Datawhale AI 夏令营—科大讯飞AI大赛(大模型技术)—让大模型理解表格数据(列车信息表)
目录
一、本次赛事目标:让大模型理解表格数据(列车信息表)
二、分析赛题、对问题进行建模
赛事背景
赛题解读
数据分析与探索
赛题要点与难点
解题思考过程
三、Baseline方案
Baseline概况
Baseline运行步骤
Baseline文件概况
Baseline方案思路
Baseline核心逻辑
一、输入数据处理
二、问题构建与生成方式
三、大模型调用与结果提取
四、标准格式转换与训练集构建
五、最后使用星辰MaaS平台进行微调
四、有哪些方式可以提升方案?
附录:知识点概述
欢迎回到Datawhale AI夏令营第二期,大模型技术方向的学习~
我们将聚焦在讯飞项目实践。
作为此次项目实践的第二个Task,我们将—— 理解项目目标、从业务理解到技术实现!
也许大家很好奇,我们Task1所使用的微调数据集是如何得来的,我们将在本节揭秘!一起来——
-
理解用AI理解列车信息表,究竟有哪些难点和价值、
-
以及,具体要如何判断AI是否真的理解了列车信息表
-
基于列车信息表,使用大模型构建QA对
一、本次赛事目标:让大模型理解表格数据(列车信息表)
本次赛事聚焦智慧交通领域中的一个重要场景——列车信息查询与问答。
在实际应用中,乘客和调度人员经常需要从复杂的列车时刻表中快速获取精准信息,如检票口位置、停留时间、跨车次关联等信息。
传统的人工查询方式效率低下,且难以应对复杂的多条件查询需求。因此本项目将和大家一起探讨,如何用AI赋能这项工作。
知识点提要 : 表结构数据处理、微调数据集构造、模型蒸馏
相关知识点清单:
| 学习模块 | 核心知识点 | 一句话介绍 |
| 大语言模型基础 | 大模型 API 调用方法 | 学习如何通过 API 使用大语言模型,发送请求并获取结果。 |
| Prompt 工程 | 掌握如何编写有效的提示词,引导模型输出期望的结果。 | |
| 参数高效微调 | LoRA 和合并精调的区别 | 了解 LoRA(低秩适配)与合并精调在模型微调中的不同原理和使用场景。 |
