BEVDet-4D 代码详细解析
一、介绍

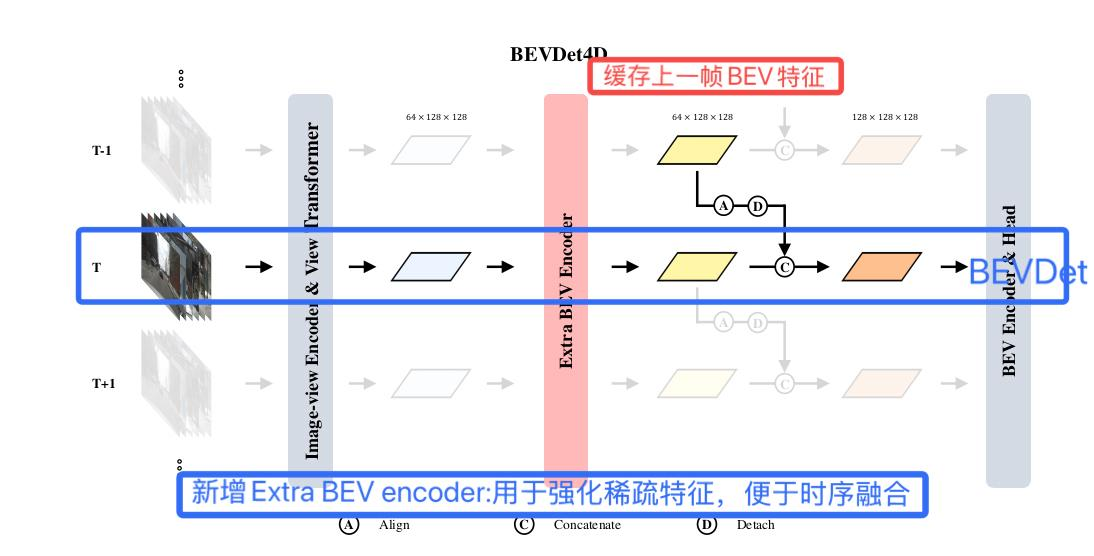
BEVDet4D 由黄俊杰等人发表于22年3月,首次对BEVDet加入时序特征。它通过缓存上一帧的BEV特征,经过空间对齐操作和拼接操作,将上一帧和当前帧中对应特征进行融合。从而极大的减小了速度预测误差。
二、改进点
1. 网络结构改进: 在时间融合前,增加额外的BEV编码器(两个残差单元),用于强化稀疏特征,便于时序融合。
2. 时序融合:Align(对齐) + Concatenate, 融合后能正确反映它车运动特征。
三、时序融合分析
方案1:直接Concatenate
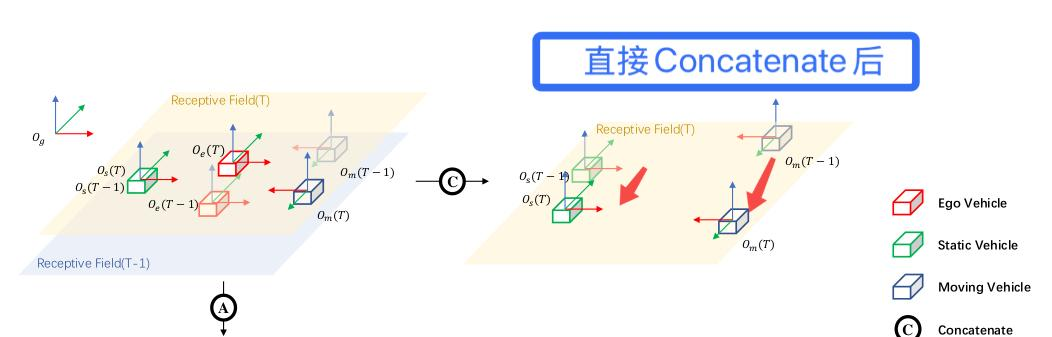
如图2,没有空间特征对齐,在自车坐标系下,自车(红)不动,静止物体(绿)运动,运动物体(蓝)运动更多。
则静止物体ego坐标系下的两帧位移差公式如下:
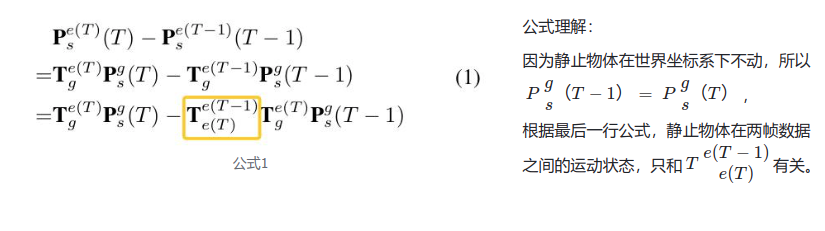
上公式可以看到,如果直接拼接两帧特征,则后续的学习目标只关联自车运动。
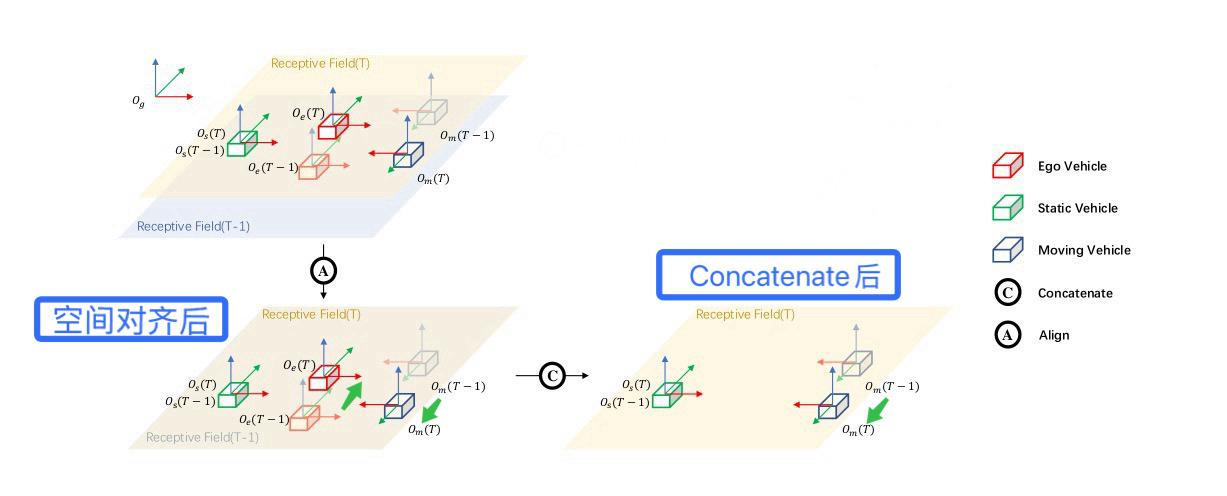
方案2:Align + Concatenate
Align空间对齐: 为了避免方案1情况,把上一帧的BEV特征乘以
的逆来消除自车(ego)运动实现空间对齐,再concat当前帧BEV特征融合。
如下图,对齐后静止车辆不动,运动车辆运动。

四、代码详解
空间对齐代码在shift_featue()中。
