C++之Stack和Queue的常用函数+习题
片头
嗨!小伙伴们,大家好~,咱们又见面啦!今天我们来回顾之前学习的Stack和Queue,并且做相关练习,准备好了吗?咱们开始咯~

一、Stack
1.1 栈的概念
(可以看看咱们之前数据结构学习的栈 --> 数据结构之栈)
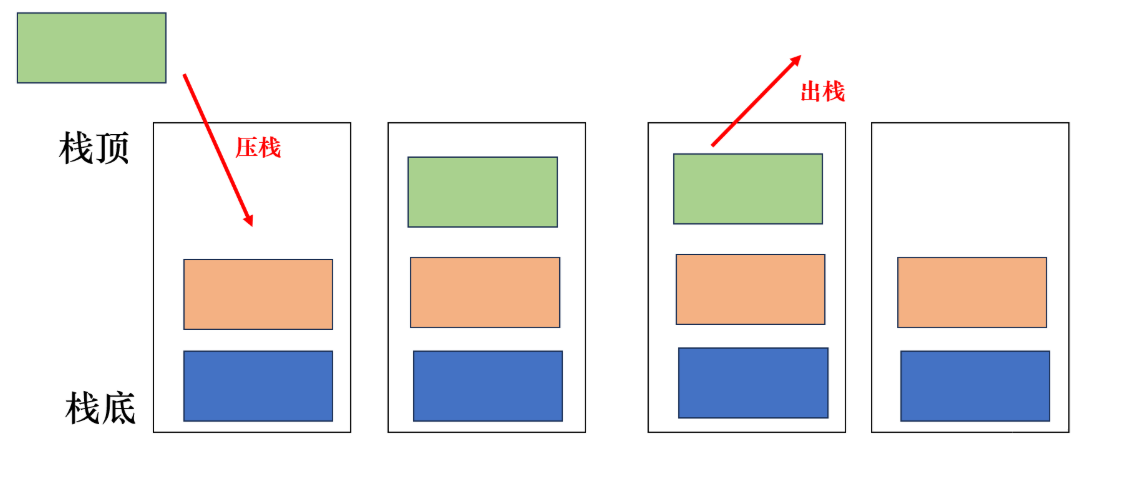
① 栈是一种特殊的线性表,它只允许在固定的一端进行插入和删除元素的操作。
② 进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。
③ 栈中的数据元素遵守后进先出LIFO (Last In First Out) 的原则。
压栈:栈的插入操作叫做 进栈 / 压栈 / 入栈,从栈顶插入数据。
出栈:栈的删除操作叫做出栈,出数据也在栈顶。
1.2 stack 的介绍
stack的文档介绍

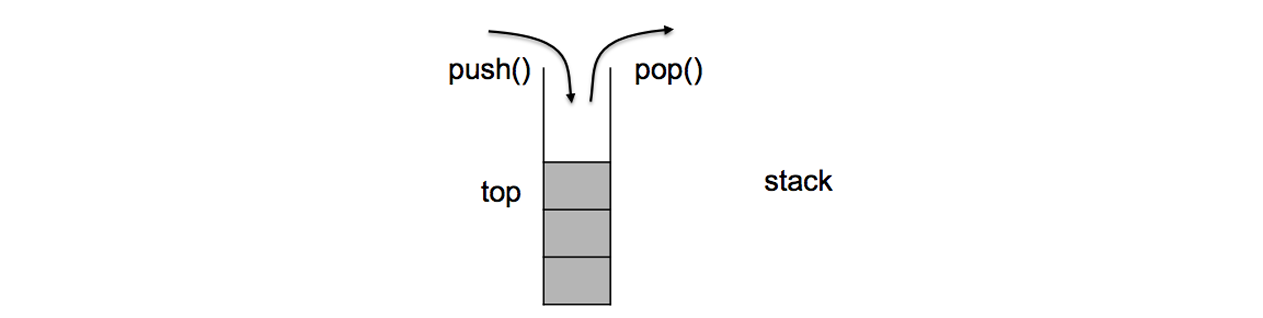
(1)stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入和提取操作。
(2)stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素
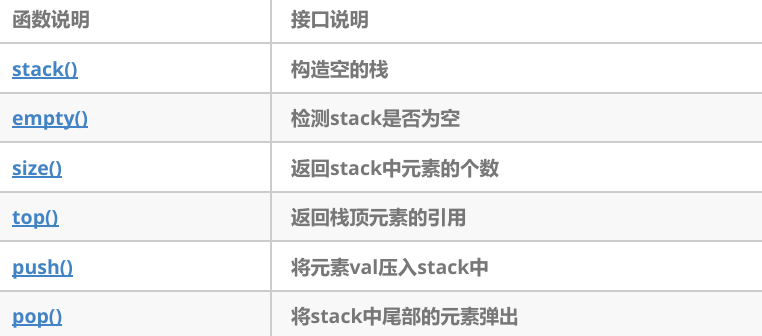
(3)stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
- empty:判空操作
- back:获取尾部元素操作
- push_back:尾部插入元素操作
- pop_back:尾部删除元素操作
(4)标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器,默认情况下使用deque。
1.3 stack 的使用
简单使用:
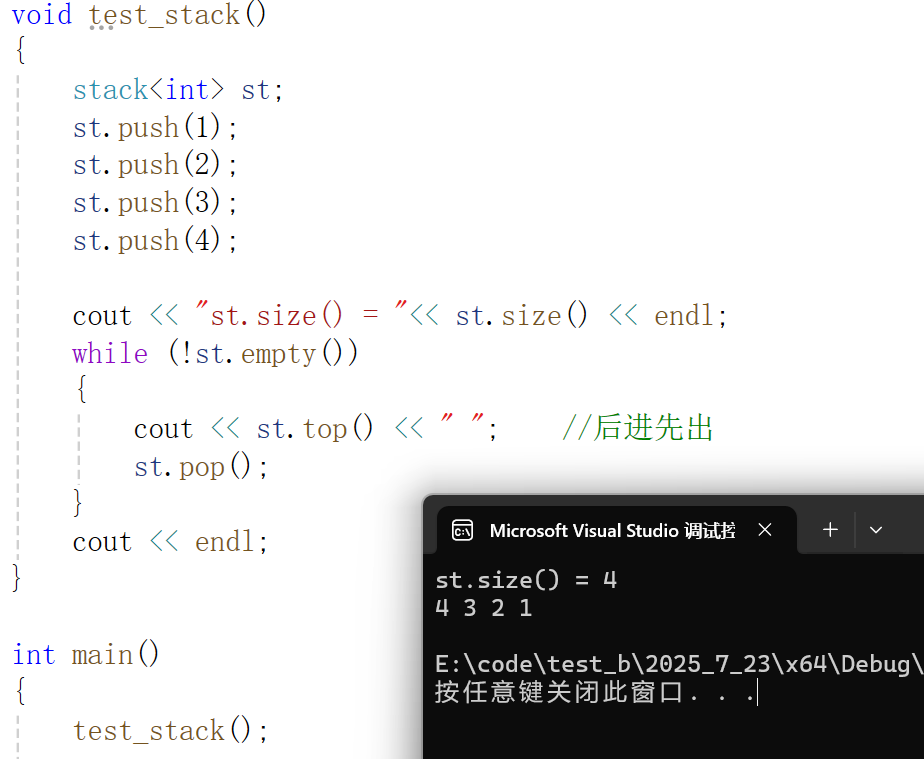
#include<iostream>
using namespace std;#include<stack>void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);cout << "st.size() = "<< st.size() << endl;while (!st.empty()){cout << st.top() << " "; //后进先出st.pop();}cout << endl;
}int main()
{test_stack();return 0;
}
二、Queue
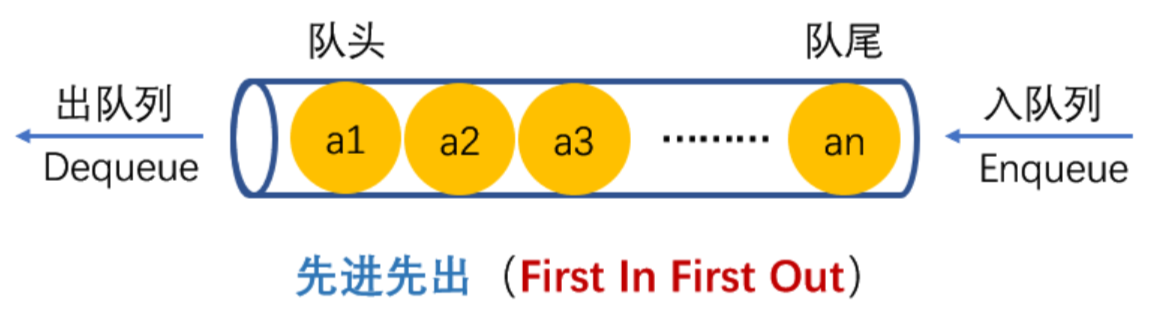
2.1 队列的概念
数据结构之队列
① 队列只允许在一端进行插入数据的操作,在另一端进行删除数据操作的特殊线性表。
② 队列具有先进先出FIFO (First in first out) 的特点。
③ 进行插入操作(入队)的一端称为队尾,进行删除操作(出队)的一端称为队头。
2.2 queue 的介绍
queue的文档介绍

(1)队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从一端插入元素,另一端提取元素。
(2)队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从对头出队列。
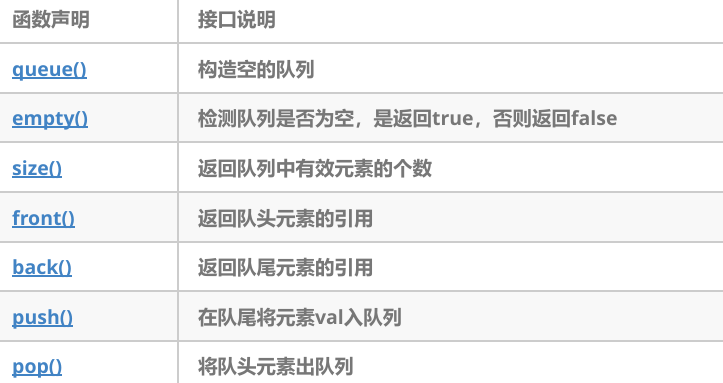
(3)底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
- empty:检测队列是否为空
- size:返回队列中有效元素的个数
- front:返回队头元素的引用
- back:返回队尾元素的引用
- push_back:在队列尾部入队列
