数据结构预备知识
在学习数据结构之前,有些知识是很有必要提前知道的,它们包括:集合框架、复杂度和泛型。本篇文章专门介绍这三个东西。
1.集合框架
1.1 什么是集合框架
Java 集合框架(Java Collection Framework),又被称为容器,是定义在 java.util 包下的一组接口 和 其实现类。其主要表现为将多个元素置于一个单元中,用与对这些元素进行快速、便捷的存储、检索、管理,即我们平时俗称的增删查改。
以下是Java集合框架的完整体系图,梳理了集合框架中比较重要的接口、抽象类与具体的类的继承/实现关系。
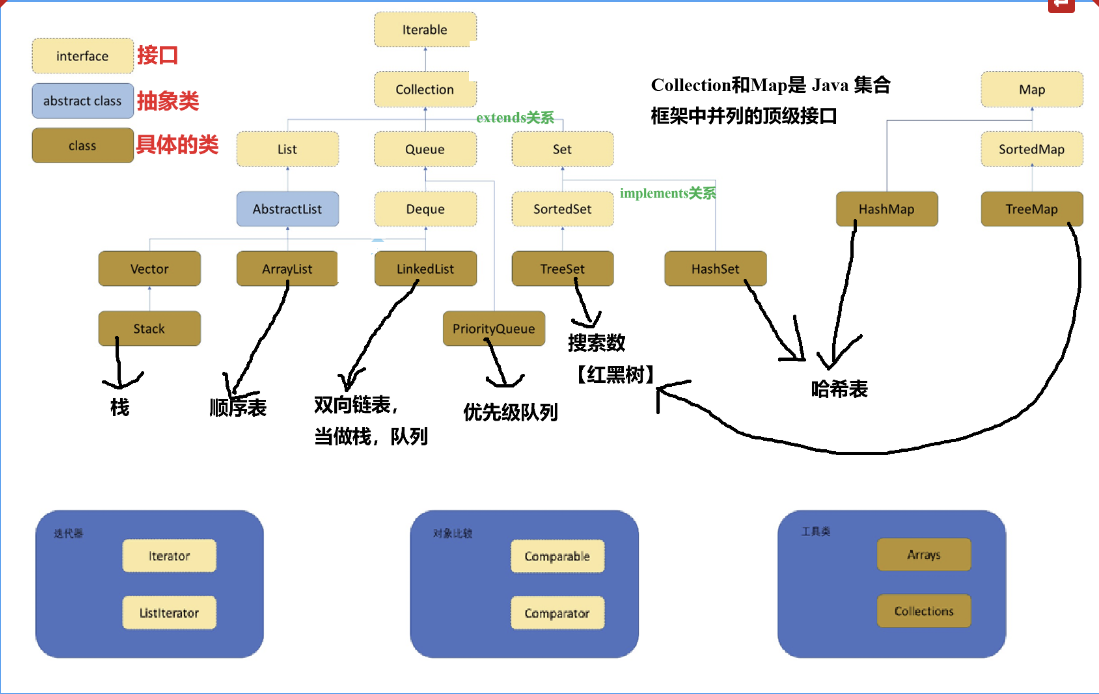
1.2 集合框架的重要性
- 使用成熟的集合框架,有助于我们便捷、快速的写出高效、稳定的代码。
- 学习背后的数据结构知识,有助于我们理解各个集合的优缺点及使用场景。
1.3 数据结构以及算法
1.3.1 什么是数据结构
数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。
关于数据结构的一些问答:
1.Java的数据结构与C语言的数据结构有区别吗?
“没有”区别,只不过是实现的语言不一样。
2.数据结构和数据库是一个东西吗?
有区别的,数据库其实是用来储存数据的,数据库在储存数据的时候,底层会用到数据结构。
3.数据结构怎么样才能学好?
多思考,多画图,多写代码,多去调试。
1.3.2 什么是算法
算法(Algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为输出。简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果。
如何学好算法呢?
死磕代码,注意画图和思考,多写博客总结和多刷题。
另外,数据结构与算法相辅相成!
