b-up:Enzo_mi:Transformer DETR系列
1.视频1:self-Attention|自注意力机制 |位置编码 | 理论 + 代码

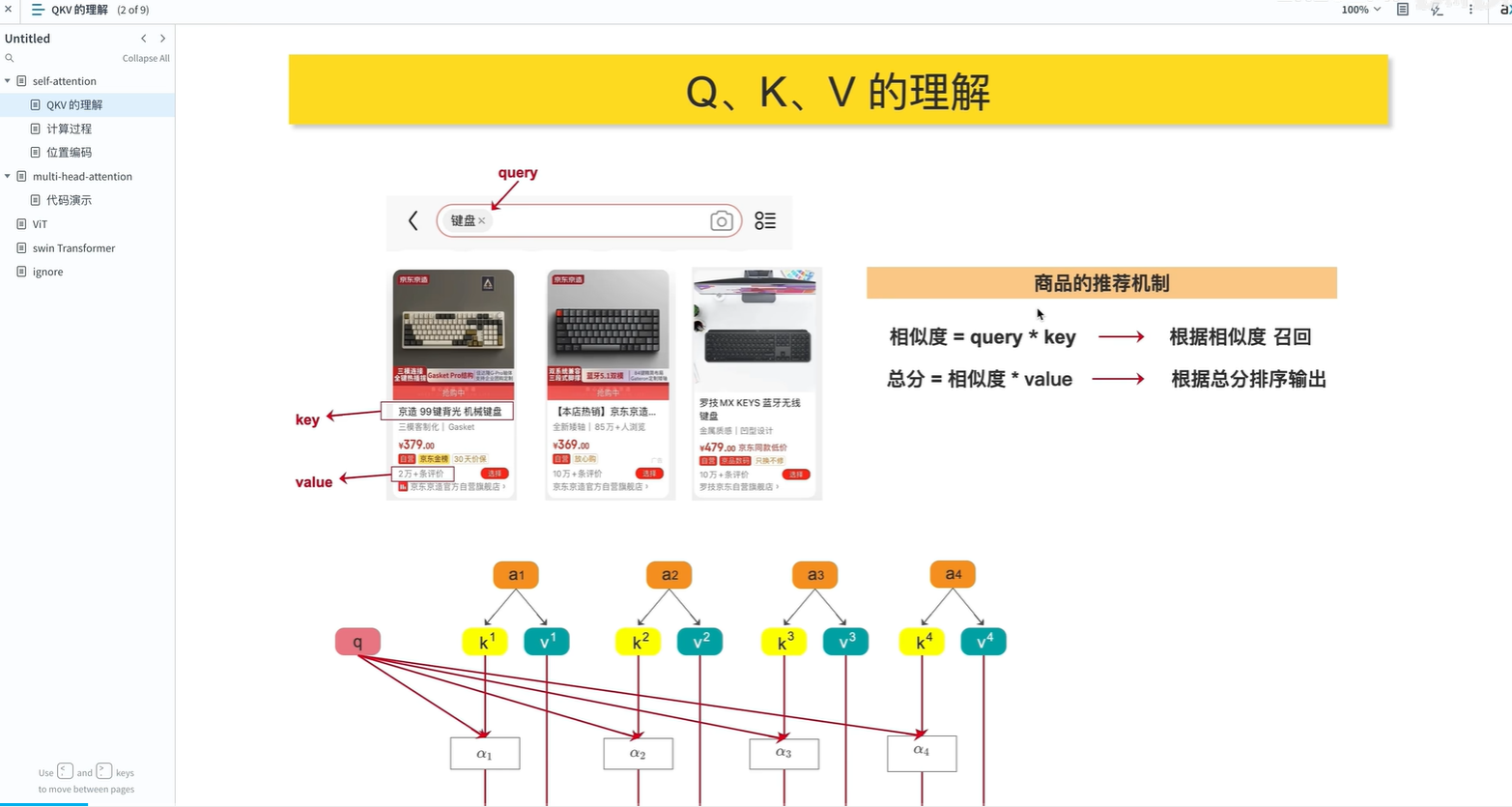
注意:
q-查询; k-商品标签; v-值(具体商品)
* 不是指乘法,类似概念
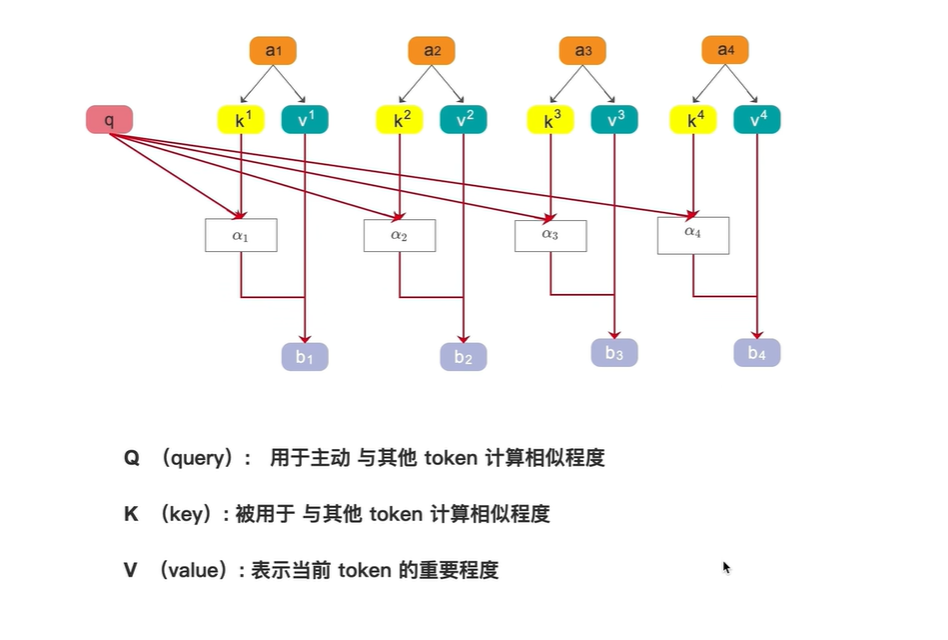
a1:相似度; b1:总分
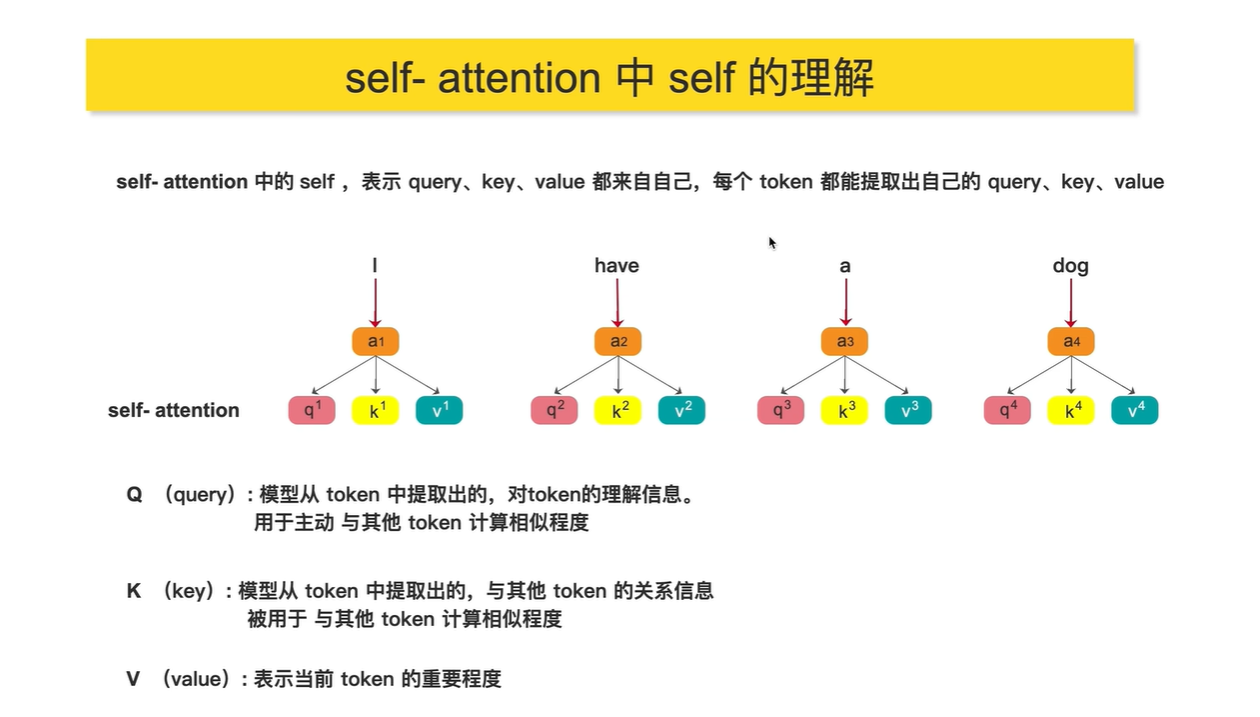
若想了解 I 这个词 与其他词的相似度,则用q1分别乘以 k2,k3,k4