#mmdet3d/models/detectors/bevdet.py
def shift_feature(self, input, sensor2keyegos, bda, bda_adj=None):#生成变换网格grid = self.gen_grid(input, sensor2keyegos, bda, bda_adj=bda_adj)#执行特征变换output = F.grid_sample(input, grid.to(input.dtype), align_corners=True)return output #[1, 80, 128, 128]1、建立网格
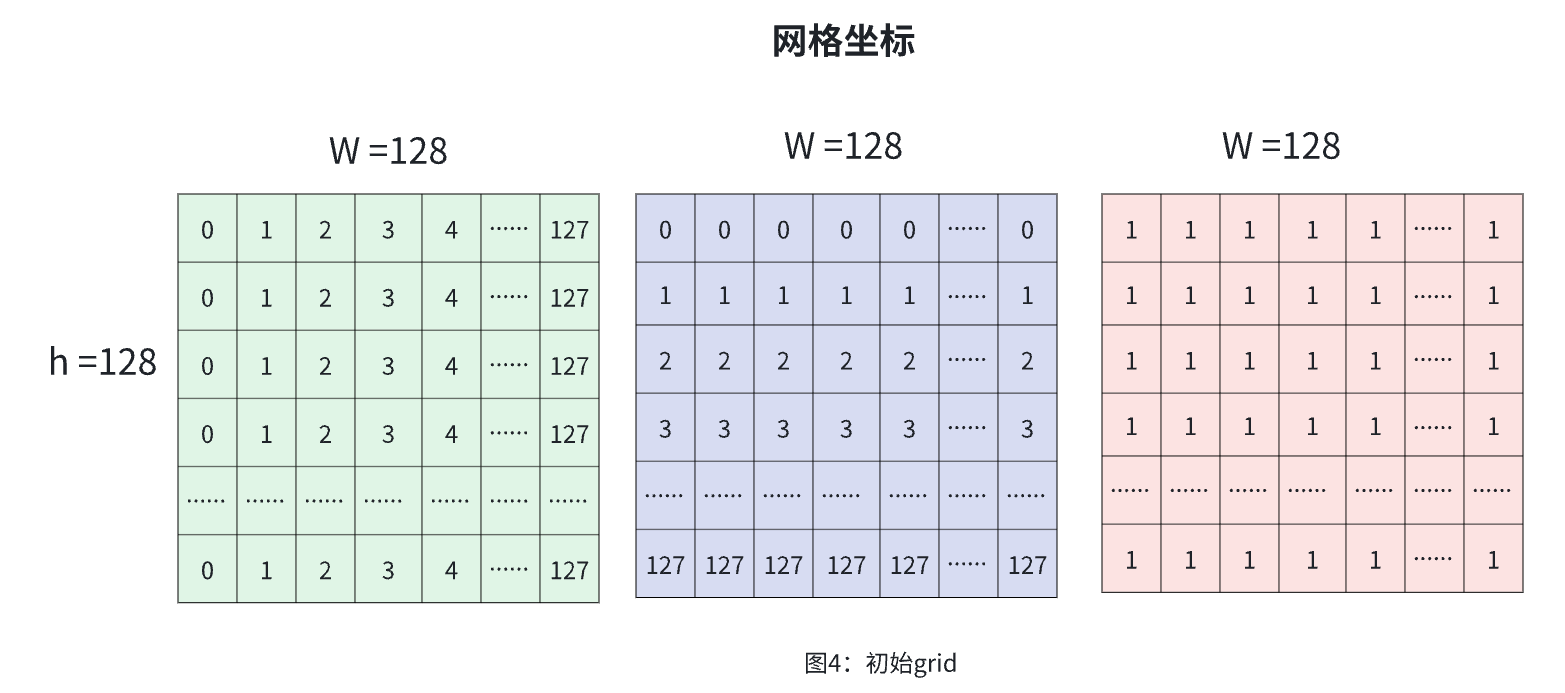
#mmdet3d/models/detectors/bevdet.py
def gen_grid(self, input, sensor2keyegos, bda, bda_adj=None):n, c, h, w = input.shape_, v, _, _ = sensor2keyegos[0].shape #传感器到关键帧的变换矩阵#----------------------------------#-1. 基础网格生成 (n,h,w,3,1):(n,128,128,3,1)#----------------------------------if self.grid is None: #检查是否有缓存网格# generate gridxs = torch.linspace(0, w - 