2.复杂度
知道了什么是算法,那么如何去衡量一个算法的好坏呢?这就引出了新概念——算法效率。
2.1 算法效率
算法效率分析分为两种:第一种是时间效率,第二种是空间效率。时间效率被称为时间复杂度,而空间效率被称作空间复杂度。 时间复杂度主要衡量的是一个算法的运行速度,而空间复杂度主要衡量一个算法所需要的额外空间,在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
2.2 时间复杂度
2.2.1 时间复杂度的概念
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个数学函数,它定量描述了该算法的运行时间。一个 算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
可以举个例子,现有一函数:
public void func(int N) {int count = 0;for (int i = 0; i < N; i++) {for (int j = 0; j < N; j++) {count++;}}for (int i = 0; i < 2*N; i++) {count++;}int m = 10;while ((m--) > 0) {count++;}System.out.println(count);}结合时间复杂度的概念及这个函数,可以得出 func执行的基本操作次数为:
F(N) = N^2 + 2*N + 10
2.2.2 大o的渐进表示法
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这里我们使用大O的渐进表示法。
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
大o的渐进表示法的规则:
- 用常数1取代运行时间中的所有加法常数。
- 在修改后的运行次数函数中,只保留最高阶项。
- 如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
那么使用大o的渐进表示法,上述函数 func 的时间复杂度为:
O(N^2)
大o的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外,算法的时间复杂度还存在着最好、平均和最坏情况:
最好情况:任意输入规模的最小运行次数(下界)。
平均情况:所有可能的输入下,算法执行所需时间的平均度量。
最坏情况:任意输入规模的最大运行次数(上界)
在实际中一般情况下,关注的是算法的最坏运行情况。
2.2.3 常见的时间复杂度计算举例
1.冒泡排序
