存储引擎 RocksDB
目录
RocksDB简介
适用场景
使用RocksDB进行基本操作
使用RocksDB的基本流程
RocksDB架构
LSM 树(Log-Structured Merge Tree)原理(核心架构)
SSTable(Sorted String Table)结构
布隆过滤器(Bloom Filter)
压缩和缓存策略
列族(Column Family)
使用 RocksDB 的底层架构特性
RocksDB简介
RocksDB 是由 Facebook 开源的嵌入式高性能键值数据库,底层基于 Google 的 LevelDB,并针对 SSD、HDD 和多核 CPU 的使用场景做了大量优化。它不需要服务端,直接嵌入应用中使用。
起源与设计目标
RocksDB 由 Facebook 的 Dhruba Borthakur 主导开发,目标是用于 Facebook 大规模后台服务,尤其是消息系统、高并发日志写入场景。
核心设计目标:
| 目标 | 说明 |
|---|---|
| 高性能 | 写优化(基于 LSM Tree),适合写密集型应用 |
| 可扩展性 | 可处理 PB 级数据,单实例支持 TB 级存储 |
| 可靠性 | 写入 WAL 日志,支持崩溃恢复 |
| 灵活性 | 可配置压缩算法(如 ZSTD)、内存管理、compaction 策略等 |
与 LevelDB 的比较
RocksDB 本质上是 LevelDB 的重构增强版本,保留了 LSM-Tree 架构,但优化了性能与功能。
| 功能方面 | LevelDB | RocksDB(改进) |
|---|---|---|
| 多线程写入支持 | 不支持 | 支持多线程后台 compaction 等 |
| 配置灵活性 | 少 | 提供数百个可调参数 |
| 压缩算法 | Snappy | 支持 Snappy、ZSTD、LZ4、Bzip2 |
| Block Cache | 简单 | 更灵活的 block cache + 过滤器 |
| Compaction 策略 | 单一 | leveled / universal / FIFO 等 |
| 数据加密 | 不支持 | 支持数据透明加密 |
| 多 Column Family 支持 | 无 | 类似于多个逻辑表 |
| 分层存储 | 无 | 支持将不同层存储在不同设备上 |
适用场景
RocksDB 适合嵌入式部署,且具备低延迟读写、高压缩比、支持大数据量等优势,适用于对性能要求极高的系统:
日志采集系统(如 Kafka 的存储层)
消息队列(如 Facebook Messenger)
区块链账本存储(如 Bitcoin Core、Ethereum)
高性能缓存(可作为磁盘级 Cache)
时间序列数据存储
分布式数据库底层引擎(如 TiKV)
案例:Facebook 使用 RocksDB 构建消息服务(如 Messenger),每秒处理数百万次读写请求,同时保持高吞吐与数据一致性。
嵌入式部署是把软件(这里指 RocksDB)直接嵌入到其他程序或设备里,让它成为整体的一部分,而不是作为一个独立的外部程序运行。
就像手机里的相机功能,它不是一个单独的 App,而是直接嵌在手机系统里,和其他功能(比如屏幕、处理器)紧密结合,一起工作。
日志采集系统(如 Kafka 的存储层)
服务器、APP、小程序每天都会产生大量日志(比如 “用户登录了”“订单支付成功”“系统出错了”),这些日志像流水一样不断产生。
日志采集系统就是专门记录这些日志,按顺序存起来,方便后面分析(比如排查故障、统计用户行为)。