若想了解 dog 这个词 与其他词的相似度,则用q4分别乘以 k1,k2,k3
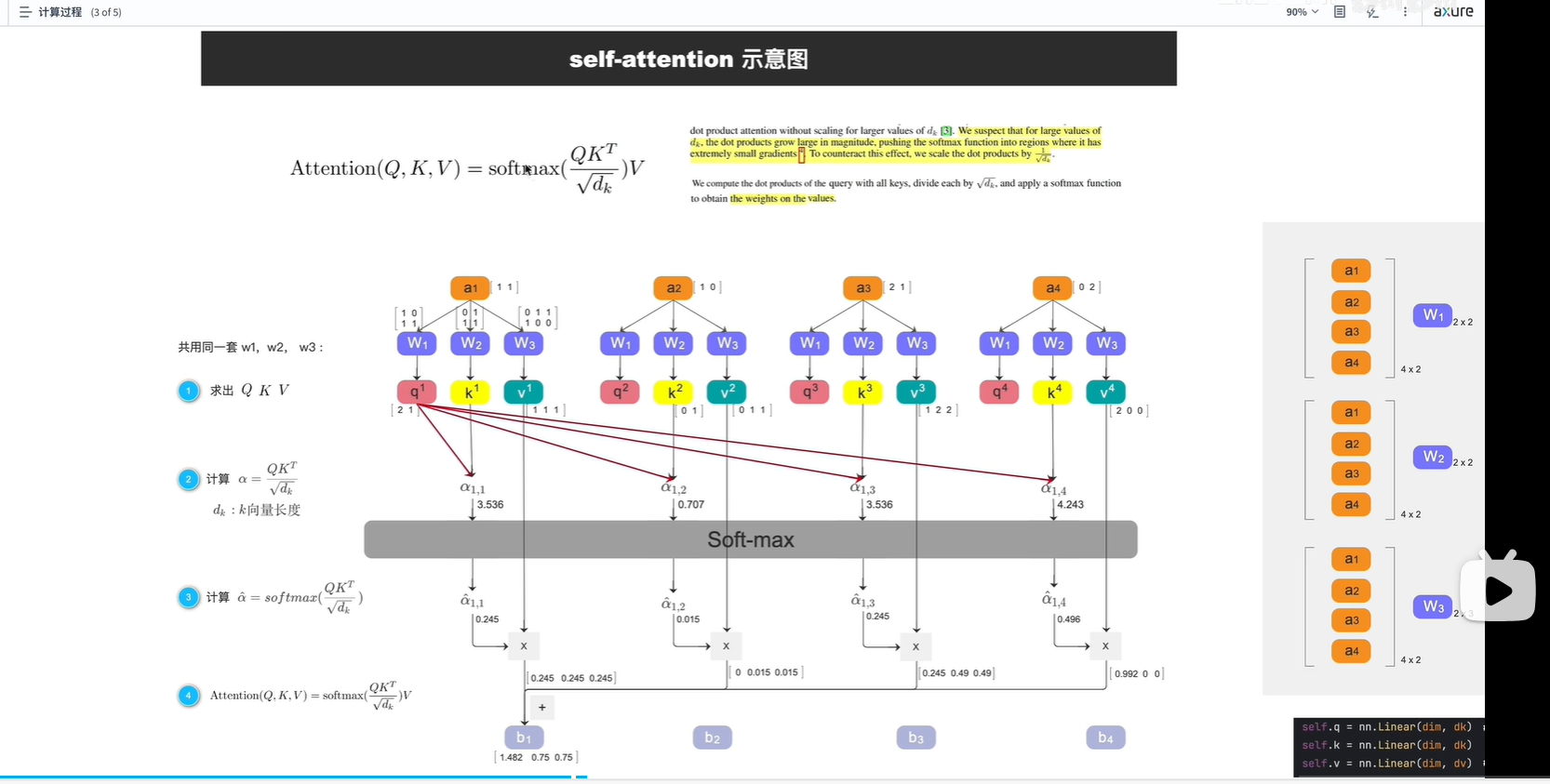
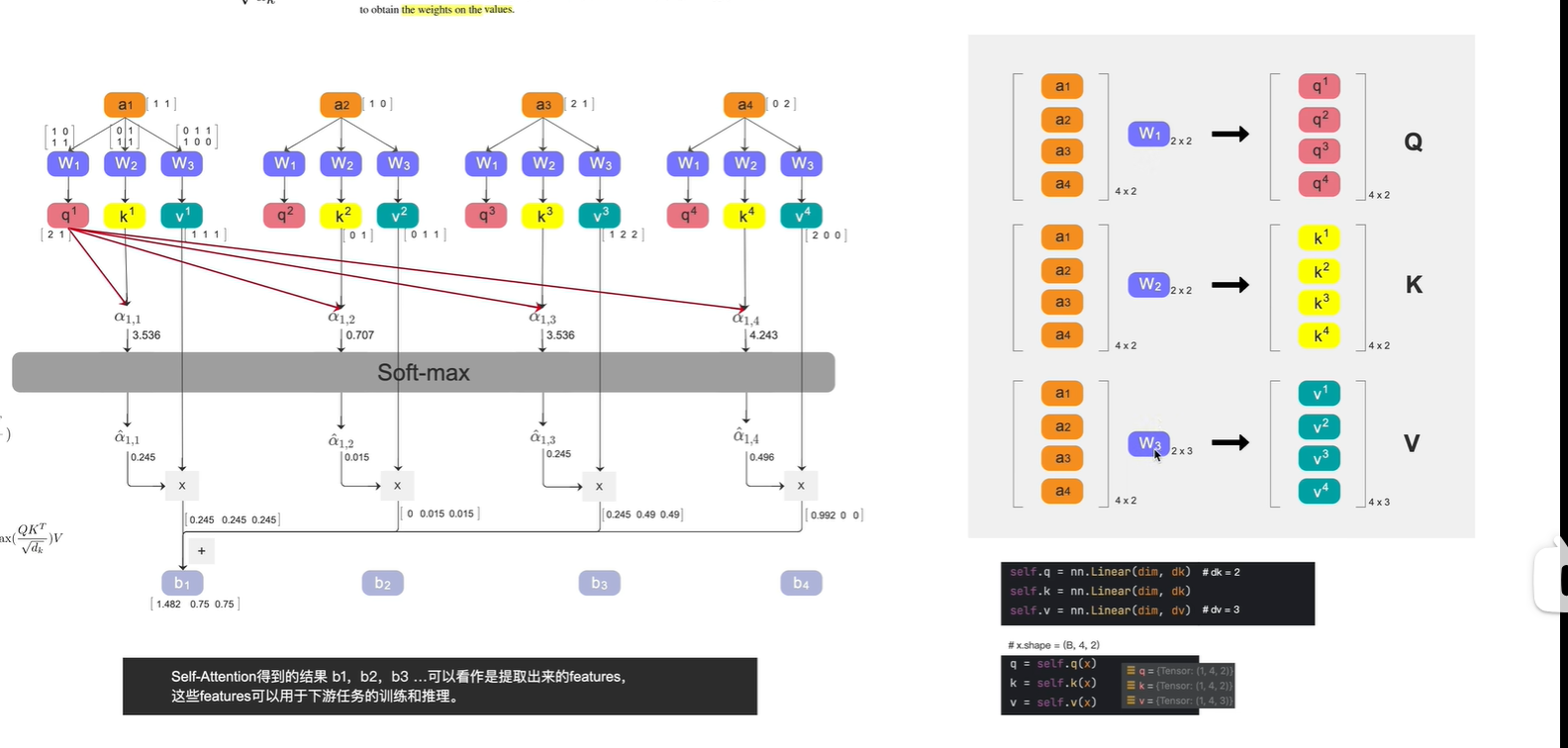
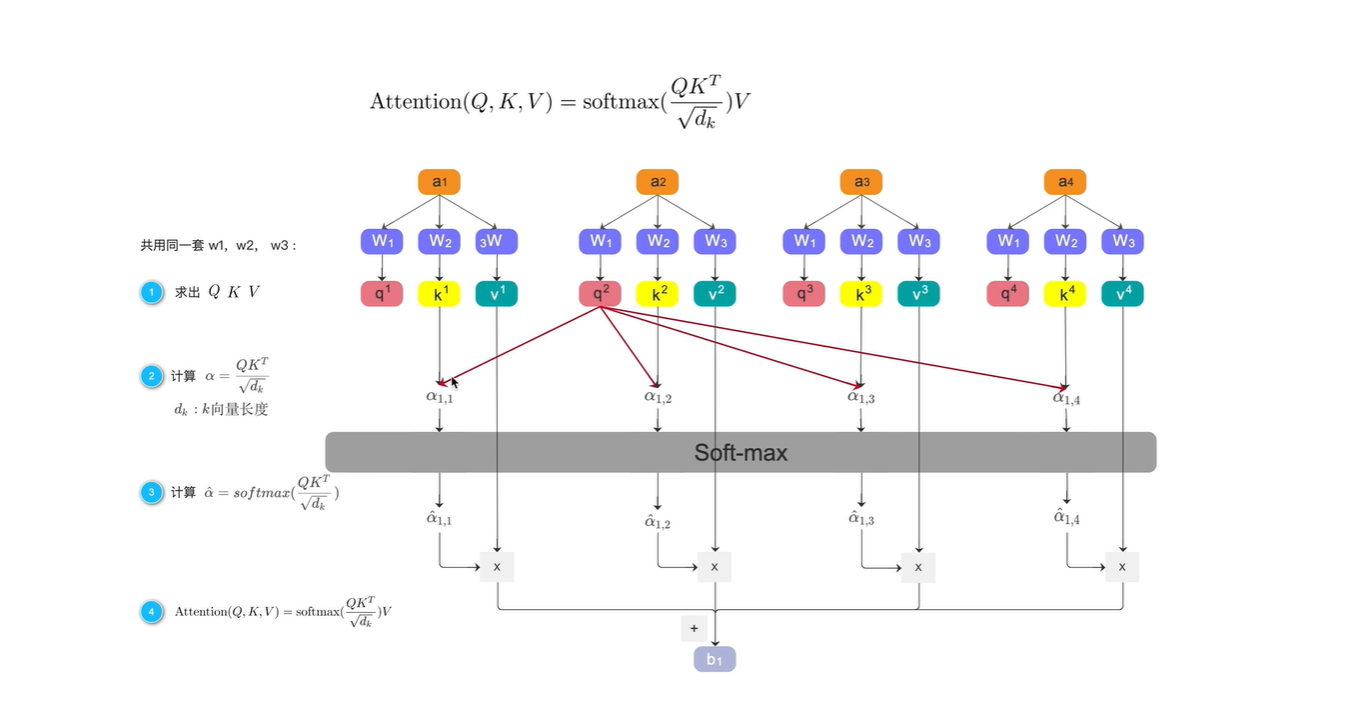
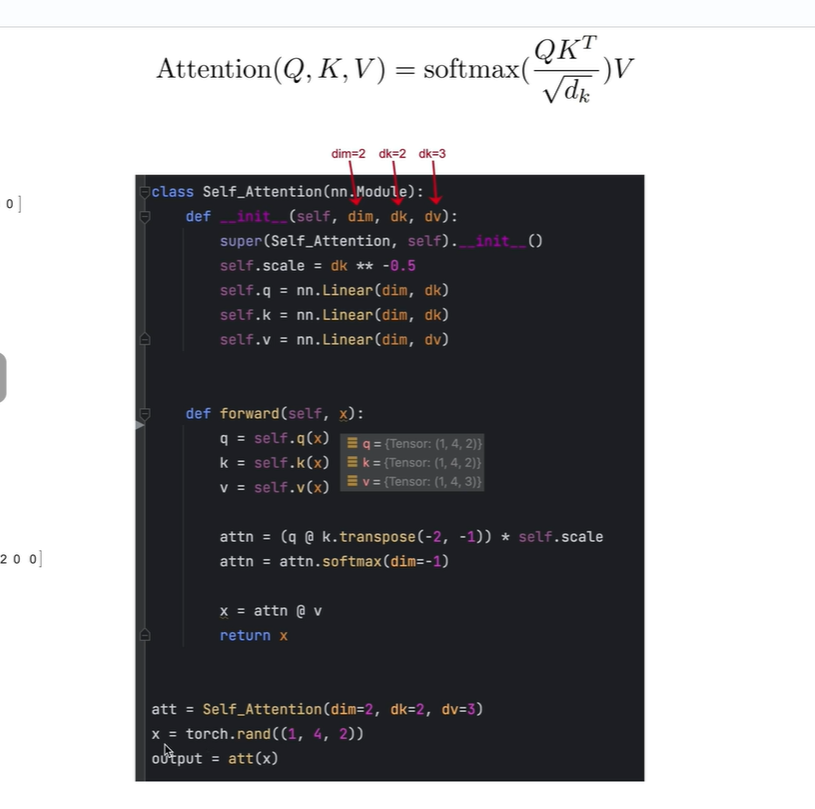
注意:
(1,4,2) 1 表示一个batch size, 4表示一个token, 2表示每个token的长度
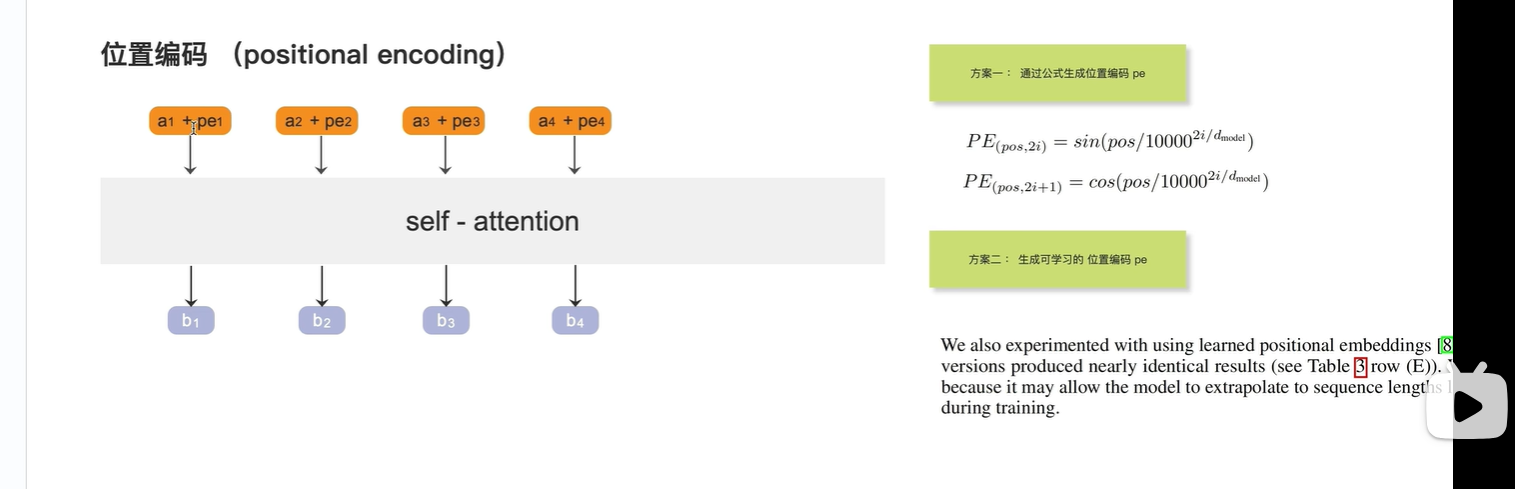
位置编码
