 0; i < array.length; i++) {int minIndex=i;for (int j = i+1; j < array.length ; j++) {if(array[j]<array[minIndex]) {minIndex = j;}}swap(array,minIndex,i);}}private static void swap(int[] array, int minIndex, int i) {int tmp=array[i];array[i]=array[minIndex];array[minIndex]=tmp;}代码思路:假定当前下标的值为最小值,将这个值与数组后面的值进行大小比较若发现还有更小的值,将两个值进行交换。
我们还可以进行优化一下,同时操作最小值和最大值。
private static void swap(int[] array, int minIndex, int i) {int tmp=array[i];array[i]=array[minIndex];array[minIndex]=tmp;}public static void selectSort2(int[] array){int left=0;int right= array.length-1;while(left<right){int minIndex=left;int maxIndex=left;for (int i = left+1; i <=right ; i++) {if(array[i]<array[minIndex]){minIndex=i;}if(array[i]>array[maxIndex]){maxIndex=i;}}swap(array,minIndex,left);if(maxIndex==left){maxIndex=minIndex;}swap(array,maxIndex,right);left++;right--;}代码思路:每次将最小值放在数组的最左边最大值放在最右边,需要注意的是,交换的时候minIndex和left先进行了交换,若此时maxIndex==left,那么minIndex才是原先maxIndex坐标。
2.2.2堆排序
public static void heapSort(int[] array) {createTree(array);int end = array.length - 1;while (end > 0) {swap(array, 0, end);shiftdown(array, 0, end);end--;}}private static void createTree(int[] array) {for (int parent = (array.length - 1 - 1) / 2; parent >= 0; parent--) {shiftdown(array, parent, array.length);}}private static void shiftdown(int[] array, int parent, int end) {int child = 2 * parent + 1;while (child < end) {if (child + 1 < end && array[child] < array[parent]) {child++;}if (array[child] > array[parent]) {swap(array, child, parent);parent = child;child = 2 * parent + 1;}else {break;}}}2.3交换排序
2.3.1冒泡排序
public static void bubbleSort(int[] array){for (int i = 0; i < array.length-1; i++) {boolean flg=false;for (int j = 0; j < array.length-1-i ; j++) {if(array[j]>array[j+1]){swap(array,j,j+1);flg=true;}}if(!flg){return;}}}2.3.2快速排序
2.3.2.1Hoare版
public static void quickSort(int[] array){quick(array,0,array.length-1);}private static void quick(int[] array, int start, int end) {if(start>end){return;}int pivot=partition(array,start,end);quick(array,start,pivot-1);quick(array,pivot+1,end);}private static int partition(int[] array, int left, int right) {int key=array[left];int i=left;while(left<right){while(left<right&&array[right]>=key){right--;//right去寻找比key小的值用于交换,比key大则跳过}while(left<right&&array[left]<=key){left++;//left去寻找比key大的值用于交换,比key小则跳过}swap(array,left,right);}swap(array,left,i);//相遇后当前位置为基准,将当前值与key进行对换。保证基准的左边全部小于基准,右边全部大于基准。return left;//返回基准下标}
}循环内部一定要取等号,以防当前置与key相同的时候,陷入交换的死循环。之所以先走right是为了确保基准的左边都比基准要小。
2.3.2.2挖坑法
private static int partition(int[] array, int left, int right) {int key=array[left];//取基准值并挖坑while(left<right){while(left<right&&array[right]>=key){right--;}array[left]=array[right];//若当前值比key小则填坑while(left<right&&array[left]<=key){left++;}array[left]=array[right];//若当前值比key大则填坑}array[left]=key;//相遇return left;}2.3.2.3前后指针法
private static int partition(int[] array, int left, int right) {int prev = left ;int cur = left+1;while (cur <= right) {if(array[cur] < array[left] && array[++prev] != array[cur]) {swap(array,cur,prev);}cur++;}swap(array,prev,left);return prev;}2.3.3快速排序的优化
1.三个数取中法选择key,使得二叉树的深度变小
2.递归到小的子区间的时候,可以考虑使用插入排序
