AI实践:Pydantic
Pydantic
Pydantic是一个用于数据解析和验证的 Python 库,它基于 Python 的类型提示系统,能有效确保数据符合预期的格式和类型。
简单数据模型定义
from pydantic import BaseModelclass User(BaseModel):name: strage: intemail: strtry:user1 = User(name="Alice", age=30, email="alice@example.com")print(user1)user2 = User(name="Bob", age="twenty", email="bob@example.com")
except ValueError as e:print(f"验证错误: {e}")
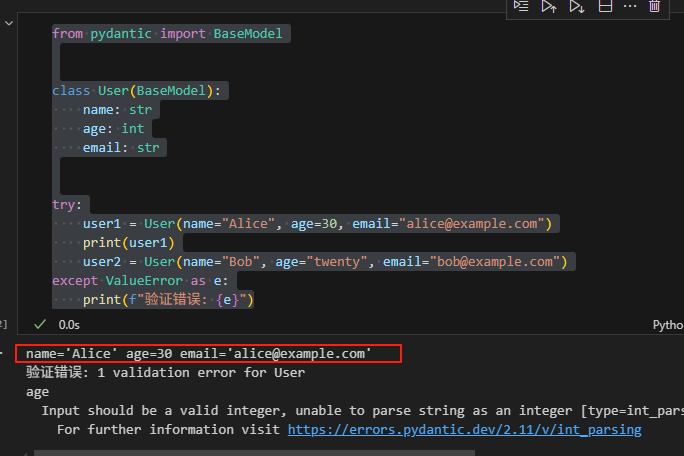
定义了一个User类,它继承自BaseModel。User类有三个属性:name(字符串类型)、age(整数类型)和email(字符串类型)。这些属性的类型声明是 Pydantic 进行数据验证的基础。
创建user1实例时,传入的数据符合定义的类型,所以实例化成功。而在创建user2实例时,age传入的是字符串"twenty",不符合整数类型的要求,因此会引发ValueError。
访问模型属性
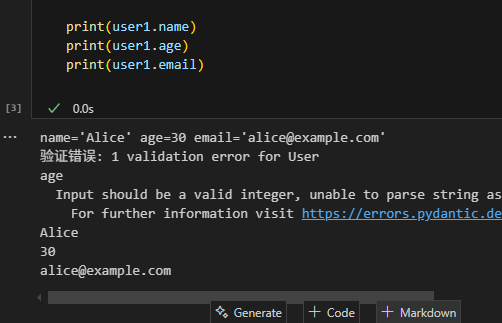
from pydantic import BaseModelclass User(BaseModel):name: strage: intemail: strtry:user1 = User(name="Alice", age=30, email="alice@example.com")print(user1)user2 = User(name="Bob", age="twenty", email="bob@example.com")
except ValueError as e:print(f"验证错误: {e}")print(user1.name)
print(user1.age)
print(user1.email)
模型转换为字典
from pydantic import BaseModelclass User(BaseModel):name: strage: intemail: strtry:user1 = User(name="Alice", age=30, email="alice@example.com")print(user1)print("---------------")
except ValueError as e:print(f"验证错误: {e}")user_dict = user1.dict()
print(user_dict)
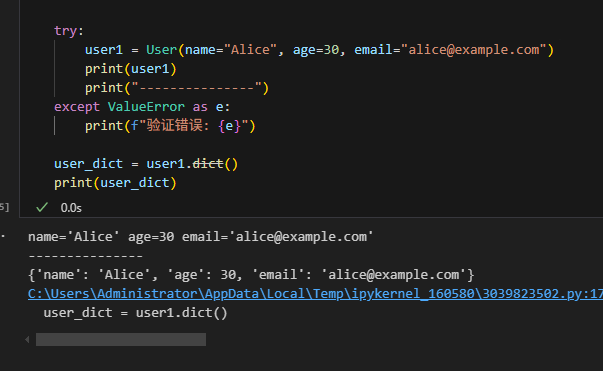
dict()方法将 Pydantic 模型实例转换为 Python 字典,方便数据的进一步处理,如存储到数据库或作为 API 响应返回。
模型转换为 JSON 字符串
import json
from pydantic import BaseModelclass User(BaseModel):name: strage: intemail: struser1 = User(name="Alice", age=30, email="alice@example.com")
user_json = user1.model_json_schema()
print(json.dumps(user_json))
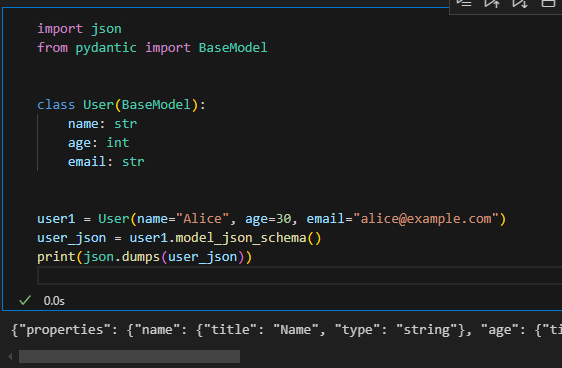
model_json_schema()是pydantic中BaseModel类实例的方法,它返回一个字典,该字典描述了这个数据模型的 JSON 模式(JSON Schema)。JSON 模式是一种用于定义 JSON 数据结构的格式、类型、约束等的标准。例如,对于User模型,它会描述name是字符串类型,age是整数类型等信息。
可选字段
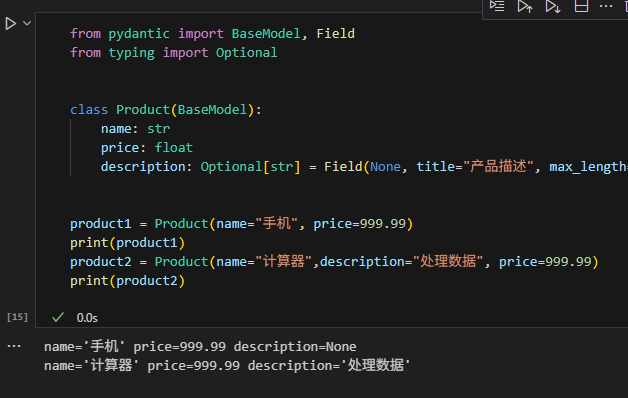
from pydantic import BaseModel, Field