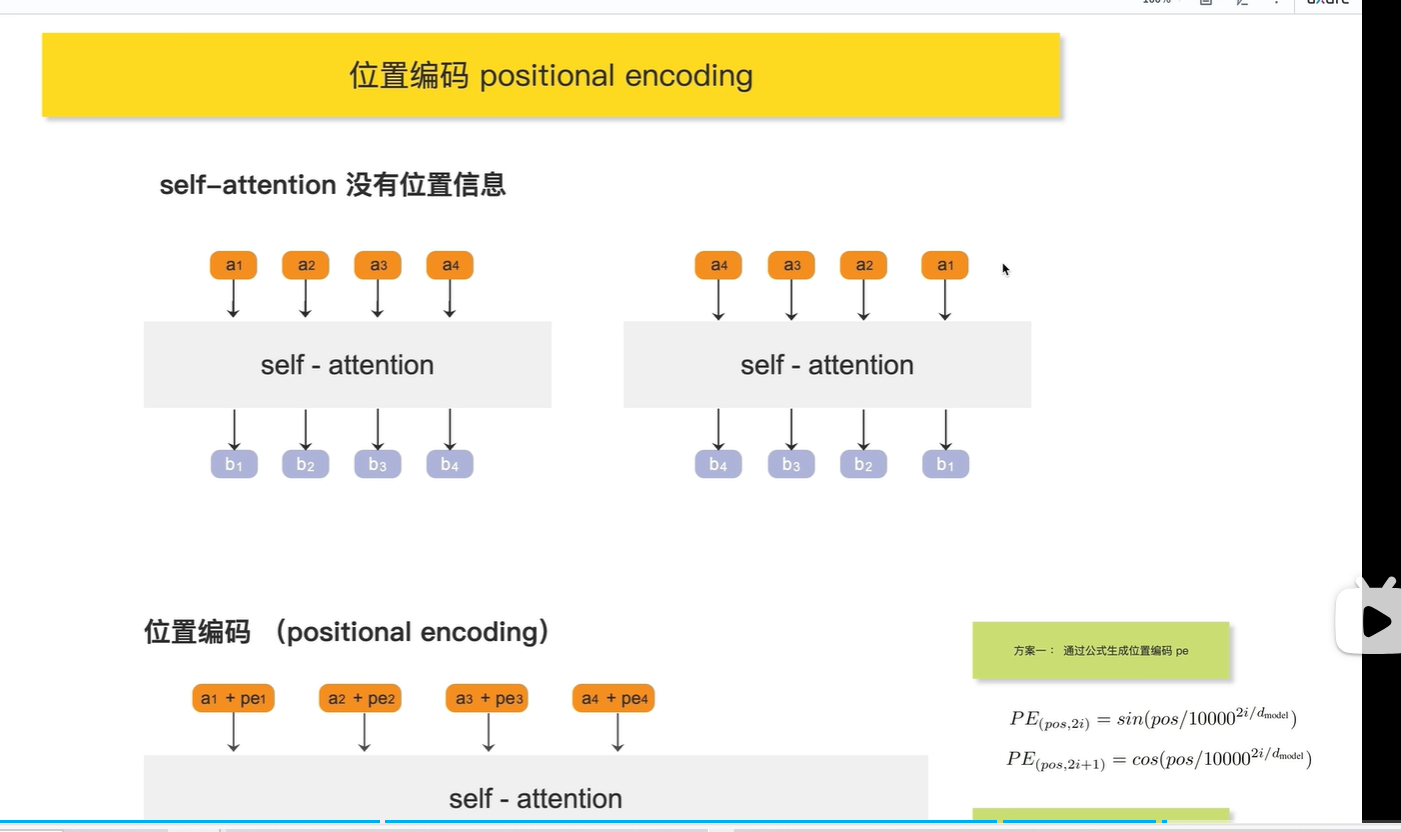
因为self-attention的输出没有位置信息, 将a4放在最后一个输出的b4, 与 将a4 放在第一个输出的b4, 两个b4完全相同,没有包含位置对其的影响(没有包含位置信息)

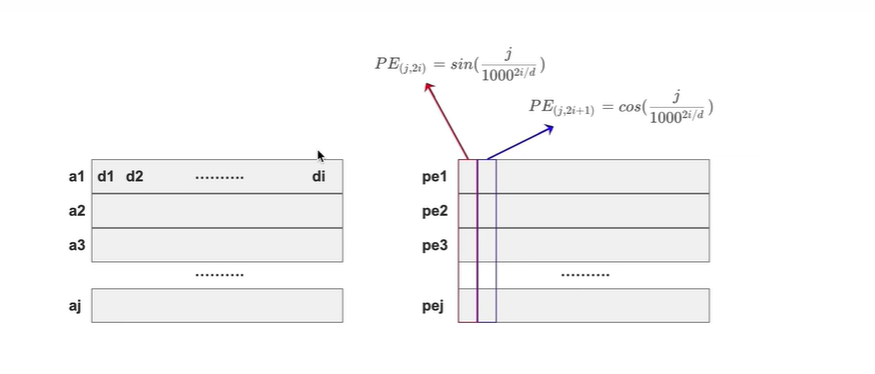
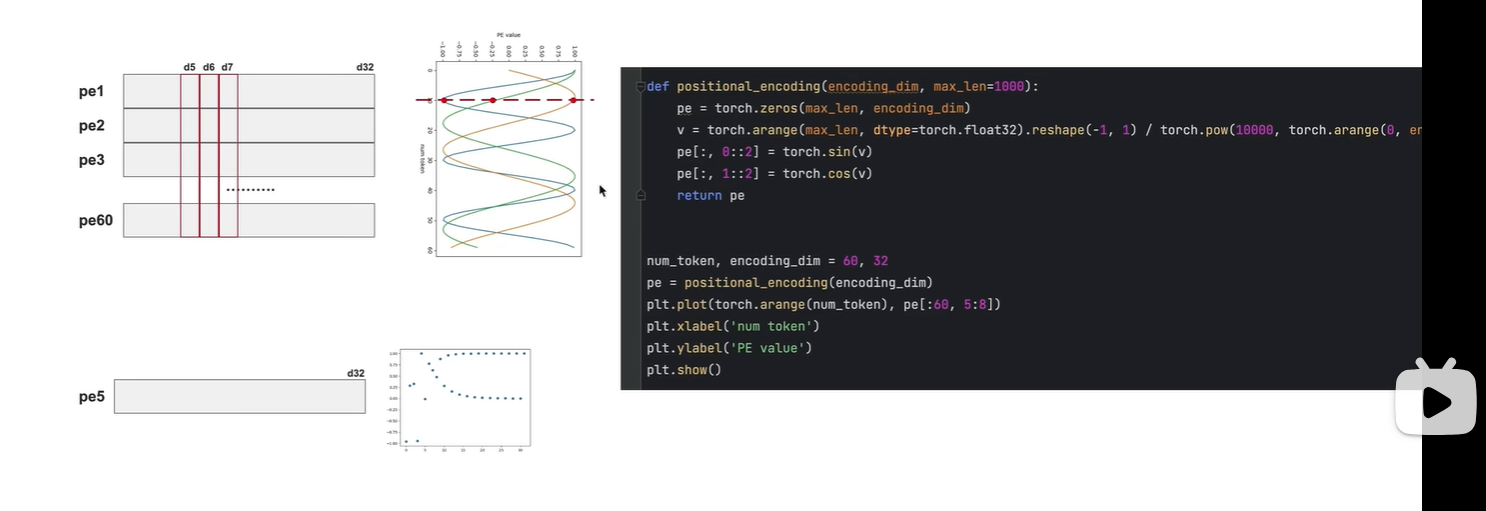
一共有j个token, 每个token都有i个维度,
对于奇数维度的位置编码,使用cos 生成
对于偶数维度的位置编码,使用sin 生成