| 全量微调 | 对整个模型的所有参数进行训练,以适应特定任务或数据集。 | |
| 数据集构建 | pandas 的基本使用 | 学习使用 pandas 进行数据读写、整理和基础操作。 |
| pandas 的数据筛选 | 掌握 pandas 中按条件筛选和提取数据的方法,如 loc、iloc 和布尔索引等。 |
二、分析赛题、对问题进行建模
在开始建立AI模型之前,我们需要全面理解赛题的背景和要求,
对问题进行清晰的定义,并分析数据的特征,理解解题的要点和难点。
这将有助于我们选择合适的模型和方法来解决问题。
赛事背景
在智慧交通平台中,乘客和调度人员需快速从庞杂的列车时刻表中获取精准信息(如检票口位置、停留时间、跨车次关联)。
传统方法依赖人工查询和分析,效率低且难以应对复杂问题。
大模型在表格理解方面已经取得了显著的进展,正在帮助用户以更直观、更高效的方式处理和解释数据。
简单而言,构建一个让大模型可以理解表格数据的方案,对于提升系统效率等具有重大意义。
赛题解读
本次大赛提供了结构化数据表格(列车时刻表)作为数据集,参赛者需基于讯飞星辰MaaS平台构建一个人工智能模型。
该模型能基于给定表格中的结构化数据,结合表格内容提取信息并回答指定的问题。
赛事任务分为两个阶段:
-
让模型学习如何解析和表示表格数据。【生成可用于微调的QA对】
-
回答与表格数据对应的自然语言问题。【微调,让大模型掌握这个表格的知识并进行回答】
该模型应具备自然语言处理(NLP)能力,能够理解用户自然语言问题中的意图(如查询始发站、终到站、检票口等),以支持多种问题类型,例如:

模型的输出应该是包含数值结果、文本描述及必要推理步骤的结构化回答,能够直接展示提取的指标和相关信息。
平台限制: 本次赛事规定选手须在讯飞星辰MaaS平台进行任务开发。需要注意的是,该平台目前主要支持模型的微调、训练和部署,不直接提供应用开发或Agent功能嵌入。
这意味着我们主要的解题手段将围绕 微调(学会列车信息表的)模型 展开,核心在于 构建高质量的(围绕列车信息表的信息的)微调数据集(QA对)。
