Linux修炼:进程概念(上)
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路!
我的博客:<但凡.
我的专栏:《编程之路》、《数据结构与算法之美》、《C++修炼之路》、《Linux修炼:终端之内 洞悉真理》、《Git 完全手册:从入门到团队协作实战》
感谢你打开这篇博客!希望这篇博客能为你带来帮助,也欢迎一起交流探讨,共同成长。

目录
1、冯诺依曼体系
1.1、冯诺依曼体系的概念
1.2、核心组成部分
1.3、工作原理
1.4、主要特点
2、操作系统
3、进程
3.1、什么是进程
3.2、 task_struct
3.3、进程深入理解
1、冯诺依曼体系
1.1、冯诺依曼体系的概念
冯诺依曼体系(Von Neumann Architecture)是由美籍匈牙利数学家约翰·冯·诺依曼在1945年提出的计算机系统设计框架。这一体系结构奠定了现代计算机的基本设计模式,至今仍被广泛采用。
1.2、核心组成部分
冯诺依曼体系主要包括五个核心部分:
- 运算器(ALU):负责算术和逻辑运算。
- 控制器(Control Unit):协调计算机各部件的工作。
- 存储器(Memory):存储程序和数据。
- 输入设备(Input Device):接收外部数据或指令。
- 输出设备(Output Device):将计算结果反馈给用户。
我们分别来介绍一下这几个部分。
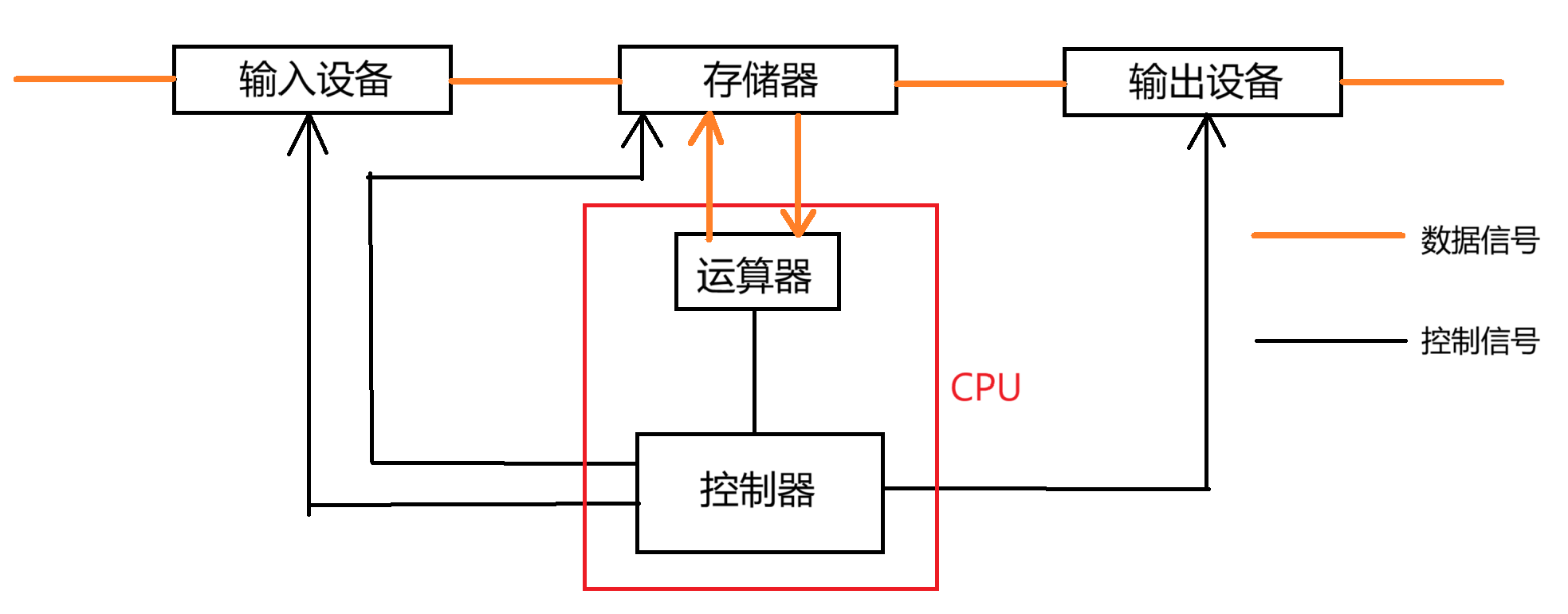
输入设备包括键盘,鼠标,摄像头,磁盘网卡...输出设备包括显示器,印象,磁盘,网卡,打印机。磁盘网卡既可以是输入设备也可以是输出设备。存储器包括主存储器和辅助存储器,主存储器是内存,直接与CPU交互,辅助存储器长期保存数据,一般是硬盘和SSD。
我们的CPU只和存储器打交道,他不会直接和输出和输出设备打交道。因为CPU的速度是非常快的,输出和输入设备都很慢。内存的本质就是外设和CPU的缓存,计算机的效率以内存的速度为主。
距离CPU越远,速度越慢效率越低,但是存储单元成本更低,距离CPU越近,存储单元成本越贵。
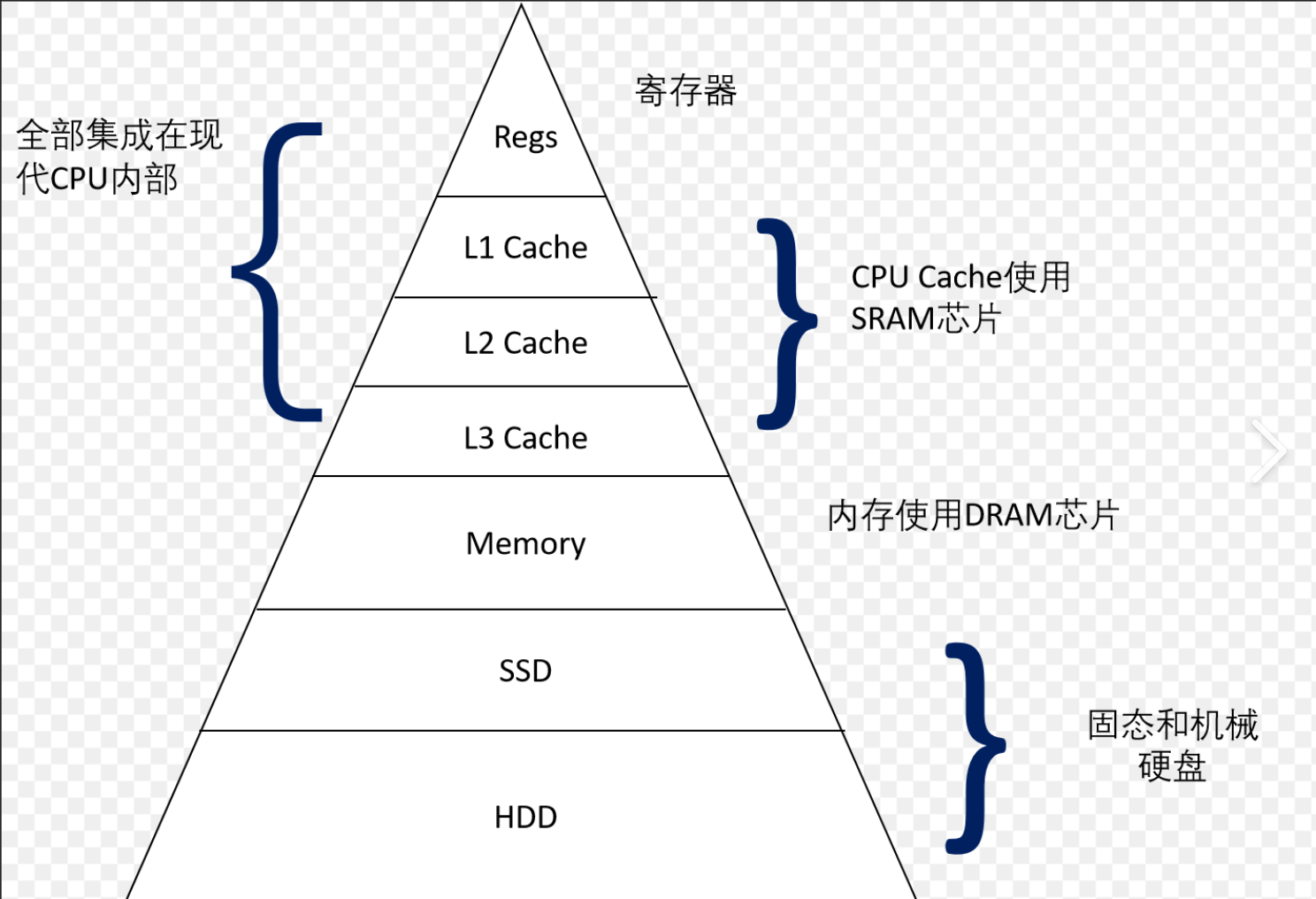
我们之前提到的IO,本质上就是外设和内存进行数据交换。所以说IO的速度很慢,这也就解释了B树的其中一个意义。大量数据的查找,我们可以利用B树减少IO的次数,从而提高效率。数据交换的本质其实就是拷贝。
我们编程处理的范围,就是从键盘,输入数据到存储器,存储器交给CPU计算,计算完之后把数据输出到输出设备。