- pop_front:在队列头部出队列
(4)标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque。
2.3 queue 的使用
简单使用:
#include<iostream>
using namespace std;#include<stack>
#include<queue>void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);cout << "st.size() = "<< st.size() << endl;while (!st.empty()){cout << st.top() << " "; //后进先出st.pop();}cout << endl;
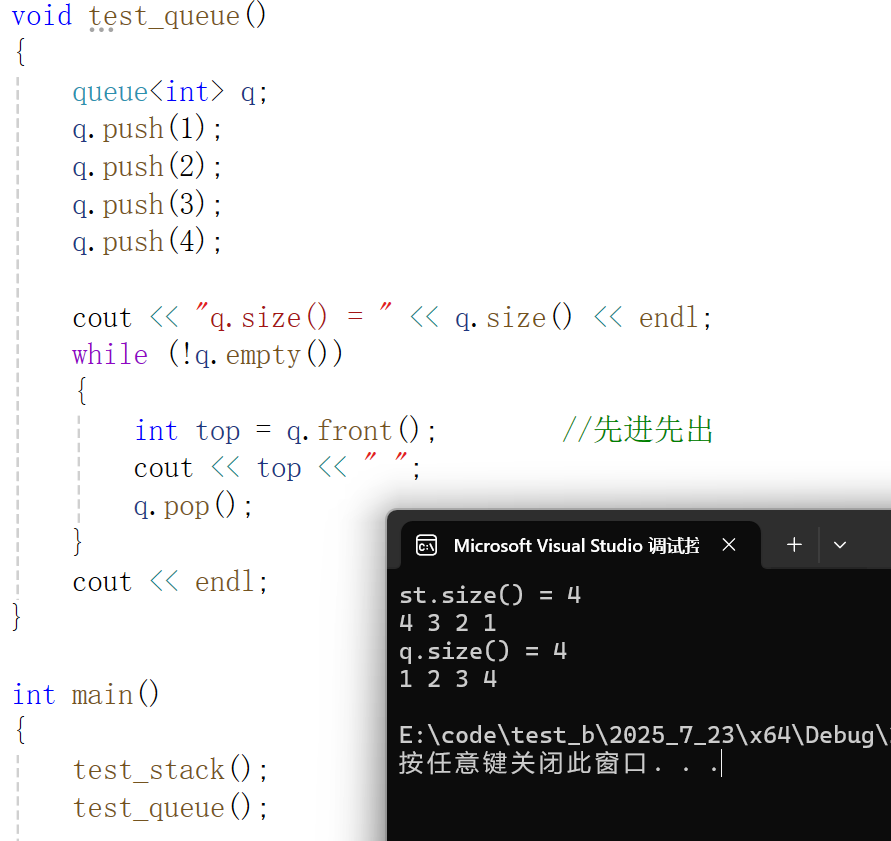
}void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);cout << "q.size() = " << q.size() << endl;while (!q.empty()){int top = q.front(); //先进先出cout << top << " ";q.pop();}cout << endl;
}int main()
{test_stack();test_queue();return 0;
}
三、栈和队列的相关选择题
1、下面程序的输出结果正确的是( )
int main()
{int arr[] = { 1,2,3,4,0,5,6,7,8,9 };int n = sizeof(arr) / sizeof(int);list<int> mylist(arr, arr + n);auto it = mylist.begin();while (it != mylist.end()){if (*it != 0)cout << *it << " ";elseit = mylist.erase(it);++it;}return 0;