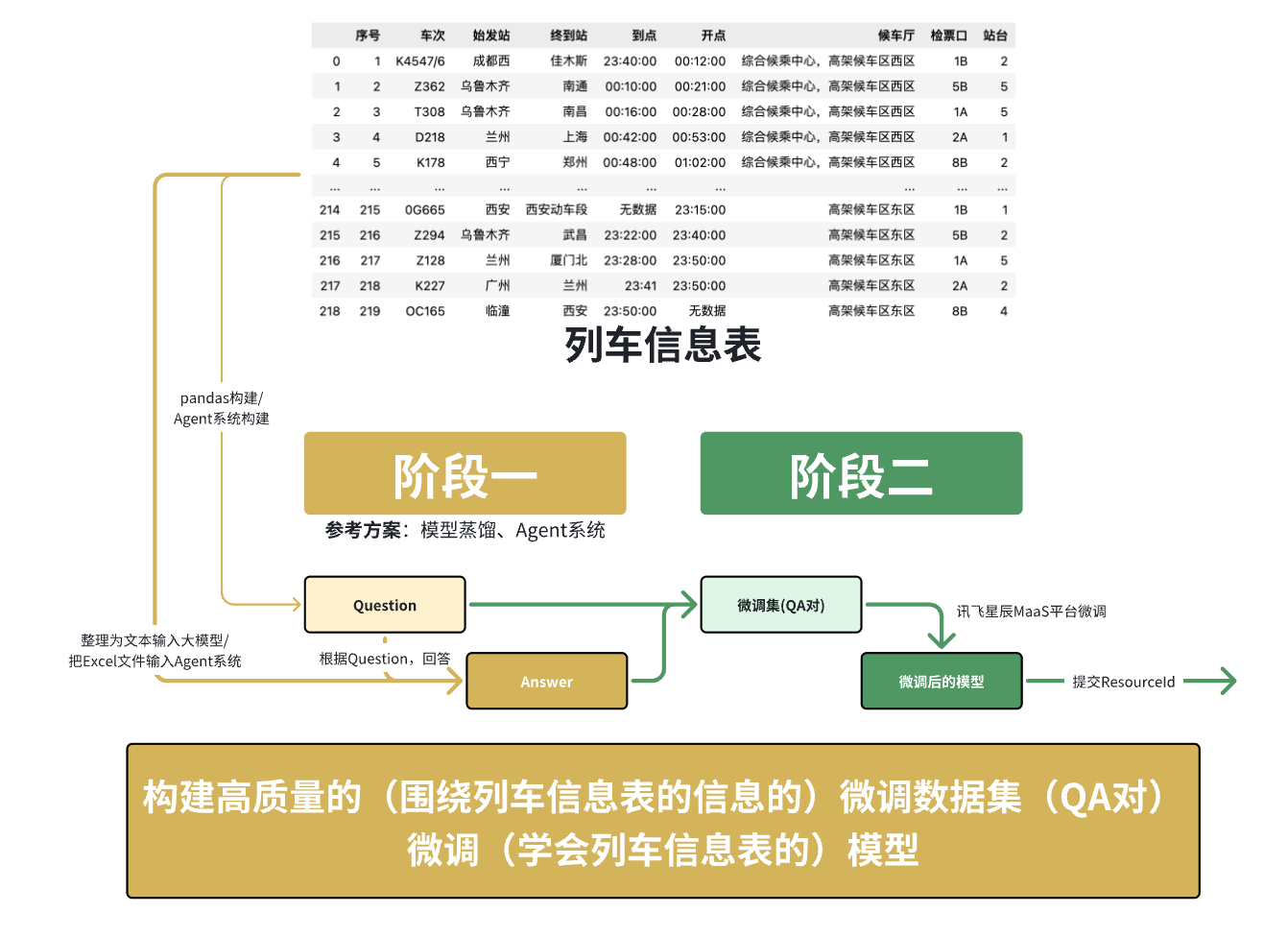
数据分析与探索
然后我们可以通过 经验/资料查阅肉眼观测/代码 等手段,对 赛事提供的数据 有大致的理解和把握
本赛题围绕 列车时刻表结构化数据 展开,核心任务目标是构造覆盖关于给定列车时刻表的多类型问题的问答对,供大模型在讯飞星辰MaaS平台进行微调。
输入数据:info_table(训练+验证集).xlsx(结构化的列车时刻表)

-
格式:.xlsx文件
-
数据量:200+条列车时刻信息
-
字段:包含“序号”、“车次”、“始发站”、“终到站”、“到点”、“开点”、“候车厅”、“检票口”、“站台”等信息。
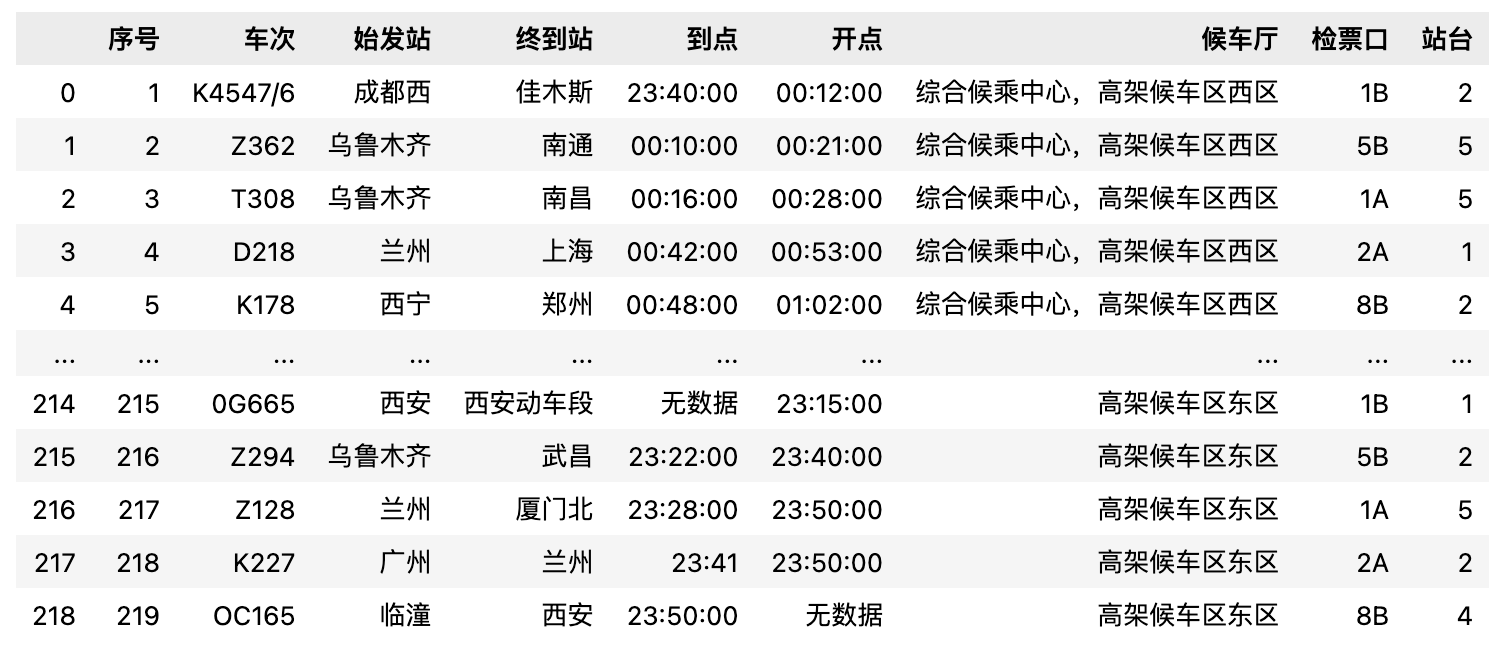
从整体查看数据我们可以了解到,数据当中存在一些信息缺失,我们可以针对性进行人工清洗、补充
SFT数据:基于输入数据,生成的可在星辰MaaS平台上微调模型的数据(QA对)
-
格式:Alpaca 或 Sharegpt
-
Alpaca字段举例:一定要有“instruction”和“output”
-
Alpaca基本格式:
{"instruction": "Z152次列车的终到站是哪里?", "output": "Z152次列车的终到站是北京西。"}数据处理的关键点:
-
时间格式统一化处理:原始数据中时间格式可能不统一,需要进行标准化处理,便于后续的时间计算和推理。
-
缺失值处理策略:数据中可能存在“无数据”或空值,需要定义合适的填充或处理策略。
-
字段间关系分析:理解各字段之间的逻辑关系,例如“车次”与“检票口”、“站台”的对应关系,以及“到点”、“开点”与“停留时长”的计算关系。
-
数据清洗和标准化:确保数据质量,移除异常值或不一致的数据。
赛题要点与难点
| 核心要点 |
|
| 主要难点 |
|
Baseline:理解数据、训练数据构造、模型训练
提升:Agent工具构造、模型蒸馏
解题思考过程
你看到题目会首先思考到什么、做什么、找了什么参考资料,遇到了什么卡点,如何解决?