Kafka 是最常用的日志采集工具之一,而 RocksDB 可以作为 Kafka 存日志的底层硬盘管家,Kafka 收到日志后,交给 RocksDB 高效存储,既能快速写入新日志,又能快速查历史日志。
消息队列(如 Facebook Messenger)
消息队列就是专门传消息的工具,比如你在微信上给朋友发消息,消息不会直接到对方手机,而是先传到腾讯的消息队列里,再由队列转发给对方。
这么做是为了避免堵车:如果同时有 100 万人发消息,直接传可能卡死,队列会按顺序排队,慢慢处理。
Facebook Messenger(脸书的聊天工具)背后就用了 RocksDB 存消息,聊天记录会先存在 RocksDB 里,保证即使服务器临时出问题,消息也不会丢,等恢复后再正常发送。
区块链账本存储(如 Bitcoin Core、Ethereum)
区块链的核心是账本,比如比特币的每一笔转账(谁转给谁、转了多少),都会被永久记下来,而且一旦记上就改不了,所有人都能查。
这种账本需要写得快、存得稳、查得方便:每秒钟可能有上万笔交易要记录,而且不能丢、不能改。
Bitcoin Core(比特币核心客户端)、Ethereum(以太坊)这些区块链系统,就用 RocksDB 来存这个账本—— 每笔交易按顺序存,既能扛住高频写入,又能高效验证历史记录。
高性能缓存(可作为磁盘级 Cache)
缓存的作用是加速读取:比如你经常用的文件,不放在柜子深处(硬盘),而是放在抽屉里(缓存),拿起来更快。
普通缓存可能存在内存里(速度极快但容量小),而 磁盘级 Cache 是存在硬盘上的缓存(容量比内存大,速度比普通硬盘快)。
RocksDB 可以当这个高速抽屉:比如浏览器存历史记录、视频软件存临时缓冲数据,用 RocksDB 存,既能快速找到常用的内容,又比纯内存缓存能存更多东西。
时间序列数据存储
时间序列数据存储简单说就是按时间顺序产生的一连串数据的存储方式。家里的温度计,每 10 分钟记录一次温度(20℃、21℃、20.5℃…),这些带时间戳的数据就是时间序列数据;
股票价格每秒更新一次(100 元、100.2 元、99.8 元…),也是时间序列数据;
服务器的 CPU 使用率、APP 的用户在线人数,随时间变化的记录,都属于这类数据。这类数据的特点是写得多、读得有规律(比如查最近 1 小时、最近 1 天的数据)、很少修改旧数据。
RocksDB 适合存这类数据,因为它写速度快(能跟上高频产生的数据),而且可以通过配置策略(比如按时间淘汰旧数据)高效管理不断增长的时序数据。
分布式数据库底层引擎(如 TiKV)
分布式数据库:比如一个数据库的数据,不是存在一台电脑上,而是分散在多台服务器(比如 10 台机器共同存一个大数据库),这样能存更多数据、抗住更多人同时访问(比如电商平台的数据库)
底层引擎:就是负责实际存数据、读数据、管理数据的核心模块。分布式数据库的上层负责处理用户的查询请求(比如查用户订单),但真正把数据存在磁盘 / 内存、保证数据不丢、在多台机器间同步数据的 “脏活累活”,就是底层引擎干的。TiKV 就是一个典型的分布式数据库底层引擎,它基于 RocksDB 实现,每台服务器上的数据,实际是存在 RocksDB 里的,TiKV 再在此基础上增加了多机器数据同步、故障自动切换等分布式能力。
简单来说 RocksDB 是单台机器上的数据管家,TiKV 这类引擎则是多台机器的数据管家团队,而 RocksDB 是团队里每台机器的核心工具。
使用RocksDB进行基本操作
