大模型应用主要组成
一、LLM大语言模型(理解问题并生成回答)
(一)闭源(API 调用为主)
1、GPT 系列(OpenAI) (GPT-3.5-turbo、GPT-4、GPT-4-turbo)
- GPT-3.5:性价比高,支持多轮对话、文本生成,适合日常问答、客服等场景;
- GPT-4 / GPT-4-turbo:支持多模态(文本 + 图像输入),分析图像内容(看图说话、图像内容提取),逻辑推理、复杂任务处理(如数据分析、代码调试)表现顶尖,适合专业场景。
2、Claude 系列(Anthropic)(Claude 2、Claude 3)
- 以安全性和长上下文著称(Claude 3 支持 20 万 tokens 上下文,可处理超长文档),Claude 3支持多模态图像理解
- 适合法律、医疗等对准确性和安全性要求高的场景。
(二)开源可微调模型(可本地部署 / 二次训练)
1、DeepSeek 系列 (DeepSeek-R1、DeepSeek-V2、DeepSeek-Coder)
- 顶尖的中文开源大模型之一,中文理解、创作、知识问答、逻辑推理方面表现优异,支持128k超长上下文。
2、Llama 系列(Meta)(Llama 2、Llama 3)
- 开源标杆,有多种参数规模可选(7B, 8B, 13B, 70B等),包括 Llama 2(70 亿 - 700 亿参数,商用需申请许可)、Llama 3(最新版,性能接近闭源模型),支持多语言,社区衍生模型极多(如 Alpaca、Vicuna)。
3、Mistral 系列(Mistral AI)
- 以高效著称,高性价比、快速响应,API调用成本低。如 Mistral 7B(70 亿参数)性能接近 130 亿参数模型,Mixtral 8x7B(混合专家模型)能力更强,适合资源有限场景。
4、国产开源模型
- 通义千问开源版(Qwen-7B/14B 等)、百川(Baichuan-7B/13B)、智谱 AI 的 GLM 系列,针对中文优化,支持本地部署和微调,适合企业私有化场景。
5、其他轻量模型
- Phi-2(微软,27 亿参数)、Llama 3-8B 等,参数量小但能力强,适合边缘设备(如手机、嵌入式设备)部署。
(三)LLM选择的考量因素
任务类型: 你是要聊天、写作、编程、看图、还是处理文档?
资源和性能要求: 需要顶尖的推理能力(如Claude 3 Opus, GPT-4),还是性价比/速度优先(如Mixtral, Claude Haiku)?
语言支持: 主要处理中文还是英文?某些模型(如国产模型、GPT/Claude)中文好,某些开源模型(如早期Llama)中文需额外优化。
上下文长度: 需要处理很长的文档或对话吗?(Kimi, Claude, Gemini 1.5 Pro, GPT-4-turbo 支持很长上下文)。
多模态需求: 是否需要理解或生成图像/音频?
成本与部署: 使用API(按量付费)还是自己部署(开源模型)?预算如何?
数据隐私与安全: 数据敏感吗?需要私有化部署吗?(开源模型优势)。
(四)适用场景总结
日常对话、创意写作、通用知识问答: GPT-4-turbo, Claude 3 (Sonnet/Haiku), Gemini 1.5 Pro/Flash, Llama 3 都是优秀选择。
处理超长文档/复杂推理: Claude 3 (Opus/Sonnet), Gemini 1.5 Pro, Kimi Chat, GPT-4-turbo。
编程开发: GPT-4-turbo, Claude 3, Code Llama, DeepSeek-Coder, GitHub Copilot (Codex)。
多模态理解(图+文): GPT-4V (GPT-4-turbo), Gemini 1.5 Pro, Claude 3。