本赛题要求大家使用给定的 CSV 表格数据来构造大模型可以接受的文本数据,然后在此基础上进行模型训练,最终使得模型拥有表格解读的能力。
在面对这类结构化数据问答赛题时,我们最初的思路是,直接利用大模型来生成问题和答案。
例如,在Prompt里给定一行表格数据,让大模型直接基于我们给定的输出模板给出 “问题-答案”的json信息。
这种方法看似高效,但经过实践和深入讨论,我们发现这种 “让模型既生成问题又生成答案” 的方式存在一个核心问题:无法保证生成的问题和答案的准确性。
如果模型生成的问题本身就是错误的,或者答案与表格数据不符,那么用这样的数据去微调我们的目标模型(学生模型),会导致学生模型学到错误的知识,最终影响其在真实测试集上的表现。
因此,我们调整了数据构建的策略,采用了 模型蒸馏(Model Distillation)的思想:
-
编程生成问题(确保问题正确性):我们不再让大模型凭空生成问题,而是通过编程(例如使用Pandas结合模板)来构造基于表格数据的确定性问题。例如,针对每一行数据,我们可以生成“X车次的终到站是哪里?”、“Y车次应该从哪个检票口检票?”等单字段查询问题。对于更复杂的问题类型,也可以设计相应的编程逻辑来生成。这样,我们能确保问题的正确性和相关性。
-
使用更强大的大模型(教师模型)生成答案(确保答案质量):对于这些编程生成的问题,我们再将其输入给一个能力更强、更稳定的教师模型(例如一个大型的通用LLM,如Qwen3-8B),让教师模型根据给定的表格数据和问题来生成答案。由于教师模型能力更强,它生成答案的准确性会更高。
-
构建高质量SFT数据集:将编程生成的“正确问题”和教师模型生成的“高质量答案”配对,形成
{"instruction": "问题", "output": "答案"}格式的SFT(Supervised Fine-Tuning)数据集。 -
微调目标模型(学生模型):最后,使用这个高质量的SFT数据集来微调我们的目标模型(学生模型)。通过这种方式,我们让学生模型学习如何从结构化数据中提取信息并生成准确的答案,从而在讯飞星辰MaaS平台上达到更好的性能。
这种方法的优点在于:
-
保证了问题的正确性:避免了模型生成无效或错误的问题。
-
提升了答案的质量:通过强大的教师模型生成答案,确保了训练数据的准确性。
-
实现了模型蒸馏:将大模型的知识“蒸馏”到我们微调的小模型中,使其在特定任务上表现优异,同时可能具备更快的推理速度,这对于赛题的“回答响应时长”指标至关重要。
-
契合平台限制:由于平台只支持微调,这种数据构建方式是克服平台无Agent功能限制的有效途径。
但如果仅限于此,分数会有上限和瓶颈,且不适合扩展。
因此更好的方法可能是构造一个表格问答Agent,这个Agent拥有以下7个工具(tool),可用于构造正确的回答。

三、Baseline方案
Baseline概况
| 核心信息 | 信息详情 |
| 赛题任务类型 | 赛题的任务是微调一个用于领域知识问答的大模型,核心任务是sft数据的制作。 |
| Baseline 代码 |
|
| Baseline 所需要使用的库 | pandas、requests、re、json、tqdm |
| Baseline 所需环境和时间 | CPU环境可运行,重点是计算机能通过http调用大模型。 免费注册即可获得大模型API额度:硅基流动 |
| Baseline 分数 | 57 |
| Baseline 方案概述 |
|
| Baseline 必备知识点清单 |
|

Baseline运行步骤
-
准备免费的大模型api资源,申请地址:硅基流动
-
安装必要依赖:
pip install pandas requests tqdm -
数据准备:确保
info_table(训练+验证集).xlsx - Sheet1.csv文件位于正确路径。项目根目录下创建 data 和 train_data 的文件夹,它们的作用发如下:
-
data:存放赛题的原始数据
-
train_data:存放生成的训练数据,后续用于上传到平台中微调大模型
然后将赛题的数据放入data文件夹中
-
-
环境配置:安装Python及其所需的库,如
pandas,requests,tqdm。 -
API Key配置:在
baseline.ipynb中填入你申请的硅基流动(或其他教师模型)的API Token。 -
运行Jupyter Notebook:一键运行
baseline.ipynb中的所有单元格。-
第一个单元格读取并初步处理数据。
-
第二个单元格定义了
