计算机中的数据表示
内容索引
- 数据结构
- 数据类型
- 数据宽度
- 数据表示
- 数字编码
- 字符编码
- 字节序
1. 数据类型与数据结构
基本数据类型是CPU可以直接进行运算的类型,以二进制的形式存储在计算机中
- 整数型:byte, short, int, long
- 浮点数:float, double
- 字符型:char,用于表示各种语言的字母、标点符号、甚至表情符号等;
- 布尔型:bool,用于表示“是”与“否”判断
基本数据类型提供了数据的“内容类型”,而数据结构提供了数据的“组织方式”
数据结构:数组与链表、栈与队列、哈希表、树、堆、图等
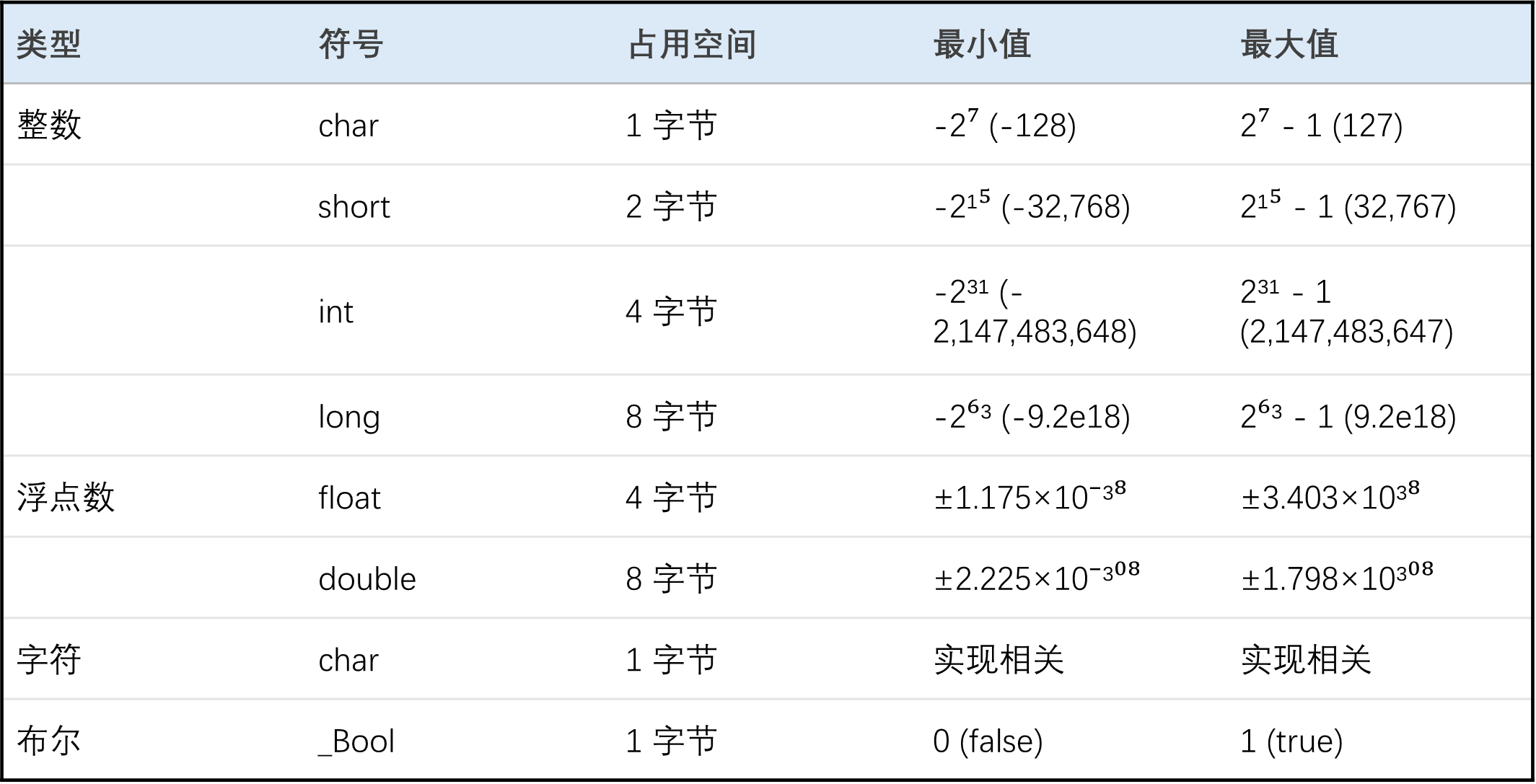
- 字符char的大小在C/C++中为1字节,
- 在大多数现在操作系统中,1字节(byte)由8比特(bit)组成
2. 数据宽度
字节byte、字word、双字dword
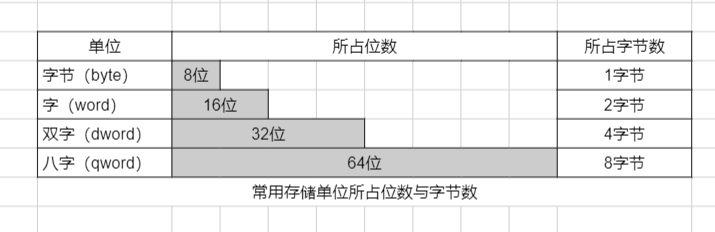
- 字(word)是一定数量的字节,所占位数取决于架构,x86架构的 1字 = 2字节 = 16 比特
3. 数据表示:位、字节、字
位 bit、字节 byte、字 WORD
在x86架构中:1 DWORD = 2字 = 4 字节 = 32 位(比特)
最低有效位LSB 是最右边的位

- 最低有效位(Least Significant Bit,LSB)
- 最高有效位(Most Significant Bit,MSB)是最左边的位
- 当我们从二进制转换为十进制时,最高有效位会被乘以2的31次方,而最低有效位则会被乘以2的0次方;
4. 数字编码
原码(Sign-Magnitude)、反码(Ones' Complement)、补码(Two's Complement)
- 原码:用二进制数表示一个数,包括正负号。在原码中,最高位(最左边的位)是符号位,0 表示正数,1 表示负数。其余位表示数值本身。例如,十进制数 +5 的原码表示为
0000 0101,而 -5 的原码表示为1000 0101。 - 反码:正数的反码与其原码相同,负数的反码是对其原码除符号位外的所有位取反。例如,十进制数-5的反码表示为
1111 1010。 - 补码:补码是计算机中最常用的表示方法,用于进行二进制加法运算。正数的补码与其原码相同,负数的补码是在其反码的基础上加1 。补码的一个重要特性是,任何数的补码加上该数本身,结果总是 0。例如,十进制数 -5 的补码表示为
1111 1011。
5. 字符编码
ASCII字符集, Unicode字符集, UTF-8编码
相关概念:“码点”、“基本多语言平面字符”
字符集:规定了每个字符和二进制数之间的对应关系,可以通过查表完成二进制数到字符的转换
码点:给字符分配的编号
- ASCII码仅能够表示英文,最多能够表示128个不同的字符;
- Unicode致力于将全球范围内的字符纳入统一的通用字符集中,理论上能容纳100多万个字符
- UTF-8 是国际上使用最广泛的Unicode编码方法;
- UTF-8 是一种变长的编码方法,有效提升了存储空间的使用效率;
- UTF-16是一种等长的编码方法,但在编码中文时,UTF-16占用的空间比UTF-8更小;