void bubbleSort(int[] array) {for (int end = array.length; end > 0; end--) {boolean sorted = true;for (int i = 1; i < end; i++) {if (array[i - 1] > array[i]) {Swap(array, i - 1, i);sorted = false;}}if (sorted == true) {break;}}}这个方法基本操作在最好情况下会执行N次,即一开始这个这个数组就已经排好序了,最坏情况下:数组完全逆序排列,那么第一轮需要操作 n-1次,第二轮需要操作 n-2次,第三轮需要操作 n-3次,……,最后一轮需要操作 1次,那么合起来就是:(n-1) + (n-2) + …… + 1 = (n-1)*n/2,用大o渐进表示法,得:O(N^2)。
2.二分查找
int binarySearch(int[] array, int value) {int begin = 0;int end = array.length - 1;while (begin <= end) {int mid = begin + ((end-begin) / 2);if (array[mid] < value)begin = mid + 1;else if (array[mid] > value)end = mid - 1;elsereturn mid;}return -1;}
这个方法的基本操作在最好情况下执行1次,即目标值刚好在中间,最坏情况:一直找,直到不满足循环条件。因为每一轮查找都会使循环区间减半,即令初始区间长度为n,第一轮之后,区间长度变为 n/2,第二轮之后,n/4,……,第k轮后,n/(2*k),此时需要继续缩小区间,直到区间为0,即 n/(2*k) <= 1,那么有 k 约等于 n以2为底的对数,使用大o的渐进表示法,得:O(n以2为底的对数)。
3.一般递归
long factorial(int N) {return N < 2 ? N : factorial(N-1) * N;}像这种一般递归的方法, 通常它的时间复杂度 = 递归的次数 * 每次递归执行的次数。像这个方法,它的时间复杂度 = (N - 1)* 1 = N - 1,使用大o的渐进表示法,得:O(N)。
4.斐波那契数列的递归
int fibonacci(int N) {return N < 2 ? N : fibonacci(N-1)+fibonacci(N-2);}用递归求斐波那契数列的方法不能看出一般的递归方法,因为当它在计算 fibonacci(N)时,这个方法又会调用 fibonacci(N - 1)和 fibonacci(N-2),这两个子问题又会各自调用更小规模的子问题,形成一个类似二叉树的调用结构:
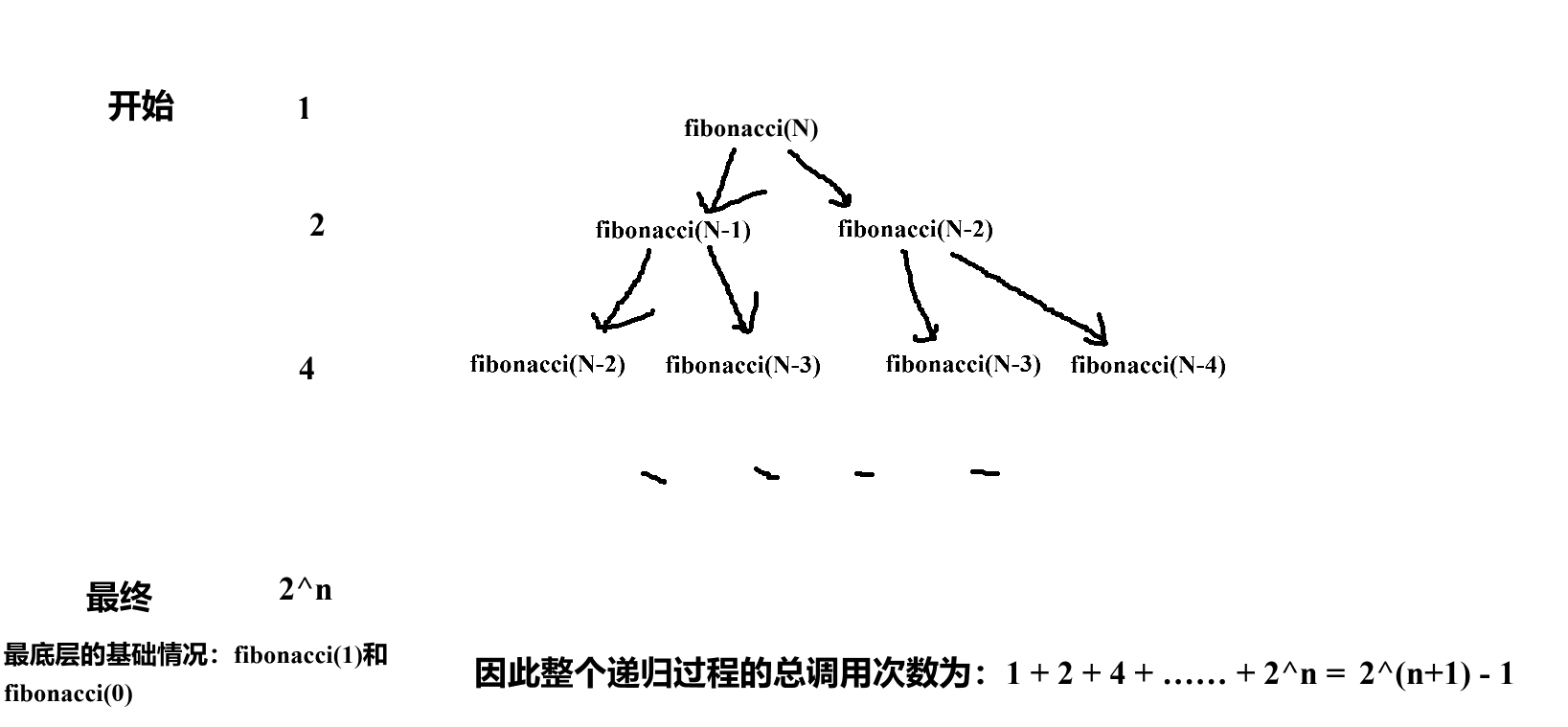
使用大o的渐进表示法,得:O(2^n)。
