详述消息队列kafka
1.介绍:
kafka是最初由Linkedin公司开发,是一个分布式、支持分区的、多副本的,给予zookeeper协调的分布式消息系统,它的最大特性就是可以实时的处理大量数据以满足各种需求场景:比如给予Hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等 等,用scala语言编写。Linkedin于2010年贡献给了Apache基金会并称为顶级开源项目。
Kafka的设计哲学源于发布-订阅模型,但其创新性地引入了分布式存储和分区化处理机制,使得系统能够高效处理每秒百万级的消息吞吐。这一特性使其迅速成为现代数据管道(Data Pipeline)和流式处理(Stream Processing)的核心组件。
使用场景:日志收集、消息系统(解耦生产者和消费者)、用户活动追踪(活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析)、运营指标(收集分布式应用的数据)
2.kafka定义:
kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
kafka最新定义:kafka是一个开源的分布式事件流平台,被数千家公司用于高新能数据管道、流分析、数据集成、和关键人物应用
消息队列的应用场景:缓存/消峰、解耦和异步通信
3.MQ定义:
消息队列中间件, MQ通过将消息的发送和接收分离来实现应用程序的异步解耦,这个给人的直觉是MQ是异步的,用来解耦的, 但是这个只是MQ的想法,而不是目的,MQ真正的目的是为了通讯,屏蔽底层复杂的通讯协议,定义了一套应用层的更加简单的通讯协议。MQ所要做的就是在这些协议(http、TCP)之上构建一个简单的“协议”--生产者/消费者模型。
4.消息队列的两种模式:
1.点对点模式(单播消息):消费者主动拉取数据,消息收到后清除数据

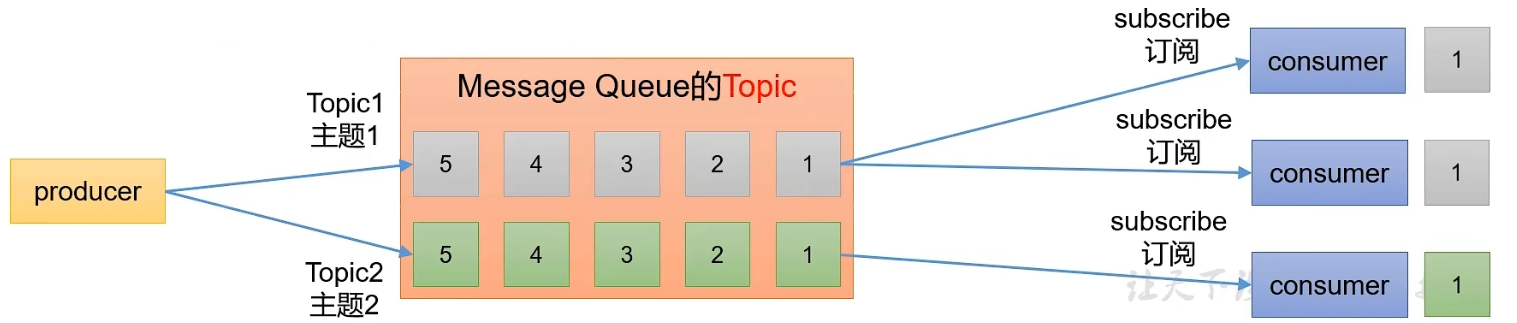
2.发布/订阅模式(多播消息):
- 可以有多个topic主题(浏览、点赞、收藏、评论等)
- 消费者消费数据之后,不删除数据
- 每个消费者相互独立,都可以消费到数据
5.kafka基础架构:
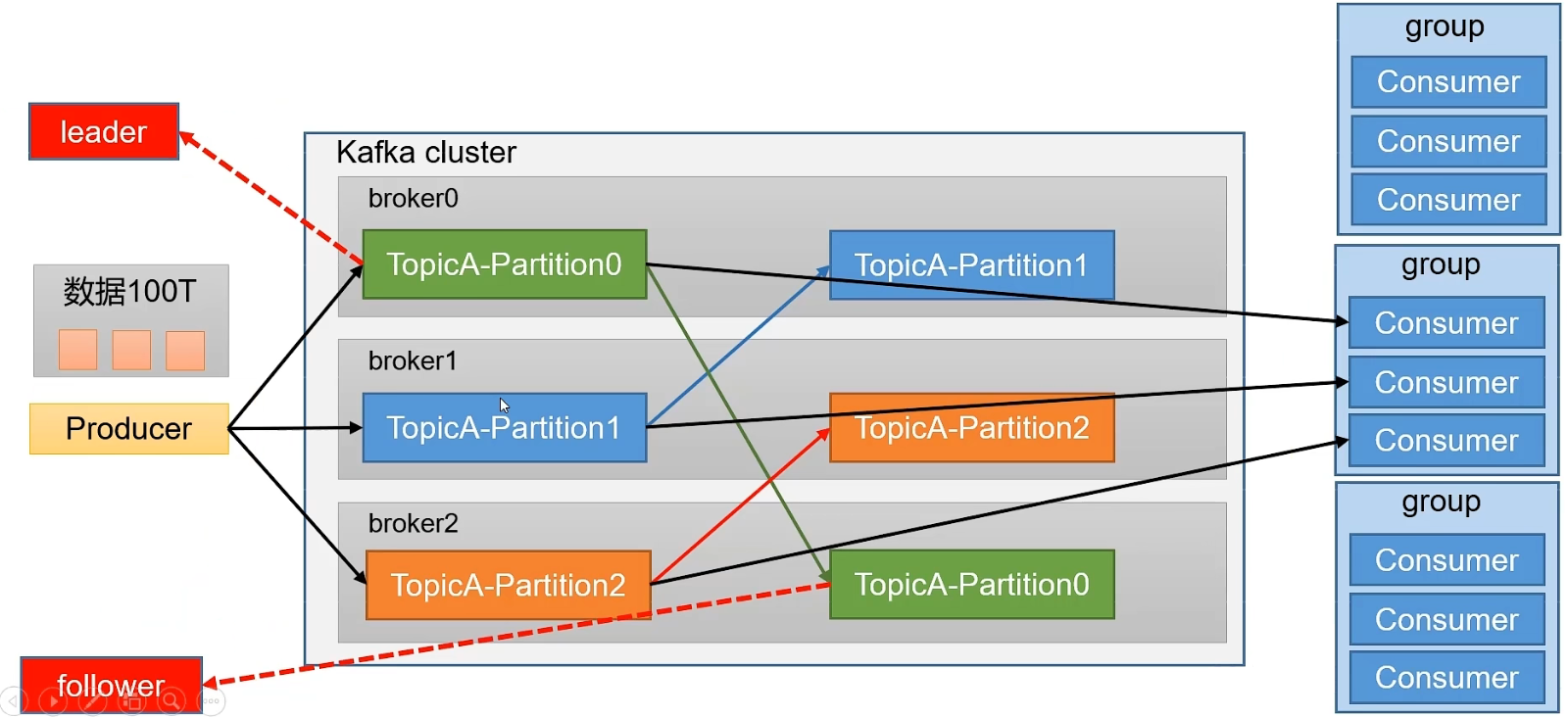
为方便扩展,并提高吞吐量,一个topic分为多个partition
配合分区的设计,提出消费者组的概念,组内每个消费者并行消费,但是相同消费组中的消费者,不能同时读取同一分区的数据,会造成数据重复
为提高可用性,为每个partition增加若干副本(备份 )
zookeeper中会进行记录谁是Leader,Kafka2.8.0以后可以配置不采用zookeeper
6.kafka基本概念:
kafka是一个分布式的,分区的消息(官方称之为commit log) 服务,

broker可以理解为就是我们的集群节点,每一个集群节点中通过topic(主题)对数据进行分组,一个broker可以存在多个主题,主题中的数据为了提高读写性,所以对数据分开操作就有了分区,就是将一个主题中的数据分为多个块存放。
主题:主题-topic在kafka中是一个逻辑的概念,kafka通过topic将消息进行分类,不同的topic会被订阅该topic的消费者消费。但是有一个问题,如果说这个topic中的消息非常非常多,多到需要几个T来存储,此时会被保存到log日志文件中的。为了解决这个文件过大的问题,kafka提出了Partition分区的概念。
分区:通过partition将一个topic中的消息分区来存储。这样做的好处是:分区存储,可以解决统一存储文件过大问题,提供了读写的吞吐量:读写可以同时在多个分区中进行
