【论文解读】MambaVision: A Hybrid Mamba-Transformer Vision Backbone
论文信息
题目:MambaVision: A Hybrid Mamba-Transformer Vision Backbone
会议:CVPR 2025、
单位:NVIDIA
链接:https://arxiv.org/pdf/2407.08083
代码:https://github.com/NVlabs/MambaVision
摘要
我们提出了一种全新的混合架构——MambaVision,它融合了 Mamba 与 Transformer,专为视觉任务量身打造。核心贡献在于重新设计了 Mamba 的公式,使其更高效地建模视觉特征。通过大量消融实验,我们验证了将 Vision Transformer(ViT)与 Mamba 整合的可行性,并发现仅在最后几层加入自注意力模块,就能显著提升 Mamba 架构捕获长距离空间依赖的能力。基于此,我们构建了一系列层级化的 MambaVision 模型,以满足不同设计需求。在 ImageNet-1K 分类任务上,MambaVision 各变体在 Top-1 准确率与吞吐量上均达到新的 SOTA(state-of-the-art)。在下游任务(如 MS COCO 上的目标检测、实例分割,以及 ADE20K 的语义分割)中,MambaVision 也超越了同等规模的现有骨干网络,展现出更优的综合性能。
Introduction
Transformer,好!但是复杂度O(N^2)
最近提出了一些基于 Mamba (SSM) 的视觉主干, 线性复杂度O(N)
但原生 Mamba 的自回归机制并不直接适用于视觉,为什么?两个原因
1、图像像素间并非顺序依赖,而是局部/全局空间关系