1, w, dtype=input.dtype,device=input.device).view(1, w).expand(h, w) # (0,1,...w-1)^ hys = torch.linspace(0, h - 1, h, dtype=input.dtype,device=input.device).view(h, 1).expand(h, w) #(0,1,...h-1)^ wgrid = torch.stack((xs, ys, torch.ones_like(xs)), -1) #堆叠表示:网格位置(h,w,3)->[x,y,1]self.grid = grid #(128,128,3)else:grid = self.gridgrid = grid.view(1, h, w, 3).expand(n, h, w, 3).view(n, h, w, 3, 1) #(n,128,128,3,1)2. 提取基础变换矩阵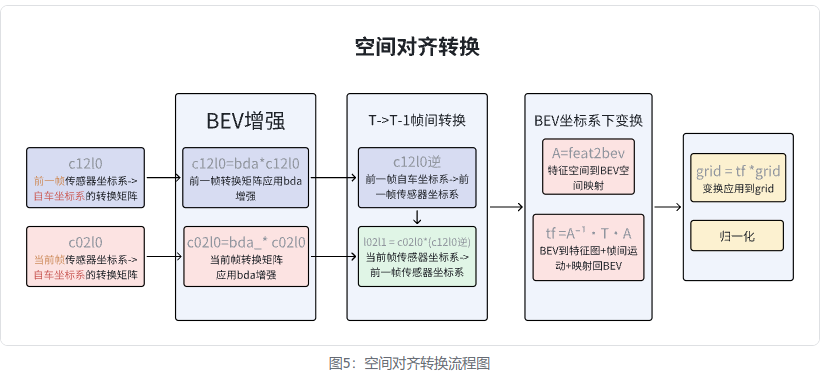

c02l0 = sensor2keyegos[0][:, 0:1, :, :] # 当前帧到关键帧ego坐标系的变换矩阵
c12l0 = sensor2keyegos[1][:, 0:1, :, :] # 前一帧到关键帧ego坐标系的变换矩阵3. BEV增强变换矩阵
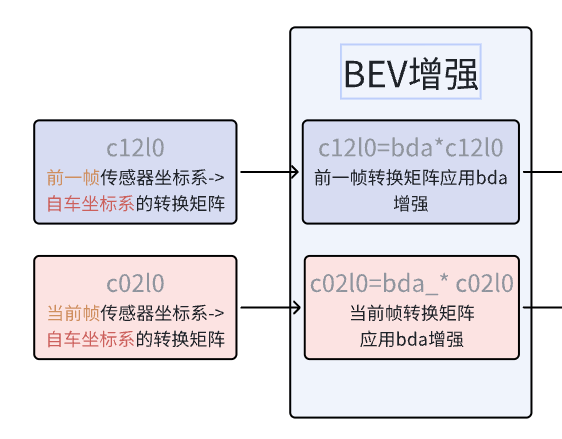