2.3 空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度 。空间复杂度衡量的是算法在执行过程中额外占用的存储空间(不包括输入数据本身占用的空间)。空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。空间复杂度计算规则基本跟时间复杂度类似,也使用大O渐进表示法。
举个例子:
void bubbleSort(int[] array) {for (int end = array.length; end > 0; end--) {boolean sorted = true;for (int i = 1; i < end; i++) {if (array[i - 1] > array[i]) {Swap(array, i - 1, i);sorted = false;}}if (sorted == true) {break;}}}这个冒泡排序方法中仅使用了几个固定的变量:end、sorted、i ,这些变量的占用的存储空间不会随着输入数组的大小变化而变化,交换元素的 Swap方法也只需要临时变量来交换两个元素,同样不依赖与数组规模。因此它的空间复杂度为3,使用大o的渐进表示法,得:O(1)。
3.泛型
3.1 包装类
在Java中,由于基本数据类型不是继承自Object,为了在泛型代码中可以支持基本类型,Java给每个基本类型都对应了一个包装类型。
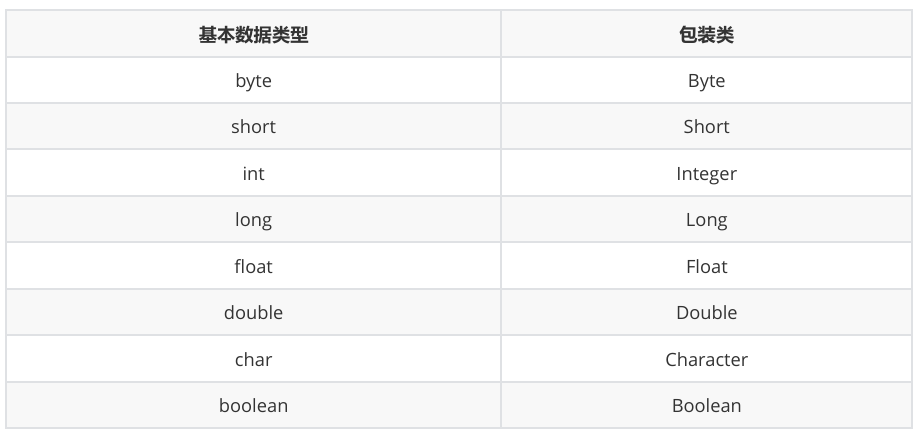
3.1.1 装箱与拆箱
装箱(也叫装包):把基本数据类型 变为 包装类类型的过程叫做装箱。
拆箱(也叫拆包):把保证类类型 变为 基本数据类型的过程叫做拆箱。
int i = 10;
//装箱操作,新建一个 Integer 类型对象,将 i 的值放入对象的某个属性中
Integer i1 = Integer.valueOf(i);
Integer i2 = new Integer(i);
//拆箱操作,将 Integer 对象中的值取出,放到一个基本数据类型中
int j = i1.intValue();
3.1.2 自动装箱与自动拆箱
装箱和拆箱分为自动和显式,上述就是显式装箱和显式拆箱。从显示装箱和显式拆箱的使用过程来看,它们的操作带来了不少的代码量,所以为了减少开发者的负担,Java提供了自动机制:
int i = 10;
//自动装箱
Integer i1 = i;
Integer i2 = (Integer)i;
//自动拆箱
int j = i1;
int k = (int)i1;
那么自动装箱和自动拆箱的底层机制到底是怎么样的呢?很简单,底层是在我们使用自动装箱和自动拆箱时,Java帮我们调用了具体的方法,也就是使用了显式的方式。
3.1.3 装箱与拆箱的面试题
为什么下列的代码的输出结果不一样?