2、逐 token 的自回归处理难以一次捕获全局上下文,双向扫描又带来高延迟。
Ps:在图像里,像素(或 patch)之间没有天然的阅读顺序——左上角的像素与右下角的像素可能在语义上立即相关(例如同属于一架飞机),所以强制按某个单向顺序读取会“人为”地割裂空间联系,所以需要同时考虑局部邻域(纹理、边缘)和远距离区域(物体整体结构)才符合视觉任务的先验。
另外,逐个 token 的递归展开:每一步只能基于已生成的信息,必须走完整个序列才能看到完整图像,导致一次前向传播无法直接利用全局信息。若想补救,可采用“双向扫描”(先左→右再右→左,或四方向扫描),但这相当于把同一张图片反复送入网络,计算量增加数倍,延迟大幅上升,失去了 Mamba 线性复杂度带来的效率优势。
本文贡献:
- 重新设计 Mamba 公式:提出“MambaVision Mixer”,用非因果卷积替代因果卷积,并增加对称无-SSM 分支,兼顾局部与全局信息,显著提升视觉建模能力。
- 系统研究 Mamba 与 Transformer 的混合策略,发现仅在最后若干层引入自注意力块即可最有效地恢复全局上下文、捕获长距离依赖,同时保持高吞吐。
- 构建层级化混合架构 MambaVision:高分辨率阶段用 CNN 残差块快速提特征;低分辨率阶段交替堆叠 MambaVision Mixer 与 Transformer 块。
Related Work
里面关于Mamba的部分介绍了一些基于Mamba的视觉主干,感兴趣可以看一下。
Methodology
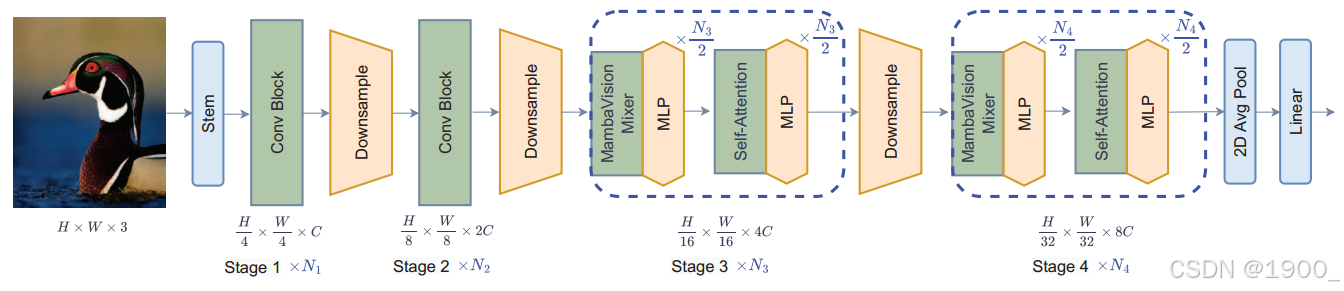
这个图就很清晰了,一共分为4个阶段
设计思路是:
高分辨率阶段:用 CNN 残差块做“粗而快”的特征提取,减少显存占用。