import org.rocksdb.*;public class RocksDBExample {static {RocksDB.loadLibrary(); // 加载 RocksDB 本地库}public static void main(String[] args) {// 数据库路径String dbPath = "/tmp/rocksdb_example";try (final Options options = new Options().setCreateIfMissing(true);final RocksDB db = RocksDB.open(options, dbPath)) {// 写入数据db.put("key1".getBytes(), "value1".getBytes());// 读取数据byte[] value = db.get("key1".getBytes());if (value != null) {System.out.println("Get key1: " + new String(value));}} catch (RocksDBException e) {e.printStackTrace();}}
}上面的代码使用 RocksDB Java API 进行了最基本的数据写入和读取操作
static {RocksDB.loadLibrary(); // 加载 RocksDB 的本地 C++ 库
}RocksDB 是基于 C++ 实现的,Java 访问需要通过 JNI 调用 C++ 的共享库,所以必须先调用 loadLibrary() 加载本地库。
String dbPath = "/tmp/rocksdb_example";指定数据库路径,RocksDB 会在这个目录下创建相关文件(如 .sst 数据文件、MANIFEST、LOG 等)
.sst 文件是 RocksDB 实际存储键值对数据的文件
MANIFEST 是 RocksDB 的元数据管理文件,记录了数据库的全局状态和 .sst 文件的组织信息。
LOG 是 RocksDB 的操作日志文件,记录数据库的运行过程和关键事件。
try (final Options options = new Options().setCreateIfMissing(true);final RocksDB db = RocksDB.open(options, dbPath)) {创建一个 Options 实例用于配置 RocksDB。
setCreateIfMissing(true):如果目录中不存在数据库,则自动创建。
用 RocksDB.open() 打开数据库,并传入配置选项和路径。
使用 try-with-resources 自动释放资源。
Options 实例是一个配置容器,用于在打开或创建数据库时,设置各种核心参数和行为规则。
db.put("key1".getBytes(), "value1".getBytes());写入一条 key-value 数据。注意 key 和 value 都需要是 byte[] 类型。
db.put() 方法要求键(key)和值(value)必须以 字节数组(byte []) 形式传入
String.getBytes() 的作用就是将字符串转换为字节数组
byte[] value = db.get("key1".getBytes());
if (value != null) {System.out.println("Get key1: " + new String(value));
}查询 key1 对应的值,并转换成字符串打印出来。
} catch (RocksDBException e) {e.printStackTrace();
}所有的 RocksDB 读写操作都可能抛出 RocksDBException,必须捕获。
使用RocksDB的基本流程
| 步骤 | 描述 |
