ClickHouse高性能实时分析数据库-消费实时数据流(消费kafka)
告别等待,秒级响应!这不只是教程,这是你驾驭PB级数据的超能力!我的ClickHouse视频课,凝练十年实战精华,从入门到精通,从单机到集群。点开它,让数据处理速度快到飞起,让你的职业生涯从此开挂!
全套视频教程联系博主
1 写在前面
ClickHouse 的 Kafka 引擎本质上是一个数据流的适配器(Adapter),而不是一个存储引擎。
你需要记住的最重要的一点是:Kafka 引擎本身不存储任何数据。它就像一根管道,直接连接到 Kafka 的 Topic。当你查询一个 ENGINE = Kafka 的表时,ClickHouse 会实时地从 Kafka Topic 中拉取(Consume)消息,并根据你指定的格式(如 JSON, CSV)进行解析,然后将结果返回给你。
由于它不存储数据,所以它通常不单独使用,而是与物化视图(Materialized View) 结合,形成一个完整、高效的数据摄取流水线(Pipeline)。
核心比喻:
Kafka Topic:一个源源不断流淌着“原浆数据”的河流。
ClickHouse Kafka 引擎:一根直接插在河里的智能吸管,它只负责吸水,不负责存水。
ClickHouse MergeTree 表:一个巨大无比的蓄水池(我们的数据仓库),水最终要存在这里。
物化视图:一个永动机水泵,自动把吸管吸上来的水,源源不断地泵入蓄水池。
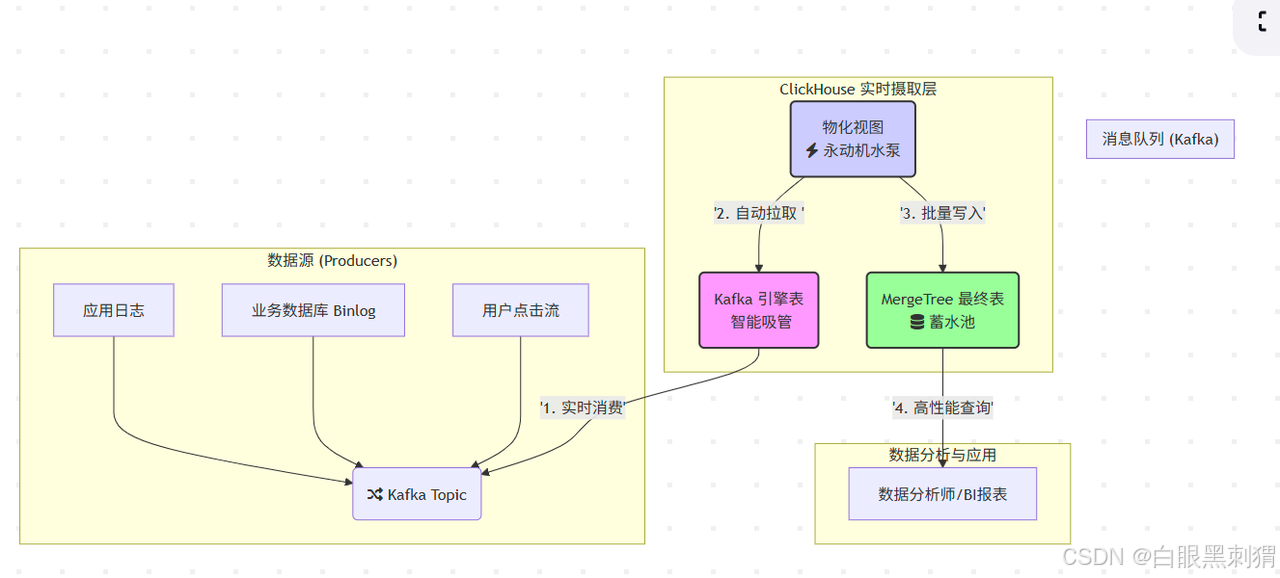
图解:数据从各种源头生产出来,汇入 Kafka 这条大河。我们的“智能吸管”(Kafka引擎表)从河里实时吸水,然后“永动机水泵”(物化视图)立刻把水抽走,存入“蓄水池”(MergeTree表),最后数据分析师就可以在蓄水池里愉快地游泳(查询)了!