private static void quick(int[] array, int start, int end) {if(start>end){return;}if(end-start+1<=7){insertSortRange(array,start,end);return;}int index=midOfThree(array,start,end);int pivot=partition(array,start,end);quick(array,start,pivot-1);quick(array,pivot+1,end);}private static int midOfThree(int[] array, int left, int right) {int mid=(left+right)/2;if(array[left]<array[right]){if(array[mid]<array[left]) {return left;} else if (array[mid]>array[right]){return right;}else {return mid;}}else {if(array[mid]>array[left]){return left;} else if (array[mid]<array[right]) {return right;}else {return mid;}}}
private static void insertSortRange(int[] array, int start, int end) {for (int i = start+1; i <=end ; i++) {int tmp=array[i];int j = i-1;for (; j >=start ; j--) {if(array[j]>tmp){array[j+1]=array[j];}else {break;}array[j+1]=tmp;}}}
2.3.4快速排序非递归
public static void quickSortNor(int[] array){Stack<Integer> stack=new Stack<>();int left=0;int right=array.length-1;int piovt=partition(array,left,right);if(piovt-1>left){//只有当左边不止一个元素的时候stack.push(left);stack.push(piovt-1);}if(piovt+1<right){stack.push(piovt+1);stack.push(right);//右边不止一个元素}while(!stack.isEmpty()){right=stack.pop();//后进先出left=stack.pop();piovt=partition(array,left,right);if(piovt-1>left){stack.push(left);stack.push(piovt-1);}if(piovt+1<right){stack.push(piovt+1);stack.push(right);}}}2.4归并排序
public static void mergeSort(int[] array){mergeSortDe(array,0,array.length-1);}private static void mergeSortDe(int[] array,int left,int right) {if(left>=right) return;int mid=(left+right)/2;mergeSortDe(array,left,mid);mergeSortDe(array,mid+1,right);merge(array,left,right,mid);}private static void merge(int[] array, int left, int right, int mid) {int s1=left;int s2=mid+1;int[] tmpArr=new int[right-left+1];int k=0;while(s1<mid&&s2<=right){if(array[s2]<=array[s1]){tmpArr[k++]=array[s2++];}else {tmpArr[k+=]=array[s1++];}}while(s1<=mid){tmpArr[k++]=array[s1++];}while (s2<=right){tmpArr[k++]=array[s2++];}for (int i = 0; i < tmpArr.length; i++) {array[i+left] = tmpArr[i];}}2.5海量数据的排序问题
3.排序算法复杂度及稳定性分析
| 排序方法 | 最好 | 平均 | 最坏 | 空间复杂度 | 稳定性 |
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 希尔排序 | O(n) | O(n^1.3) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(n * log(n)) | O(n * log(n)) | O(n * log(n)) | O(1) | 不稳定 |
| 快速排序 | O(n * log(n)) | O(n * log(n)) | O(n^2) | O(log(n)) ~ O(n) | 不稳定 |
| 归并排序 | O(n * log(n)) | O(n * log(n)) | O(n * log(n)) | O(n) | 稳定 |
4.其他排序
4.1计数排序
- 统计相同元素出现的次数
- 根据统计的结果将序列回收到原来的序列中
public static void countSort(int[] array){int minVal=array[0];int maxVal=array[0];//求当前数组的最大值和最小值for (int i = 1; i <array.length ; i++) {if(array[i]<minVal){minVal=array[i];}if(array[i]>maxVal){maxVal=array[i];}}//根据最大值和最小值来确定数组的大小int[] count=new int[maxVal-maxVal+1];//根据原来的数组进行计数for (int i = 0; i < array.length; i++) {count[array[i]-minVal]++;}//根据计数数组打印int index=0;for (int i = 0; i < array.length; i++) {while(count[i]>0){array[index]=i+minVal;index++;count[i]--;}}}4.2基数排序
基数排序(Radix Sort)是一种非比较型的排序算法,它通过逐位比较元素的每一位(从最低位到最高位)来实现排序。基数排序的核心思想是将整数按位数切割成不同的数字,然后按每个位数分别进行排序。基数排序的时间复杂度为 O(n * k),其中 n 是列表长度,k 是最大数字的位数。
算法步骤:
确定最大位数:找到列表中最大数字的位数,确定需要排序的轮数。
按位排序:从最低位开始,依次对每一位进行排序(通常使用计数排序或桶排序作为子排序算法)。
合并结果:每一轮排序后,更新列表的顺序,直到所有位数排序完成。
4.3桶排序
一句话总结:划分多个范围相同的区间,每个子区间自排序,最后合并。
桶排序是计数排序的扩展版本,计数排序可以看成每个桶只存储相同元素,而桶排序每个桶存储一定范围的元素,通过映射函数,将待排序数组中的元素映射到各个对应的桶中,对每个桶中的元素进行排序,最后将非空桶中的元素逐个放入原序列中。