最近邻规则分类KNN,原理,k值选择优化,kd树优化,以及iris数据集分类
最近邻规则分类KNN
算法介绍
KNN是一种近朱者赤近墨者黑的监督学习分类算法,是基于实例的学习,属于懒惰学习(没有显式学习过程;在训练阶段不做或做很少的模型构建工作,而是在预测阶段才进行大量计算)
- 为了判断未知实例的类别,以所有已知类别的实例作为参照选择参数K
- 计算未知实例与所有已知实例的距离
- 选择最近K个已知实例
- 根据少数服从多数的投票法则,让未知实例归类为K个最邻近样本中最多数的类别
距离度量
闵可夫斯基距离
有两个k维向量a⃗=(x11,x12,…,x1k),b⃗=(x21,x22,…,x2k)两个向量之间的闵可夫斯基距离为d(x,y)=(∑i=1k∣x1i−x2i∣p)1/p 有两个k维向量\vec{a}=(x_{11},x_{12},\dots,x_{1k}),\vec{b}=(x_{21},x_{22},\dots,x_{2k}) \\ 两个向量之间的闵可夫斯基距离为\\ d(x,y)=(\sum_{i=1}^{k}|x_{1i}-x_{2i}|^p)^{1/p} 有两个k维向量a=(x11,x12,…,x1k),b=(x21,x22,…,x2k)两个向量之间的闵可夫斯基距离为d(x,y)=(i=1∑k∣x1i−x2i∣p)1/p
曼哈顿距离
各个维度差值的绝对值的和
闵可夫斯基距离中p=1d(x,y)=∑i=1k∣x1i−x2i∣
闵可夫斯基距离中p=1\\
d(x,y) =\sum_{i=1}^{k}|x_{1i}-x_{2i}|
闵可夫斯基距离中p=1d(x,y)=i=1∑k∣x1i−x2i∣
欧几里得距离
接触最多的距离公式
闵可夫斯基距离中p=2d(x,y)=∑i=1k(x1i−x2i)2
闵可夫斯基距离中p=2\\
d(x,y)=\sqrt{\sum_{i=1}^{k}(x_{1i}-x_{2i}})^2
闵可夫斯基距离中p=2d(x,y)=i=1∑k(x1i−x2i)2
切比雪夫距离
各个维度差值的最大值
闵可夫斯基距离中p−>∞d(x,y)=maxi(∣x1i−x2i∣)
闵可夫斯基距离中p->∞ \\
d(x,y) = \max\limits_{i}(|x_{1i}-x_{2i}|)
闵可夫斯基距离中p−>∞d(x,y)=imax(∣x1i−x2i∣)
K值
K通常是奇数
为什么?若K是偶数,那么可能出现每类的数量均等这样一个平局的场面,就不好选择到底把未知实例归属到哪一类
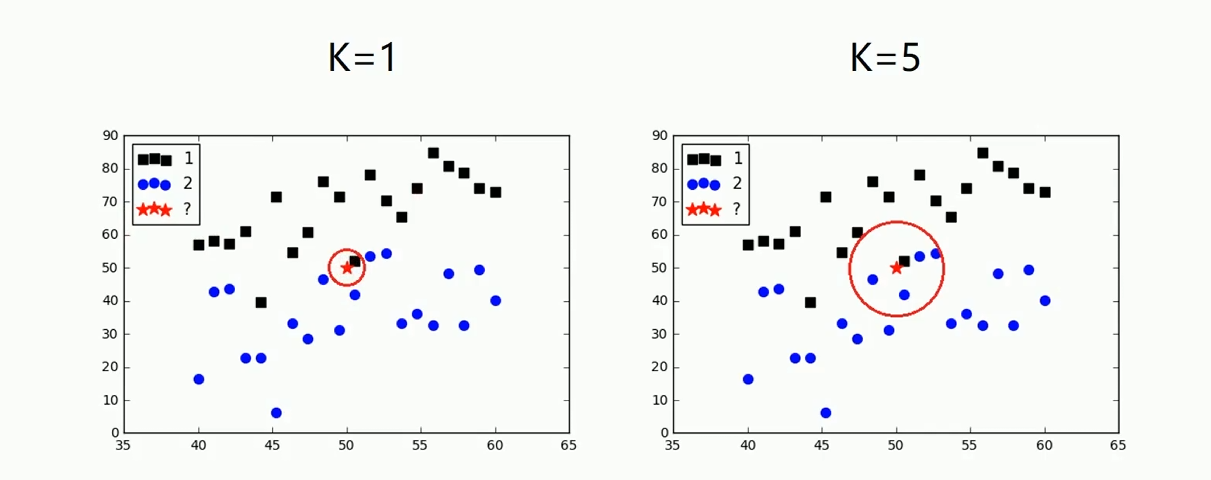
由图中我们可以发现:不同的K值对未知实例的归属有影响;K=1时,与未知实例最近的1个点中有1个第一类,0个第二类,此时未知实例归属第一类;而K=5时,与未知实例最近的5个点中有1个第一类,4个第二类,此时未知实例归属第二类
- k太大:会把很远的邻居考虑进去,分类就不准确了(欠拟合)
- k太小:泛化能力差,对于复杂一些的模型,只要改变一点点结果就会变化很大
算法缺点
-
复杂度高:要计算比较未知实例与所有已知实例之间的距离
-
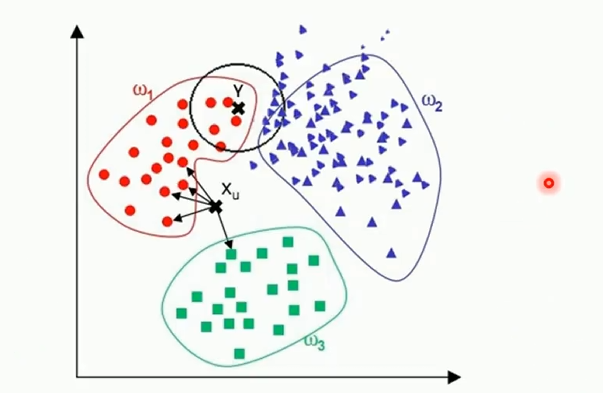
样本分布不均衡时(比如有一类样本特别大而且密度大,占主导),新的未知实例容易被归类到这个主导样本中;但实际上未知样本并没有接近目标样本(比如图中的Y,看图其实应该是属于ω1,但是在KNN算法中被分类到了ω2)
-
预测阶段很慢(懒惰学习,预测时才进行大量计算)
-
对不相关的功能和数据规模敏感(KNN基于距离进行计算,如果特征中向量中有很多不相关的特征,就相当于引入干扰,导致模型性能下降)
代码实现
例子
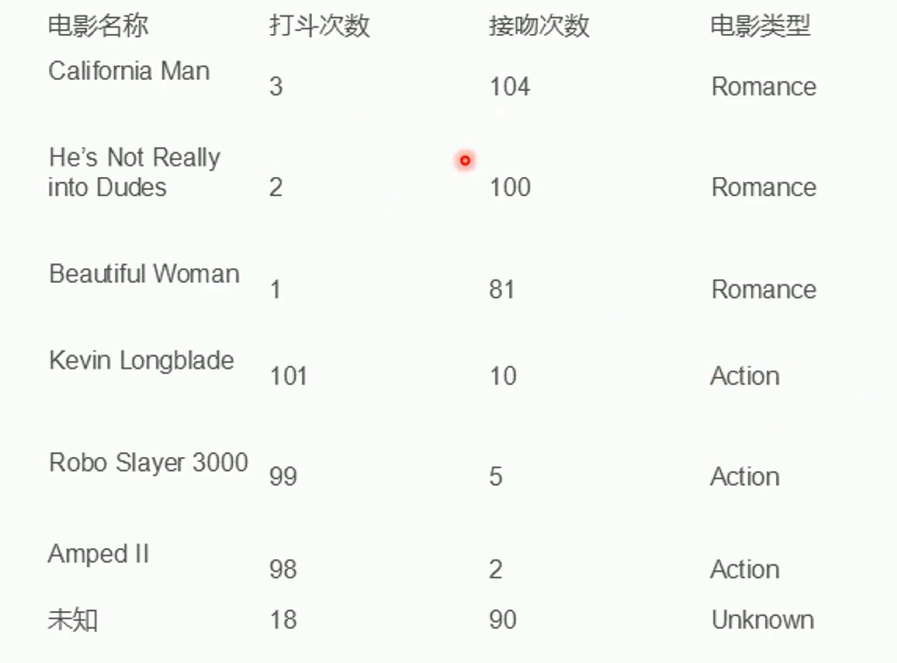
绘图
数据定义
# 爱情片
x1 = np.array([3, 2, 1])
y1 = np.array([104, 100, 81])
# 动作片
x2 = np.array([101, 99, 98])
y2 = np.array([10, 5, 2])
# 未知实例
unknown_x = np.array([18])
unknown_y = np.array([90])
绘图的点集
sct1 = plt.scatter(x1, y1)
sct2 = plt.scatter(x2, y2)
sct3 = plt.scatter(unknown_x, unknown_y)
绘图
plt.legend(handles=[sct1, sct2, sct3], # 自定义图例中想出现的绘图对象labels=['爱情片', '动作片', '未知实例'], # 绘图对象的标签loc='best' # 自动选择最佳位置
)plt.show()
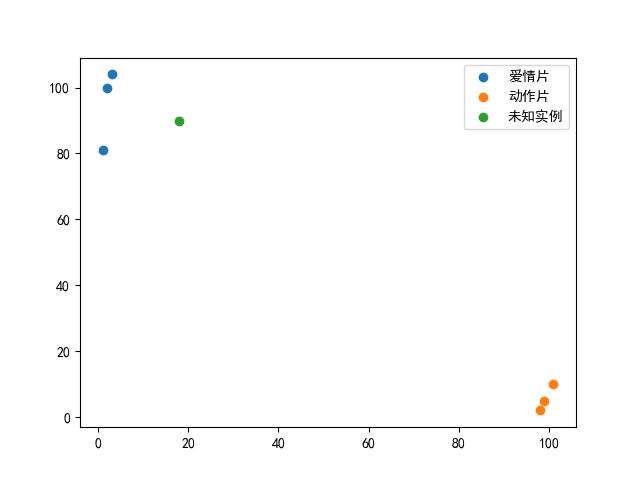
绘图结果
算法实现
数据定义
# 已知实例
X = np.array([[3, 104],[2, 100],[1, 81],[101, 10],[99, 5],[98, 2]
])# 已知实例的标签
Y = np.array(['A', 'A', 'A', 'B', 'B', 'B'])# 未知实例
unknown_x = np.array([18, 90])sample_size = X.shape[0]# 参数k
k = 3
计算点与点的差
方法1:显式转化未知实例矩阵的形状