|---|---|
| 1 | 加载本地库:RocksDB.loadLibrary() |
| 2 | 设置数据库路径 |
| 3 | 配置 Options(如 setCreateIfMissing(true)) |
| 4 | 打开数据库:RocksDB.open() |
| 5 | 数据操作:put() 写入,get() 读取 |
| 6 | 释放资源:通过 try-with-resources 自动关闭 |
RocksDB架构
LSM 树(Log-Structured Merge Tree)原理(核心架构)
LSM-Tree 是 RocksDB 的核心结构,是一种写优化的数据结构,主要目的是提升写入和压缩效率。
写优化可以理解为:让写入数据这个操作变得特别快、特别高效,哪怕为此在读取数据时多做一点工作。
想象你是一个秘书,需要记录老板随时说的话(写入就是记录这些话)
非写优化的方式:老板说一句,你就立刻找到笔记本上对应的位置(比如按日期排序的页面),擦掉旧内容、写下新内容,还要保证笔记本永远整齐。但这样每次记录都要花时间翻页、修改,老板说得快了,你根本跟不上。
写优化的方式:老板说什么,你先拿一张便签纸快速记下来(不管顺序),攒够一沓便签后,再找个空闲时间,把这些便签上的内容按顺序整理到笔记本里。
这样一来,老板说话时你能 秒记(写入极快),只是后续整理时要花点时间,而且别人查内容时,可能需要先翻便签再翻笔记本(读取时多做点工作)。
对应到 RocksDB 的 LSM-Tree:
写入数据时,先快速丢进内存中的临时区域(类似便签纸),不立即整理顺序。
等临时区域满了,再后台慢慢合并成有序的大文件(类似整理便签到笔记本)
写入流程(WAL + MemTable → SSTable)
| 阶段 | 描述 |
|---|---|
| 1. WAL 写入 | 所有写操作首先写入 Write-Ahead Log,保证崩溃恢复 |
| 2. MemTable | 同步写入内存结构(默认是 SkipList,有序结构) |
| 3. Immutable MemTable | MemTable 写满后冻结,后台线程 flush |
| 4. SSTable(Level 0) | Frozen MemTable 持久化为 L0 文件(SSTable) |
| 5. Compaction 合并 | 后台自动将多个 SSTable 按 key 顺序合并到更低层(如 L1、L2) |
| 英文 | 中文 | 简单说明 |
|---|---|---|
| WAL(Write-Ahead Log) | 预写日志 | 写入数据前先记录的日志文件,用于数据库崩溃后恢复数据,保证数据不丢失 |
| MemTable | 内存表 | 内存中的临时数据结构,用于快速接收新写入的键值对(默认用跳表实现,保持有序) |
| Immutable MemTable | 不可变内存表 | 当 MemTable 写满后冻结(不能再写入新数据),等待刷到磁盘 |
| SSTable(Sorted String Table) | 有序字符串表 | 磁盘上的持久化数据文件,内部键值对按 key 排序,是 RocksDB 存储数据的最终形式 |
| Level 0(L0) | 0 层级 | SSTable 按层级组织,刚从内存刷出的文件放在 Level 0,后续逐步合并到更高层级(L1、L2 等) |
| Compaction | 合并操作 | 后台将多个 SSTable 合并为更少、更大文件的过程,同时删除重复或过期数据,优化查询效率 |
读取流程(多级查找 + Filter + Cache)
查找流程是:
1. MemTable(内存中的最新值)