1.3、工作原理
冯诺依曼体系的核心思想是“存储程序控制”:
- 程序和数据以二进制形式存储在同一个存储器中。
- 控制器按顺序从存储器中读取指令并执行,通过运算器处理数据。
- 输入输出设备与外部交互,完成信息传递。
1.4、主要特点
- 二进制编码:指令和数据均以二进制形式表示。
- 顺序执行:指令按存储在内存中的顺序依次执行(可通过跳转指令改变流程)。
- 存储程序:程序可像数据一样修改,实现灵活的控制逻辑。
尽管现代计算机在性能、并行化等方面大幅改进,但基本仍遵循冯诺依曼体系。后续发展如哈佛架构(分离指令与数据存储)等变体,也在特定领域(如嵌入式系统)中得到应用。
2、操作系统
操作系统是一款软硬件资源管理的软件。它是计算机系统的核心,负责协调硬件、软件及用户之间的交互。
之前我们简单介绍过操作系统,现在我们再深入理解一点点。
我们广义操作系统指管理计算机硬件与软件资源的系统软件,不仅包括传统操作系统内核,还涵盖中间件、运行时环境、虚拟化平台等扩展组件。其核心目标是提供统一的资源抽象和管理机制,支持多样化应用场景。而狭义的操作系统仅仅指的是操作系统内核。接下来我们提到的操作系统,都指的是狭义的操作系统。 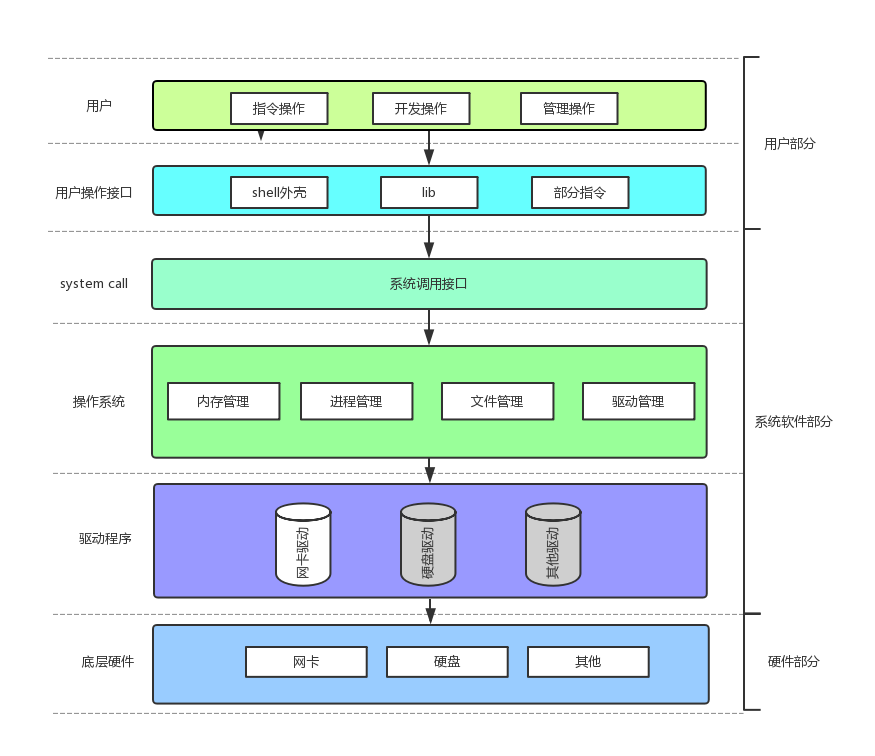