public class Main {public static void main(String[] args) {Integer a = 100;Integer b = 100;System.out.println(a == b);Integer c = 200;Integer d = 200;System.out.println(c == d);}
}//运行结果
true
false
显然这里涉及到了装箱操作,我们都知道装箱底层上是调用了 Integer.valueOf()方法,那么到Integer类中去找这个方法:
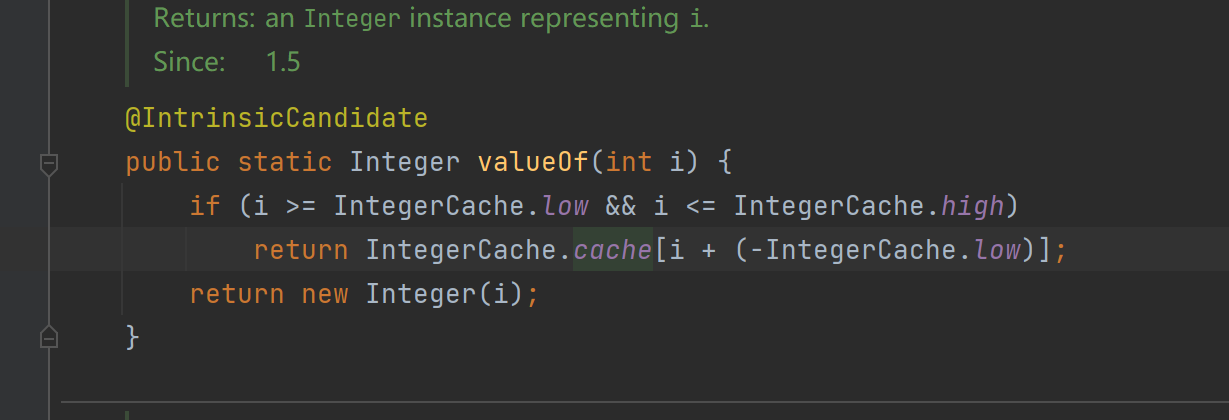
发现:当传入的 i 在某个范围内时,是从一个数组中直接去获取值,当 i 在这个范围内时,它返回一个新的 Integer对象。但是这个范围是多少呢?继续深挖,我们发现:
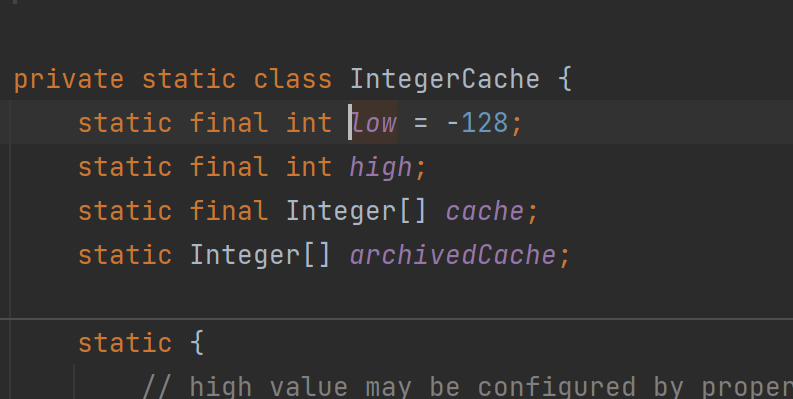
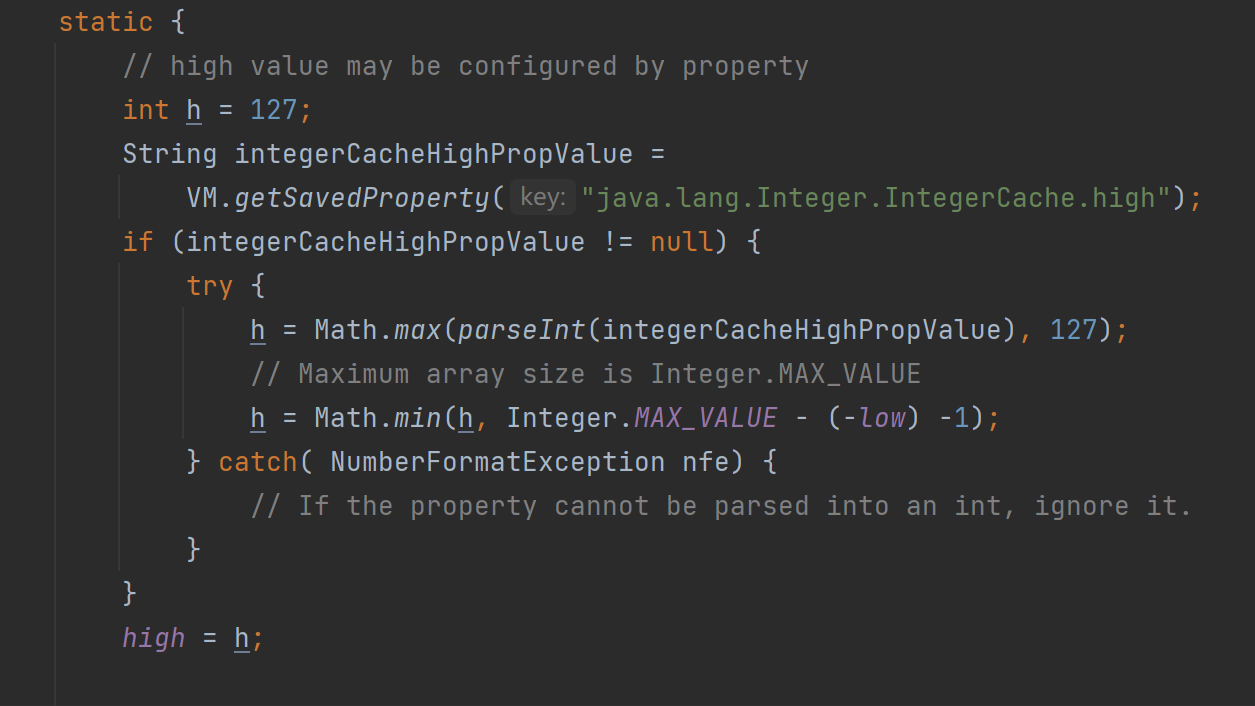
low = -128,high = 127,因此得出结论:这个范围是-128 到 127!这就解释清楚了,因为传入a和b的值为100,在这个范围内,因此它们是从同一个数组内获取的值,而传入c和d的值为200,不在这个范围内,因此它们的值分别来自新建的两个Integer对象,用 == 进行比较,比较的是它们的地址,a和b来自同一个数组,因此地址相同,故输出为true,而c和d是两个不同的对象,因此地址不同,故输出false。
3.2 什么是泛型
一般的类和方法,只能使用具体的类型: 要么是基本类型,要么是自定义的类。如果要编写可以应用于多种类型的代码,这种刻板的限制对代码的束缚就会很大,但泛型的出现打破了这种束缚。通俗讲,泛型就是适用于许多类型。从代码上讲,就是对类型实现了参数化。
3.3 不使用泛型的问题
现在,要做一件事:实现一个类,类中包含一个数组成员,使得数组中可以存放如何类型的数据,也可以根据成员方法返回数组中某个下标的值。要解决这个问题,我们会想到:
- 以前学的数组,只能放指定类型的元素。
- 所有类的父类默认为Object类。
那么突发奇想——数组的类型能不能是Object类。
class MyArrays {public Object[] arrays = new Object[10];public void setArrays(int pop,Object obj) {this.arrays[pop] = obj;}public Object getArrays(int pop) {return this.arrays[pop];}