2. Immutable MemTable(正在 flush 的旧值)
3. 各级 SSTable(Level 0~N)中查找
优先查 Index Block → 再查 Data Block → 找 key
配合 Bloom Filter 快速排除无命中表
SSTable 文件内部除了 Data Block(数据块),还有 Index Block(索引块)
索引块记录了每个 Data Block 中 最小 key 和 最大 key,以及该 Data Block 在文件中的位置;
查找时,先查索引块,通过 key 的范围快速定位到 可能包含目标 key 的 Data Block,再去该 Data Block 中精确查找。
比如 SSTable 有 100 个 Data Block,索引块会告诉你 Block 1 存的是 key=1~100,Block 2 是 101~200……,要找 key=150,直接定位到 Block 2 即可,不用逐个扫描所有块。
Bloom Filter(布隆过滤器)
一种概率性数据结构,每个 SSTable 可附带一个 Bloom Filter,用于快速判断某个 key 是否可能存在于该 SSTable 中,能极大减少不必要的磁盘查询(比如直接排除掉肯定不含该 key 的文件)每个 SSTable 可以提前生成一个 Bloom Filter,记录该文件中所有 key 的 “特征”;
查找时,先通过 Bloom Filter 判断 这个 SSTable 有没有可能包含目标 key:
如果 Bloom Filter 说 “没有”,就直接跳过这个文件(100% 准确)
如果说 “可能有”,再去文件里仔细查(有极小概率误判,但能过滤掉绝大多数无效文件)
Cache(块缓存,减少重复磁盘读取)
Cache 是 内存中的临时仓库,用于缓存最近访问过的 Data Block:
第一次读取某个 key 时,需要从磁盘加载对应的 Data Block,同时把这个块存到 Cache 里
下次再读同一个块中的数据(比如相邻的 key),直接从 Cache 取,不用再读磁盘。
LSM Tree(日志结构合并树) 的数据流转过程图
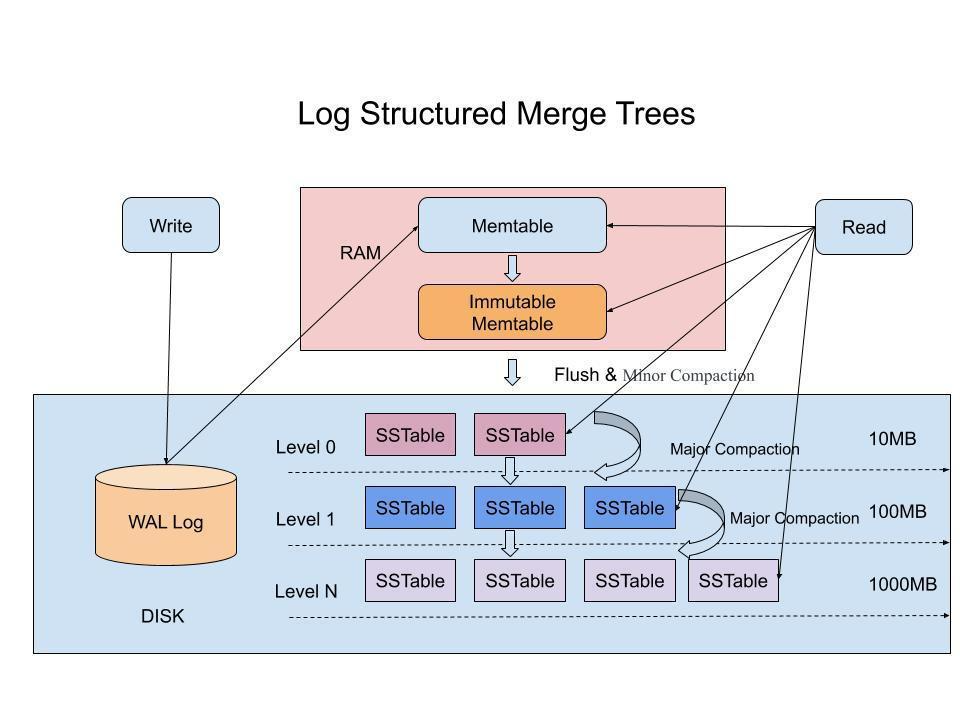
写入先写日志和内存,再异步写磁盘(Level 0),随后逐级合并到更低层(Level 1+),最终形成有序、压缩、高效可读的多级磁盘存储结构。
这里的异步写磁盘是指当 MemTable 写满变成 Immutable MemTable 后,RocksDB 会启动后台线程将其持久化到磁盘(生成 Level 0 的 SSTable),而主线程不需要等待这个过程完成,可以继续处理新的写入请求。
SSTable(Sorted String Table)结构
SSTable 是磁盘上的不可变有序表,结构如下:
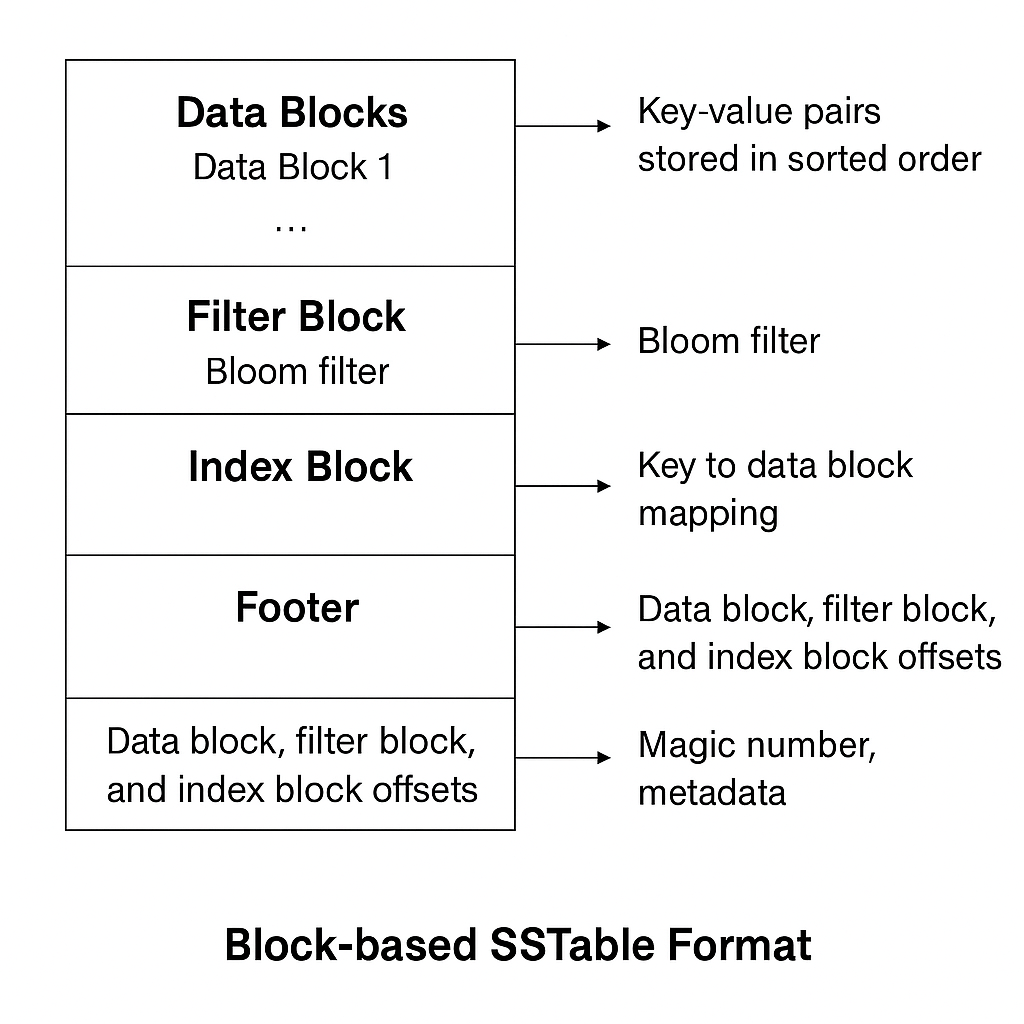
Key-value pairs stored in sorted order 按键排序存储的键值对
Data block, filter block, and index block offsets 数据块、过滤块和索引块的偏移量
Block-based SSTable Format 基于块的 SSTable 格式
Footer(页脚)
内容:包含元数据和偏移信息,用于标识 Data Block、Filter Block 和 Index Block 的偏移量,即这些块在文件中存储的起始位置。
功能:
偏移量:指示 Data Block、Filter Block 和 Index Block 在文件中的存储位置。这个信息在读取 SSTable 文件时非常关键。