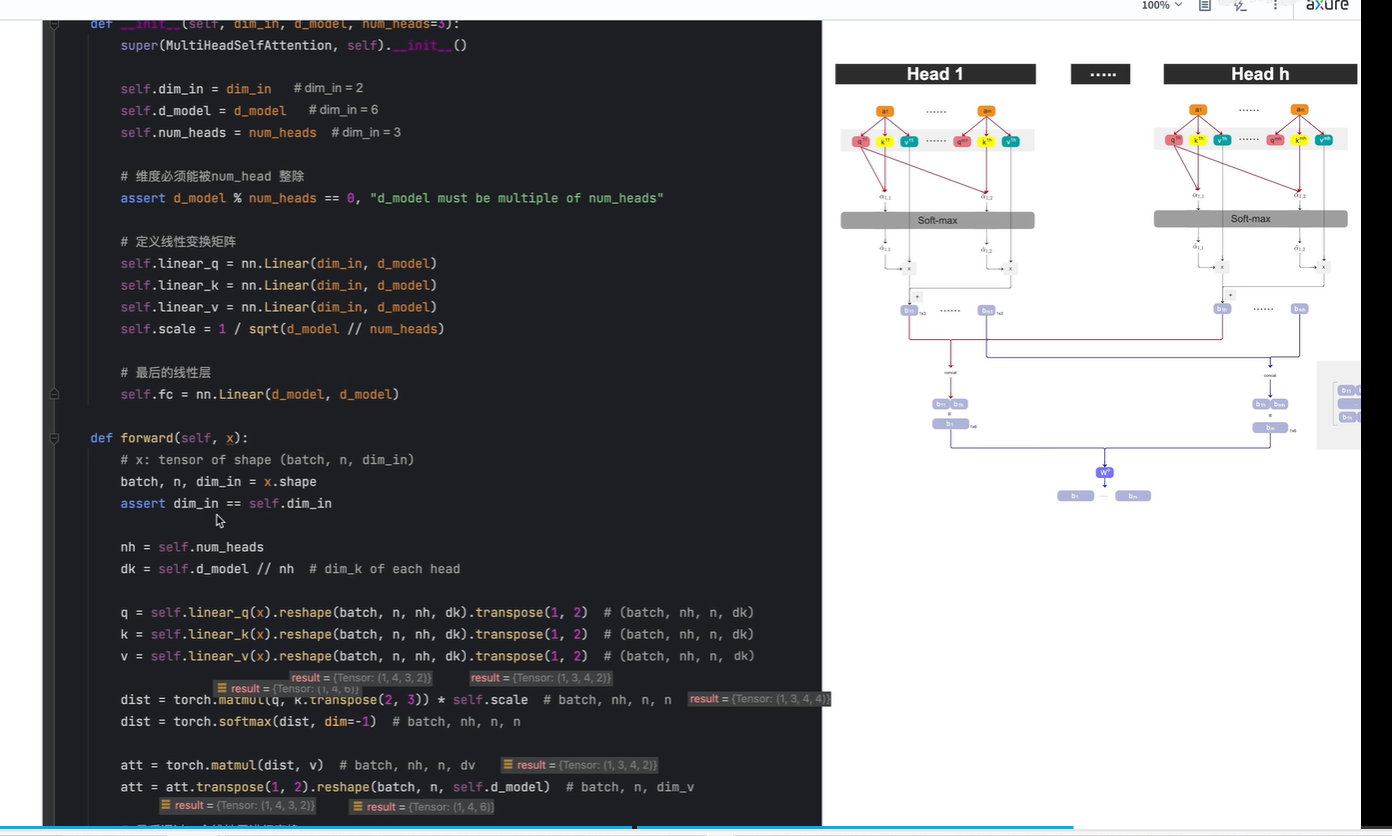
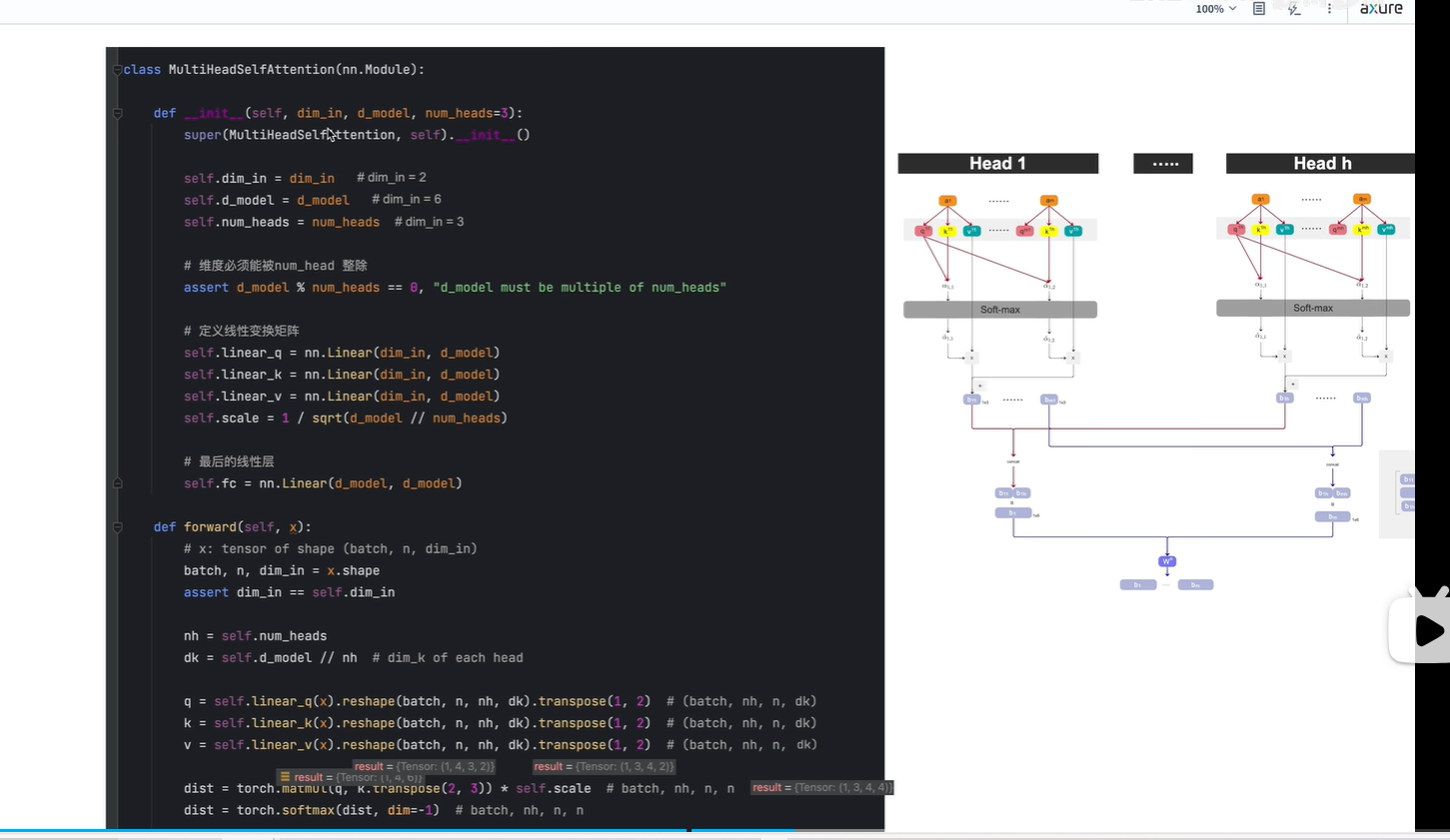
2. 视频2:Multi-Head Attention | 算法 + 代码
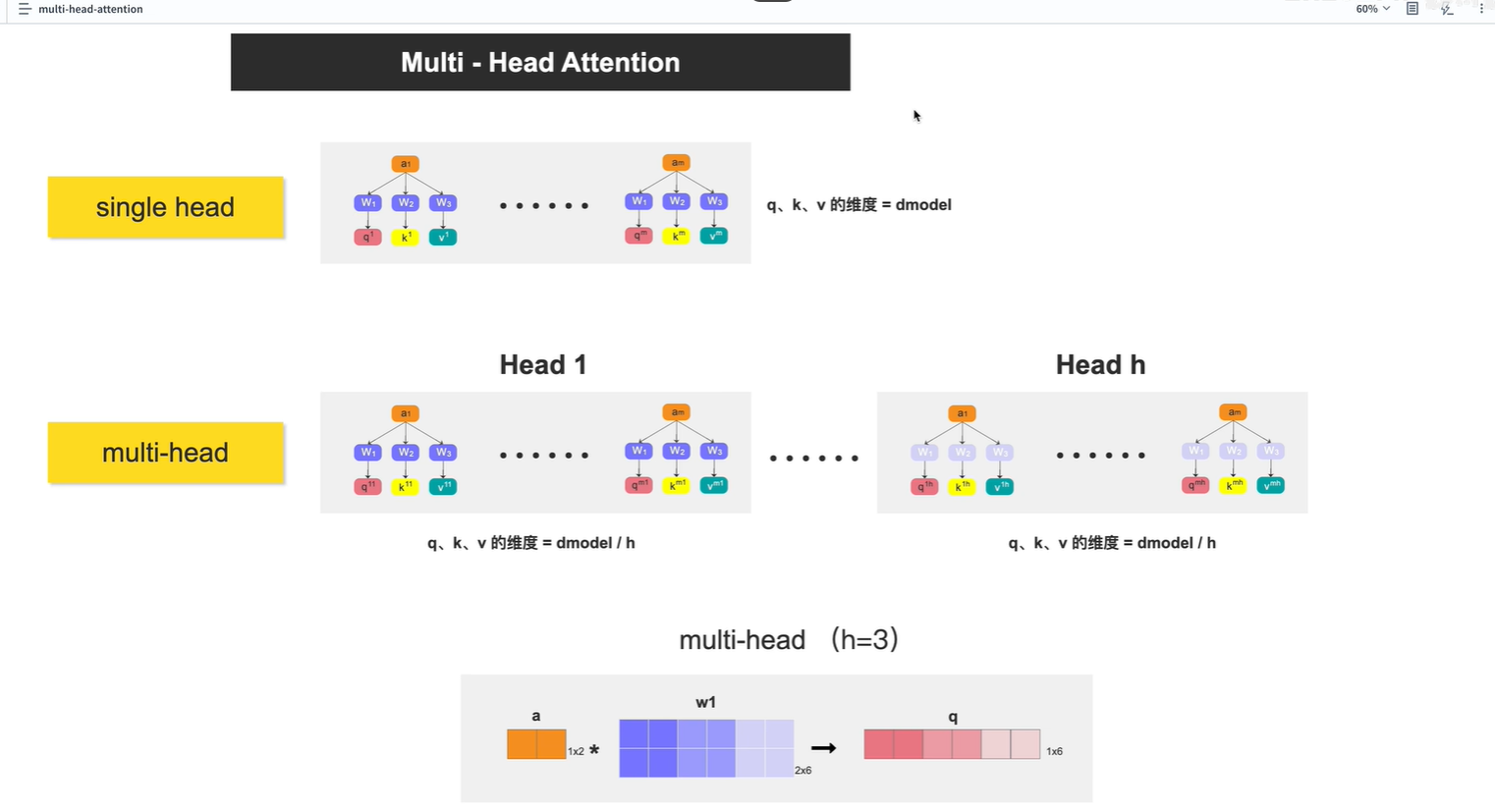
上一节课讲的是 single head
这节课将multi-head, 其中 h表示head的个数
讲了 几种q,k,v的计算方法
方法1:见上个图片,w1 2x6 分成三份(每份 2x2),分别与ai相乘,分别生成三份q,每个q 1x2
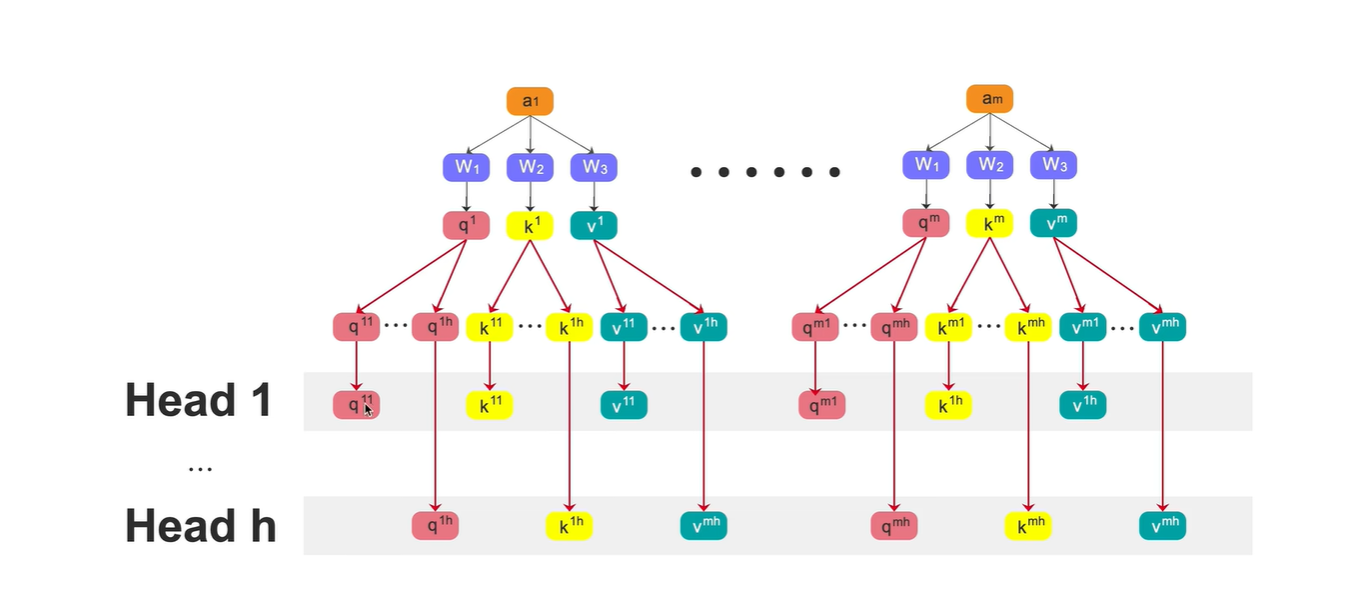