以上是一个较完整的计算机组成体系。软硬件体系本质是层状的。底层硬件部分值得就是我们的冯诺依曼体系。往上走首先是驱动程序。驱动大家都不陌生,我们windows系统设置里面能找到键盘驱动,鼠标驱动等的设置。我们想要使用一个输入/输出硬件,就需要有对应的驱动和他匹配。当然了,一些重要的驱动程序电脑都是自带的,我们不需要手动安装。
再往上走,就是操作系统。操作系统的主要功能就是图中的内存管理,进程管理,文件管理,驱动管理。操作系统的存在就是为了给用户提供一个良好的稳定的运行环境。
操作系统对于数据的管理,都是先描述,再组织,这种思想就像我们之前学过的C++或者其他语言中的类一样,面向对象的思想把数据分块,然后用stl容器把数据都组织起来。 操作系统的内部存在大量的数据结构,数据结构中存储着“描述”好的一块块数据。
接下来我们看一下用户部分。用户想使用操作系统,需要通过系统调用,也就是system call。但是用户直接使用系统调用太难了,所以说再往上又设计了一层用户操作接口(抽象接口层),比如Shell外壳程序,编程语言中的各种库。用户通过指令,语言,调用用户操作接口,用户操作结构再去调用系统,实现对操作系统的使用。
再往上,就是由各种语言编写的各种APP,像什么抖音,快手之类的。
