RAG架构原理和LangChain方式实现RAG
文章目录
- 参考文档
- 一 RAG
- 二 LangChain方式实现RAG
- 2.1 环境准备
- 2.2 整体思路
- 2.3 代码实践
- 2.3.1 milvus
- 2.3.2 详细步骤和完整代码
参考文档
- Agentic RAG 架构的基本原理与应用入门
一 RAG
- Retrieval-Augmented Generation (RAG\检索增强生成) 是帮助大模型更好地回答问题的一种方式。RAG旨在为大模型灵活的提供外部知识库支持,以拓展大模型知识边界。
- RAG(检索增强生成)技术就能派上用场。它的作用就是从这些文档中找到最相关的信息,然后利用大模型生成精准的回答。简单来说,RAG 就是帮助大模型‘找到’并‘利用’最相关的信息来回答你的问题,就像一个聪明的助手快速翻阅资料给你最合适的答案。
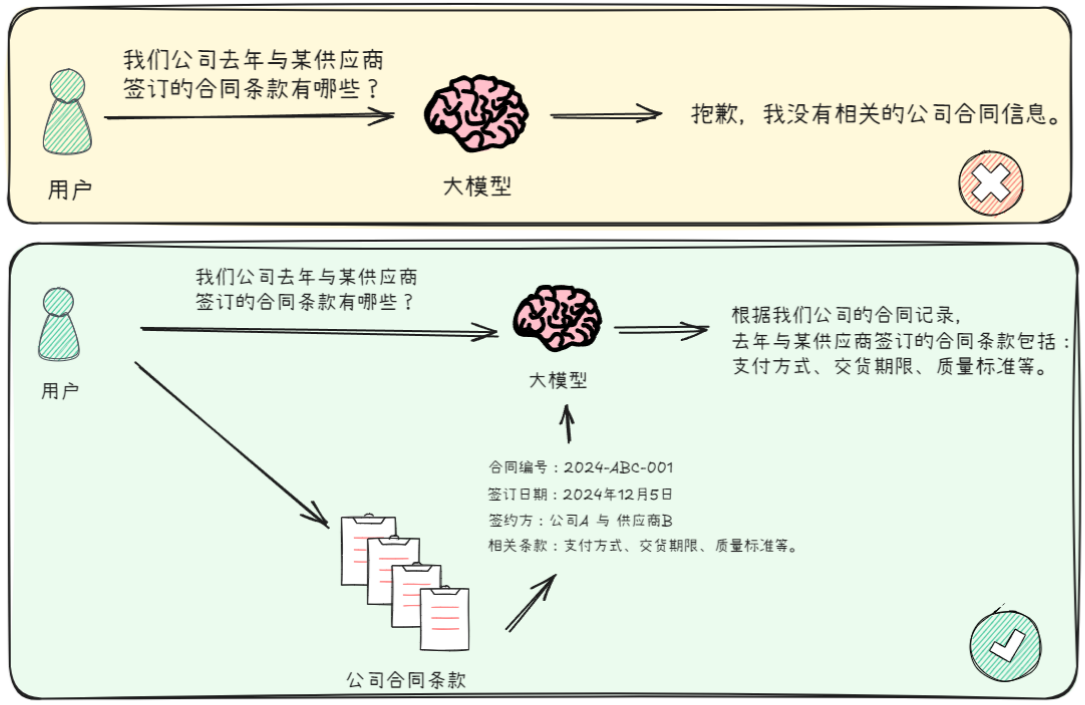
- RAG能够实现的原因是实验论文证明,当为大模型提供一定的上下文信息后,其输出会变得更稳定。传统RAG的方法是将知识库中的信息或掌握的信息先输送给大模型,再由大模型服务用户。
- 传统的对话系统、搜索引擎等核心依赖于检索技术,如果将这一检索过程融入大模型应用的构建中,既可以充分利用大模型在内容生成上的能力,也能通过引入的上下文信息显著约束大模型的输出范围和结果,同时还实现了将私有数据融入大模型中的目的,达到了双赢的效果。