}A .1 2 3 4 5 6 7 8 9
B . 1 2 3 4 6 7 8 9
C .程序运行崩溃
D .1 2 3 4 0 5 6 7 8 9
本题答案:B
解析:
1、首先,用arr的前n个元素去初始化mylist,使用迭代器it去遍历mylist
2、如果当前元素不等于0,则输出该元素;如果当前元素是0,则删除它。
3、mylist.erase(it) 删除 it 指向的元素,并返回指向下一个元素的迭代器。
注意:erase 会使当前迭代器失效,所以必须使用返回值更新 it 。
4、移动迭代器到下一个元素:++it;
(1)如果当前元素不是0,则 ++it 使迭代器指向下一个元素
(2)关键问题:如果 erase 被调用,it 已经被更新为下一个元素,此时 ++it 会导致跳过一个元素
2、对于list有迭代器it, 当erase(it)后,说法错误的是( )
A.当前迭代器it失效
B.it前面的迭代器仍然有效
C.it后面的迭代器失效
D.it后面的迭代器仍然有效
本题答案:C
解析:
std::list 是双向链表,其迭代器在 erase 操作后的行为如下:
(1)A.当前迭代器it失效:正确。erase(it) 会删除 it 指向的元素,it 变为无效迭代器,不能再解引用或递增/递减。
(2)B.it前面的迭代器仍然有效:正确。链表删除操作不会影响其他节点的迭代器(包括前面的迭代器)。
(3)C.it后面的迭代器失效:错误。std::list 的 erase 不会影响其他迭代器(包括后面的迭代器)。
(4)D.it后面的迭代器仍然有效:正确。链表结构决定删除操作不会影响其他节点的迭代器。
注意:如果是std::vector 或 std::deque,erase(it) 会使 it 及以后的所有迭代器失效!
