用Python玩转数据:Pandas库实战指南(二)
一、Pandas 数据读取与保存
在实际工作中,数据通常存储在外部文件中,Pandas 支持多种常见文件格式的数据读取和保存。
1.读取数据
(1)CSV 文件:使用read_csv()方法,这是最常用的读取方式之一。可以通过sep参数指定分隔符(默认是逗号),header参数指定表头行(默认第一行)等。
pd.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, ...)
import pandas as pd
df = pd.read_csv('data.csv')(2)Excel 文件:需要先安装openpyxl库(用于读取.xlsx 格式),然后使用read_excel()方法。可以通过sheet_name参数指定工作表。
pd.read_excel(io, sheet_name=0, names=None, index_col=None, usecols=None, ...)
import pandas as pd
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')(3)JSON 文件:使用read_json()方法,能直接将 JSON 格式的数据转换为 DataFrame。
pd.read_json(path_or_buf=None, orient=None, typ='frame', dtype=None, ...)
import pandas as pd
df = pd.read_json('data.json')2.保存数据
(1)保存为 CSV 文件:to_csv()方法,index=False参数可以去掉保存时默认添加的索引列。
pdata.to_csv(path_or_buf=None, sep=',', ...)
import pandas as pd
df.to_csv('output.csv', index=False)(2)保存为 Excel 文件:to_excel()方法,同样可以指定工作表名。
pdata.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', ...)
import pandas as pd
df.to_excel('output.xlsx', sheet_name='Result', index=False)(3)保存为 JSON 文件:to_json()方法。
pdata.to_json(path_or_buf=None, orient=None, ...)
import pandas as pd
df.to_json('output.json')二.缺失值处理
1.缺失值与空值
缺省值:数据集中数值为空的值, pandas使用Nan表示
空值:空字符串 " "
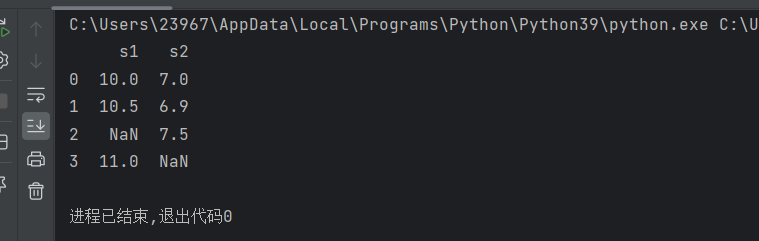
import pandas as pd
s1 = [10, 10.5, None, 11]
s2 = [7, 6.9,7.5,None]
pdata = pd.DataFrame({'s1':s1, 's2':s2})
print(pdata)
2. 缺失值判断
判断方法:
• pd.isnull():缺省值对应的值为True,返回值为Boolean的Series或者DataFrame对象
• pd.notnull():缺省值对应的值为False,返回值为Boolean的Series或者DataFrame对象
• pdata.isnull() / pdata.notnull() :同上
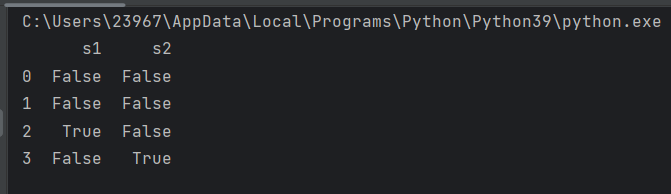
import pandas as pd
s1 = [10, 10.5, None, 11]
s2 = [7, 6.9,7.5,None]
pdata = pd.DataFrame({'s1':s1, 's2':s2})
print(pd.isnull(pdata))
3.判断是否有缺失值
1.方式:np.all 或 pd.notnull
import pandas as pd
s1 = [10, 10.5, None, 11]
s2 = [7, 6.9,7.5,None]
pdata = pd.DataFrame({'s1':s1, 's2':s2})
# pd.notnull,若包含缺省值,缺省值对应值为False
# np.all:若对象中包含假,返回False, 否则返回真
pdata=pd.notnull(pd.notnull(pdata))
# 返回False, 说明包含缺省值,否则不包含缺省值
print(pdata) 2.方式:np.any 或 pd.isnull
import pandas as pd
s1 = [10, 10.5, 11]
s2 = [7, 6.9,7.5]
pdata = pd.DataFrame({'s1':s1, 's2':s2})
# isnull:缺省值对应值为True
# np.any:对象中包含真,返回True
print(pd.isnull(pd.isnull(pdata)))
# 返回False,说明不含缺省值,返回True说明包括缺省值4. 缺省值处理方式
缺省值处理:
• 过滤缺省值(按行列)
• 删除缺省值(按行列)
• 填充值,填充值方式:
• 插入均值,中位数,最大值,最小值等
• 插入特殊值
• 插入前(后)值入前(后)值
1.删除含有缺失值的行
import pandas as pd
s1 = [10, 10.5, None, 11]
s2 = [7, 6.9,7.5,None]
s3 = [7, 6.9,7.5,7]
s4 = [None, 6.9,None,7.2]
pdata = pd.DataFrame({'s1':s1, 's2':s2, 's3':s3,'s4':s4})
pdata=pdata.dropna()
print(pdata)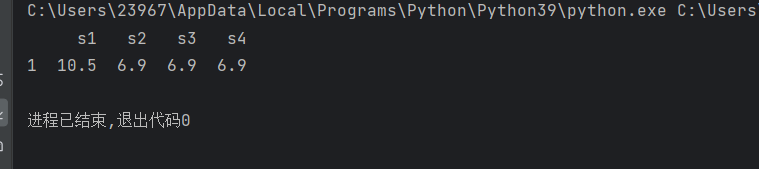
2.删除含有缺失值的列
import pandas as pd
s1 = [10, 10.5, None, 11]
s2 = [7, 6.9,7.5,None]
s3 = [7, 6.9,7.5,7]
s4 = [None, 6.9,None,7.2]
pdata = pd.DataFrame({'s1':s1, 's2':s2, 's3':s3,'s4':s4})
print(pdata)
pdata=pdata.dropna(axis=1)
print(pdata)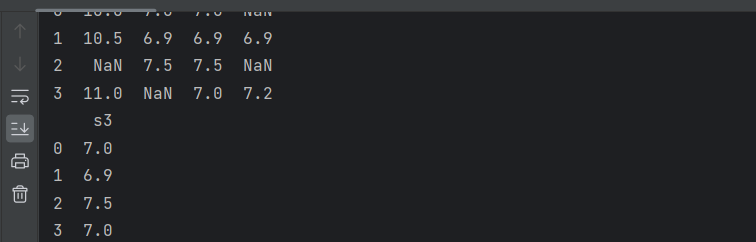