- 从技术实现细节上,RAG的实现是包括两个阶段的:检索阶段和生成阶段。在检索阶段,从知识库中找出与问题最相关的知识,为后续的答案生成提供素材。在生成阶段,RAG会将检索到的知识内容作为输入,与问题一起输入到语言模型中进行生成。
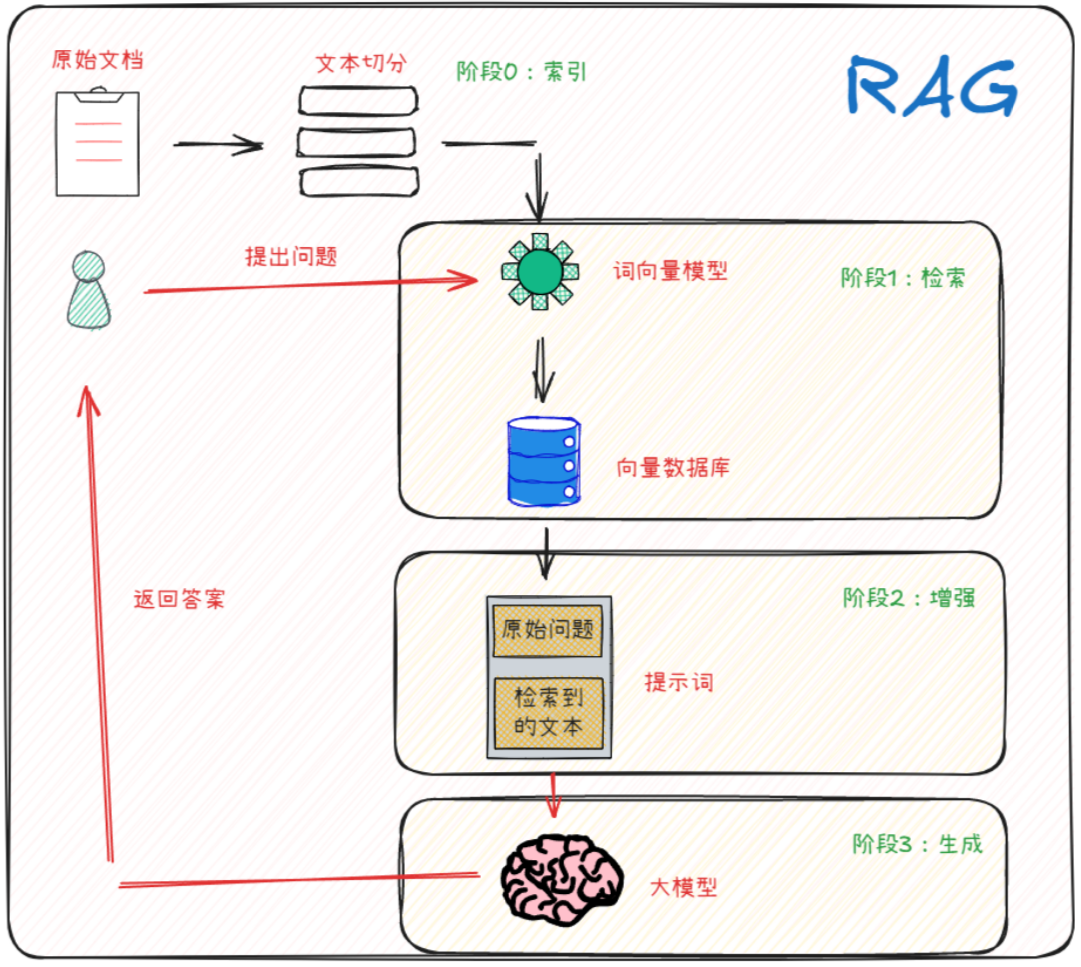
- 将外部文本相关信息作为Prompt的一部分输入给大模型的原因:
- 如果用户提出的问题,其对应的答案出现在一篇文章中,但是将检索到的这整篇文章直接放入Prompt中并不是最优的选择,因为其中包含非常多无关的信息,而无效信息越多,对大模型后续的推理影响越大。
- 任何一个大模型都存在最大输入的Token限制,如果将一整个文本去全部传入大模型,无法容纳如此多的信息。
- RAG构建的关键,则是由检索组件(通常由Embedding模型和向量数据库组成)和生成组件( 大模型 )组成。在推理时,用户查询用于对索引文档运行相似性搜索,以检索与查询最相似的文档,并为大模型提供额外的上下文。
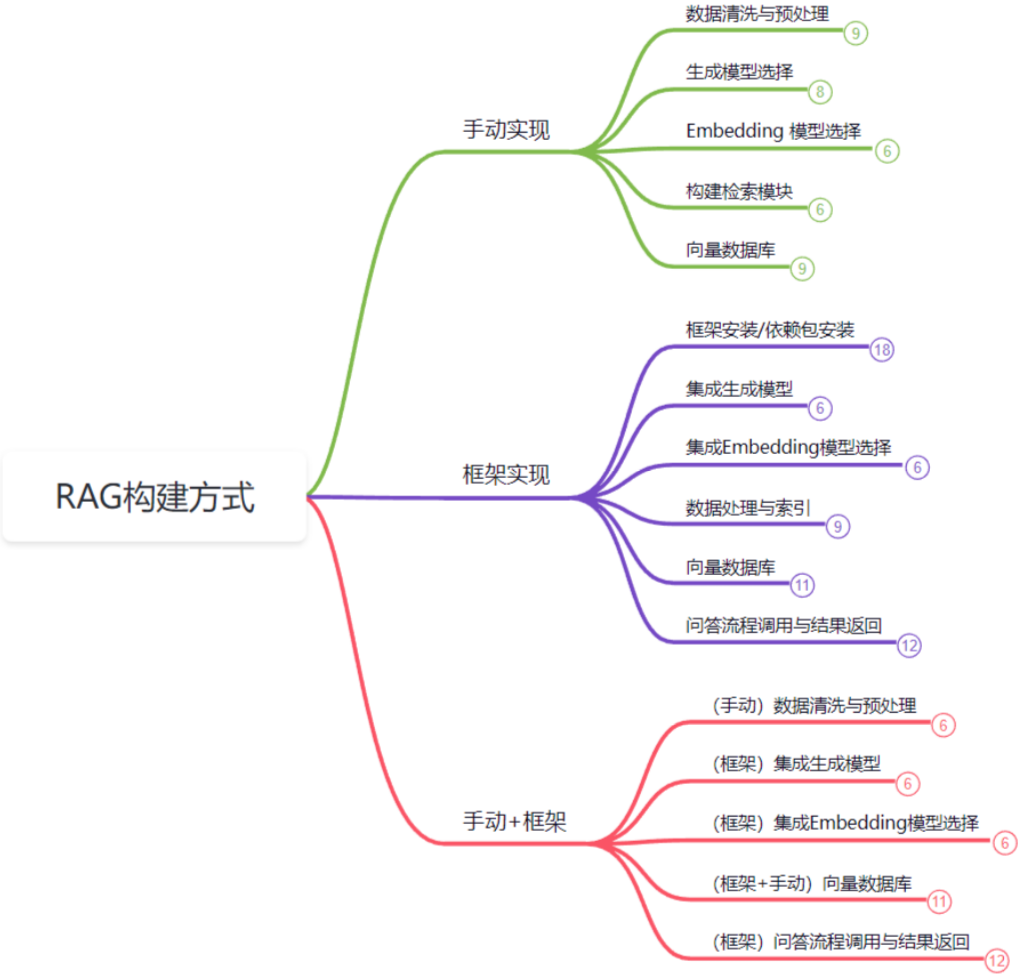
- 实现RAG系统主要有三种方式:手动实现、框架实现和手动+框架结合的方式。通常,90%以上开发者会选择灵活性和高效的手动+框架结合的方式。
二 LangChain方式实现RAG
2.1 环境准备
- OpenAI中转 API Key
- Python环境
- 正常网络环境
- LangChain框架
- milvus
2.2 整体思路
- 简易RAG实现思路。
2.3 代码实践
- 安装langchain框架
