shell 正则表达式
文章目录
- 前言
- 一、基础概念
- 1. 正则表达式类型
- 2. 常用元字符
- 二、字符类
- 1. 预定义字符类
- 2. POSIX字符类
- 三、Shell工具中的正则应用
- 1. grep
- 2. sed
- 3. awk
- 四、实用正则模式
- 1. 常见匹配模式
- 2. 高级技巧
- 五、性能优化建议
- 六、调试技巧
前言
正则表达式是文本处理的强大工具,在Shell脚本中广泛使用。本文将全面介绍Shell中常用的正则表达式语法、工具和实际应用。
一、基础概念
1. 正则表达式类型
基本正则表达式(BRE):grep, sed 默认使用
扩展正则表达式(ERE):grep -E, egrep, awk 使用
Perl兼容正则(PCRE):grep -P (部分系统支持)
2. 常用元字符
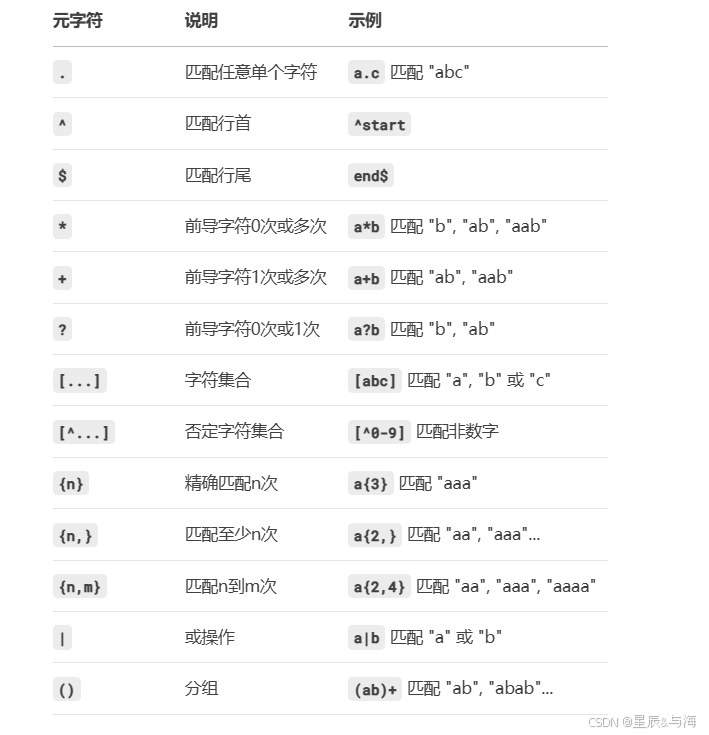
二、字符类
1. 预定义字符类
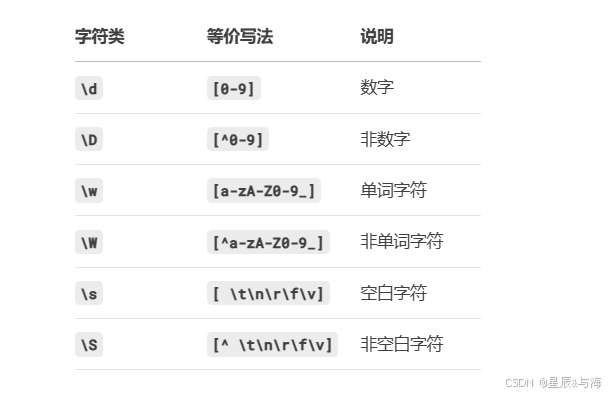
2. POSIX字符类

三、Shell工具中的正则应用
1. grep
# 基本用法
grep 'pattern' file.txt# 常用选项
grep -i 'pattern' file.txt # 忽略大小写
grep -v 'pattern' file.txt # 反向匹配
grep -n 'pattern' file.txt # 显示行号
grep -c 'pattern' file.txt # 统计匹配行数
grep -o 'pattern' file.txt # 只输出匹配部分
grep -E 'pattern' file.txt # 使用扩展正则
grep -P 'pattern' file.txt # 使用PCRE正则(部分系统)# 示例
grep '^[A-Z]' file.txt # 匹配以大写字母开头的行
grep '[0-9]{3}-[0-9]{4}' file.txt # 匹配电话号码
2. sed
# 基本用法
sed 's/pattern/replacement/' file.txt# 常用选项
sed -n '5p' file.txt # 打印第5行
sed -i 's/old/new/g' file.txt # 直接修改文件
sed '/pattern/d' file.txt # 删除匹配行# 示例
sed 's/[0-9]\+/**NUM**/g' file.txt # 替换所有数字
sed -E 's/([a-z])([A-Z])/\1 \2/g' file.txt # 在小写和大写字母间加空格
3. awk
# 基本用法awk '/pattern/{action}' file.txt# 示例
awk '/^[A-Z]/{print $0}' file.txt # 打印以大写字母开头的行
awk '$3 ~ /^[0-9]+$/{print $1}' file.txt # 打印第3列为数字的行的第1列
awk 'BEGIN{FS=":"; OFS="-"}{print $1,$NF}' /etc/passwd # 修改输入输出分隔符
四、实用正则模式
1. 常见匹配模式
用途 正则表达式
邮箱地址 \b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b
URL `(https? ftp)://[^\s/$.?#].[^\s]*`
IP地址 \b(?:\d{1,3}\.){3}\d{1,3}\b
日期(YYYY-MM-DD) `\d{4}-(0[1-9] 1[0-2])-(0[1-9] [12][0-9] 3[01])`
时间(HH:MM:SS) `([01][0-9] 2[0-3]):[0-5][0-9]:[0-5][0-9]`
HTML标签 `<([a-z]+)([^<]+)(?:>(.)</\1> \s+/>)`
信用卡号 \b(?:\d[ -]*?){13,16}\b
2. 高级技巧
非贪婪匹配 (PCRE)
echo "<div>content</div>" | grep -Po '<div>.*?</div>'
后向引用
echo "hello hello" | sed -E 's/(hello) \1/\1 world/'
条件匹配
awk '/start/{flag=1} flag; /end/{flag=0}' file.txt
多行匹配
grep -Pzo '(?s)start.*?end' file.txt
五、性能优化建议
尽量使用具体匹配而非.*
优先使用字符类[abc]而非选择a|b|c
合理使用锚点^和$限定范围
避免过度使用捕获组()
对于复杂匹配,考虑分步处理
六、调试技巧
使用grep --color=auto高亮显示匹配
在线正则测试工具辅助开发
分步构建复杂正则表达式
使用echo $?检查上一条命令的退出状态