副本:那么为了增加数据的可靠性,防止数据丢失,会给数据做一个备份称之为副本,副本分为两种:Leader和follower,无论是生产者还是消费者,都只会去操作Leader。
7.kafka应用:
Kafka是一个开源的高吞吐量的分布式消息中间件,对比于其他
1、缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
2、解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
3、冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
4、健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
5、异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
6、实时流处理:用户行为追踪、实时推荐、日志收集:集中式日志系统、事件源:微服务间的事件驱动架构、消息队列:系统解耦、削峰填谷、Metrics收集:监控数据聚合
8.Kafka的特点与优势
1.高吞吐量与低延迟
Kafka通过批处理、顺序磁盘I/O和零拷贝技术(Zero-Copy)优化数据传输效率。生产者(Producer)将消息批量发送至Broker,消费者(Consumer)按顺序拉取数据,避免了传统消息系统的频繁网络交互。实测中,单台Broker可轻松支持每秒数十万条消息的读写。
2. 水平扩展与容错性
Kafka集群由多个Broker(服务器节点)组成,支持动态扩容。每个主题(Topic)被划分为多个分区(Partition),分区可分布在不同Broker上,通过多副本(Replica)机制实现数据冗余。若某Broker宕机,其他副本会自动接管服务,确保系统的高可用性。
3. 持久化存储与回溯消费
消息在Kafka中默认保留7天(可配置为永久存储),消费者可随时重置偏移量(Offset)以重新消费历史数据。这一特性在数据重放、故障恢复等场景中至关重要。
4. 生态兼容性
Kafka与主流大数据工具(如Spark、Flink、Hadoop)深度集成,并提供了Connect API和Streams API,支持构建端到端的流处理管道。
9.什么是Zookeeper?
Zookeeper是一个高性能、高可靠的分布式协调服务,最初由雅虎开发,是Google Chubby的开源实现。它被广泛应用于分布式系统中,用于解决分布式应用中的协调问题,如配置管理、服务注册与发现、分布式锁等。Zookeeper的设计目标是封装复杂且容易出错的关键服务,为分布式应用提供简单易用的接口。
10.Zookeeper的应用场景
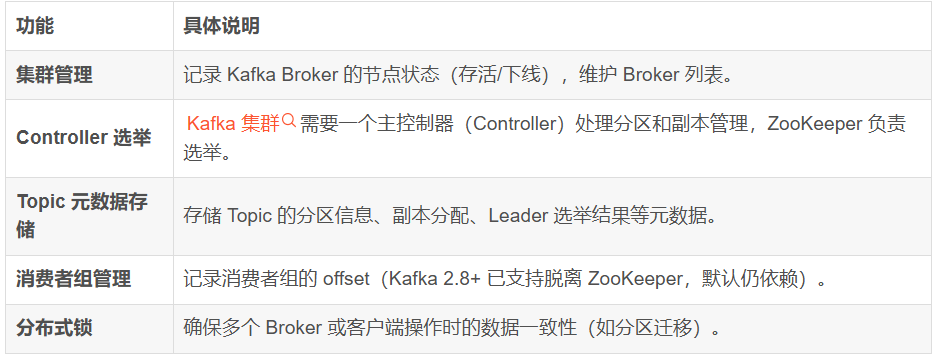
Zookeeper在分布式系统中扮演着重要的角色,其典型应用场景包括:
配置管理:Zookeeper可以作为分布式系统的配置中心,集中管理配置信息,确保所有节点能够获取到最新的配置。
服务注册与发现:分布式系统中的服务可以通过Zookeeper进行注册,客户端可以通过查询Zookeeper来发现所需服务。
分布式锁:Zookeeper提供了一种实现分布式锁的机制,确保多个节点对共享资源的访问是互斥的。
集群管理:Zookeeper能够监控集群中节点的状态,及时发现并处理节点故障。
消息队列:Zookeeper可以用于实现分布式消息队列中的协调功能。
11.Zookeeper核心特性
顺序一致性:客户端的更新操作按照其发送的顺序被应用到Zookeeper上,确保了操作的顺序性。
原子性:所有对Zookeeper的操作都是原子的,要么全部成功,要么全部失败。
单一系统映像:无论Zookeeper集群中有多少节点,客户端看到的都是一个单一的、一致的视图。
可靠性:Zookeeper通过副本机制和选举算法确保系统的高可用性。