以上数据删除都不对原始数据进行修改
指定inplace为True,在原始数据中进行修改
3.缺失值填充
填充方法:
pdata.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
value:填充值
method:填充方式{'backfill', 'bfill', 'pad', 'ffill', None}
axis:指定行列0 或 'index' 表示按行,1 或 'columns' 表示按列
limit:插入数量限制
import pandas as pd
s1 = [10, 10.5, None, 11]
s2 = [7, 6.9,7.5,None]
s3 = [7, 6.9,7.5,7]
s4 = [None, 6.9,None,7.2]
pdata = pd.DataFrame({'s1':s1, 's2':s2, 's3':s3,'s4':s4})
print(pdata)
pdata = pdata.fillna(pdata.mean())
print(pdata)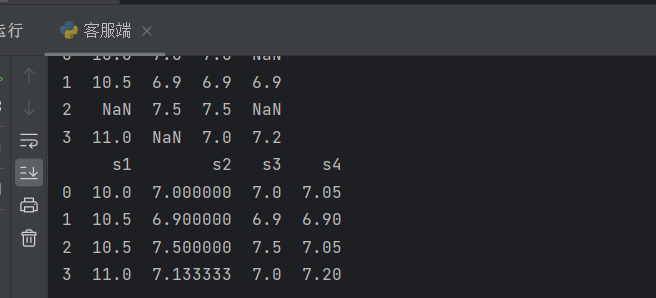
用平均数来填充空值
三.重复值处理
1.使用duplicated()检测重复行,drop_duplicates()删除重复行。
import pandas as pd
s1 = [10, 10.5, None, 11]
s2 = [7, 6.9,7.5,None]
s3 = [7, 6.9,7.5,7]
s4 = [None, 6.9,None,7.2]
pdata = pd.DataFrame({'s1':s1, 's2':s2, 's3':s3,'s4':s4})
print(pdata)
pdata=pdata.drop_duplicates('s3')
print(pdata)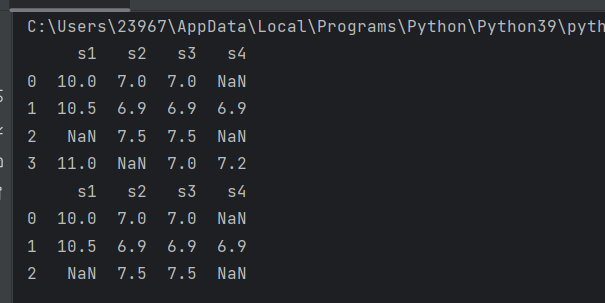
删除s3这一行重复的数据
四.数据抽取
数学成绩大于80的所有成绩;
实现思路:
根据条件生成boolean索引
通过boolean索引获取数据
import pandas as pd
import numpy as npnames = list('ABCD')
math = [90,100,50,80]
chinese = [89,96,58,77]
pdata = pd.DataFrame({'name':names, 'math':math, 'chinese':chinese})
print(pdata)
# 需求1:数学成绩大于80的所有成绩;
bindex = pdata['math'] > 80
print(pdata[bindex])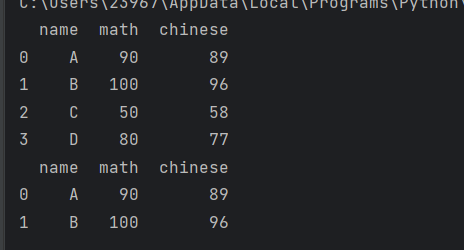
获取数学语文都大于80的成绩
条件1:数学成绩大于80
条件2:语文成绩大于80
条件3:两个条件与操作:&
基本语法:pdata[condition1&condition2]
import pandas as pd
import numpy as npnames = list('ABCD')
math = [90,100,50,80]
chinese = [89,96,58,77]