低分辨率阶段:插入作者重新设计的 MambaVision Mixer + Transformer 自注意力,兼顾长程依赖和全局上下文。
前面两个阶段是卷积CNN,就是3x3的卷积,从224–>56–>28
阶段3和阶段4:28–>14–>7
每个 Stage 有 N 层,其中前 N/2 层是 MambaVision Mixer + MLP,后 N/2 层是多头自注意力+MLP
MambaVision Mixer
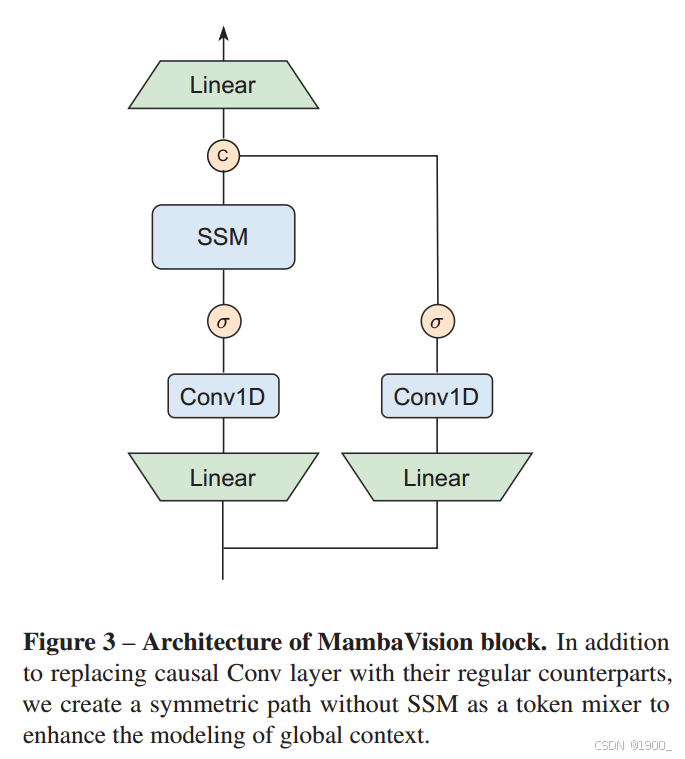
首先,我们提议用常规卷积替换因果卷积,因为它将影响限制在一个方向,这对于视觉任务来说既不必要也不灵活。此外,我们添加了一个没有SSM的对称分支,由额外的卷积和SiLU激活组成,以补偿由于SSM的序列约束而可能损失的任何内容。
给定输入XinX_{in}Xin,输出用如下公式表示:

Mamba 原论文里的 Selective Scan
σ\sigmaσ是SiLU激活函数
伪代码如下:

然后自注意力部分用的就是一个通用的多头自注意力机制,支持窗口化(window size 14 或 7)进一步减少计算
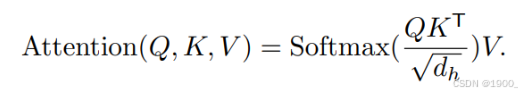
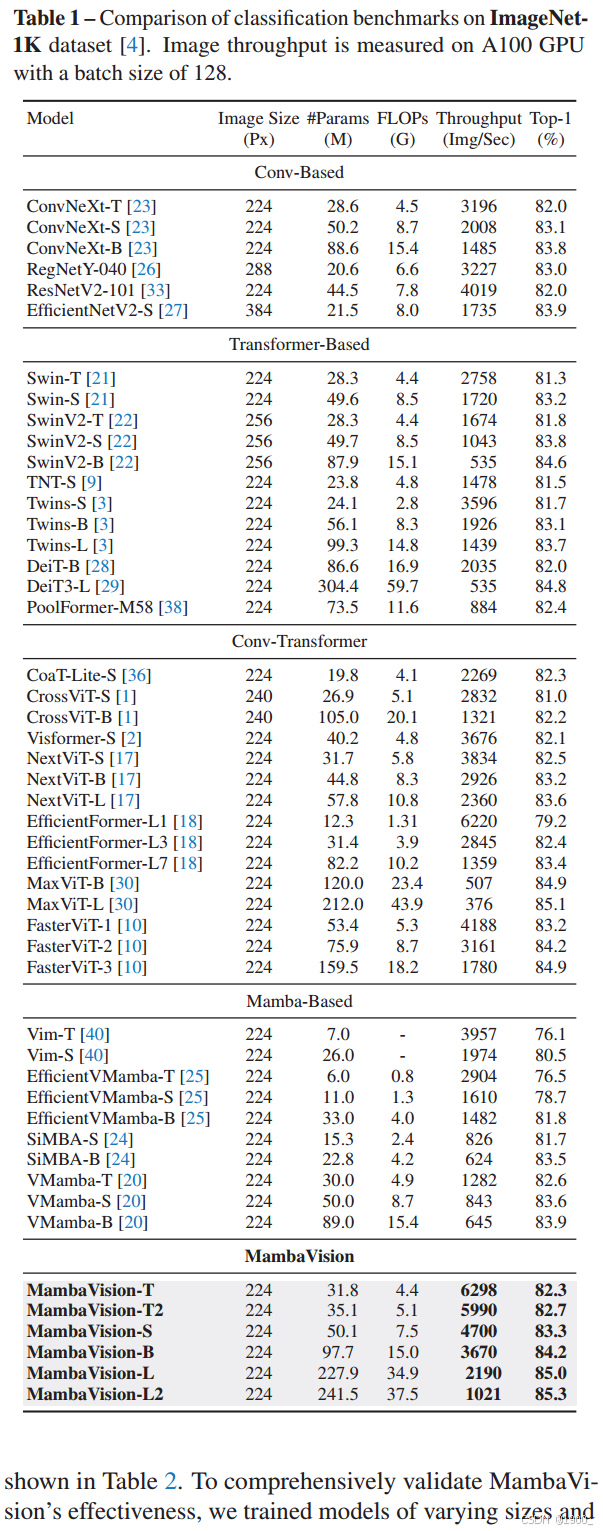
实验
图像分类
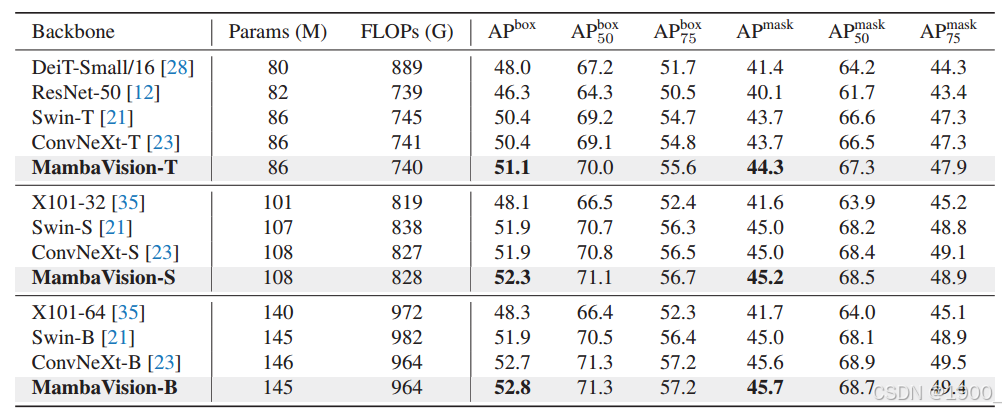
目标检测和分割 MS COCO数据集
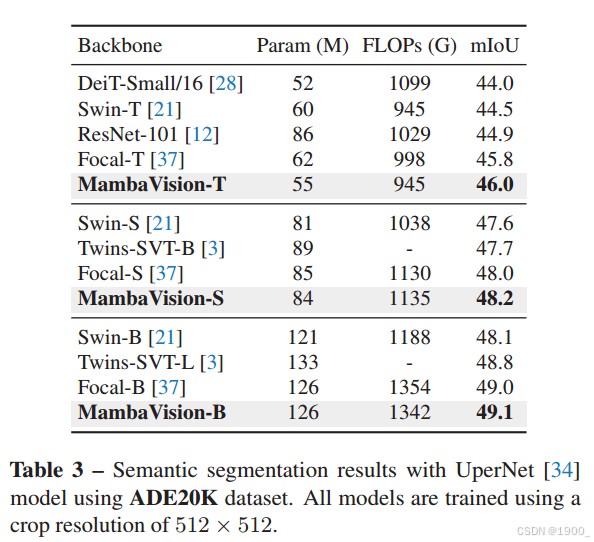
ADE20K数据集
总结
整个设计是非常简单的,但是看起来是很有效的。
后面试着用一下,看看其他任务上效果如何。