操作系统是计算机功能的基石,直接影响性能、安全性和用户体验。它抽象了硬件复杂性,使开发者能专注于应用逻辑,同时为多任务、多用户环境提供支持。
3、进程
3.1、什么是进程
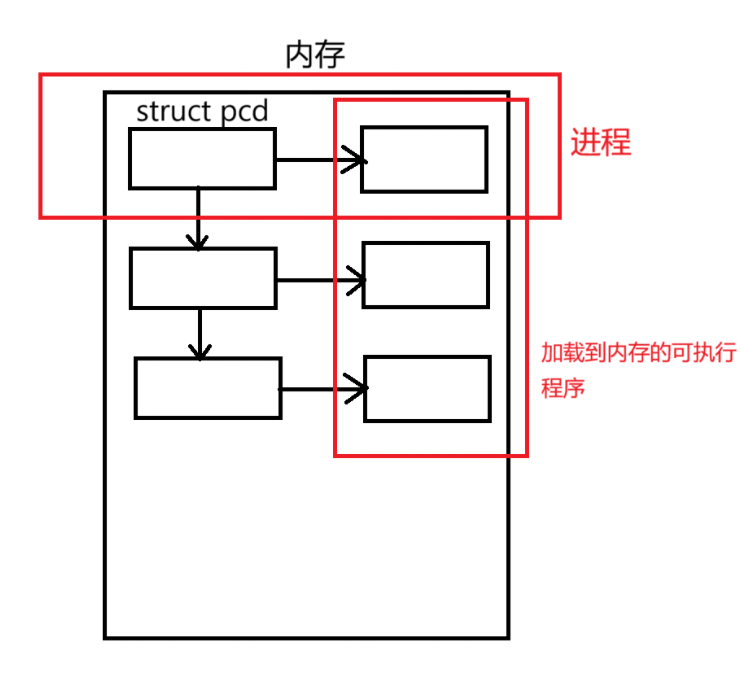
进程是操作系统分配资源的基本单位,由程序代码、相关数据和进程控制块(PCB)组成。PCB是内核维护的关键数据结构,用于存储进程的元信息和控制信息,包括进程标识符(PID)、内存地址空间、寄存器状态、打开文件列表等。
当可执行程序被加载到内存时,操作系统会为其创建对应的PCB。PCB与内存中的代码段、数据段共同构成完整的进程实体。PCB作为进程存在的唯一标识,使操作系统能够有效地管理和调度多个并发执行的进程。
进程与程序的区别在于动态性:程序是静态的指令集合,而进程是程序在特定数据集上的动态执行过程,具有生命周期和状态变化。操作系统通过PCB实现进程的创建、切换、通信和终止等核心功能。
3.2、 task_struct
上面我们的进程控制块是对于操作系统理论来说的,而task_struct是进程控制块在Linux系统中的具体实现。
task_struct中包含了以下信息:
标识符:描述本进程的唯一标识符,用来区别其他进程