文生图: DALL-E 3, Midjourney(非严格LLM,但相关), Stable Diffusion(开源), 文心一格, 通义万相。
开源与私有部署: Llama 3, Mistral/Mixtral, Qwen, DeepSeek-Coder。
中文场景优先: 文心一言、通义千问、Kimi Chat、DeepSeek-R(深度求索的通用中文模型)。
(五)局限性
- 幻觉:生成看似合理但错误的信息(如编造事实、引用不存在的文献),尤其在专业领域需谨慎。
- 上下文限制:存在最大上下文tokens限制。
- 计算资源消耗大:大模型训练和推理需高端 GPU/TPU,开源小模型(如 7B 参数)虽可本地部署,但能力有限。
二、推理框架(推理加速)
(一)vLLM
高性能推理框架,加速大模型本地运行,适用GPU 环境(RTX 3060+),
极高吞吐量(PagedAttention)、动态批处理
- 适用场景: 高并发API服务、大流量场景。
(二)llama.cpp
针对 CPU 优化的推理框架,支持量化模型(4-bit/8-bit),无 GPU 环境(需 32GB + 内存),GGUF量化、多平台支持。
- 适用场景: 开发者个人项目本地部署、纯CPU/边缘设备运行、低资源环境设备(如 MacBook、低配服务器)。
(三)Text Generation Inference (TGI)
Hugging Face提供,官方优化、支持多GPU/量化/持续生成
- 适用场景: HuggingFace模型生产部署
(四)TensorRT-LLM
NVIDIA显卡极致性能(FP8/量化)、低延迟
- 适用场景: 英伟达环境超高性能需求、超低延迟、企业级支持
(五)ctransformers
CPU 或轻量级 GPU 推理,与 LangChain 无缝集成,支持流式输出
基于 llama.cpp 封装,提供 Python 接口,更易用。
支持多种量化方法(如 INT8、INT4、INT3 等),将模型权重压缩为更低精度,显著减少内存需求,并加速计算。
- 适用场景: 个人电脑或边缘设备上运行小型 LLM(如 7B/13B 参数模型)的本地部署,嵌入式设备、移动应用或低配置服务器,快速轻量的部署模型,
三、向量数据库(存储知识数据)
(一)Chroma
Chroma 是一个开源、轻量级的向量数据库(向量存储),百万级以下向量存储,存储 数据库表结构、字段注释、业务规则文档片段 等知识的向量,适合中小企业内部知识库,与 llama-index 无缝集成。
pip install chromadbChroma 支持两种存储模式:
- 内存模式:数据存于内存,适合临时测试(程序结束后数据丢失)。
- 持久化模式:数据存于本地文件,适合长期使用(重启后数据不丢失)。
import chromadb
from chromadb.config import Settings
from sentence_transformers import SentenceTransformer# 初始化客户端(持久化模式,数据存在./chroma_data目录)
client = chromadb.Client(Settings(persist_directory="./chroma_data" # 本地存储路径)
)# 创建或获取一个集合(如果已存在则直接获取)
# 这里创建“table_structures”集合,存储数据库表结构信息
collection = client.get_or_create_collection(name="table_structures")# 加载中文 Embedding 模型(之前提到的轻量模型,适合CPU)
embedding_model = SentenceTransformer("BAAI/bge-small-zh-v1.5")# 准备知识库文档(例如:数据库表结构描述)