实时性:Zookeeper能够实时监控节点的状态变化,并及时通知客户端。
12.ZooKeeper 的作用
13.SpringBoot整合Kafka:
1.导入依赖:
<!--kafka-->
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.7.1</version>
</dependency>2.编写pom.xml
# Kafka 相关配置kafka:# Kafka 服务器地址bootstrap-servers: 192.168.142.131:9092# 生产者配置producer:# 序列化器,用于将键转换为字节key-serializer: org.apache.kafka.common.serialization.StringSerializer# 序列化器,用于将值转换为字节value-serializer: org.apache.kafka.common.serialization.StringSerializer# 消费者配置consumer:# 消费者组ID,用于区分不同的消费者组group-id: my-application-group# 自动偏移量重置策略,当没有初始偏移量时从最早的偏移量开始消费auto-offset-reset: earliest# 禁用自动提交功能enable-auto-commit: false# 反序列化器,用于将字节转换为键key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 反序列化器,用于将字节转换为值value-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 配置监听器的确认模式为手动立即确认listener:ack-mode: manual_immediate# 主题配置topic:default: default-topicmanual: manual-commit-topic3.kafka消息生产者:
package com.lw.mqdemo.mq.kafka;import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;/*** Kafka消息生产者服务类*/
@Service
public class KafkaProducerService {//kafka的引入private final KafkaTemplate<String, String> kafkaTemplate;public KafkaProducerService(KafkaTemplate<String, String> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}/*** 发送消息到指定主题* @param topic 主题名称* @param message 消息内容*/public void sendMessage(String topic, String message) {kafkaTemplate.send(topic, message);}/*** 发送消息到指定主题和分区* @param topic 主题名称* @param partition 分区号* @param key 消息键* @param message 消息内容*/public void sendMessage(String topic, Integer partition, String key, String message) {kafkaTemplate.send(topic, partition, key, message);}
}4.kafka消息消费者:
package com.lw.mqdemo.mq.kafka;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;/*** Kafka 消费者服务*/
@Service
public class KafkaConsumerService {/*** 监听指定主题的消息(自动提交)* @param message 消息内容*/@KafkaListener(topics = "${spring.kafka.topic.default}", groupId = "${spring.kafka.consumer.group-id}")public void consumeAutoCommit(String message) {System.out.println("接收到自动提交消息: " + message);// 业务处理逻辑}/*** 监听指定主题的消息(手动提交)* 偏移量(Offset) 是 Kafka 为分区(Partition)中的每条消息分配的唯一序号(从 0 开始递增),用于标识消息在分区中的位置。* @param record 消息记录(包含元数据)* @param ack 确认对象*/@KafkaListener(topics = "${spring.kafka.topic.manual}", groupId = "${spring.kafka.consumer.group-id}")public void consumeManualCommit(ConsumerRecord<String, String> record, Acknowledgment ack) {try {System.out.println("接收到手动提交消息: key=" + record.key() + ", value=" + record.value() + ", topic=" + record.topic() + ", partition=" + record.partition() + ", offset=" + record.offset());// 业务处理逻辑// 手动提交偏移量ack.acknowledge();} catch (Exception e) {// 处理异常,可以选择不提交偏移量以便重试System.err.println("消息处理失败: " + e.getMessage());}}
}5. 测试类:
package com.lw.mqdemo.controller;import com.lw.mqdemo.mq.kafka.KafkaProducerService;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;/*** Kafka 控制器*/
@RestController
@RequestMapping("/api/kafka")
public class KafkaController {private final KafkaProducerService producerService;public KafkaController(KafkaProducerService producerService) {this.producerService = producerService;}/*** 发送消息到指定的Kafka主题*/@PostMapping("/send")public String sendMessage(@RequestParam("topic") String topic,@RequestParam("message") String message) {producerService.sendMessage(topic, message);return "消息已发送到主题: " + topic;}
}