call_llm函数(用于调用教师模型)和create_question_list函数(用于编程生成问题),并执行问题和答案的生成过程。 -
第三个单元格将生成的数据转换为SFT所需的JSON格式,并保存为
single_row.json。
-
-
模型微调:将生成的
single_row.json文件上传至讯飞星辰MaaS平台,并根据平台指引进行LoRA微调训练。
Baseline文件概况
-
info_table(训练+验证集).xlsx - Sheet1.csv:原始的列车时刻表数据。 -
baseline.ipynb:Jupyter Notebook文件,包含数据预处理、编程问题生成、教师模型调用生成答案、SFT数据格式转换的核心代码。 -
微调数据集_列车信息.json(或single_row.json): 经过处理和生成后的SFT数据集示例,包含instruction(问题) 和output(答案) 对。
点击查看代码详情
import pandas as pd
import requests
import re
import json
from tqdm import tqdm# 读取数据
data = pd.read_excel('data/info_table(训练+验证集).xlsx')
data = data.fillna('无数据')def call_llm(content: str):"""调用大模型Args:content: 模型对话文本Returns:list: 问答对列表"""# 调用大模型(硅基流动免费模型,推荐学习者自己申请)url = "https://api.siliconflow.cn/v1/chat/completions"payload = {"model": "Qwen/Qwen3-8B","messages": [{"role": "user","content": content # 最终提示词,"/no_think"是关闭了qwen3的思考}]}headers = {"Authorization": "", # 替换自己的api token"Content-Type": "application/json"}resp = requests.request("POST", url, json=payload, headers=headers).json()# 使用正则提取大模型返回的jsoncontent = resp['choices'][0]['message']['content'].split('</think>')[-1]pattern = re.compile(r'^```json\s*([\s\S]*?)```$', re.IGNORECASE) # 匹配 ```json 开头和 ``` 结尾之间的内容(忽略大小写)match = pattern.match(content.strip()) # 去除首尾空白后匹配if match:json_str = match.group(1).strip() # 提取JSON字符串并去除首尾空白data = json.loads(json_str)return dataelse:return contentreturn response['choices'][0]['message']['content']def create_question_list(row: dict):"""根据一行数创建问题列表Args:row: 一行数据的字典形式Returns:list: 问题列表"""question_list = []# ----------- 添加问题列表数据 begin ----------- ## 检票口question_list.append(f'{row["车次"]}号车次应该从哪个检票口检票?')# 站台question_list.append(f'{row["车次"]}号车次应该从哪个站台上车?')# 目的地question_list.append(f'{row["车次"]}次列车的终到站是哪里?')# ----------- 添加问题列表数据 end ----------- #return question_list# 简单问题的prompt
prompt = '''你是列车的乘务员,请你基于给定的列车班次信息回答用户的问题。
# 列车班次信息
{}# 用户问题列表
{}'''
output_format = '''# 输出格式
按json格式输出,且只需要输出一个json即可
```json
[{"q": "用户问题","a": "问题答案"
},
...