Magic Number(魔数):用来验证文件的完整性,确保数据没有损坏。
Metadata(元数据):记录文件的全局信息,比如 SSTable 的版本、压缩算法、创建时间等
特点:
每个 block 是顺序压缩的 key-value 数据
Index Block 一般用二分查找快速定位对应 Data Block
Footer 存放偏移量、magic number,方便快速定位结构
Block 默认大小:4KB(可配置)
可以使用压缩算法如 Snappy、LZ4,对每个 Block 压缩存储。
布隆过滤器(Bloom Filter)
布隆过滤器是一种空间效率很高的概率型数据结构,用于判断一个元素是否在一个集合中。布隆过滤器可以告诉我们某个元素一定不存在集合中或者某个元素可能存在集合中。
RocksDB为每个SSTable维护一个布隆过滤器,以减少不必要的磁盘I/O。
| 作用 | 减少 I/O 读取开销 |
|---|---|
| 场景 | 在读取某个 key 时,如果能快速判断某个 SSTable 不包含这个 key,就可以跳过读取磁盘内容 |
| 原理 | 多个 hash 函数 + 位图,如果返回一定不存在,就不必查;但可能存在时仍需验证 |
布隆过滤器可视化网站如下,可点击链接跳转
布隆过滤器可视化
布隆过滤器的基本原理
布隆过滤器的核心组件是一个位数组和多个哈希函数。在初始状态下,位数组中的所有位都被设置为0。当需要添加一个元素时,系统会使用多个不同的哈希函数对该元素进行处理。每个哈希函数都会将元素映射到位数组中的某个位置。这些被映射到的位置随后会被设置为1。通过使用多个哈希函数,每个元素都会在位数组中标记多个位置。
当需要查询一个元素是否存在时,系统会使用相同的哈希函数对查询元素进行处理,得到对应的位置。然后检查位数组中这些位置的值。如果发现任何一个位置的值为0,那么可以确定该元素一定不在集合中,因为如果元素曾经被添加过,这些位置应该都是1。然而,如果所有对应位置的值都是1,我们只能说该元素可能存在于集合中,因为这些位置的1可能是由其他元素设置的。这就是布隆过滤器的一个特性:它可能会产生假阳性(误报),但不会产生假阴性(漏报)。
压缩和缓存策略
压缩(Compaction ≠ 压缩算法)
Compaction 是指合并整理多个 SSTable 到低层的过程(逻辑压缩)
压缩算法 是指 Snappy、Zlib 等物理压缩数据块大小(减少磁盘占用)
支持的压缩算法:
| 算法 | 特点 |
|---|---|
| Snappy(默认) | 压缩快、解压快,压缩率中等 |
| Zlib | 压缩率高,速度慢 |
| LZ4 / ZSTD | 高速压缩,兼顾压缩率(ZSTD 很受欢迎) |
缓存机制:
| 缓存类型 | 说明 |
|---|---|
| Block Cache | 缓存 Data Block,默认使用 LRU,存放在内存中 |
| Table Cache | 缓存 SSTable 句柄(文件元信息) |
| Index Block Cache | 从 RocksDB 7.x 起,索引块和 Filter Block 也可以独立缓存,提高命中率 |
RocksDB 的 Block Cache 会把 SSTable 中经常访问的 Data Block(数据块)临时存储在主内存里,而不是一直存放在磁盘上。
句柄(Handle) 可理解为一个指向资源的标识或指针,而 SSTable 句柄本质上包含了该 SSTable 文件的核心元信息,是 RocksDB 与操作系统交互、快速操作文件的中介。
为什么需要缓存 SSTable 句柄?