状态:任务状态,退出代码,退出信号等
优先级:相对于其他进程的优先级。
程序计数器:程序中即将被执行的下一条指令的地址。
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
上下文数据:进程执行是处理器的寄存器中的数据。
IO状态信息:显式的IO请求,分配给进程的IO设备和被进程使用的文件列表。
记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号登。
进程在被执行的过程中,是要被切换,调度的。在这个过程中要进行硬件上下文的保存与恢复,也就是得把寄存器中的内容保存和恢复。我们可以这样简单理解一下,程序执行的时候,数据到保存寄存器中经过一系列处理,程序执行完毕要从寄存器中取出数据。
3.3、进程深入理解
我们在Linux系统中,可以用getpid获得进程的唯一标识符(pid),我们来操作一下:
首先在文件中写入这样一串代码:
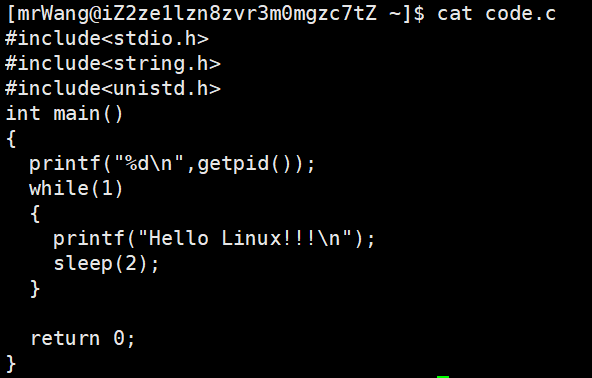
先说一下这个程序,我们首先让他把进程的pid打印出来,同时呢我们不能让这个进程结束,为了方便以后观察,所以直接把他写成了死循环。
我们可以查看proc这个目录来获得当前的进程。