# 处理当前帧的BEV数据增强(bda)bda_ = torch.zeros((n, 1, 4, 4), dtype=grid.dtype).to(grid) #(n, 1, 4, 4)bda = bda.unsqueeze(1) #[n,3,3] ->[n,1,3,3]bda_[:, :, :4, :4] = bda #将3x3bda旋转、缩放矩阵放入左上角bda_[:, :, 3, 3] = 1 #设置齐次坐标缩放因子为1(仿射变换)c02l0 = bda_.matmul(c02l0) #当前帧转换矩阵应用bda增强# 处理相邻帧的BEV数据增强(bda_adj)if bda_adj is not None:bda_ = torch.zeros((n, 1, 4, 4), dtype=grid.dtype).to(grid)bda_[:, :, :3, :3] = bda_adj.unsqueeze(1)bda_[:, :, 3, 3] = 1c12l0 = bda_.matmul(c12l0) #前一帧转换矩阵应用bda增强4. T->T-1帧间变换矩阵
以关键帧ego坐标系为中介,计算当前帧到前一帧的变换矩阵。
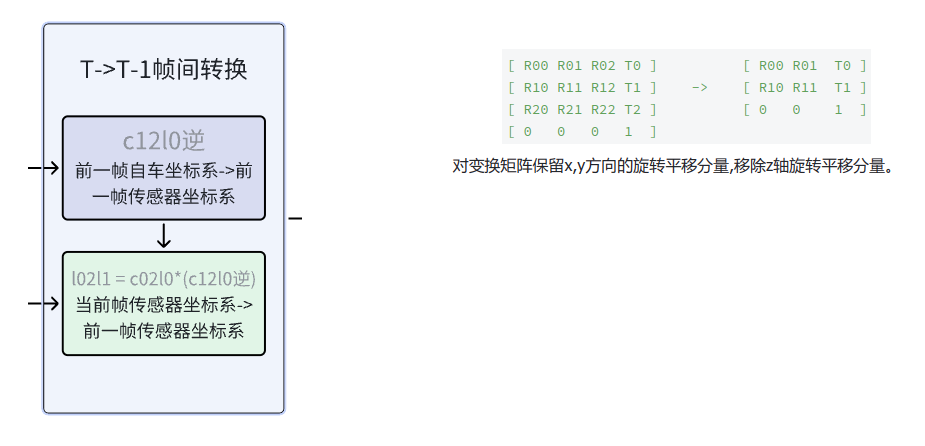
# 核心公式: l02l1 = c02l0 * inv(c12l0)l02l1 = c02l0.matmul(torch.inverse(c12l0))[:, 0, :, :].view(n, 1, 1, 4, 4)# 通过关键帧坐标系做中介,计算当前帧到相邻帧的变换矩阵# 当前帧传感器坐标系->关键帧自车坐标系->关键帧车体坐标系->前一帧传感器坐标系 '''c02l0 * inv(c12l0)= c02l0 * inv(l12l0 * c12l1)= c02l0 * inv(c12l1) * inv(l12l0)= l02l1 # c02l0==c12l1'''l02l1 = l02l1[:, :, :,[True, True, False, True], :][:, :, :, :,[True, True, False, True]]5. BEV 坐标系下的帧间变换(tf)
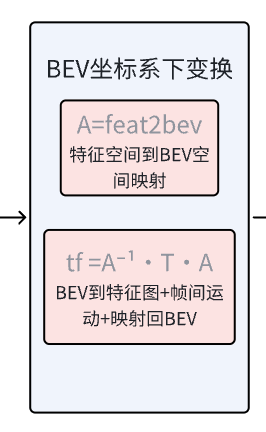

#----------------------------------#-3. 特征图到BEV空间变换#----------------------------------#grid_interval:[0.8, 0.8, 8] grid_lower_bound:[-51.2, -51.2, -5]feat2bev = torch.zeros((3, 3), dtype=grid.dtype).to(grid)feat2bev[0, 0] = self.img_view_transformer.grid_interval[0] #x方向缩放因子:0.8feat2bev[1, 1] = self.img_view_transformer.grid_interval[1] #y方向缩放因子:0.8feat2bev[0, 2] = self.img_view_transformer.grid_lower_bound[0] #x方向偏移:51.2feat2bev[1, 