documents = ["用户表(user):字段包括id(int,主键)、name(string,用户名)、register_time(datetime,注册时间)、status(int,1=活跃,0=禁用)","订单表(order):字段包括order_id(int,主键)、user_id(int,关联用户表id)、amount(float,金额)、create_time(datetime,创建时间)"
]# 生成文档的 Embedding 向量
document_embeddings = embedding_model.encode(documents)# 给每个文档添加唯一ID和元数据(方便后续管理)
ids = ["doc1", "doc2"]
metadatas = [{"type": "table_structure", "table_name": "user"},{"type": "table_structure", "table_name": "order"}
]# 将文档、Embedding、ID、元数据添加到集合
collection.add(documents=documents, # 原始文档(可选,方便查看)embeddings=document_embeddings, # 文档的Embedding向量ids=ids, # 唯一标识metadatas=metadatas # 元数据(可选,用于过滤)
)# 持久化数据(如果用了持久化模式,手动触发保存)
client.persist()# 用户查询
user_query = "如何查询活跃用户的订单金额?"# 生成查询的 Embedding 向量
query_embedding = embedding_model.encode([user_query]) # 注意:输入是列表# 从集合中检索最相关的文档(top_k=2 表示返回前2个)
results = collection.query(query_embeddings=query_embedding,n_results=2, # 返回最相关的2个文档# 可选:按元数据过滤(如只检索表结构类型的文档)where={"type": "table_structure"}
)# 输出检索结果
print("检索到的相关文档:")
for doc, distance in zip(results["documents"][0], results["distances"][0]):print(f"文档:{doc},相似度:{1 - distance:.4f}") # 余弦距离越小,相似度越高
(二)Qdrant
支持百万到千万级向量,支持实时向量更新(插入 / 删除延迟低);
- 适用场景:实时更新的向量检索(如动态知识库)、中小规模 RAG
(三)Weaviate
千万级
- 适用场景:多模态检索
(四)FAISS
轻量级、直接嵌入代码,支持亿级向量,依赖内存,无持久化存储、事务、分布式能力。
性能极强、支持多种索引(精确检索、近似检索),可自定义参数平衡速度与精度
- 适用场景:超高速检索,嵌入边缘设备
(五)Milvus(米诺斯)
Milvus 是一个开源的分布式向量数据库,支持 百亿级向量数据存储,毫秒级检索,专注于海量高维向量的存储、索引和相似度检索,
索引优化:提供多种索引类型(如 IVF_FLAT、HNSW、ANNOY 等)
需安装启动服务,支持单机 / 集群部署
支持向量相似度检索(余弦、欧氏距离等)、元数据过滤(如按文档标签、时间戳筛选)、多向量类型(稠密向量、稀疏向量),适配复杂场景
- 适用场景:亿级以上海量数据,实时 超低延迟检索(<100ms),私有部署。
四、连接器
(一)LangChain
“胶水框架”,连接大模型与各类外部资源(数据、工具、API)的中间层,解决 “如何让大模型与现实世界交互” 的问题。