vector 是连续存储的动态数组,删除一个元素后,后面的所有元素会向前移动(填补空缺),导致:
1、it 失效:it 指向被删除的元素,不能再使用。
2、it 后面的迭代器全部失效:因为元素位置发生了移动,原有的迭代器可能指向错误的位置或非法内存。
正确用法:
erase(it) 会返回一个新的有效迭代器,指向被删除元素的下一个位置。应使用返回值更新迭代器:
it = vec.erase(it); //it 现在指向下一个有效元素否则,直接操作失效的迭代器(如 ++it)会导致未定义行为(UB)。
总结:
list:仅当前 it 失效,前后迭代器仍有效(链表节点独立)。
vector/deque:erase(it) 会使 it 及之后所有迭代器失效。
3、下面有关vector和list的区别,描述错误的是( )
A.vector拥有一段连续的内存空间,因此支持随机存取,如果需要高效的随机读取,应该使用vector
B.list拥有一段不连续的内存空间,如果需要大量的插入和删除,应该使用list
C.vector<int>::iterator支持“+”、“+=”、“<”等操作符
D.list<int>::iterator则不支持“+”、“+=”、“<”等操作符运算,但是支持了[]运算符
本题答案:D
解析:
A.如果想大量随机读取数据操作,vector是首选的容器
B.如果想大量的插入和删除数据,list效率较高,是首选
C.vector迭代器可以随机访问,支持 + 、+= 、< 和 [] 等操作符,因为vector底层是连续空间,迭代器可以像指针一样进行算术运算。
D.list迭代器是双向迭代器,不支持 + 、+=、< 或 [] 运算符。list迭代器只能通过 ++ 或 -- 移动,不能随机访问。
4、下面有关vector和list的区别,描述正确的是( )
A.两者在尾部插入的效率一样高
B.两者在头部插入的效率一样高
C.两者都提供了push_back和push_front方法
D.两者都提供了迭代器,且迭代器都支持随机访问
本题答案:A
解析:
A.vector在尾部插入数据不需要移动数据,list为双向循环链表也很容易找到尾部,因此两者在尾部插入数据效率相同
B.vector头部插入效率极其低,需要移动大量数据
C.vector由于在头部插入数据效率很低,所以没有提供push_front方法
D.list不支持随机访问
6、下列代码的运行结果是( )
int main()
