【问题集】——RAG项目实战:LangChain 0.3集成 Milvus 2.5向量数据库,构建大模型智能应用
本文是项目——NFRA 智能问答系统实战过程中遇到的问题记录。
问题分类是按照 RAG 的开发过程,以及后续的迭代优化思路来进行划分的。
问题集,会不断地更新,更新标识:@modify date(@modify,作为一个关键字搜索;date,就是更新发布的当天日期)
1. 数据导入
问题1:运行时错误缺少相关驱动软件
问题描述
报错时代码版本:
from langchain_unstructured import UnstructuredLoaderfile_path = r"D:/PythonLearn/codeWorkSpace/rag_learn/data/中华人民共和国反洗钱法.pdf"loader = UnstructuredLoader(file_path=file_path, # PDF文件路径strategy="hi_res", # 使用高分辨率策略进行文档处理# partition_via_api=True, # 通过API进行文档分块# coordinates=True, # 提取文本坐标信息
)
docs = []for doc in loader.lazy_load():docs.append(doc)
print(docs)Traceback (most recent call last):
File "D:\PythonLearn\myEnv\venv_rag_learn\lib\site-packages\pdf2image\pdf2image.py", line 581, in pdfinfo_from_path
proc = Popen(command, env=env, stdout=PIPE, stderr=PIPE)
File "D:\PythonLearn\myEnv\venv_rag_learn\lib\subprocess.py", line 971, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "D:\PythonLearn\myEnv\venv_rag_learn\lib\subprocess.py", line 1456, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
问题分析
代码使用了 langchain_unstructured 中的 UnstructuredLoader,并且指定了 strategy="hi_res",这个策略会触发 PDF 高分辨率解析,而 unstructured 库在底层依赖 pdf2image 来将 PDF 页面转换为图像,以便进行更精确的布局分析(如 OCR 或元素定位)。
解决方法
- 安装 Poppler,Windows 版本下载地址
- 代码中显式指定 Poppler 的路径。
解决后代码:
import osfrom langchain_unstructured import UnstructuredLoader# 显式指定 Poppler 的路径 (或者配置环境变量,并且使用管理员身份打开代码编辑器)
os.environ["PATH"] += r";D:\poppler-24.07.0\Library\bin" # 替换为你的实际路径file_path = r"D:/PythonLearn/codeWorkSpace/rag_learn/data/中华人民共和国反洗钱法.pdf"loader = UnstructuredLoader(file_path=file_path, # PDF文件路径strategy="hi_res", # 使用高分辨率策略进行文档处理# partition_via_api=True, # 通过API进行文档分块# coordinates=True, # 提取文本坐标信息
)
docs = []for doc in loader.lazy_load():docs.append(doc)print(docs)问题2 加载文件出现编码问题
问题描述
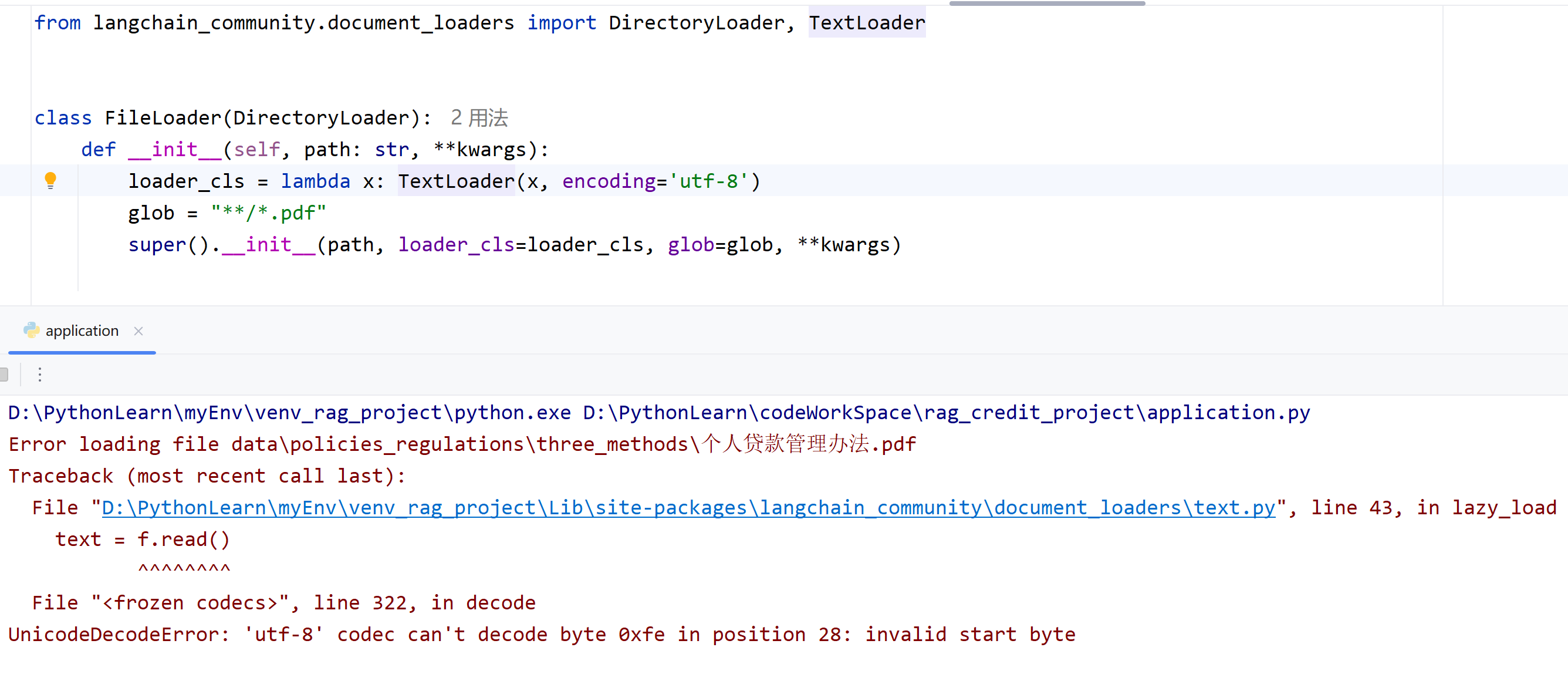
问题分析
应该是加载了文件中的图标导致的,这种图标的编码方式非“UTF-8”,如下:

