神经网络和机器学习的一些基本概念
记录一些基本概念,不涉及公式推导,因为数学不好,记了也没啥用,但是知道一些基本术语以及其中的关系,对神经网络训练有很大帮助。
可能有些概念不会讲得很详细,但是当你有了这个概念,你就知道往这个方向去获取更详细的信息,不至于连往哪走都不知道。
下面以多元线性回归模型为例
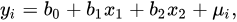
1.模型
模型训练过程就是利用已知的x和y,求解b的过程,b也称为权重。
虽然没有那么简单,但是训练完成的模型本质上就是一组权重值,如
[b1, b2,b2......]
所谓保存模型,就是把这一组值保存到文件中,需要用的时候,再从文件中读取。
正常的模型文件,还会保存训练中用到的训练库信息,优化器信息,损失函数信息等。
2.训练数据,验证数据,测试数据。
训练数据:用于训练模型的数据。
验证数据:可以看做训练数据的一部分,但是不参与模型训练,其主要作用是用于训练过程中调整超参数(如学习率、正则化系数)或选择最佳模型配置,避免过拟合。
验证数据:用于验证模型训练的好坏。
3.参数和超参数
参数:是模型训练中自动调节的参数,即权重b.
超参数:一般指需要人工手动调节的参数,函数等(但是也可以设置自动调节)。常见的超参数是学习率,损失函数,优化器,网络层数,节点数等等。
4.损失函数
模型训练,求解权重,实际上也是求解损失函数的过程。
对于多元线性回归模型,最常用的损失函数就是最小二乘法。
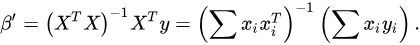
在不同模型训练时,损失函数有很多种选择。
损失函数的含义就是找到一组值(权重),使得预测值和实际值之间的距离最小。
当损失函数越小,代表预测值和实际值越接近,