from typing import Optionalclass Product(BaseModel):name: strprice: floatdescription: Optional[str] = Field(None, title="产品描述", max_length=200)product1 = Product(name="手机", price=999.99)
print(product1)
product2 = Product(name="计算器",description="处理数据", price=999.99)
print(product2)
古诗词小能手
import os
from langchain.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplateos.environ['OPENAI_API_KEY'] = os.getenv("DASHSCOPE_API_KEY")
os.environ['OPENAI_BASE_URL'] = "https://dashscope.aliyuncs.com/compatible-mode/v1"llm = ChatOpenAI(temperature=0, model_name='qwen-plus')# 定义系统消息模板
system_template = "你是一位古诗词小能手,根据用户输入的关键词,输出相关的古诗词诗句。请按照以下格式输出:{format_instructions}"# 这里假设 format_instructions 是某种格式化指令,比如 "诗句:<诗句内容>"
format_instructions = "诗句:<诗句内容>"prompt_template = ChatPromptTemplate.from_messages([("system", system_template), ("user", "{text}")]
)keyword = "春天"
prompt = prompt_template.format_prompt(text=keyword, format_instructions=format_instructions)
messages = prompt.to_messages()
response = llm.invoke(messages)
print(response.content)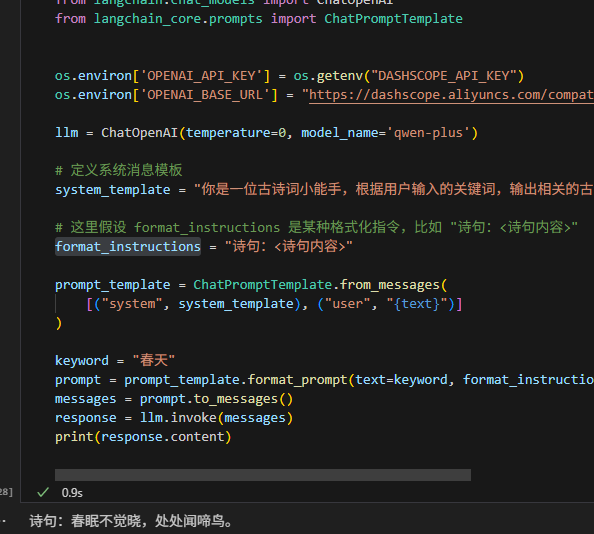
使用pydantic
import os
from langchain.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModelclass AncientPoetryInfo(BaseModel):verse: strauthor: strpoem_title: strparser = PydanticOutputParser(pydantic_object=AncientPoetryInfo)os.environ['OPENAI_API_KEY'] = os.getenv("DASHSCOPE_API_KEY")
os.environ['OPENAI_BASE_URL'] = "https://dashscope.aliyuncs.com/compatible-mode/v1"llm = ChatOpenAI(temperature=0, model_name='qwen-plus')# 定义系统消息模板
system_template = "你是一位古诗词小能手,根据用户输入的关键词,输出相关的古诗词诗句。请按照以下格式输出:{format_instructions}"
# 获取格式化指令
format_instructions = parser.get_format_instructions()prompt_template = ChatPromptTemplate.from_messages([("system", system_template), ("user", "{text}")]
)keyword = "春天"
prompt = prompt_template.format_prompt(text=keyword, format_instructions=format_instructions)