# 手动将未知实例复制成与已知实例相同的形状,等价于广播
unknown_x_ext = np.tile(unknown_x, # 要复制的向量(sample_size, 1) # 行复制6次,列复制1次
)diff2 = unknown_x_ext - X
diff2:[[ 15 -14][ 16 -10][ 17 9][-83 80][-81 85][-80 88]]
方法2:直接利用numpy广播机制隐式转换
diff1 = unknown_x - X
diff1:[[ 15 -14][ 16 -10][ 17 9][-83 80][-81 85][-80 88]]
计算距离
# 点与点的差
diff = unknown_x - X
# 点与点差的平方和
diffsum = np.sum(diff ** 2, axis=1)
# 欧式距离
dis = np.sqrt(diffsum)
dis:[ 20.51828453 18.86796226 19.23538406 115.27792503 117.41379817118.92854998]
对距离进行排序
# argsort()是获取排序后在原列表中的索引
min_dis_index = dis.argsort()
获取到距离从小到大的索引:
[1 2 0 3 4 5]
对最近邻k个实例进行统计
# 定义一个字典(类似与Java的Map<K,V>)存储最近k个实例中标签(K)与出现次数(V);字典可以直接用索引形式获取K对应的V map['K'] -> V
map = {}
for i in range(k):nearest_label = Y[min_dis_index[i]]# 更新KV对,.get(K,0)表示如果K对应的V不存在,就创建K对应的V=0map[nearest_label] = map.get(nearest_label, 0) + 1
map:{'A': 3}
根据键值对的值进行排序
# 根据KV对的V进行排序
sortedMap = sorted(map.items(), # 以视图形式返回map,列表中是键值对的元组形式key=operator.itemgetter(1), # 根据每个元组的第2个元素进行排序(即键值对的值,索引从0开始)reverse=True #逆置后从大到小
)
map:{'A': 3}
map.items():dict_items([('A', 3)])
sortedMap:[('A', 3)]
获取最终分类的标签
# sortedMap[0][0]获取第1个元组的第1个元素(即键)
print(f"ultimate_label:{sortedMap[0][0]}")
ultimate_label:A
换一组数据,k改为5
X = np.array([# 动作片(高打架,低接吻)[95, 3], [98, 2], [100, 5], [102, 4], [105, 1],[90, 6], [92, 4], [97, 3], [103, 2], [99, 1],[88, 5], [94, 2], [101, 3], [96, 4], [104, 0],# 爱情片(低打架,高接吻)[5, 95], [3, 98], [1, 100], [4, 102], [2, 105],[6, 90], [4, 92], [3, 97], [2, 103], [1, 99],[5, 88], [2, 94], [3, 101], [4, 96], [0, 104],# 边界点(可能被误分类)[50, 50], # 中等打架和接吻[60, 40], # 偏动作[40, 60], # 偏爱情[80, 20], # 较明显动作片[20, 80], # 较明显爱情片
])# 已知实例的标签
Y = getY(X)# 未知实例
unknown_x = np.array([[50, 60]])# 绘制图像
scatter_show(X, unknown_x)sample_size = X.shape[0]
# 参数k
k = 5
def getY(X):Y = []for i in range(X.shape[0]):if X[i, 0] < X[i, 1]:Y.append('A')else:Y.append('B')return Ydef scatter_show(X, unknown):x1 = []y1 = []x2 = []y2 = []unknown_x = [unknown[0, 0]]unknown_y = [unknown[0, 1]]for i in range(X.shape[0]):if X[i, 0] < X[i, 1]:x1.append(X[i, 0])y1.append(X[i, 1])else:x2.append(X[i, 0])y2.append(X[i, 1])sct1 = plt.scatter(x1, y1, marker='o')sct2 = plt.scatter(x2, y2, marker='s')sct3 = plt.scatter(unknown_x, unknown_y, marker='^')plt.legend(handles=[sct1, sct2, sct3], labels=['A-label', 'B-label', 'unknown-label'], loc='best')plt.show()