}public class Main {public static void main(String[] args) {MyArrays myArrays = new MyArrays();myArrays.setArrays(0,10);myArrays.setArrays(1,"10");//String str = myArrays.getArrays(2); //编译报错String str = (String) myArrays.getArrays(1);System.out.println(str);}
}
把代码实现后我们发现:
- 任何的类型的数据都可以存放。
- 1号下标本身就是字符串,但是直接取出来会报错,要强制类型转换才不报错。
虽然说,在这种情况下什么类型的数据都能放入数组中,但是我们还是希望它只能装一种数据类型,而不是同时装这么多类型。而泛型的主要目的就在这里了!就是指定当前的容器,只能装什么类型的对象,让编译器去做检测。 从而实现:想装什么类型,就将什么类型作为参数传入。
3.4 泛型的语法
//第一种语法格式
class 分析类名称 <类型形参列表> {
//这里可以使用类型参数
}
例如
class ClassName <T1,T2, .... ,Tn> {
}
//第二种语法格式
class 分析类名称 <类型形参列表> extends 继承的类 /* 这里可以使用类型参数*/ {
//这里可以使用类型参数
}
例如
class ClassName <T1,T2, .... ,Tn> extends ParentClass<T1> {
//这里可以使用类型参数
}
借助泛型,原来的代码我们可以改成这样:
class MyArrays <T>{public Object[] arrays = new Object[10];public void setArrays(int pop,T obj) {this.arrays[pop] = obj;}public T getArrays(int pop) {return (T)this.arrays[pop];}
}
public class Main {public static void main(String[] args) {MyArrays<String> arrays= new MyArrays<>();arrays.setArrays(0,"1");arrays.setArrays(1,"hello");String str = arrays.getArrays(1);System.out.println(str);}
}//运行结果
hello完全符合我们的预期!