]
```'''train_data_list = []
error_data_list = []
# 提取列
cols = data.columns
# 遍历数据(baseline先10条数据)
i = 1
for idx, row in tqdm(data.iterrows(), desc='遍历生成答案', total=len(data)):try:# 组装数据row = dict(row)row['到点'] = str(row['到点'])row['开点'] = str(row['开点'])# 创建问题对question_list = create_question_list(row)# 大模型生成答案llm_result = call_llm(prompt.format(row, question_list) + output_format)# 总结结果train_data_list += llm_resultexcept:error_data_list.append(row)continue# 转换训练集
data_list = []
for data in tqdm(train_data_list, total=len(train_data_list)):if isinstance(data, str):continuedata_list.append({'instruction': data['q'], 'output': data['a']})json.dump(data_list, open('train_data/single_row.json', 'w', encoding='utf-8'), ensure_ascii=False)Baseline方案思路
你知道、我们是如何想到和选取这样的baseline方案的吗?
本Baseline方案的核心思路是通过模型蒸馏的方法,将一个强大的教师模型(如Qwen3-8B)在特定任务上的知识,迁移到我们最终需要微调的学生模型上。具体步骤如下:
-
表格数据文本化:将结构化的列车时刻表数据(每一行代表一趟列车的信息)转换为易于大模型理解的文本格式。
-
编程生成问题:针对每一行列车数据,我们手动设计问题模板,并通过编程方式(例如Python脚本)批量生成问题。例如,对于“车次”、“检票口”、“终到站”等字段,可以生成“
{车次}号车次应该从哪个检票口检票?”、“{车次}次列车的终到站是哪里?”等问题。这种方式确保了生成问题的语法正确性和与表格内容的强相关性。 -
教师模型生成答案:将文本化的列车信息和编程生成的问题作为Prompt输入给一个能力更强的教师模型。教师模型根据其强大的理解和推理能力,为每个问题生成对应的答案。
-
构建SFT数据集:将编程生成的问题和教师模型生成的答案配对,形成
{"instruction": "问题", "output": "答案"}的JSON格式数据集。这个数据集就是用于微调学生模型的SFT数据。 -
学生模型LoRA微调:将构建好的SFT数据集上传到讯飞星辰MaaS平台,并使用LoRA技术对选定的基础模型(学生模型)进行微调。微调后的模型将能够根据用户提出的问题,从内部学习到的表格知识中给出准确的回答。
Baseline核心逻辑
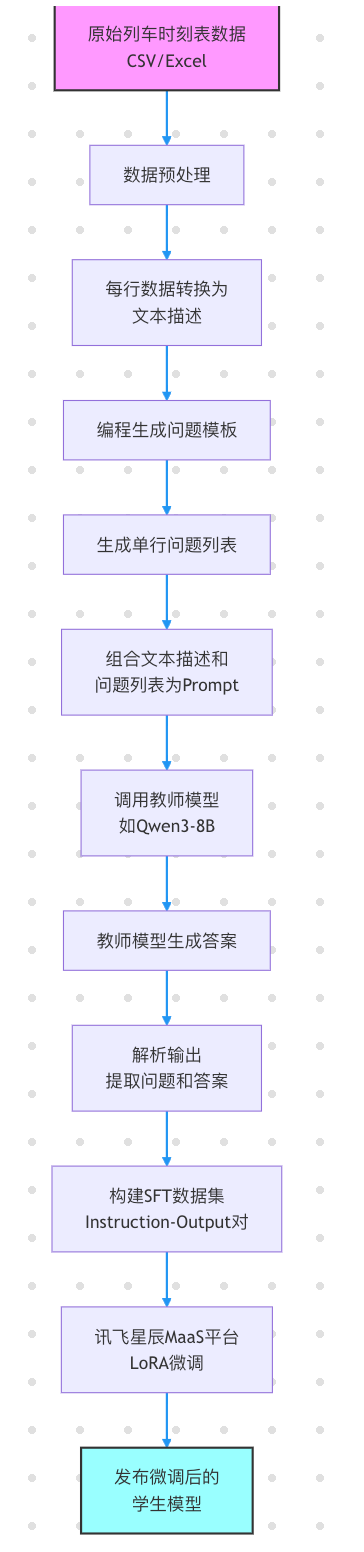
整个流程聚焦于 数据清洗、问题构建、生成与格式转换 四个步骤,确保模型能准确理解并回答与表格相关的自然语言问题。
核心函数说明:
-
pd.read_excel('data/info_table.xlsx'):使用pandas库读取原始的列车时刻表数据。 -