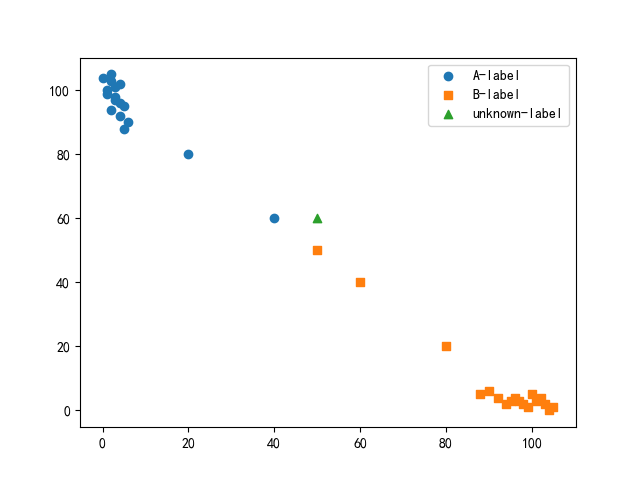
分类结果:未知实例属于B类
map:{'A': 2, 'B': 3}
map.items():dict_items([('A', 2), ('B', 3)])
sortedMap:[('B', 3), ('A', 2)]
ultimate_label:B
Iris数据集分类

使用到的数据集
from sklearn import datasets
iris_data = datasets.load_iris()
.load_iris()返回一个bunch对象,类似于字典

里面比较重要的属性
data:存放样本数据
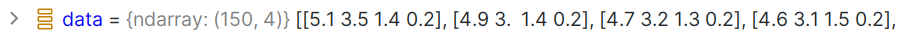
target:3个类别

target_names:类别对应的名字

分割数据集
方法1:直接使用sklearn自带的train_test_spilit
from sklearn import datasets
from sklearn.model_selection import train_test_splitiris_data = datasets.load_iris()x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2)
方法2:自己实现从打乱数据到分割数据集
def train_test_split(x, y, test_size=0.2):# 样本尺寸size = x.shape[0]train_size = 1.0 - test_size# 训练集与测试集的实际尺寸train_set_size = np.floor(size * train_size).astype(int)test_set_size = np.floor(size * train_set_size).astype(int)# 索引列表index = [i for i in range(size)]# 打乱索引列表random.shuffle(index)# 同时打乱特征与标签x = x[index]y = y[index]# 划分测试集(最后test_set_size个)与训练集(前train_set_size个)x_train = x[train_set_size:]x_test = x[:test_set_size]y_train = y[train_set_size:]y_test = y[:test_set_size]return x_train, x_test, y_train, y_test
KNN代码
自己实现
与前面演示算法实现不同的是,这里未知实例是很多组,需要用循环进行逐组分类
def KNN(unknown, X, y, k=5):diff = X - unknown# 点差平方diffpow2 = diff ** 2# 行内部求和(特征与特征之间)dist = np.sqrt(np.sum(diffpow2, axis=1))# 最小距离索引min_dist_idx = np.argsort(dist)# 字典map = {}for i in range(k):nearest = y[min_dist_idx[i]]map[nearest] = map.get(nearest, 0) + 1# 根据点数量排序sorted_map = sorted(map.items(),key=operator.itemgetter(1),reverse=True)# 返回类别代码return sorted_map[0][0]
y_test_classified = []
for i in range(x_test.shape[0]):label = KNN(x_test[i], X, y)y_test_classified.append(label)
评估分类结果
# from sklearn.metrics import classification_report
print(classification_report(y_test, y_test_classified))
precision recall f1-score support0 1.00 1.00 1.00 501 1.00 1.00 1.00 502 1.00 1.00 1.00 50accuracy 1.00 150macro avg 1.00 1.00 1.00 150
weighted avg 1.00 1.00 1.00 150进程已结束,退出代码为 0
整体代码
import operator
import randomfrom sklearn import datasetsimport numpy as np