- Java和C#等编程语言默认使用 UTF-16,Microsoft的大部分技术都使用 UTF-16编码;
- Python3.x使用灵活的Unicode表示方式(不是UTF-8或UTF-16),实际存储会根据字符串内容动态优化;
- Go, Rust语言的string类型在内部使用UTF8编码
- Unicode 包含15万左右个字符(截止2022年);
字符空间占用
- ASCII字符:固定1字节
- UTF-8:ASCII字符占1字节,中文占3字节。
- UTF-16:基本多文种平面(BMP)字符占2字节,扩展字符(如emoji)占4字节。
*字符串如何在文件中存储或在网络中传输,与字符串在编程语言中的存储方式是不同的问题。在文件存储或网络传输中,通常会将字符串编码为UTF-8格式,以达到最优的兼容性和空间效率。
*逆向分析时,utf-8的字符理解为1字节,utf-16的字符一般理解为2字节;
字符编码核心概念区分
| 术语 | 定义 | 关键特性 |
| ASCII字符集 | 7位编码标准(0-127),仅含英文、数字、基础符号及控制字符。 | 固定1字节/字符,共128字符。 |
| Unicode字符集 | 国际统一字符集(最新版15.0),涵盖全球文字(如中文、阿拉伯文、emoji)。 | 抽象字符编号 |
| UTF-8 | Unicode的变长编码(1-4字节/字符),兼容ASCII。 | ASCII字符占1字节,中文占3字节。 |
| UTF-16 | Unicode的定长/变长编码(2或4字节/字符),不兼容ASCII。 | 基本多文种平面(BMP)字符占2字节,扩展字符(如emoji)占4字节。 |
6. 字节序
大端序是最高有效字节在前,小端序则相反:
- 比如 0x12345678, 大端序存储为 12 34 56 78,小端序存储为 78 67 34 12
大端序的使用场景
- 网络协议:如 TCP/IP 使用大端序作为标准(“网络字节序”),例如 IP 地址和端口号的传输;
- 文件格式:某些文件格式(如 JPEG、PNG)使用大端序存储数据;
- 处理器架构:PowerPC、SPARC 等架构默认采用大端序
小端序的使用场景
- x86/x86_64 架构:Intel 和 AMD 的处理器默认使用小端序,因此Windows,Linux 系统常见为小端序;
- 嵌入式系统:如 ARM 处理器通常支持小端序模式;
- 文件格式:如 Windows 的 PE 文件(可执行文件)和某些二进制协议(如 USB 数据包)
python struct模块中,小端序的格式字符是 <
- 示例:
strcut.pack('<I', 0x12345678),会生成b'\x78\56\34\12' - struct 模块的格式化字符串对应的类型字符:
- I 无符号整型(4 字节),unsigned int
- L 无符号长整型(4 字节),unsinged long
参考引用
Hello算法对理解计算机表示、基本数据类型和数据结构很有帮助,有以前没有思考过的角度和视野,十分推荐阅读:
[1] 3.2 基本数据类型 - Hello 算法
[2] 3.4 字符编码 * - Hello 算法