{stack<char> S;char x, y;x = 'n', y = 'g';S.push(x); S.push('i'); S.push(y);S.pop(); S.push('r'); S.push('t'); S.push(x);S.pop(); S.push('s');while (!S.empty()){x = S.top();S.pop();cout << x;}cout << y;return 0;
}A.gstrin
B.string
C.srting
D.stirng
本题答案:B
解析:
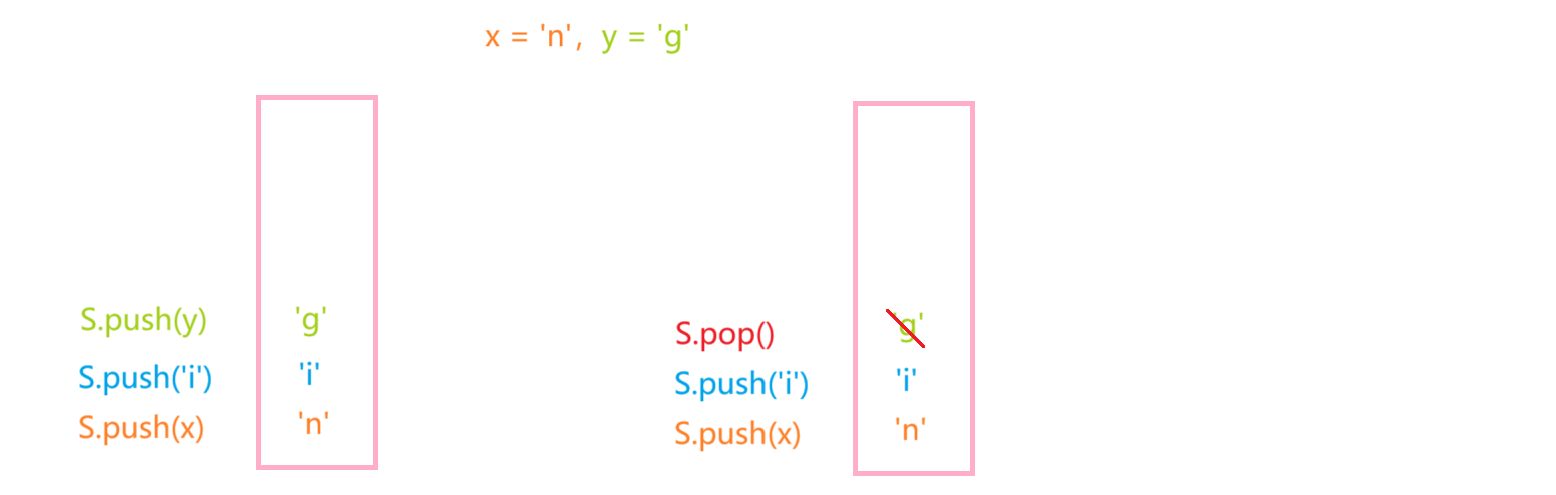
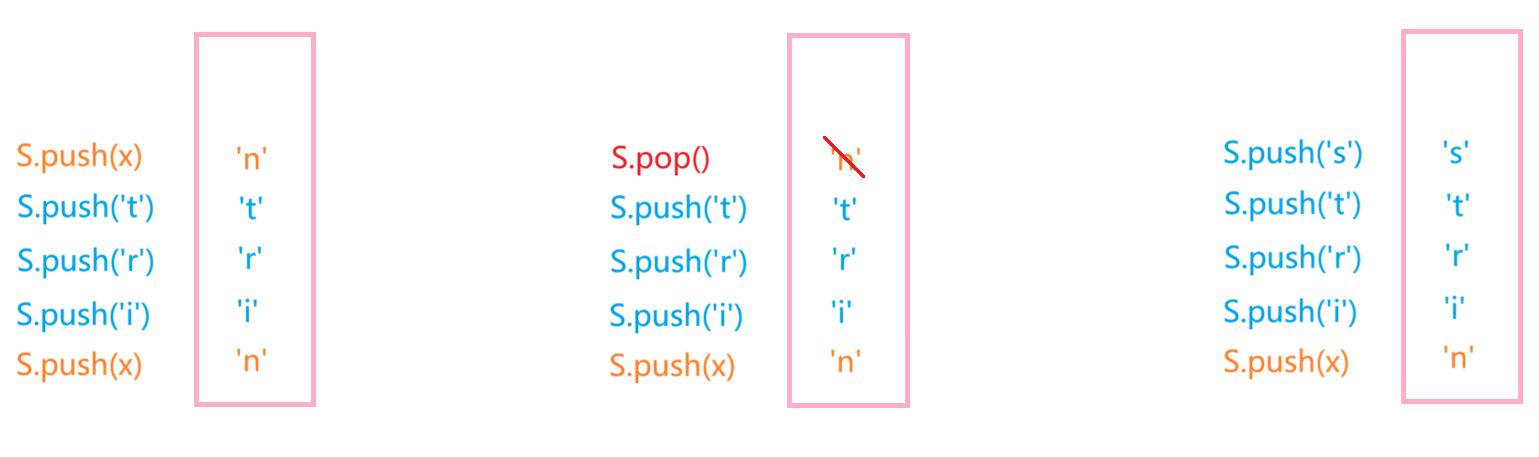
接下来,按照栈的后进先出(LIFO)规则依次出栈,出栈顺序为:'s','t','r','i','n',最后输出y的值'g',最终的打印结果为:'s','t',‘r','i',’n',‘g' --> string
7、下列代码的运行结果是( )
int main()
{queue<char> Q;char x, y;x = 'n', y = 'g';Q.push(x); Q.push('i'); Q.push(y);Q.pop(); Q.push('r'); Q.push('t'); Q.push(x);Q.pop(); Q.push('s');while (!Q.empty()){x = Q.front();Q.pop();cout << x;}cout << y;return 0;
}A.gstrin
B.grtnsg
C.srting
D.stirng
本题答案:B
解析:
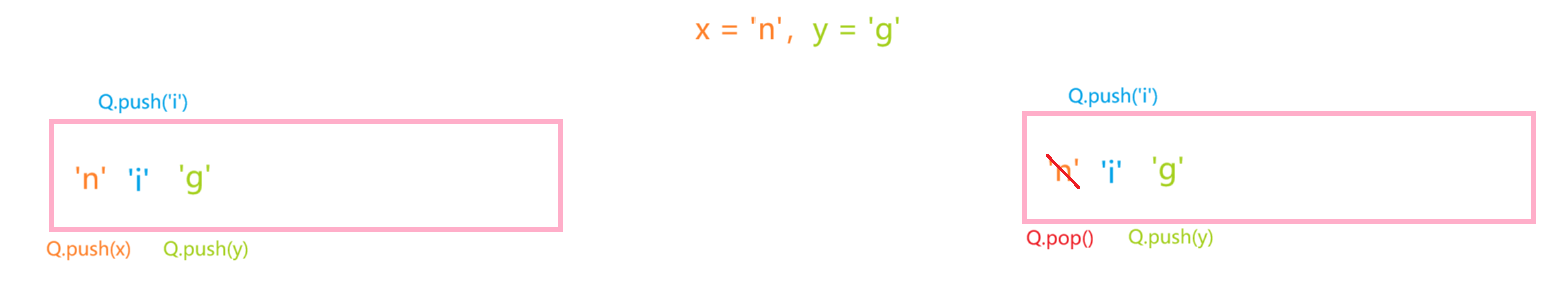

接下来,按照队列的先进先出规则出队列,出队列的顺序为:'g','r','t','n','s',最后输出y的值'g',最终的打印结果为:'g','r','t','n','s','g' --> grtnsg
8、一个栈的输入顺序是a,b,c,d,e则下列序列中不可能是出栈顺序是( )
A.e,d,a,c,b
B.a,e,d,c,b
C.b,c,d,a,e
D.b,c,a,d,e
本题答案:A
分析:首先此题要保证入栈的顺序不能改变,其次,某个字母出栈前,必须把其栈顶的元素都要出栈
A:e要先出栈,就必须把a b c d e 全部入栈,然后e才能出栈,对于e d 的出栈没有问题,只是a要出栈,就必须b、c 先出栈后,才能轮到a出栈,因此A是不可能得到的出栈顺序,其他答案可以自行验证