messages = prompt.to_messages()
response = llm.invoke(messages)try:poetry_info = parser.parse(response.content)print(poetry_info)
except Exception as e:print(f"解析错误: {e}")
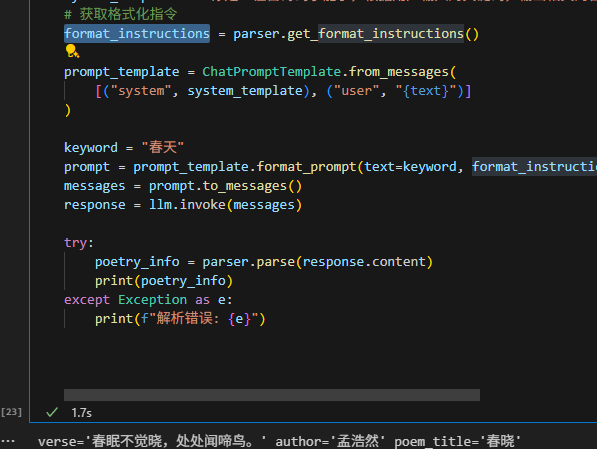
AncientPoetryInfo的 Pydantic 模型,用于表示古诗词的信息,包括诗句(verse)、作者(author)和诗歌标题(poem_title)。
创建一个PydanticOutputParser实例,指定要解析成的 Pydantic 模型为AncientPoetryInfo。这个解析器将用于把模型的输出解析成AncientPoetryInfo对象。
format_instructions通过parser.get_format_instructions()获取,这是解析器生成的格式化指令,用于指导模型输出符合AncientPoetryInfo模型的格式。
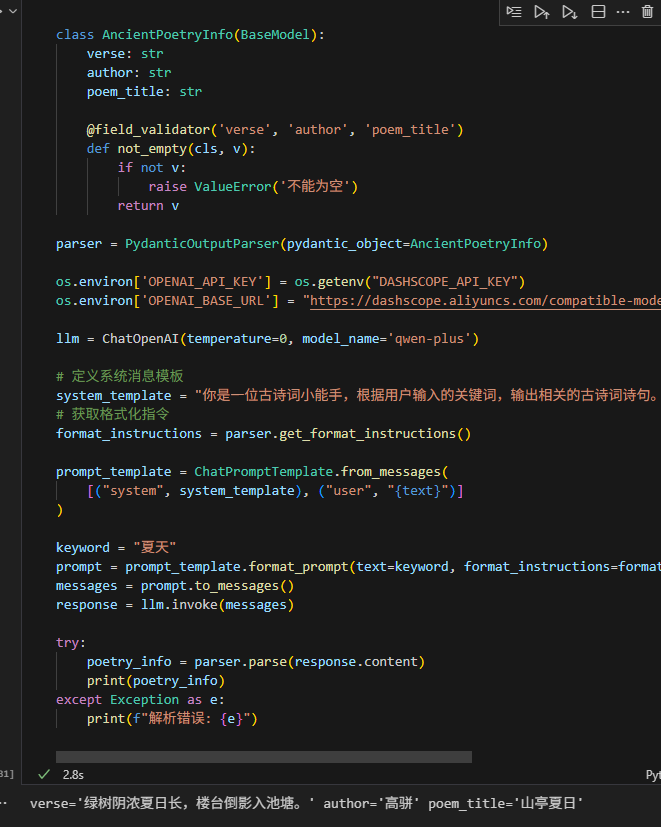
@field_validator
从pydantic库导入BaseModel和field_validator。
定义AncientPoetryInfo类,包含verse、author和poem_title三个字符串类型的字段。
使用@field_validator装饰器来定义验证函数not_empty。这个装饰器接受一个或多个字段名作为参数,表示该验证函数将应用于这些字段。
not_empty函数检查传入的值是否为空,如果为空则抛出ValueError异常,否则返回该值。这样可以确保verse、author和poem_title字段都不为空。
import os
from langchain.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, field_validatorclass AncientPoetryInfo(BaseModel):verse: strauthor: strpoem_title: str@field_validator('verse', 'author', 'poem_title')def not_empty(cls, v):if not v:raise ValueError('不能为空')return vparser = PydanticOutputParser(pydantic_object=AncientPoetryInfo)os.environ['OPENAI_API_KEY'] = os.getenv("DASHSCOPE_API_KEY")
os.environ['OPENAI_BASE_URL'] = "https://dashscope.aliyuncs.com/compatible-mode/v1"llm = ChatOpenAI(temperature=0, model_name='qwen-plus')# 定义系统消息模板
system_template = "你是一位古诗词小能手,根据用户输入的关键词,输出相关的古诗词诗句。请按照以下格式输出:{format_instructions}"
# 获取格式化指令
format_instructions = parser.get_format_instructions()prompt_template = ChatPromptTemplate.from_messages([("system", system_template), ("user", "{text}")]
)keyword = "夏天天"
prompt = prompt_template.format_prompt(text=keyword, format_instructions=format_instructions)
messages = prompt.to_messages()
response = llm.invoke(messages)try:poetry_info = parser.parse(response.content)print(poetry_info)
except Exception as e:print(f"解析错误: {e}")