data.fillna('无数据'):对数据中的缺失值进行填充,统一处理。 -
create_question_list(row: dict):-
作用:根据传入的单行列车数据(字典形式),编程生成一系列针对该行数据的单字段查询问题。
-
示例:对于车次“K4547/6”,会生成“K4547/6号车次应该从哪个检票口检票?”、“K4547/6号车次应该从哪个站台上车?”、“K4547/6次列车的终到站是哪里?”等问题。
-
-
call_llm(content: str):-
作用:调用外部大模型API(教师模型)来生成答案。
-
输入:包含列车信息和问题列表的Prompt。
-
输出:教师模型根据Prompt生成的答案(通常是JSON格式的问答对)。
-
注意:需要替换
Authorization中的token为你的API Key。
-
-
prompt.format(row, question_list) + output_format:构建发送给教师模型的完整Prompt,其中row是当前列车行的文本描述,question_list是编程生成的问题列表,output_format是要求模型输出的JSON格式。 -
json.dump(data_list, open('single_row.json', 'w', encoding='utf-8'), ensure_ascii=False):将最终生成的SFT数据集保存为JSON文件,以便上传到微调平台。
一、输入数据处理
-
原始数据文件为
info_table(训练+验证集).xlsx,格式为结构化表格,每行代表一趟列车信息。 -
包含字段有:车次、始发站、终到站、到点时间、开点时间、候车厅、检票口、站台等。
为便于处理,我们进行了如下操作:
-
对缺失字段填充
'无数据'; -
将“到点”“开点”等时间字段统一为字符串格式;
-
删除如“序号”等无关字段,保留核心字段用于生成问题。
二、问题构建与生成方式
为了构造覆盖度广的问题集,我们设计了包含多种类型的 Prompt 模板,指导大模型从用户视角生成问题及其答案:
常见问题类型包括:
-
单字段查询 (如:“Z152次列车的终到站是哪里?”)
-
多条件查询 (如:“在哪候车、几点发车、几号检票口?”)
-
时间推理 (如:“列车在某站停留多久?”)
-
推荐类问题 (如:“凌晨从X地出发去Y地坐哪趟车?”)
输出格式统一要求为结构化 JSON:
[{"q": "生成的问题","a": "对应的答案"},...
]三、大模型调用与结果提取
我们调用硅基流动中的 Qwen/Qwen3-8B 模型进行自然语言生成,核心过程如下:
-
将单条列车记录转换为结构化输入(dict → JSON)
-
拼接 prompt + 数据,作为输入发送到模型接口
-
使用正则表达式从返回内容中提取
json格式的问答对数组
四、标准格式转换与训练集构建
为了适配讯飞星辰MaaS平台的模型训练输入,我们将生成结果进一步转换为 instruction 格式的训练样本:
{"instruction": "Z152次列车的终到站是哪里?","output": "Z152次列车的终到站是北京西"
}五、最后使用星辰MaaS平台进行微调
详见Task1的步骤
四、有哪些方式可以提升方案?
可以尝试思考以下问题:
-
如何设计编程逻辑,高效且准确地生成涉及多行数据、跨字段计算和时间推理的复杂问答对?
-
在模型蒸馏过程中,除了选择更强大的教师模型,还有哪些方法可以进一步提升生成答案的质量和多样性?
-
在有限的计算资源下,如何平衡模型的准确率、回答响应时长和信息传达效率,以在赛题中取得更高的综合得分?