【注意】
- 类名之后的<T>代表占位符,表示当前类是一个泛型类
- 在main方法中,类型后面加入<String> 表示指定当前类型
- 用能够接收数组元素的变量去接收数组元素不报错,不需要强制类型转换
- 当存放的元素与泛型类指定的元素不同时,会报错,编译器会在存放元素时帮助我们进行类型检测
3.5 泛型类的使用
使用的语法格式:
泛型类<类型参数> 变量名; //定义一个泛型类引用
new 泛型类<类型参数>(构造方法实参); //实例化一个泛型类对象
举例
MyArray<Integer> list = new MyArrays<Integer>();
注意:泛型的类型实参只接受类,所有的基本数据类型必须使用包装类!
类型推导
当编译器可以可以根据上下文推导出类型实参时,可以省略类型实参的填写,例如:
MyArray<Integer> list = new MyArrays< >();
3.6 裸类型
裸类型是一个泛型类但没有带着类型实参,例如:
MyArray list = new MyArrays();
//这就是一个裸类型
注意:我们不要自己去使用裸类型,因为裸类型是为了兼容老版本的 API 保留的机制。
3.7 泛型如何编译
Java的泛型机制是在编译时实现的(它的两个功能:自动类型检查和自动类型转换),在编译的过程中,编译器会将所有的 T 替换为 T的上界类型,也就是说编译结束后所有的 T 都被替换为了T的上界类型,这种机制称为:擦除机制。
若没有 T 没有指定上界类型,那么默认指定Object类。
3.8 泛型的上界
在定义泛型类时,有时候需要对传入的类型变量做一定的约束,可以通过类型边界来约束。
具体的语法格式:
class 泛型类名称<类型形参 extends 类型边界> {
……
}
举例:
public class MyArrays<E extends Number> {
……
}
//意思是:只接受 Number 的子类型作为 E 的类型实参
注意:没有指定类型边界 E,可以视为 E extends Object
特殊场景
public class MyArrays<E extends Comparable<E>> {
……
}
//意思是:接收的 E 必须实现了Comparable接口,即extends后面加接口说明传入的类型实参必须实现这个接口!
3.9 泛型方法
除了有泛型类,还有泛型方法,它的语法格式为:
方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) {
……
}
举例:
class Alg {public <E> void Swap(E[] arrays,int i,int j) {E t = arrays[i];arrays[i] = arrays[j];arrays[j] = t;}
}这是一个非静态的泛型方法,当然也有静态的泛型方法,即在public后面加 static即可。
关于泛型方法的使用一般有两种:使用类型推导和不使用类型推导。这里拿非静态的泛型方法举例:
使用类型推导:
import java.util.Arrays;class Alg {public <E> void Swap(E[] arrays,int i,int j) {E t = arrays[i];arrays[i] = arrays[j];arrays[j] = t;}
}public class Main {public static void main(String[] args) {Integer[] arrays = {1,2,4,3};Alg alg = new Alg();alg.Swap(arrays,2,3);System.out.println(Arrays.toString(arrays));}
}//运行结果
[1, 2, 3, 4]不使用类型推导:
import java.util.Arrays;class Alg {public <E> void Swap(E[] arrays,int i,int j) {E t = arrays[i];arrays[i] = arrays[j];arrays[j] = t;}
}public class Main {public static void main(String[] args) {Integer[] arrays = {1,2,4,3};Alg alg = new Alg();alg.<Integer>Swap(arrays,2,3);System.out.println(Arrays.toString(arrays));}
}//运行结果
[1, 2, 3, 4]到此,数据结构的预备知识已经完结!感谢您的阅读,如有错误还请指出!