连接大模型和知识库,实现 “检索 + 生成” 的问答流程,比RAG 更通用,还支持工具调用、多智能体协作、流程编排等。Agent 调度能力最强。
用标准化组件(Chain, Agent, Tool, Memory 等)快速搭建生产级 AI 应用。
实现对话历史存储与检索(如短期记忆、长期记忆),支持会话状态维护。
让模型自主决策调用哪些工具解决问题。
- 适用场景:复杂流程编排、涉及多种工具调用,需要高度定制化流程。
(二)LlamaIndex
连接大模型与知识库,文档解析、向量存储、检索增强生成(RAG),可定制检索策略和提示词模板。专精 RAG、数据接入优化。
专注于结构化处理和索引化外部知识,高效管理和检索外部信息。
支持从各种数据源(PDF、网页、数据库、API)提取和解析数据,支持增量索引和动态更新,适应数据变化。将非结构化数据转化为向量索引(如向量相似度检索、树状索引、图索引),优化知识检索效率。
- 适用场景:快速构建 RAG 系统,RAG 文档问答、企业知识库问答、文档分析。极简数据接入方案。
(三)Haystack
企业级流水线设计、可视化调试,支持ES/Milvus/监控等生产组件。
- 适用场景:企业级检索流水线,生产环境检索系统
(四)AutoGen
多 Agent 协作(角色分工)
- 适用场景:模拟团队协作解决复杂问题,多 AI 智能体协作场景。
五、Embedding模型(嵌入模型)(知识检索)
文本→向量的转换,将文本(问题/知识)转换为高维向量,通过计算语义的余弦相似度,找到最相关的知识。提供向量检索。
- Embedding模型是RAG框架 检索部分的实现
- sentence-transformers又是Embedding模型的实现工具(加载、推理、微调、评估)
(一)四款主流中文Embedding模型的深度对比
| 模型 | 参数量 | 磁盘体积 | 内存占用 | 上下文长度 | 中文优化 | CPU推理延迟 |
|---|---|---|---|---|---|---|
| text2vec-base-chinese | 110M | 420MB | 350MB | 512 tokens | ⭐⭐⭐⭐ | 22-35ms |
| text2vec-bge-large-chinese | 335M | 1.3GB | 1.1GB | 512 tokens | ⭐⭐⭐⭐⭐ | 80-120ms |
| bge-small-zh-v1.5 | 33M | 130MB | 110MB | 512 tokens | ⭐⭐⭐⭐ | 8-15ms |
| bge-large-chinese-onnx | 335M | 680MB (量化) | 950MB | 2048 tokens | ⭐⭐⭐⭐⭐ | 50-75ms |
(二)适用场景
选型决策图:
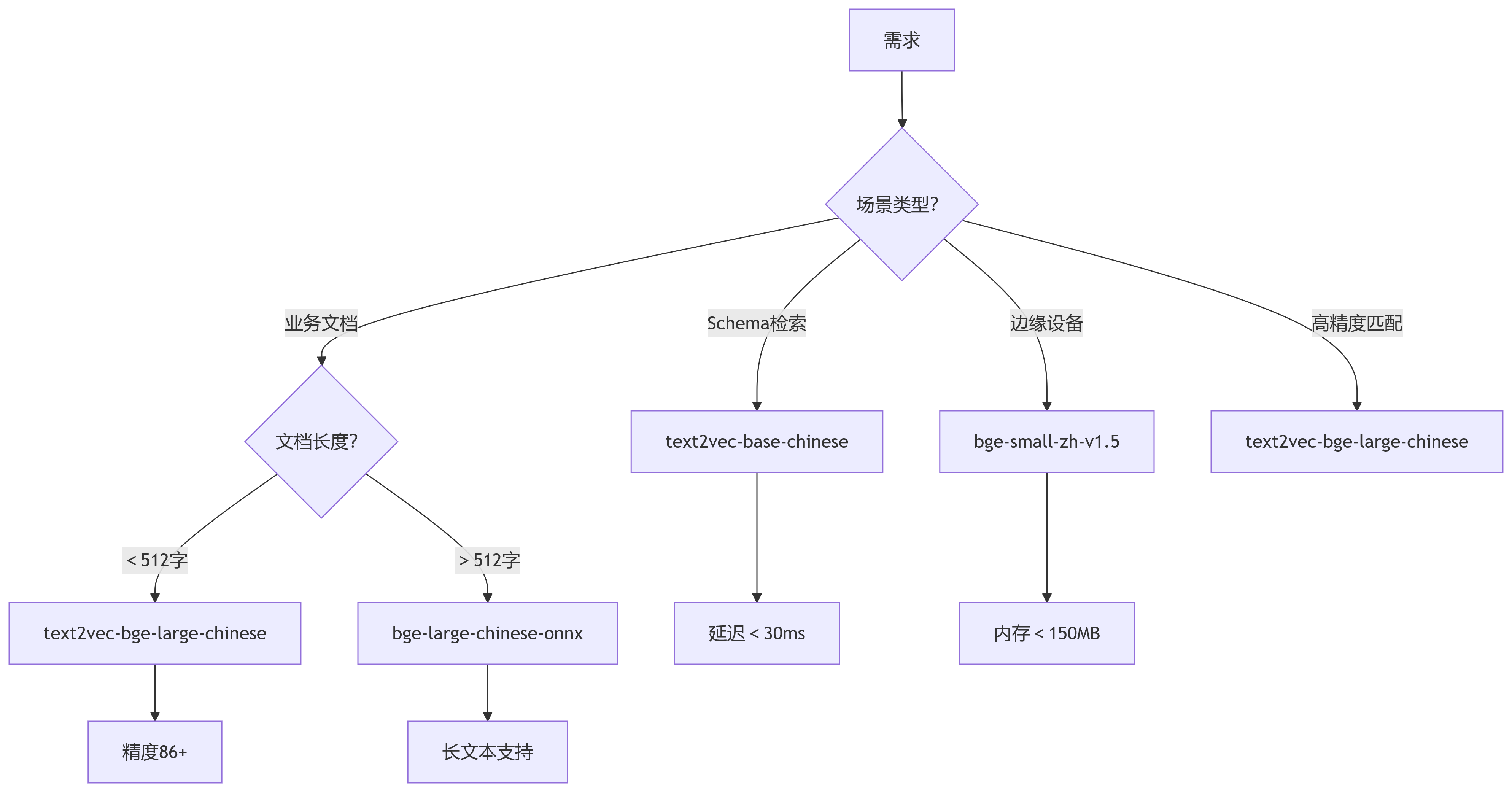
1、性价比之王
text2vec-base-chinese :平衡精度与速度,国产数据库首选,适合数据库Schema检索,(如简单文本聚类、关键词匹配)。
2、精度优先
text2vec-bge-large-chinese :中文SOTA模型,适合专业领域 高精度语义检索。
3、资源受限环境
bge-small-zh-v1.5 :树莓派/工控机等设备检索。
4、长文档处理
bge-large-chinese-onnx :2048上下文,金融/医疗等领域专有名词理解强,适合长业务文档检索。
sentence-transformers的使用:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('text2vec-base-chinese') # 加载Embedding模型
embeddings = model.encode # 生成向量