解决办法
使用 UnstructuredLoader,安装命令:
pip install langchain_unstructured==0.1.6
修改后代码:
from langchain_community.document_loaders import DirectoryLoader
from langchain_unstructured import UnstructuredLoaderclass FileLoader(DirectoryLoader):def __init__(self, path: str, **kwargs):loader_cls = UnstructuredLoaderglob = "**/*.pdf"super().__init__(path, loader_cls=loader_cls, glob=glob, **kwargs)
2. 文本分块
3. 信息嵌入
4. 向量存储
问题1:Windows 本地使用启动 Milvus 数据库失败
问题描述
报错的配置文件:
version: '3.5'services:etcd:image: quay.io/coreos/etcd:v3.5.0container_name: milvus-etcdenvironment:ETCD_AUTO_COMPACTION_MODE: revisionETCD_AUTO_COMPACTION_RETENTION: "1000"ETCD_QUOTA_BACKEND_BYTES: "4294967296" # 4GBvolumes:- ./etcd:/etcdcommand: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcdminio:image: minio/minio:RELEASE.2023-03-20T20-16-18Zcontainer_name: milvus-minioenvironment:MINIO_ROOT_USER: minioadminMINIO_ROOT_PASSWORD: minioadminvolumes:- ./minio:/datacommand: minio server /datahealthcheck:test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]interval: 30stimeout: 20sretries: 3standalone:image: milvusdb/milvus:v2.5.4 # 替换为你需要的版本container_name: milvus-standaloneenvironment:ETCD_ENDPOINTS: etcd:2379MINIO_ADDRESS: minio:9000LD_PRELOAD: ""volumes:- ./milvus:/var/lib/milvusports:- "19530:19530" # Milvus 服务端口- "9091:9091" # Milvus Dashboard 端口(如果启用)depends_on:- etcd- minio错误信息:
ERROR: ld.so: object '/milvus/lib/' from LD_PRELOAD cannot be preloaded (cannot read file data): ignored.
tini (tini version 0.19.0 - git.de40ad0)
Usage: tini [OPTIONS] PROGRAM -- [ARGS] | --version
Execute a program under the supervision of a valid init process (tini)
Command line options:
--version: Show version and exit.
-h: Show this help message and exit.
-s: Register as a process subreaper (requires Linux >= 3.4).
-p SIGNAL: Trigger SIGNAL when parent dies, e.g. "-p SIGKILL".