from sklearn.metrics import classification_reportiris_data = datasets.load_iris()def train_test_split(x, y, test_size=0.2):# 样本尺寸size = x.shape[0]train_size = 1.0 - test_size# 训练集与测试集的实际尺寸train_set_size = np.floor(size * train_size).astype(int)test_set_size = np.floor(size * train_set_size).astype(int)# 索引列表index = [i for i in range(size)]# 打乱索引列表random.shuffle(index)# 同时打乱特征与标签x = x[index]y = y[index]# 划分测试集与训练集x_train = x[train_set_size:]x_test = x[:test_set_size]y_train = y[train_set_size:]y_test = y[:test_set_size]return x_train, x_test, y_train, y_testdef KNN(unknown, X, y, k=5):diff = X - unknown# 点差平方diffpow2 = diff ** 2# 行内部求和(特征与特征之间)dist = np.sqrt(np.sum(diffpow2, axis=1))# 最小距离索引min_dist_idx = np.argsort(dist)# 字典map = {}for i in range(k):nearest = y[min_dist_idx[i]]map[nearest] = map.get(nearest, 0) + 1# 根据点数量排序sorted_map = sorted(map.items(),key=operator.itemgetter(1),reverse=True)# 返回类别代码return sorted_map[0][0]X = iris_data.data
y = iris_data.target
x_train, x_test, y_train, y_test = train_test_split(X, y)
y_test_classified = []
for i in range(x_test.shape[0]):label = KNN(x_test[i], X, y)y_test_classified.append(label)print(classification_report(y_test, y_test_classified))
使用sklearn的KNeighborsClassifier实现
import numpy as np
import random
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
# 使用 z1-归一化
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, accuracy_scoredef load_data():iris_data = load_iris()return iris_data.data, iris_data.targetdef train_test_split(x, y, test_size=0.2):# 样本尺寸size = x.shape[0]train_size = 1.0 - test_size# 训练集与测试集的实际尺寸train_set_size = np.floor(size * train_size).astype(int)test_set_size = np.floor(size * train_set_size).astype(int)# 索引列表index = [i for i in range(size)]# 打乱索引列表random.shuffle(index)# 同时打乱特征与标签x = x[index]y = y[index]# 划分测试集(最后test_set_size个)与训练集(前train_set_size个)x_train = x[train_set_size:]x_test = x[:test_set_size]y_train = y[train_set_size:]y_test = y[:test_set_size]return x_train, x_test, y_train, y_testif __name__ == '__main__':X, y = load_data()x_train, x_test, y_train, y_test = train_test_split(X, y)# 进行z1归一化scaler = StandardScaler()x_train = scaler.fit_transform(x_train)# 测试集不能参与拟合x_test = scaler.transform(x_test)# n_neighbors就是kknn = KNeighborsClassifier(n_neighbors=5)# 拟合knn.fit(x_train, y_train)# 获得knn的分类结果y_pred = knn.predict(x_test)print(f"准确率:{accuracy_score(y_test, y_pred)}")
z1归一化
xi=xi−μσμ:均值σ:标准差 x_i = \frac{x_i-\mu}{\sigma} \\ \mu:均值\\ \sigma:标准差\\ xi=σxi−μμ:均值σ:标准差
K值选择
K折交叉验证
将原始数据集均分成K个子集,称为折(Fold),然后模型在K个不同的训练集上进行K次训练和验证;每次训练中,其中一个折被划分为验证集,剩下K-1个折为训练集;这样就产生了K个模型和K个验证分数
通常使用5/10折
为什么?