想象一下如果每次访问 SSTable 都要重新从磁盘读取这些元信息(比如重新打开文件、查询文件属性),就像每次找档案都要先去查 “档案目录册”,会非常耗时。
而缓存句柄后,RocksDB 可以直接从内存中拿到这些元信息,省去了重复与操作系统交互、读取文件元数据的过程,从而加快对 SSTable 的访问速度(比如快速判断文件是否包含目标 Key、快速定位到文件内的索引块)。
简单说,SSTable 句柄就是 SSTable 文件的 “身份证 + 快速访问通行证”,缓存它是为了避免重复 “查证件” 的麻烦,提升效率。
列族(Column Family)
在 RocksDB 中,列族是对逻辑键值空间的划分单位
可以把 RocksDB 想象成一个大仓库,而列族就是仓库里的不同货架。
每个货架(列族)独立存储一类数据:比如一个货架放用户基本信息(姓名、年龄),另一个货架放用户订单记录,不同货架的数据互不干扰,但都属于这个仓库(数据库)
共享底层存储,但逻辑上隔离:所有列族的数据最终都存在 RocksDB 的磁盘文件(SSTable)中,但查询时可以指定只查某个货架的数据,不用扫描整个仓库。
| 对比 | 传统数据库的 表格(Table) | RocksDB 的列族(Column Family) |
|---|---|---|
| 数据结构 | 有严格的列定义,每条记录字段固定 | 无固定结构,以 Key-Value 对存储,Value 格式完全灵活 |
| 隔离粒度 | 表之间完全独立(数据存储、索引通常分开) | 列族共享数据库的底层存储引擎(如 SSTable 文件可能混合存储多个列族数据),但逻辑上隔离 |
| 核心用途 | 按实体类型(如用户、订单)分类结构化数据 | 按访问模式或数据热度分类(如高频访问数据放一个列族,低频放另一个),优化性能 |
| 查询方式 | 通过 SQL 语句按列查询(如SELECT name FROM user) | 通过 Key 直接定位,查询时指定列族即可(如db.Get(ReadOptions(), "user_info", "user:100")) |
使用 RocksDB 的底层架构特性
public class RocksDBArchitectureOverview {static {RocksDB.loadLibrary();}public static void main(String[] args) {String dbPath = "/tmp/rocksdb_example";try (DBOptions dbOptions = new DBOptions().setCreateIfMissing(true).setCreateMissingColumnFamilies(true);ColumnFamilyOptions cfOptions = new ColumnFamilyOptions().setWriteBufferSize(8 * 1024 * 1024).setTableFormatConfig(new BlockBasedTableConfig().setBlockCacheSize(64 * 1024 * 1024).setFilterPolicy(new BloomFilter(10))).setCompressionType(CompressionType.LZ4_COMPRESSION)) {List<ColumnFamilyDescriptor> cfDescriptors = List.of(new ColumnFamilyDescriptor(RocksDB.DEFAULT_COLUMN_FAMILY, cfOptions));List<ColumnFamilyHandle> cfHandles = new ArrayList<>();try (RocksDB db = RocksDB.open(dbOptions, dbPath, cfDescriptors, cfHandles)) {// 写入db.put(cfHandles.get(0), "key".getBytes(), "value".getBytes());// 读取byte[] result = db.get(cfHandles.get(0), "key".getBytes());System.out.println("读取 key = " + new String(result));}for (ColumnFamilyHandle handle : cfHandles) {handle.close();}} catch (RocksDBException e) {e.printStackTrace();}}
}RocksDB.loadLibrary();加载 RocksDB 的本地 C++ 库。
1. 打开数据库(支持 Column Family)
DBOptions dbOptions = new DBOptions().setCreateIfMissing(true).setCreateMissingColumnFamilies(true);DBOptions 是数据库级别的配置,控制整体行为。