方法2:先使用统一的权重, 生成q,k,v, 然后再将q,k,v, 分别切分多个 ,如q切分为q1,q2,q3,q4,q5。
形成多个head
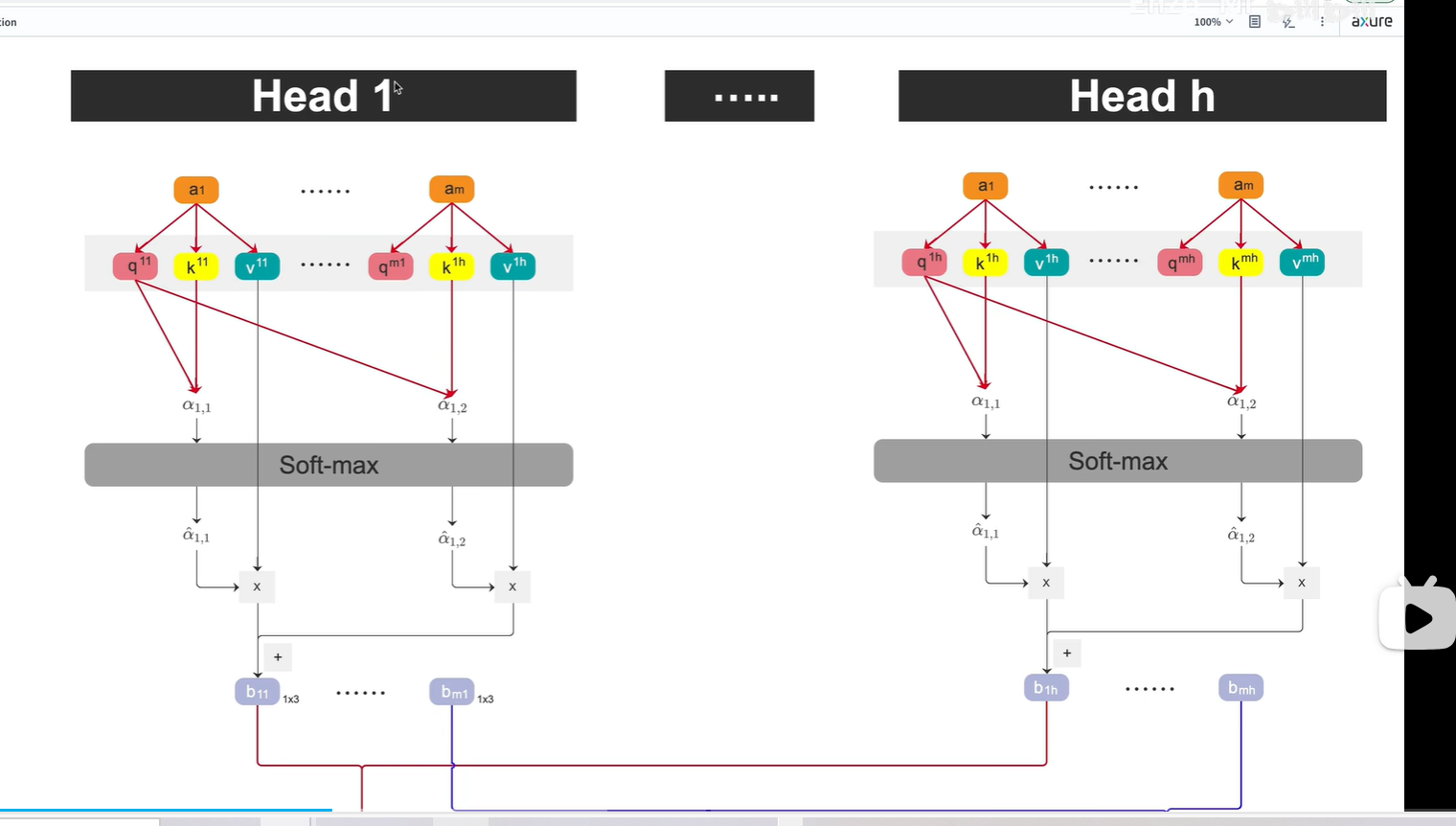
对于每个head,向上一节课那样,分别生成b1,b2...bm
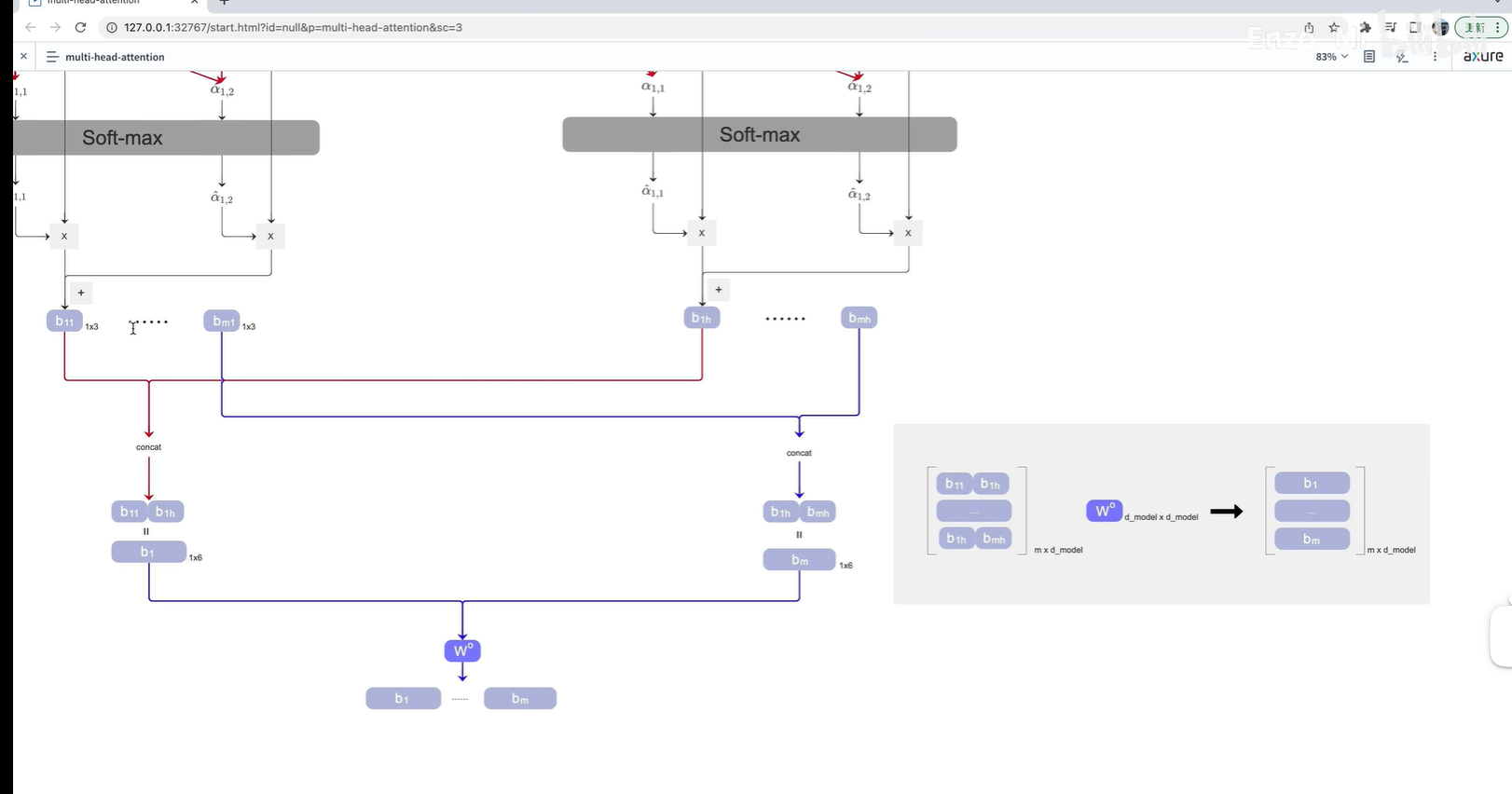 将得到的b先按列concat, 再按行concat, 得到一个mxd 的矩阵
将得到的b先按列concat, 再按行concat, 得到一个mxd 的矩阵
m表示token的个数;d表示每一个token的维度