-v: Generate more verbose output. Repeat up to 3 times.
-w: Print a warning when processes are getting reaped.
-g: Send signals to the child's process group.
-e EXIT_CODE: Remap EXIT_CODE (from 0 to 255) to 0.
-l: Show license and exit.
Environment variables:
TINI_SUBREAPER: Register as a process subreaper (requires Linux >= 3.4).
TINI_VERBOSITY: Set the verbosity level (default: 1).
TINI_KILL_PROCESS_GROUP: Send signals to the child's process group.
问题分析
这种问题就是配置项不对,根据报错信息的最后几行来分析即可。
解决方案
使用官方提供的配置文档,修改 Milvus 版本为自己使用的,问题解决。
启动 docker 配置文件(docker-compose.yml):
version: '3.5'services:etcd:container_name: milvus-etcdimage: quay.io/coreos/etcd:v3.5.18environment:- ETCD_AUTO_COMPACTION_MODE=revision- ETCD_AUTO_COMPACTION_RETENTION=1000- ETCD_QUOTA_BACKEND_BYTES=4294967296- ETCD_SNAPSHOT_COUNT=50000volumes:- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcdcommand: etcd -advertise-client-urls=http://etcd:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcdhealthcheck:test: ["CMD", "etcdctl", "endpoint", "health"]interval: 30stimeout: 20sretries: 3minio:container_name: milvus-minioimage: minio/minio:RELEASE.2024-05-28T17-19-04Zenvironment:MINIO_ACCESS_KEY: minioadminMINIO_SECRET_KEY: minioadminports:- "9001:9001"- "9000:9000"volumes:- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_datacommand: minio server /minio_data --console-address ":9001"healthcheck:test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]interval: 30stimeout: 20sretries: 3standalone:container_name: milvus-standaloneimage: milvusdb/milvus:v2.5.4command: ["milvus", "run", "standalone"]security_opt:- seccomp:unconfinedenvironment:MINIO_REGION: us-east-1ETCD_ENDPOINTS: etcd:2379MINIO_ADDRESS: minio:9000volumes:- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvushealthcheck:test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]interval: 30sstart_period: 90stimeout: 20sretries: 3ports:- "19530:19530"- "9091:9091"depends_on:- "etcd"- "minio"networks:default:name: milvus问题2 Collection.search() 和 MilvusClient.search() 混淆
问题描述
没搞清楚 Collection.search() 和 MilvusClient.search(),这两者的区别,致使在处理它们返回的结果上使用了错误的方法,拿不到处理结果,出现各种属性不存在的报错信息。比如,代码中使用了 Collection.search(),处理结果的代码如下:
results = collection.search(data=query_vector,anns_field=config.EMBEDDING_FIELD_NAME,param=search_params,limit=config.TOP_K,output_fields=["id", "text"]
)[0]retrieved_context = ""
for doc in enumerate(results):print(" doc:", doc)retrieved_context = retrieved_context.join(doc.entity.text).join(f";相似度得分:{doc.distance:.4f}").join("\n")
print(retrieved_context)出现的报错如下:
retrieved_context = retrieved_context.join({doc.entity.text}).join(f";相似度得分:{doc.distance:.4f}").join("\n")
^^^^^^^^^^
AttributeError: XXX has no attribute 'entity'
doc: (0, "id: 459448196553510786, distance: 0.7420327067375183, entity: {'id': 459448196553510786, 'text': '期原因和后续还款安排的可行性。同意展期的,应根据借款人'}")
问题分析
这种问题就是缺乏知识的表现,因为都不知道 milvus 中有 Collection.search() 和 MilvusClient.search() 这样的同名方法,所以就是不清楚它们的使用的。至于,怎么发现问题的,就是刚好都用练习使用过它们,在实战中发现的。
解决方案
- 了解Collection.search() 和 MilvusClient.search() 的区别,尤其是返回结果;
- Collection.search() ,返回的结果是 Hits 对象的集合;
- MilvusClient.search(),返回的结果是字典类型的集合。
2. 选择合适项目使用场景的即可。
5. 检索前处理
6. 索引优化
7. 检索后处理
8. 响应生成
9. 系统评估
大家若在实战此项目遇到新问题,欢迎私发或评论发出来,供大家参考与学习。同时,我会及时维护到正文中。
以下是问题集对应的项目博客地址:
RAG项目实战:LangChain 0.3集成 Milvus 2.5向量数据库,构建大模型智能应用-CSDN博客