被认为是 在偏差(bias)和方差(variance)之间取得良好平衡的选择
与其他k对比:
- Loo(留一法):n个样本,每次只留一个验证集,那么进行n次验证,每次只有一个样本作为验证集;泛化能力最强的同时计算开销最大
优点
- 防止过拟合,每个样本都会被验证
- 提高模型泛化能力
缺点
- 计算成本比较大
- 最终验证的分数与验证集和测试集划分有关系,可能出现分数不稳定的情况
GridSearchCV网格搜索
sklearn中一个强大的超参数调优工具
核心功能:
- 自动尝试一组超参数的组合;
- 对每组参数使用交叉验证(如 K 折交叉验证)评估模型性能;
- 找出在验证集上表现最好的参数组合;
- 最终使用最优参数在整个训练集上重新训练模型。
对前面的iris数据集分类案例进行优化
使用cross_val_score实现k折交叉验证
def select_k(X, y):k_list = np.arange(1, 22, 2) # k值列表res_map = {} # 存储k-score的字典for k in k_list:scores = cross_val_score(KNeighborsClassifier(n_neighbors=k), # 模型实例X,y,cv=5, # 折数scoring="accuracy" # 分数标准)# 得到每组的平均分数score = np.mean(scores)# 键值对赋值res_map[k] = res_map.get(k, score)# 排序res_map = sorted(res_map.items(),key=operator.itemgetter(1),reverse=True)# 返回准确率最高的kreturn res_map[0][0]
整体代码
import operatorimport numpy as np
import random
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
# 使用 z1-归一化
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, accuracy_score
# 交叉验证
from sklearn.model_selection import cross_val_scoredef load_data():iris_data = load_iris()return iris_data.data, iris_data.targetdef train_test_split(x, y, test_size=0.2):# 样本尺寸size = x.shape[0]train_size = 1.0 - test_size# 训练集与测试集的实际尺寸train_set_size = np.floor(size * train_size).astype(int)test_set_size = np.floor(size * train_set_size).astype(int)# 索引列表index = [i for i in range(size)]# 打乱索引列表random.shuffle(index)# 同时打乱特征与标签x = x[index]y = y[index]# 划分测试集(最后test_set_size个)与训练集(前train_set_size个)x_train = x[train_set_size:]x_test = x[:test_set_size]y_train = y[train_set_size:]y_test = y[:test_set_size]return x_train, x_test, y_train, y_testdef select_k(X, y):k_list = np.arange(1, 22, 2) # k值列表res_map = {} # 存储k-score的字典for k in k_list:scores = cross_val_score(KNeighborsClassifier(n_neighbors=k), # 模型实例X,y,cv=5, # 折数scoring="accuracy" # 分数标准)# 得到每组的平均分数score = np.mean(scores)# 键值对赋值res_map[k] = res_map.get(k, score)# 排序res_map = sorted(res_map.items(),key=operator.itemgetter(1),reverse=True)# 返回准确率最高的kreturn res_map[0][0]if __name__ == '__main__':X, y = load_data()x_train, x_test, y_train, y_test = train_test_split(X, y)# 进行z1归一化scaler = StandardScaler()x_train = scaler.fit_transform(x_train)# 测试集不能参与拟合x_test = scaler.transform(x_test)best_k = select_k(x_train, y_train)# n_neighbors就是kknn1 = KNeighborsClassifier(n_neighbors=best_k)knn2 = KNeighborsClassifier(n_neighbors=5)# 拟合knn1.fit(x_train, y_train)knn2.fit(x_train, y_train)# 获得knn的分类结果y_pred1 = knn1.predict(x_test)y_pred2 = knn2.predict(x_test)print(f"交叉验证后准确率:{accuracy_score(y_test, y_pred1)}")print(f"无交叉验证准确率:{accuracy_score(y_test, y_pred2)}")