2 实操(上代码)
光说不练假把式!我们来亲手搭建这个系统。假设 Kafka 的 user_actions topic 里有如下JSON数据流: {"user_id": 101, "event": "login", "ts": "2023-10-27 10:00:00"} {"user_id": 102, "event": "purchase", "ts": "2023-10-27 10:00:05"}
第一步:建造蓄水池 (创建 MergeTree 目标表)
我们得先有个地方存数据。这是我们的最终归宿,必须坚固耐用(性能好)。
-- 这是我们的“蓄水池”,用来存最终的数据
CREATE TABLE account_store (user_id UInt64,name String,city String
) ENGINE = MergeTree()
PARTITION BY city
ORDER BY (user_id);第二步:安装智能吸管 (创建 Kafka 引擎表)
现在,把我们的吸管插到 Kafka 河里。
-- 这是我们的“智能吸管”,它本身不存水!
CREATE TABLE account (user_id UInt64,name String,city String
) ENGINE = Kafka
SETTINGSkafka_broker_list = 'linux01:9092,linux01:9092,linux03:9092',kafka_topic_list = 'zk_data',kafka_group_name = 'g1', -- 非常重要!每个流用独立组名kafka_format = 'JSON', -- 告诉吸管,水里的是啥味道的(数据格式)kafka_num_consumers = 1;灵魂拷问:如果我现在 SELECT * FROM user_actions_pipe,会发生什么? 答案:你会看到 当前 Kafka Topic 中的数据!就像你用吸管吸了一口河水尝尝味道。但你关掉查询,数据就没了,因为它不存储。
第三步:启动永动机水泵 (创建物化视图)
-- 这是我们的“永动机水泵”,连接吸管和蓄水池
CREATE MATERIALIZED VIEW user_actions_pump TO account_store AS
SELECT user_id, name, city
FROM account ;工作原理:
TO account_store: 告诉水泵,水要泵到哪个池子。AS SELECT ... FROM account: 告诉水泵,要从哪个吸管抽水,以及抽水的方式(可以直接抽,也可以在抽的时候过滤、转换一下)。
大功告成! 从现在起,任何进入 account Topic 的新消息,都会被这套全自动系统捕捉,并在几秒钟内出现在 account_store 表中,随时可以查询!
3 性能优化: 如果管道堵了怎么办
关键监控指标:消费延迟 (Lag) Lag 指的是你的消费速度和你上游数据生产速度之间的差距。Lag 持续增大,说明你的“水泵”马力不足,水快要从河里溢出来了!
-- 查水表!看看我们的消费组状态
SELECTtable,partition,last_committed_offset, -- 水泵上次汇报说“我抽到这儿了”current_offset, -- 河流的最新水位(current_offset - last_committed_offset) AS lag, -- 水位差last_error -- 水泵有没有发出警报?
FROM system.kafka_consumers
WHERE table = 'user_actions_pipe';
问题:Lag 持续增长
原因:ClickHouse写入慢(目标表结构复杂、硬件瓶颈)或消费能力不足。
解决:
优化
MergeTree表的ORDER BY键。增加
kafka_num_consumers数量(不能超过Topic分区数)。给 ClickHouse 服务器加配置!
问题:
last_error显示错误,消费停止
原因:遇到了“毒丸消息” (Poison Pill)!比如你的数据流里混进了一个非JSON格式的字符串,解析器直接卡住。
解决:给 Kafka 引擎表加上“金刚不坏之身”。
坏(脏)数据怎么办?设置一下就可以了--针对格式不正确的数据
-- 加上这个设置,遇到10个连续的坏数据就跳过,不影响大部队
ALTER TABLE user_actions_pipe MODIFY SETTING kafka_skip_broken_messages = 10;