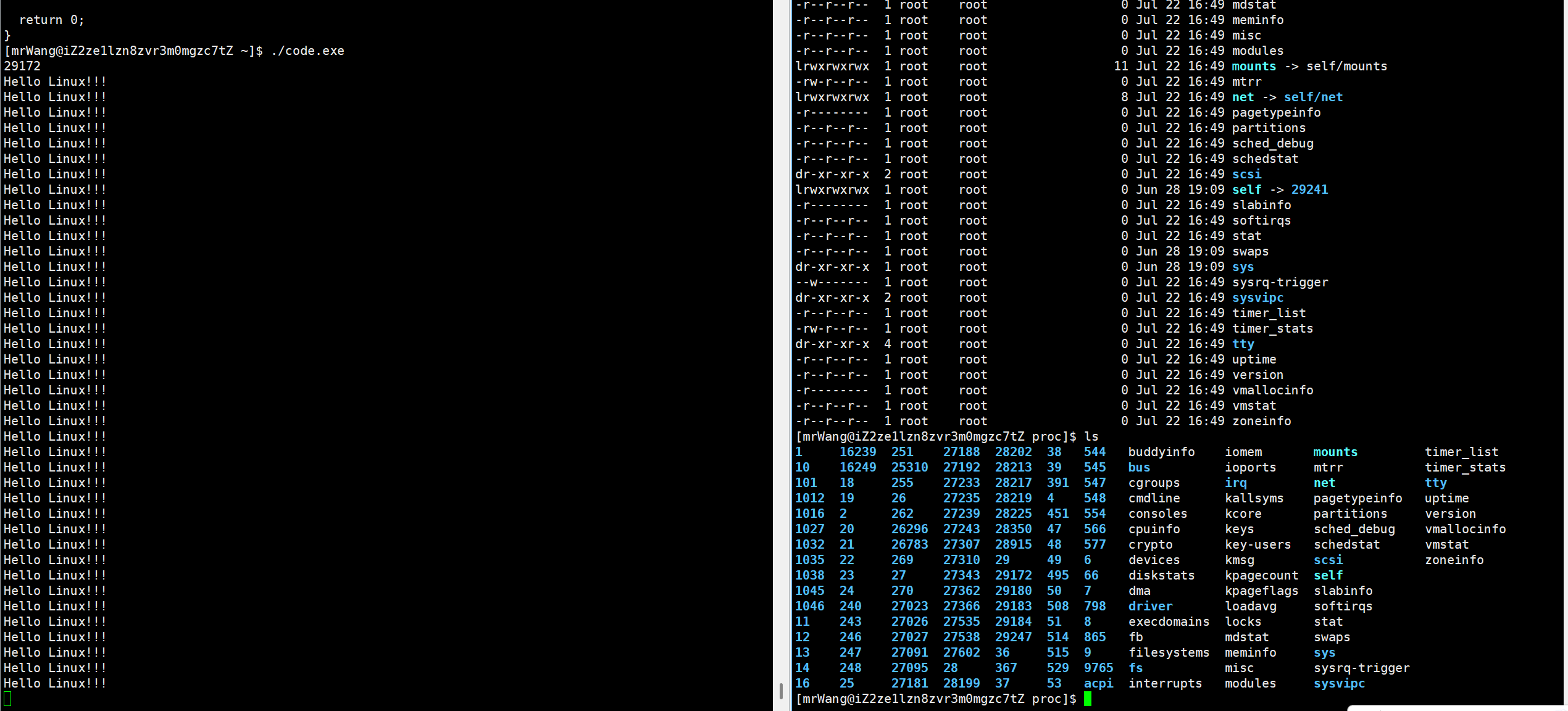
需要注意,每次我们执行同一个可执行文件,他的pid大概率是不一样的。
我们也可以直接查pid,看看这个进程是否存在。其实,每出现一个进程,在proc这个目录中就出现一个以某个数字为名的文件夹。
我们可以查看进程的当前工作路径:
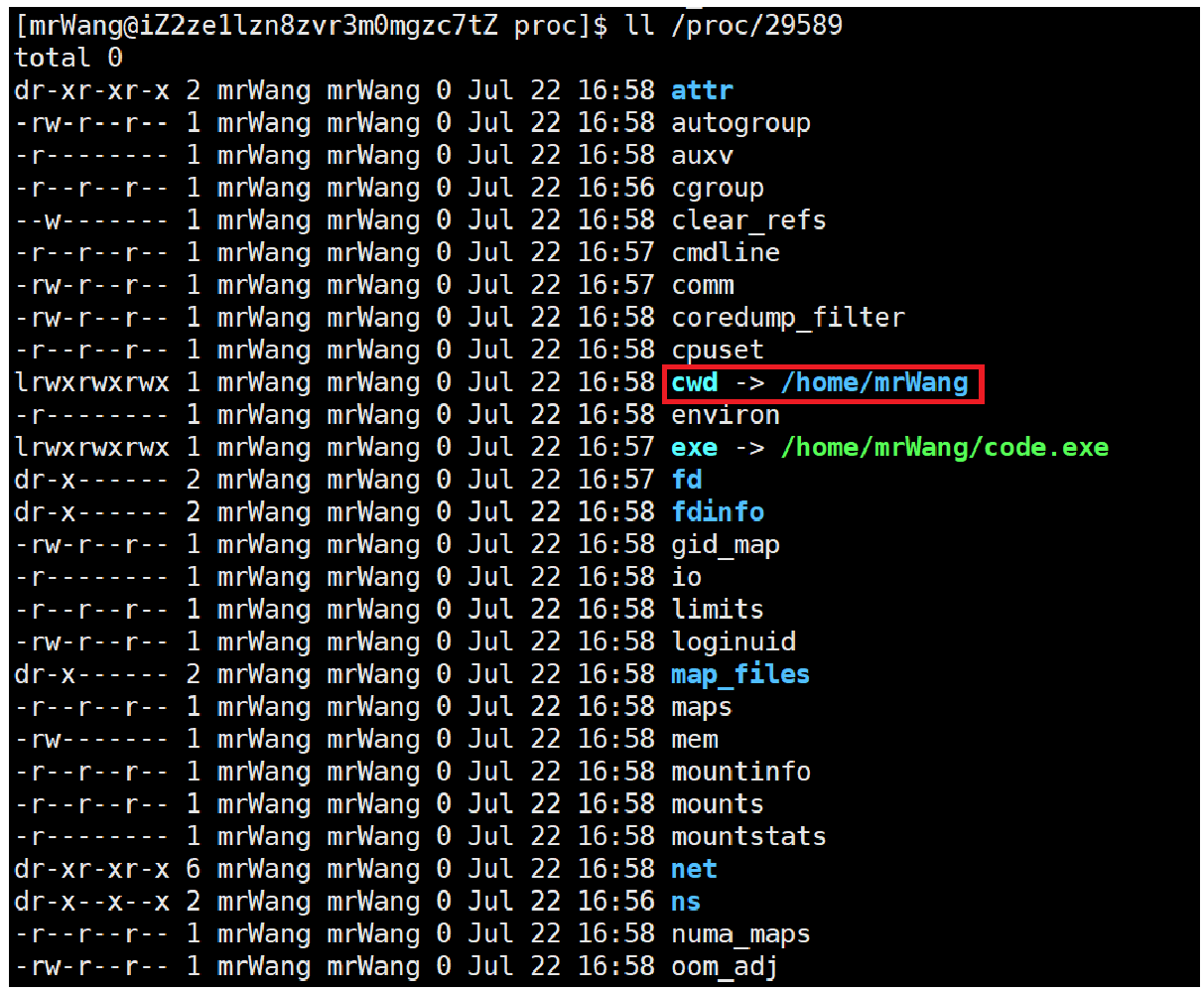
我们可以手动修改这个工作路径:
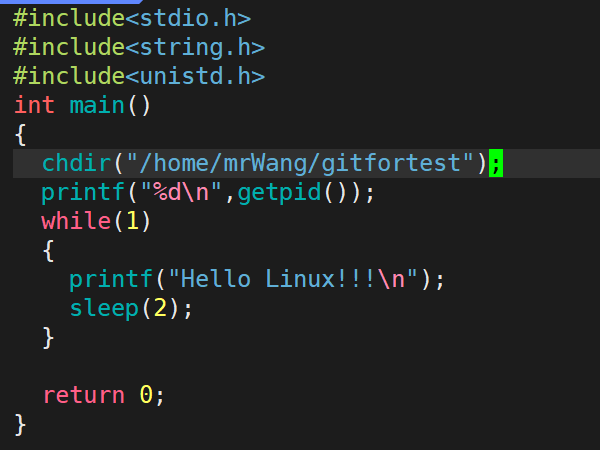
 我们可以根据以下命令看pid:
我们可以根据以下命令看pid:
ps axj | head -1 && ps axj | grep " "双引号中写我们可执行文件的名字。或者不写双引号,写pid。

其中grep也是一个进程,他在过滤的时候把自己也过滤出来了。 如果我们不想显式这个grep我们可以执行以下命令:
ps axj | head -1 && ps axj | grep " " | grep -v grep
#反向匹配每个进程都有父进程,我们同样可以通过打印来看到ppid:
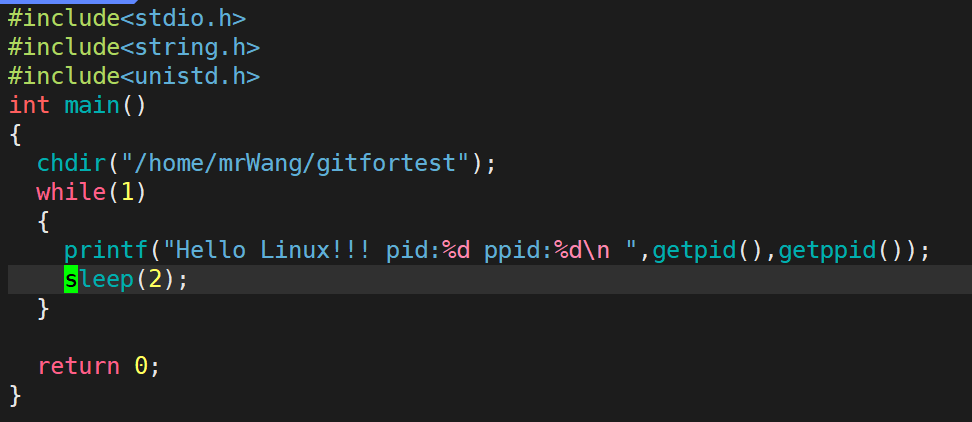
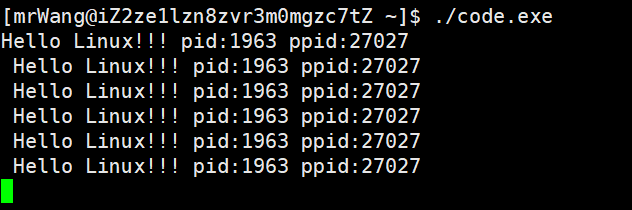