输出结果
第一次
交叉验证后准确率:0.8866666666666667
无交叉验证准确率:0.86
第二次
交叉验证后准确率:0.9466666666666667
无交叉验证准确率:0.9266666666666666
第三次
交叉验证后准确率:0.9333333333333333
无交叉验证准确率:0.8933333333333333
使用sklearn的KFold进行k折验证
# KFold实例
kf = KFold(n_splits=5, # 5折shuffle=True, # 打乱顺序random_state=43 # 固定种子
)
遍历k值,找到最合适的那个
for k in np.arange(1,22,2):cur_scope=0# kf.split(X)返回训练集的索引和验证集的索引for train_index, val_index in kf.split(X):X_train, X_val = X[train_index], X[val_index]y_train, y_val = y[train_index], y[val_index]# KNNclf = KNeighborsClassifier(n_neighbors=k)clf.fit(X_train,y_train)# 计算组的总分数cur_scope = cur_scope+clf.score(X_val,y_val)# 组的平均分数avg_scope = cur_scope / 5# 更新if avg_scope > best_score:best_score = avg_scopebest_k = k
整体代码
import numpy as np
from sklearn.model_selection import KFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_irisiris_data = load_iris()
X = iris_data.data
y = iris_data.target# KFold实例
kf = KFold(n_splits=5, # 5折shuffle=True, # 打乱顺序random_state=43 # 固定种子
)best_score = 0
best_k = 0for k in np.arange(1,22,2):cur_scope=0# kf.split(X)返回训练集的索引和验证集的索引for train_index, val_index in kf.split(X):X_train, X_val = X[train_index], X[val_index]y_train, y_val = y[train_index], y[val_index]# KNNclf = KNeighborsClassifier(n_neighbors=k)clf.fit(X_train,y_train)# 计算组的总分数cur_scope = cur_scope+clf.score(X_val,y_val)# 组的平均分数avg_scope = cur_scope / 5# 更新if avg_scope > best_score:best_score = avg_scopebest_k = kprint(f"最优验证分数:{best_score},最优k={best_k}")
结果
最优验证分数:0.9666666666666668,最优k=11
使用网格搜索
导入网格搜索
# 网格搜索交叉验证
from sklearn.model_selection import GridSearchCV
核心代码
# 需要搜索的k值,键的名字就是KNeighborsClassifier中参数名
params = {"n_neighbors": np.arange(1, 22, 2)
}
# 这里就不用传参数进去了
knn = KNeighborsClassifier()# 在模型内部对每一个k进行评估
clf = GridSearchCV(KNeighborsClassifier(), # 模型实例param_grid=params, # 传参cv=5 # 5折交叉验证
)# 拟合
clf.fit(X_train, y_train)
整体代码
import numpy as np
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
# 网格搜索交叉验证
from sklearn.model_selection import GridSearchCV, train_test_splitiris_data = load_iris()
X = iris_data.data