setCreateIfMissing(true) 表示如果目录中不存在数据库,则自动创建。
setCreateMissingColumnFamilies(true) 表示如果访问的 Column Family 不存在则创建。
2. 配置 Column Family 的存储行为(重点)
ColumnFamilyOptions cfOptions = new ColumnFamilyOptions().setWriteBufferSize(8 * 1024 * 1024) // 设置 MemTable 大小为 8MB.setTableFormatConfig(new BlockBasedTableConfig().setBlockCacheSize(64 * 1024 * 1024) // Block 缓存大小为 64MB.setFilterPolicy(new BloomFilter(10))) // 使用布隆过滤器(10个bits/键).setCompressionType(CompressionType.LZ4_COMPRESSION); // 使用 LZ4 压缩 SST 文件写缓冲区通常指的是MemTable,它是一个内存中的数据结构,用于暂存新写入的数据。
这一段开启了 RocksDB 的核心优化特性:
每个 MemTable 达到 8MB 就会 flush 成一个 SST 文件(触发 compaction)BlockBasedTableConfig 控制 SST 表的块格式
BlockCache 是 用于读缓存的 LRU 缓存(提高读取性能)
BloomFilter(10) 表示为每个 key 设置约 10 位布隆过滤器,在查找时可快速判断 key 不存在,避免不必要的磁盘读取,节省 IO。
最后启用 LZ4 压缩 SST 文件,兼顾压缩率和解压速度。
3. 定义 Column Family + 句柄收集
List<ColumnFamilyDescriptor> cfDescriptors = List.of(new ColumnFamilyDescriptor(RocksDB.DEFAULT_COLUMN_FAMILY, cfOptions)
);
List<ColumnFamilyHandle> cfHandles = new ArrayList<>();RocksDB 支持多个 Column Family,必须通过 descriptor 配置每个的行为。
ColumnFamilyDescriptor(列族描述符)
这是一个配置容器,用来定义某个列族的名称和它的专属配置。
代码中 new ColumnFamilyDescriptor(RocksDB.DEFAULT_COLUMN_FAMILY, cfOptions) 表示:
第一个参数 RocksDB.DEFAULT_COLUMN_FAMILY:指定列族名称为RocksDB默认列族(RocksDB 必须至少有一个列族,默认名为 default)
第二个参数 cfOptions:是之前定义的 ColumnFamilyOptions 对象(包含该列族的内存大小、压缩方式等配置)
List<ColumnFamilyDescriptor> cfDescriptors
用一个列表存储所有列族的描述符,告诉 RocksDB要创建这些列族,每个列族按这样的配置运行
List<ColumnFamilyHandle> cfHandles
ColumnFamilyHandle(列族句柄)是访问列族的钥匙,后续对列族的读写操作(如 db.get(handle, key))都需要通过它。
这里初始化一个空列表,用于在数据库打开后接收 RocksDB 返回的句柄(句柄由 RocksDB 内部生成,与列族一一对应)
4. 打开 RocksDB 并操作数据
try (RocksDB db = RocksDB.open(dbOptions, dbPath, cfDescriptors, cfHandles)) {db.put(cfHandles.get(0), "key".getBytes(), "value".getBytes());byte[] result = db.get(cfHandles.get(0), "key".getBytes());System.out.println("读取 key = " + new String(result));
}db.put(cfHandles.get(0), "key".getBytes(), "value".getBytes()) 向数据库写入一个键值对(Key-Value)
cfHandles.get(0):指定列族句柄(这里取列表中第一个,即之前定义的默认列族)
"key".getBytes():要写入的键(Key),RocksDB 要求键值对必须是字节数组(byte [])
"value".getBytes():要写入的值(Value),同样需转为字节数组。
5. 资源释放
for (ColumnFamilyHandle handle : cfHandles) {handle.close();
}关闭每个 Column Family 的句柄,避免资源泄露。