我们重新启动一下code.exe,发现无论启动几次,他的父进程是不变的。 因为这个父进程是bash。

所有的进程启动都是要有父进程的,我们在启动命令、程序的时候,都会变成进程,并且该进程的父进程都是bash。
接下来我们说一下如何创建子进程。
我们可以使用fork创建子进程:
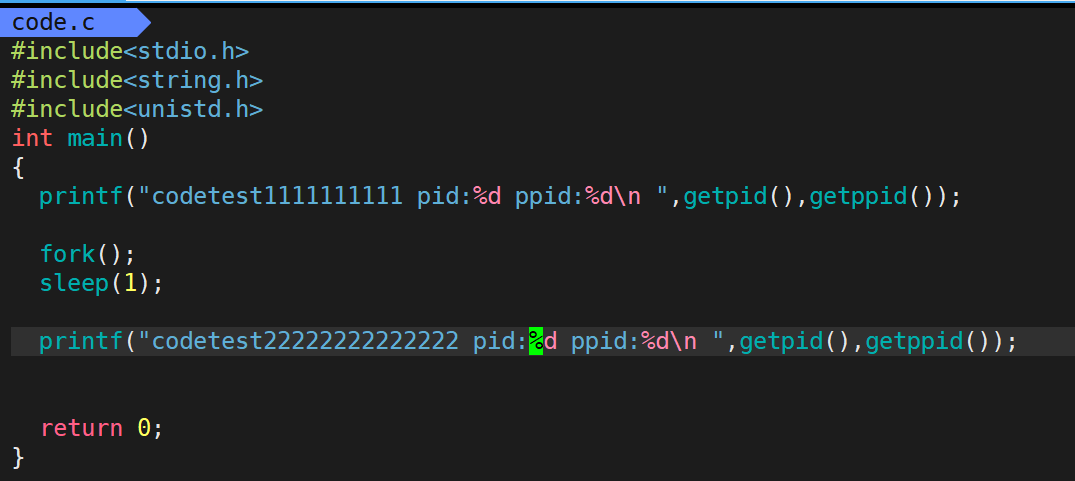

在fork之后,我们创建出了另一个进程(像细胞分裂一样),所以说我们第二条打印语句打印了两次。fork创建出来的是子进程,我们可以观察到,他的父进程是我们原来的进程。
fork其实是有返回值的,当fork成功之后,fork会返回给父进程(我们原来的进程)子进程pid,然后给子进程返回0。返回0是子进程创建成功的标志。我们可以打印看一下:
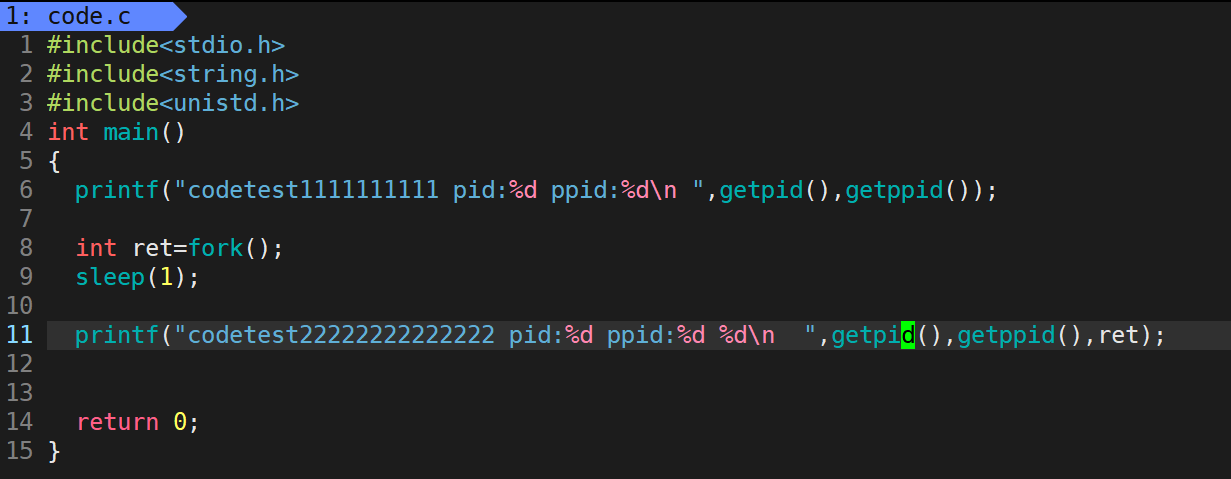

子进程是怎么被创建的呢?首先,子进程会依照父进程的task_struct为模板,初始化出自己的task_struck。但是这个新创建出来的task_struct并没有属于自己的代码和数据。他的代码和数据是和父进程共享的(大概这么理解)。
好了,今天的内容就分享到这,我们下期再见!