y = iris_data.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 需要搜索的k值,键的名字就是KNeighborsClassifier中参数名
params = {"n_neighbors": np.arange(1, 22, 2)
}
# 这里就不用传参数进去了
knn = KNeighborsClassifier()# 在模型内部对每一个k进行评估
clf = GridSearchCV(KNeighborsClassifier(), # 模型实例param_grid=params, # 传参cv=5 # 5折交叉验证
)# 拟合
clf.fit(X_train, y_train)print(f"最佳准确率={clf.best_score_}")
print(f"最佳k={clf.best_params_}")
输出
最佳准确率=0.975
最佳k={'n_neighbors': 9}
优化KNN
前面我们提到,KNN有两个很明显的缺点:
- 距离远近并不影响投票(如果k选的很大就是来者皆是客的情况)
- 计算复杂度高
因此我们可以对KNN进行优化
带权KNN
解决距离远近不影响投票的缺点,给距离带上权值
使用sklearn实现
核心代码
clf = KNeighborsClassifier(n_neighbors=11,weights="distance", # 权重为距离的倒数metric="euclidean" # 欧氏距离
)
KD树
解决计算复杂度高的问题
简介
- 一种对k维空间中的实例点进行存储以便于对其进行快速检索的树形数据结构
- kd树是一种二叉树,表示对k维空间的一个划分;构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树的每个结点都对应于一个k维矩形区域
- 利用kd树可以省去对大部分数据点的搜索,从而减少计算量
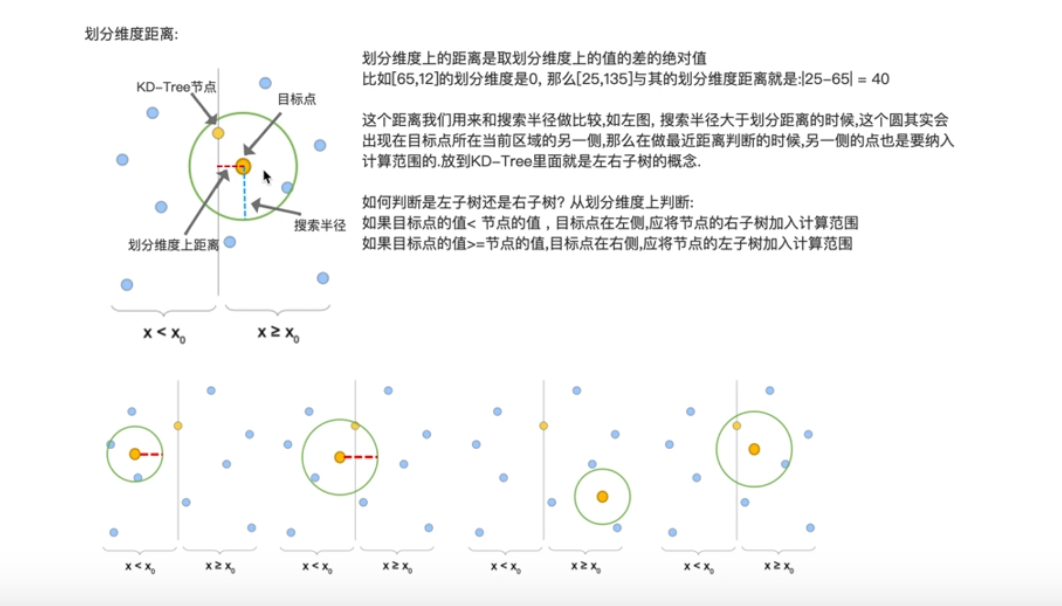
- 切分维度上,左子树值小于右子树
构造
构造 KD-Tree 的核心思想是递归地选择一个维度进行划分,并将数据点按照该维度的中位数分割为左右两部分,递归构建左右子树
步骤:
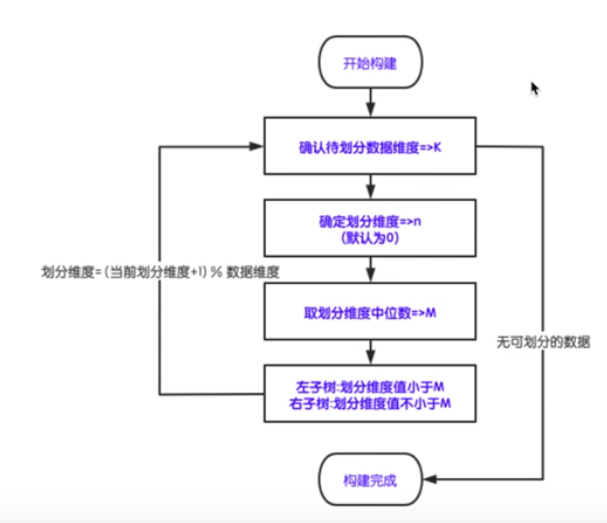
- 选择划分维度
- 通常按维度轮流选择,比如依次选择x轴,y轴,z轴
- 或者选择方差最大的维度
- 选择划分点
- 选取当前维度的中位数点作为划分点(index = size/2[整除2])
- 递归构建左右子树
- 小于中位数点的位于左子树
- 大于中位数点的位于右子树
按维度轮流选择代码实现
def build_rr(points, depth=0, d=0):''':param points: 要被划分的数据:param depth: 当前树深度:param d: 当前划分维度:return: node节点'''# 递归出口,没得划分了if len(points) == 0:return None# 数据维度k = points.shape[1]# 数据尺寸size = points.shape[0]# 对axis=d上的数据进行排序,返回排序后的索引sorted_index = np.argsort(points[:, d])# print(sorted_index)# 排序sorted_points = points[sorted_index]# 中位数索引mid_index = size // 2# 递归创建左右子树,划分维度d=(d+1)%数据维度kreturn node(point=sorted_points[mid_index], # 根节点为中位数点left=build_rr(sorted_points[:mid_index], depth + 1, (d + 1) % k), # 小于中位数点位于左子树right=build_rr(sorted_points[mid_index + 1:], depth + 1, (d + 1) % k), # 大于中位数点位于右子树)
每次选择方差最大的维度代码实现
def build_var(points, depth=0):if len(points) == 0:return None# 数据维度k = points.shape[1]# 数据尺寸size = points.shape[0]# 各个维度的方差var = np.var(points, axis=0)# 最大方差对应的维度var_max_axis = np.argmax(var)# 根据方差最大维度进行排序sorted_index = np.argsort(points[:, var_max_axis])sorted_points = points[sorted_index]# 中位数点mid_index = size // 2return node(point=sorted_points[mid_index],left=build_var(sorted_points[:mid_index],depth+1),right=build_var(sorted_points[mid_index+1:],depth+1),)
搜索
步骤
需要利用切分维度上,左子树值小于右子树这个性质
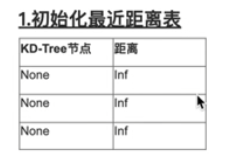
- 初始化最近距离表(输入k值)