pip install langchain langchain_community PyPDF2 langchain_milvus langgraph
2.3.1 milvus
- 打开milvus,正常注册登录,创建向量库。
- 详细操作文档参看2.3 存入向量数据库小节
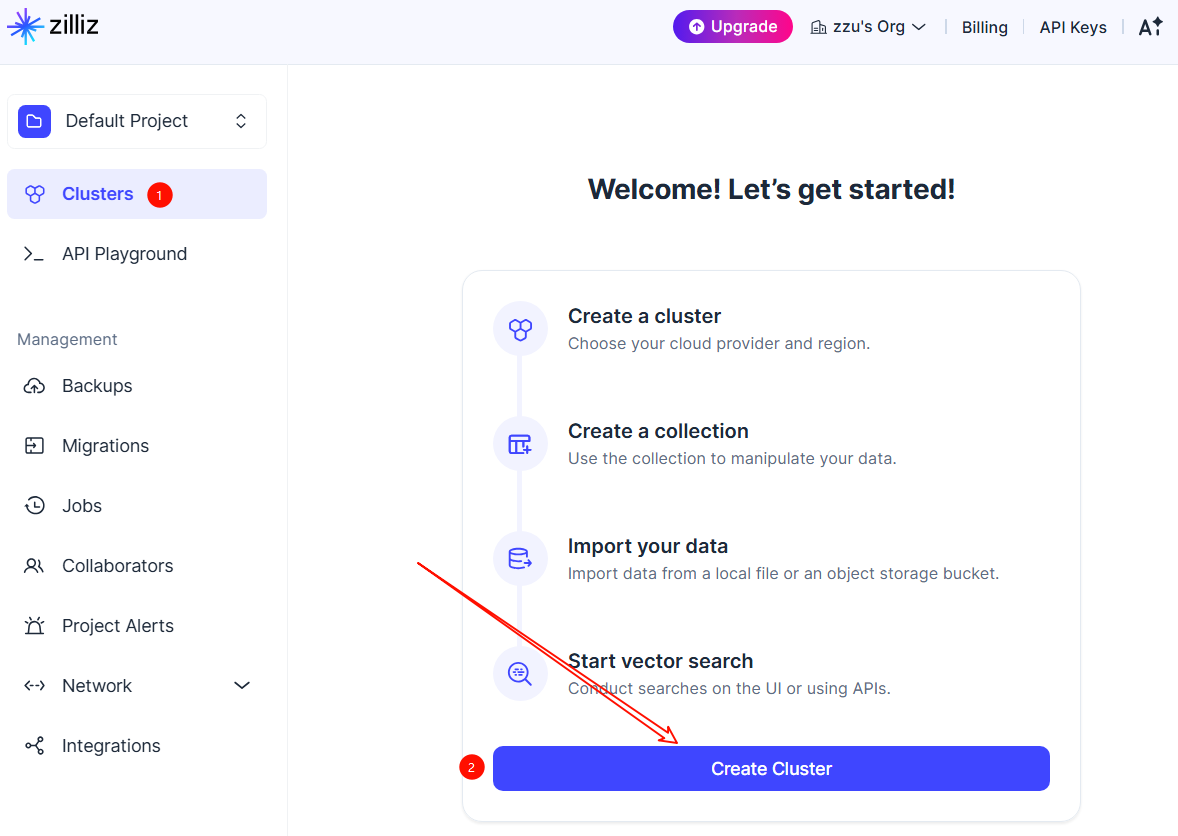
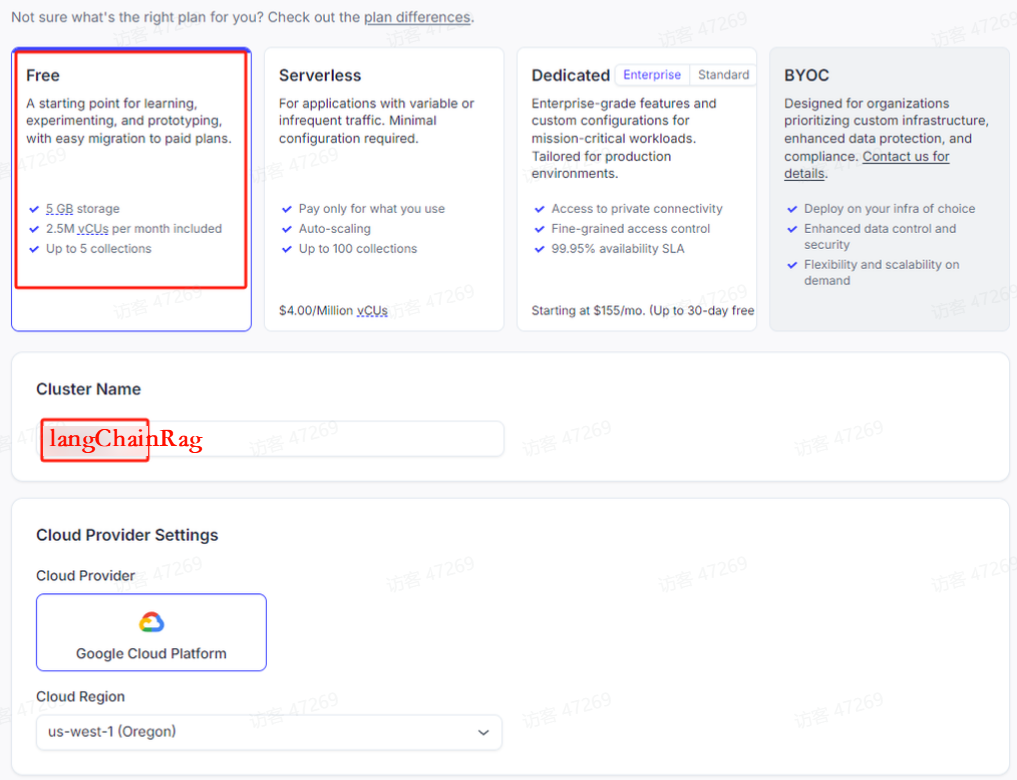
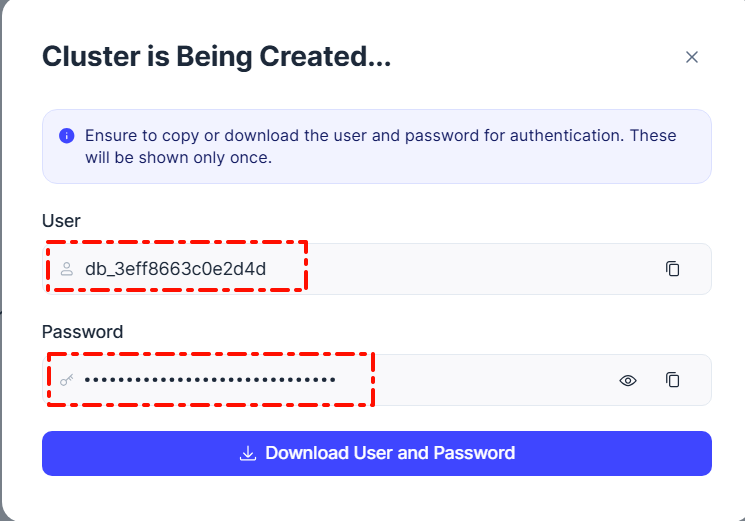
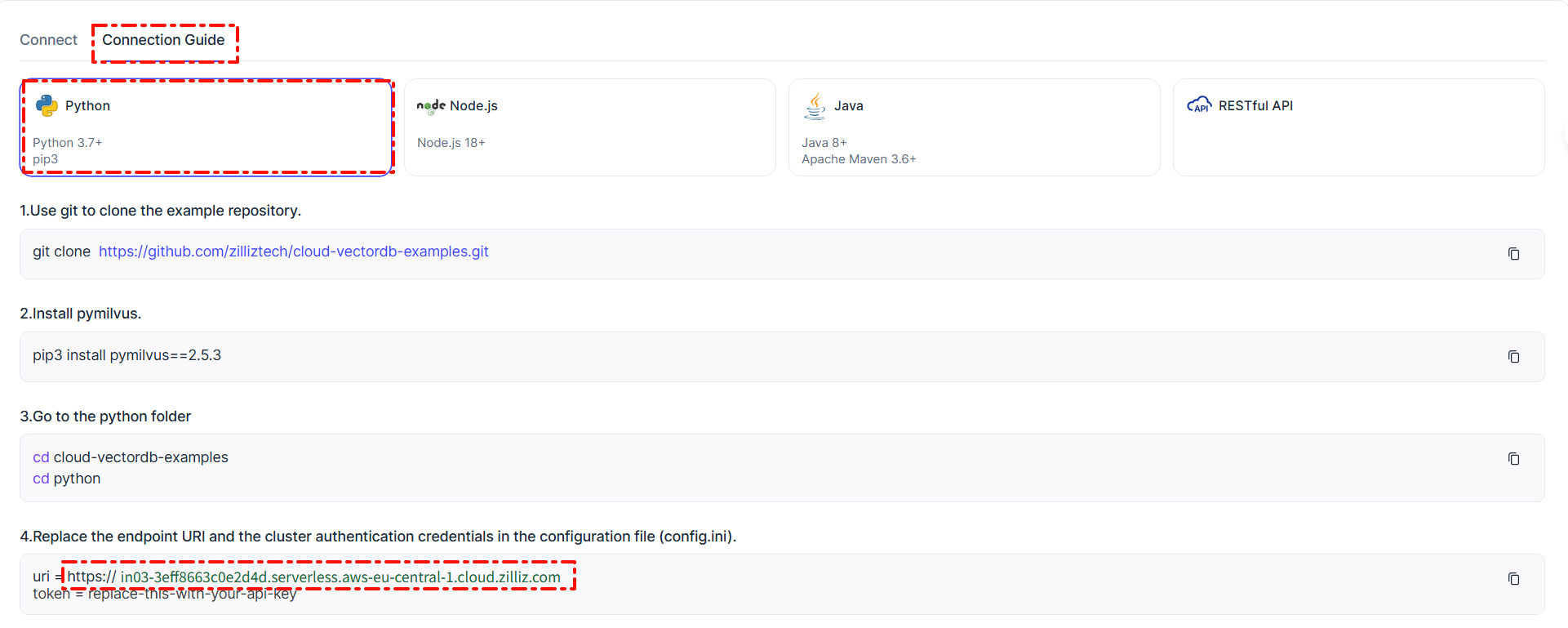
- 注意复制连接用户名称、密钥、网址、向量库名称。例如。上图中的重要信息如下:
向量库名称:langChainRag
网址:https://in03-3eff8663c0e2d4d.serverless.aws-eu-central-1.cloud.zilliz.com
用户名称:xxx
密钥:xxx
2.3.2 详细步骤和完整代码
- 在构建 RAG系统的过程中,第一步是从文档中提取有用的信息。通过使用 PyPDF2 库的 PdfReader 类来实现从 PDF 文件中提取文本。
- 加载Embedding模型,对文本进行切分和向量化。
- 使用向量化数据库存储向量化后的切分文本。
- 构建Prompt和接入大语言模型,完成完整的问答流程。