pdata = pd.DataFrame({'name':names, 'math':math, 'chinese':chinese})
print(pdata)print(pdata[(pdata['math']>80) & (pdata['chinese']>80)])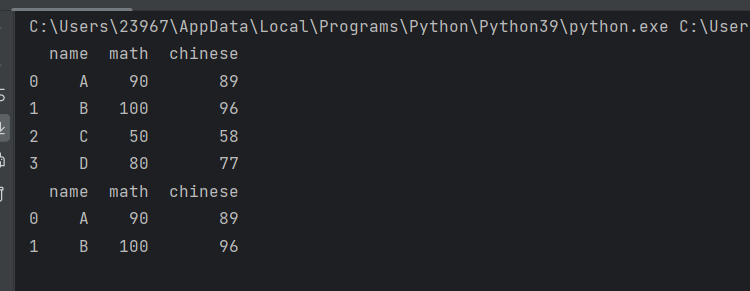
获取数学语文有一门大于等于90分
条件1:数学成绩大于等于90
条件2:语文成绩大于等于90
条件3:两个条件与操作:|
基本语法:pdata[condition1|condition2]
import pandas as pd
import numpy as npnames = list('ABCD')
math = [90,100,50,80]
chinese = [89,96,58,77]
pdata = pd.DataFrame({'name':names, 'math':math, 'chinese':chinese})
print(pdata)print(pdata[(pdata['math']>=90) | (pdata['chinese']>=90)])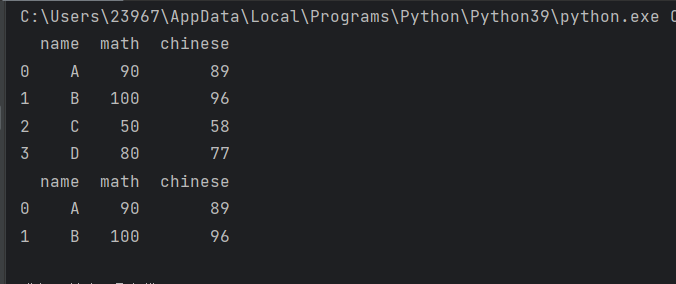
五.pandas可视化
pandas可以直接绘制图表,实现基于matplotlib,使用方式与其类似,
方法:df.plot(*args, **kwargs)
主要参数:
data:Series 或 DataFrame 对象
x:标签或索引,用于指定 x 轴数据
y:标签或索引,用于指定 y 轴数据
kind:绘制图像的样式,例如:line、bar、barh、hist 等
figsize:图像大小
use_index:是否使用 index 作为 x 轴刻度,默认为 True
grid:是否使用栅格,默认为 False
legend:是否显示图例,默认为 True
import numpy as np
import matplotlib.pyplot as plt
x=np.array([10,5,6,8,9])
y=np.array([5,3,69,5,4])
plt.plot(x,y,'r')
plt.title('abc')
plt.xlabel('X axis')
plt.ylabel('Y axis')
plt.show()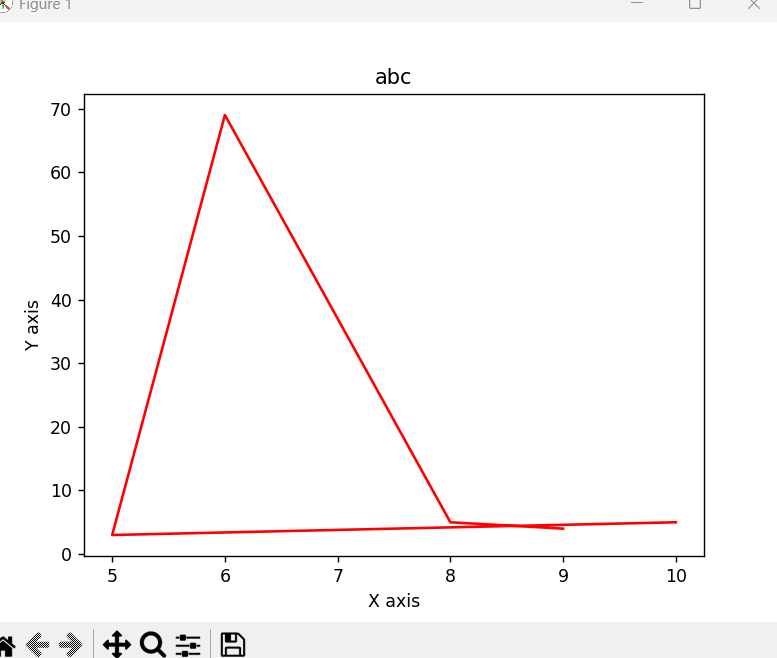
plot中可视化方法
折线图:df.plot.line(x=None, y=None, **kwargs)
柱状图:df.plot.bar(x=None, y=None, **kwargs)
条形图:df.plot.barh(x=None, y=None, **kwargs)
直方图:df.plot.hist(by=None, bins=10, **kwargs)
KDE图:df.plot.kde(bw_method=None, ind=None, **kwargs)
饼状图:df.plot.pie(**kwargs)
散点图:df.plot.scatter(x, y, s=None, c=None, **kwargs)
箱状图:df.plot.box(by=None, **kwargs)
区域块状图:df.plot.area(x=None, y=None, **kwargs)*kwargs)