9、以下是一个二叉树的遍历算法,queue是FIFO队列,请参考下面的二叉树,根节点是root,正确的输出是( )

queue.push(root);while (!queue.empty()){node = queue.top();queue.pop();output(node->val); //输出节点对应数字if (node->left)queue.push(node->left);if (node->right)queue.push(root->right);}A.1376254
B.1245367
C.1234567
D.1327654
本题答案:C
解析:
本题是一个层序遍历的伪代码,层序遍历的核心是使用队列 (先进先出,FIFO)。
代码中先将根节点入队,然后循环处理队列中的节点:每次取出队首节点,访问它的值,再将其左右子节点(如果存在)依次入队。
前序遍历 vs 层序遍历
(1)前序遍历
//前序遍历
void PreOrder(BTNode* root)
{if (root == nullptr) {printf("N "); //遇到空节点打印nullptrreturn;}printf("%d ", root->data); //数据域PreOrder(root->left); //左孩子PreOrder(root->right); //右孩子
}a、顺序:根 -> 左子树 -> 右子树 (1 -> 2 -> 4 -> 5 -> 3 -> 6 -> 7)
b、数据结构:通常用递归或栈来实现
(2)层序遍历
//层序遍历
queue.push(root);while(!queue.empty())
{node = queue.top();queue.pop(); output(node->value) //输出节点对应数字if(node->left)queue.push(node->left);if(node->right)queue.push(node->right);
}a、顺序:按层级从上到下、每层从左到右(1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7)
b、数据结构:必须用队列。
片尾
今天我们学习了Stack和Queue的常用函数以及选择题部分,下一篇我们将练习栈和队列的OJ题,希望看完这篇文章对友友们有所帮助!!!
求点赞收藏加关注!!!
谢谢大家!!!