2] = self.img_view_transformer.grid_lower_bound[1] #y方向偏移:51.2feat2bev[2, 2] = 1 #齐次坐标feat2bev = feat2bev.view(1, 3, 3) #(1,3,3)# 组合变换矩阵tf = torch.inverse(feat2bev).matmul(l02l1).matmul(feat2bev) #(n,1,1,4,4)# BEV空间坐标到点特征图像像素变换 * 当前帧到相邻帧的自车坐标系变换矩阵 * 点从特征图像像素坐标到BEV空间坐标6. 将变换应用到grid 并归一化
grid = tf.matmul(grid) #变换矩阵应用到基础网格上 (n,h,w,3,1)normalize_factor = torch.tensor([w - 1.0, h - 1.0],dtype=input.dtype,device=input.device) #[127,127]grid = grid[:, :, :, :2, 0] / normalize_factor.view(1, 1, 1,2) * 2.0 - 1.0#只保留x,y坐标(忽略z轴),移除最后一维(n,h,w,2) /[127,127] * 2 -1 # 归一化到[-1,1]:(0,0)左上角,(w-1,h-1)右下角 变换后(-1,-1)左上角, (1,1)右下角五、性能:
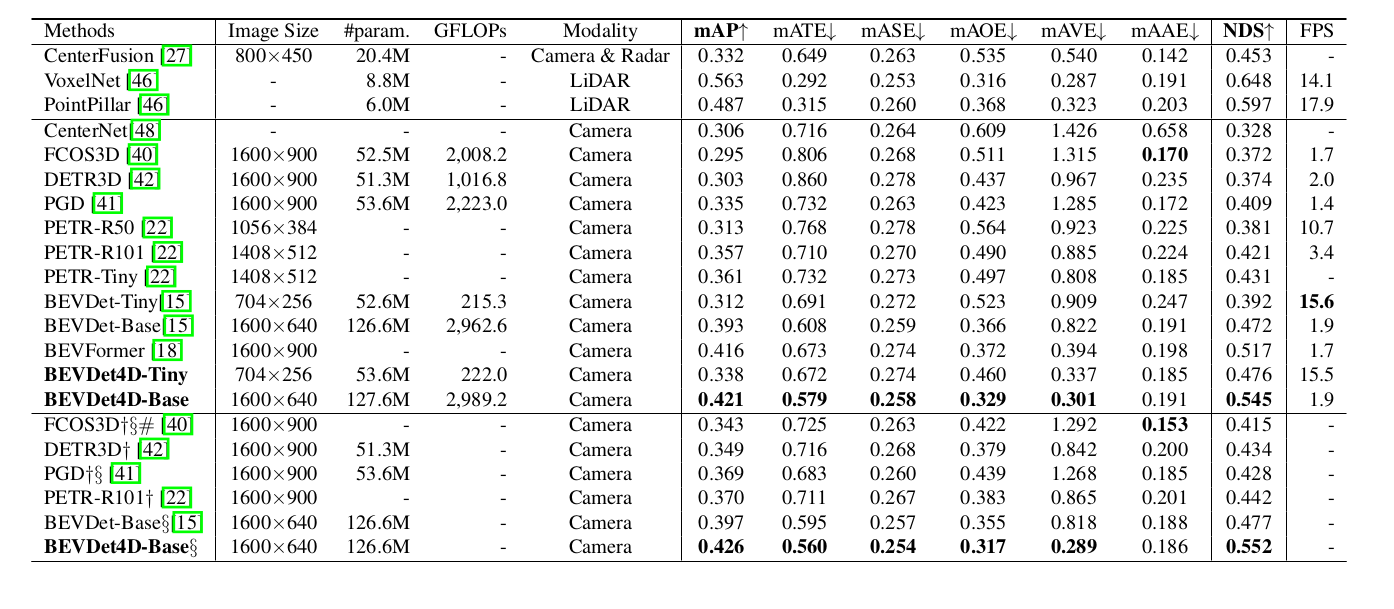
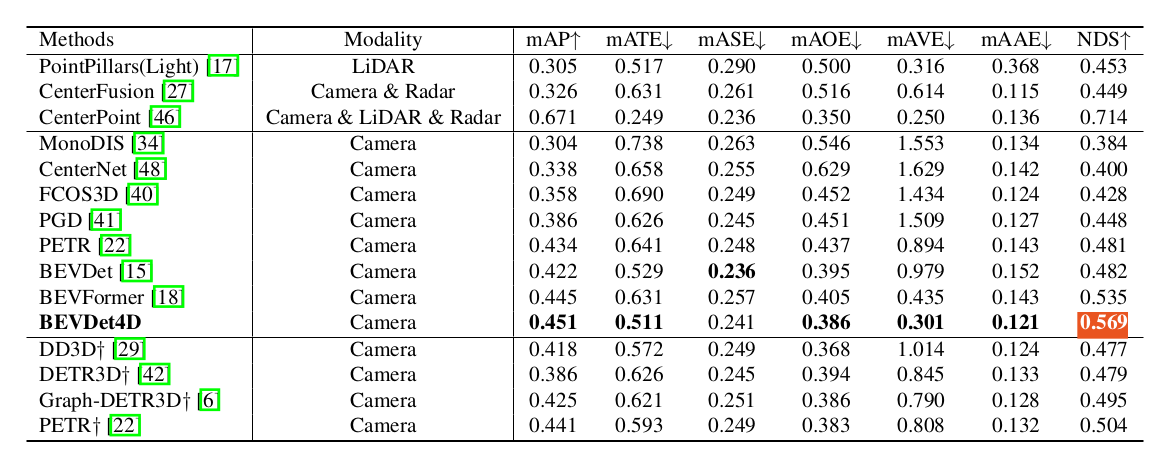
BEVDet4D