from PyPDF2 import PdfReader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitterdef pdf_read(pdf_doc):text = ""for pdf in pdf_doc:pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return text
# 返回值content将包含该 PDF 文件的所有文本内容。
content = pdf_read(['./data/凡人修仙传第一章.pdf'])
# Document 对象,其属性 page_content 被设置为之前从 PDF 文件中提取的文本 content。
documents = [Document(page_content=content)]chunk_size = 600
chunk_overlap = 200
# 使用 LangChain 的 RecursiveCharacterTextSplitter根据指定的块大小和重叠部分将文档文本分割成多个较小的部分,完成文本切分。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap
)# 切分
splits = text_splitter.split_documents(documents)
# print(splits)from langchain_openai import OpenAIEmbeddings
import os
os.environ["USER_AGENT"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
API_KEY = "hk-xxx";
BASE_URL = "https://api.openai-hk.com/v1";
os.environ["OPENAI_API_KEY"] = API_KEY
os.environ["OPENAI_API_BASE"] = BASE_URLembeddings = OpenAIEmbeddings(model="text-embedding-3-small",
)text = "第一章山边小村 \n 二愣子睁大着双眼,直直望着茅草和烂泥糊成的黑屋顶,身上盖着的旧棉被,已呈深黄色。"single_vector = embeddings.embed_query(text)
# print(str(single_vector)) # 显示前词向量的表示 1536维度from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_milvus import Milvus# 添加到向量数据中
vectorstore = Milvus.from_documents(documents=splits,collection_name="langChainRag",embedding=embeddings,connection_args={"uri": "https://xxx.serverless.aws-eu-central-1.cloud.zilliz.com","user": "db_xxx","password": "xxx",}
)# 接入LLM测试
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessagefrom langchain.prompts import PromptTemplate
from langchain import hub
from langchain_core.output_parsers import StrOutputParsermodel = ChatOpenAI(model="gpt-4o-mini")# 提示词模板
prompt = PromptTemplate(template="""你是一个智能问答助手. 使用以下检索到的上下文片段来回答问题。 如果你不知道答案,直接说不知道即可。最多用三句话,回答要简明扼要:问题: {question} 内容: {context} 回答: """,input_variables=["question", "documents"],
)# 构建传统的RAG Chain
rag_chain = prompt | model | StrOutputParser()
# 问题
question = "韩立是的名字是谁起的?"
# 构建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})# 执行检索
docs = retriever.invoke("question")
print(docs)
- 运行结果:
韩立的名字是他的父亲求村里老张叔给起的。老张叔是村里唯一的读书人,曾经认识几个字。韩立被朋友们称为“二愣子”,但这只是个绰号。