- 根据k值初始化最近距离表
- 距离-默认inf
- 节点-默认None
- 输出最近距离表
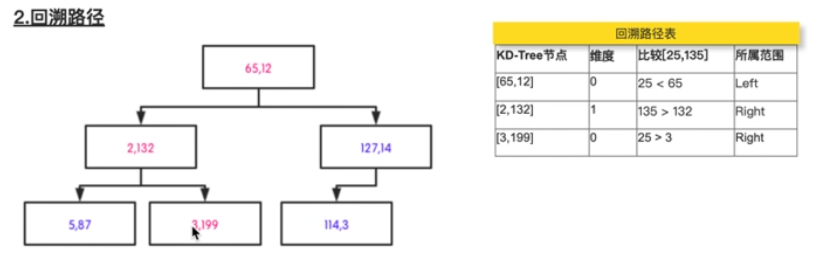
- 回溯路径(输入:目标点;KD-Tree)
- 根据kd树的节点的切分维度,比较目标点切分维度值
- 目标点值<节点值,进入左子树
- 目标点值>=节点值,进入右子树
- 回溯路径加入回溯路径表
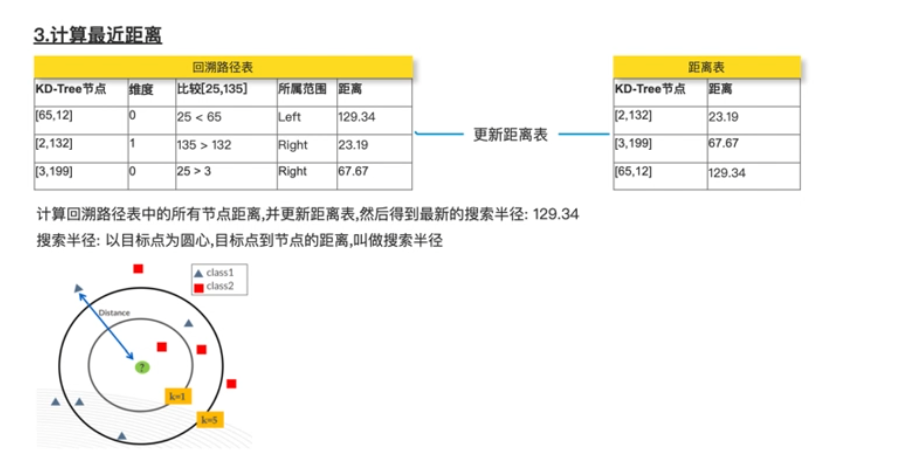
- 计算最近距离(输入:最近距离表;回溯路径表;k值;目标点)
- 计算目标点与回溯路径表中的节点距离
- 更新最近距离表(更小的距离入表)
- 取距离表中最远的距离作为搜索半径
- 计算节点在划分维度上与目标点的距离,并与搜索半径比较
- 如果搜索半径大于目标点与节点的划分维度距离,那么该节点的左子树或右子树加入回溯半径
例子
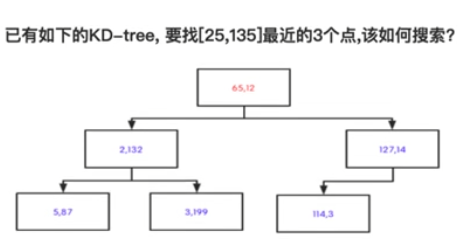
计算kd树节点与目标点的欧氏距离,把最大的距离作为搜索半径
比较与节点在划分维度上的距离,划分距离小于搜索半径时,搜索的圆形区域其实会位于节点超平面两侧(与超平面相交),也就是说要考虑另一侧子树
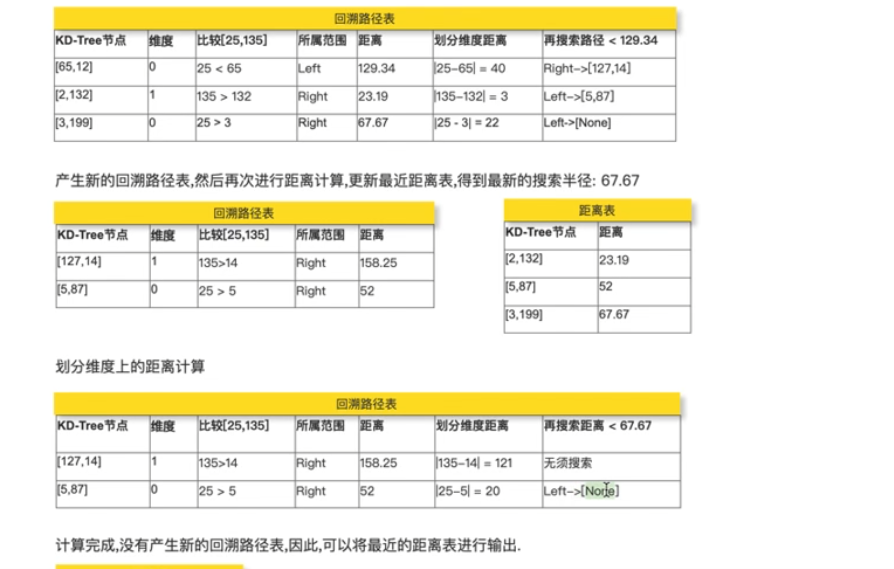
代码实现
构造kd树使用轮流选择维度
def build_rr(points, depth=0, d=0):''':param points: 要被划分的数据:param depth: 当前树深度:param d: 当前划分维度:return: node节点'''# 递归出口,没得划分了if len(points) == 0:return None# 数据维度k = points.shape[1]# 数据尺寸size = points.shape[0]# 对axis=d上的数据进行排序,返回排序后的索引sorted_index = np.argsort(points[:, d])# print(sorted_index)# 排序sorted_points = points[sorted_index]# 中位数索引mid_index = size // 2# 递归创建左右子树,划分维度d=(d+1)%数据维度kreturn node(point=sorted_points[mid_index], # 根节点为中位数点left=build_rr(sorted_points[:mid_index], depth + 1, (d + 1) % k), # 小于中位数点位于左子树right=build_rr(sorted_points[mid_index + 1:], depth + 1, (d + 1) % k), # 大于中位数点位于右子树)
表结构
# 距离表单元
class dis_node:def __init__(self, root=None, dis=inf):self.root = rootself.dis = disdef __repr__(self):return f"点: {self.root}, 距离: {self.dis}"
def kd_search(root, target, axis=0, k=3, n=0):if root is None:return []# 数据维度data_axis = root.point.shape[0]# 搜索左子树还是右子树next_node = root.left if target[axis] < root.point[axis] else root.right# 获得距离表dis_table = kd_search(next_node, target, (axis + 1) % data_axis, k, n + 1)diff = root.point - targetdis = np.sqrt(np.sum(diff ** 2))dis_table.append(dis_node(root.point, dis))# 根据距离进行排序dis_table = sorted(dis_table, key=lambda x: x.dis)# 去掉多余的距离if len(dis_table) > k:dis_table.pop()# 检查是否需要搜索另一侧子树if len(dis_table) == k:# 最大距离作为搜索半径max_dis = dis_table[-1].dis# 维度上距离小于搜索半径if np.abs(target[axis] - root.point[axis]) < max_dis:# 选择搜索另一半子树other_node = root.right if target[axis] < root.point[axis] else root.leftif other_node is not None:dis_table_other = kd_search(other_node, target, (axis + 1) % data_axis, k, n + 1)# 合并距离表dis_table.extend(dis_table_other)# 排序dis_table = sorted(dis_table, key=lambda x: x.dis)# 维护距离表长度while len(dis_table) > k:dis_table.pop()return dis_table