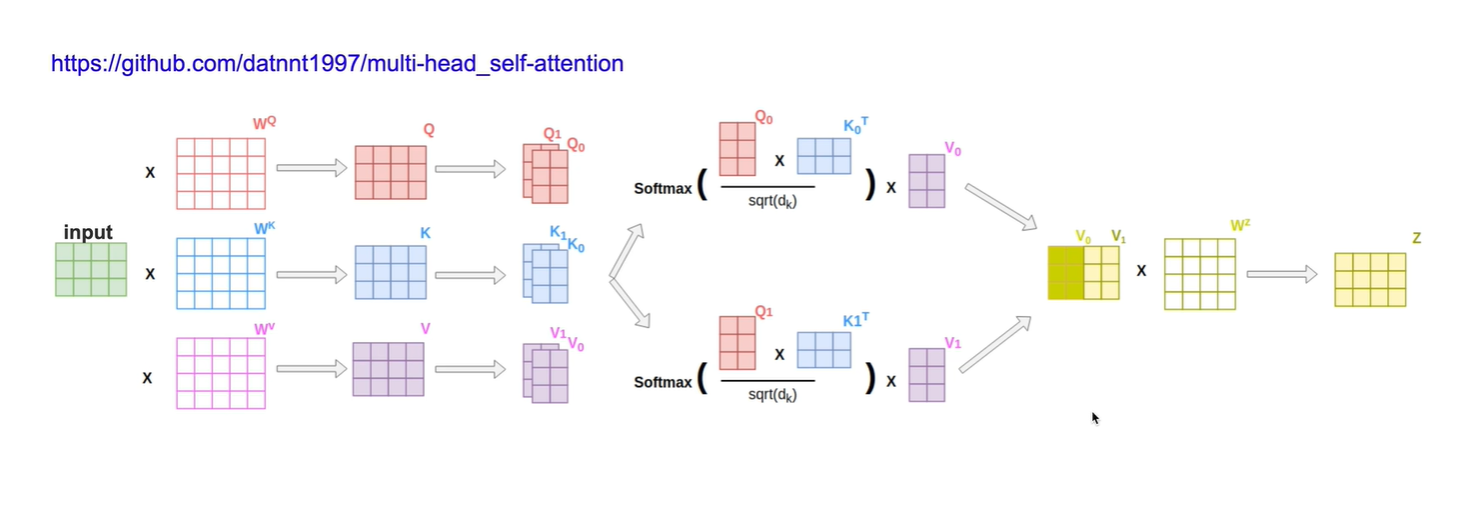
代码实现
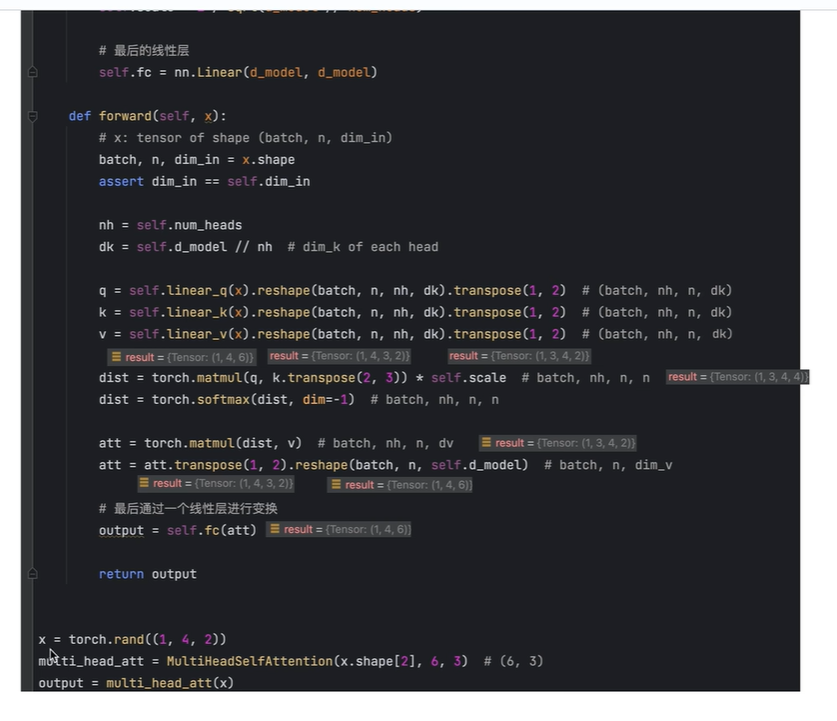
首先定义一个x, (1,4,2)
1表示batch size
4表示token个数
2表示token

实例化一个类,传入三个参数
第一个参数:dim_in表示输入中每个token的维度(即输入x的最后一个维度)
第二个参数:d_model表示如果使用single self-attention 时,qkv总的向量长度
第三个参数:num_heads表示指定head的个数

指定qkv的总向量长度为6;指定一共有3个head;