阶段 1:复杂问答对的生成逻辑
目标:一次生成 N 组「多行-跨字段-时间推理」问答,准确率>95%,可并行。1. 数据层:
• 用 Arrow/Feather 把原始表转列式存储,按「主键+时间戳」双索引。
• 预计算常用聚合:滑动窗口统计、环比、同比、累计值,落盘为物化视图。2. 逻辑层(DSL → SQL → QA):
• 定义一套轻量级 DSL(YAML 即可),描述“计算单元 + 条件 + 时间锚点”。
例:
```
- name: q1
select: [user_id, order_amt]
where: "region='华东'"
window: [-7d, -1d]
op: sum(order_amt) / sum(order_cnt) - 1
```
• 用 Jinja2 模板把 DSL 实时渲染成 SQL;SQL 走 DuckDB/ClickHouse,毫秒级出结果。
• 结果+DSL 喂给 LLM(教师模型)生成自然语言问句和答案,Prompt 模板:
```
你是一名数据分析师。请基于下面 SQL 及结果,生成一个中文问答对。
SQL: {{sql}}
结果: {{result}}
要求:
1. 问题必须包含时间推理(如“过去7天”)。
2. 答案给出数值和简短解释。
```
• 用 JSON Schema 验证输出,不合法立即重试。3. 并发层:
• DSL 文件拆成 block,Ray/ multiprocessing 并行渲染,单机 8 核可跑 2k QA/分钟。
• 对命中缓存的 DSL 直接复用,减少 60% 计算。────────────────
阶段 2:蒸馏阶段的“除教师模型外”的增效手段1. 数据端增强
• 问题改写:用 T5-small 做 paraphrase,同义句 3× 扩充。
• 逻辑反转:把“最大值”改成“最小值”,把“7 天”改成“30 天”,保持答案也相应翻转,防止模型死记。2. 训练端技巧
• R-Distillation:除了常规 KL 散度,再加一个 Ranking Loss,让学生的 top-1 概率与老师排序一致。
• 分阶段冻结:先训 embedding+最后一层 1 epoch,再全量微调 2-3 epoch,省 40% 时间。3. 推理端后处理
• 多学生投票:3 个不同初始化的小模型投票,取多数答案;对数值题可加权平均。
• 基于规则的 sanity checker:数值超出 3σ 或日期不合法直接触发二次推理。────────────────
阶段 3:有限算力下的“三指标”平衡(准确率 / 响应时长 / 信息效率)1. 指标量化
• Score = 0.5·Acc + 0.3·(1/Latency) + 0.2·InfoRatio
其中 InfoRatio = 有效信息字节数 / 答案总字节数(用中文分词器计算)。2. 资源分配策略
• 建立“模型阶梯”:
A. 规则/缓存 → 1 ms,覆盖率 40%
B. 1.3B 小模型 LoRA → 50 ms,覆盖率 85%
C. 7B 大模型 → 300 ms,兜底 100%
• 用轻量级 router(一个 3 层 MLP)按问题复杂度打分,动态路由。3. 运行时优化
• KV-Cache 复用:同一 batch 中相似前缀共享 KV,显存下降 25%。
• 动态 batching + continuous batching(如 vLLM),可把 RTT 再降 20-30%。
• 量化:INT4 weight + FP16 KV-Cache,显存减半,精度掉 <1%。4. 信息效率
• 答案模板化:固定“数值+单位+原因”三段式,减少冗余 15-20%。
• 后处理压缩:用中文标点压缩 + 指代消解,把“2025 年 7 月 26 日” → “今日”。────────────────
落地方案小结
1. 用 DSL+列式存储先把「复杂计算」转成可缓存的 SQL,LLM 只负责自然语言包装。
2. 蒸馏阶段靠数据增强、Ranking Loss、多学生投票,在不换教师模型的情况下提 3-5 pt。
3. 竞赛/业务场景下,把模型切成规则-小-大三级,量化+KV-Cache+动态 batching,把 Score 提升 10-15% 的同时显存占用减半。
附录:知识点概述
-
LoRA (Low-Rank Adaptation):一种高效的参数微调技术,通过在预训练模型中注入小的、可训练的低秩矩阵来适应新任务,从而大大减少了需要训练的参数量和计算成本,同时保持了模型性能。
-
SFT (Supervised Fine-Tuning):监督式微调,指使用带有明确“指令”(Instruction)和“输出”(Output)的标注数据集来训练模型,使其学习如何遵循指令并生成期望的响应。
-
模型蒸馏 (Model Distillation):一种模型压缩技术,通过训练一个小型模型(学生模型)来模仿一个大型模型(教师模型)的行为,从而在保持大部分性能的同时,减小模型体积并提高推理速度。
-
提示工程 (Prompt Engineering):设计和优化输入给大模型的文本提示(Prompt),以引导模型生成期望的、高质量的输出。