所以每个head的维度等于 6/3=2,
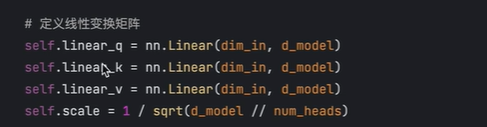
定义三个全连接层,分别从输入x中提取qkv

表示每个head的维度 dk

从三个全连接层分别提取q,k,v
提取的qkv的维度等于d_model 即6, (1,4,6)
将其reshape, 将6拆分为3x2
(1,4,3,2)
3表示3个head
将3进行移动,得到
(1,3,4,2)
4,2表示每个head的qkv的维度,
此时即可以对每个head进行并行处理

第一行表示:
q乘以k的转置,再除以根号下dk, 得到相似度分数
(个人:这里感觉自已听得有问题,没有完全理解)

对dist的最后一个维度做softmax, 然后乘以v 得到b

将b的维度调整为(1,4,3,2)
4表示4个token
3表示3个head
2表示每个b的维度
再将(1,4,3,2)reshape成 (1,4,6)
b最后维度为6
再将b经过全连接层,得到最终结果 ,最终结果的维度也是(1,4,6)
个人:
听得比较迷糊
本来是想听听这个,看看能否理解YOLO11里面的PSA, 还是没有搞懂
参考资料:
1.self-Attention|自注意力机制 |位置编码 | 理论 + 代码_哔哩哔哩_bilibili
2.Multi-Head Attention | 算法 + 代码_哔哩哔哩_bilibili