Elasticsearch 字段值过长导致索引报错问题排查与解决经验总结
在最近使用 Elasticsearch 的过程中,我遇到了一个 字段值过长导致索引失败 的问题。经过排查和多次尝试,最终通过设置字段 "index": false 方式解决。本文将从问题现象、排查过程、问题分析、解决方案和建议等方面,详细记录这次踩坑经验。
如下图所示:

1.原因解释:
你在保存文档时,fieldOvyryf 字段的值(可能是一个超长字符串,比如大 JSON、大文本块等)经过 UTF-8 编码后,字节数达到了 61506;
但是 Elasticsearch 对单个字段的最大字节长度限制是 32766,超过就会报错。
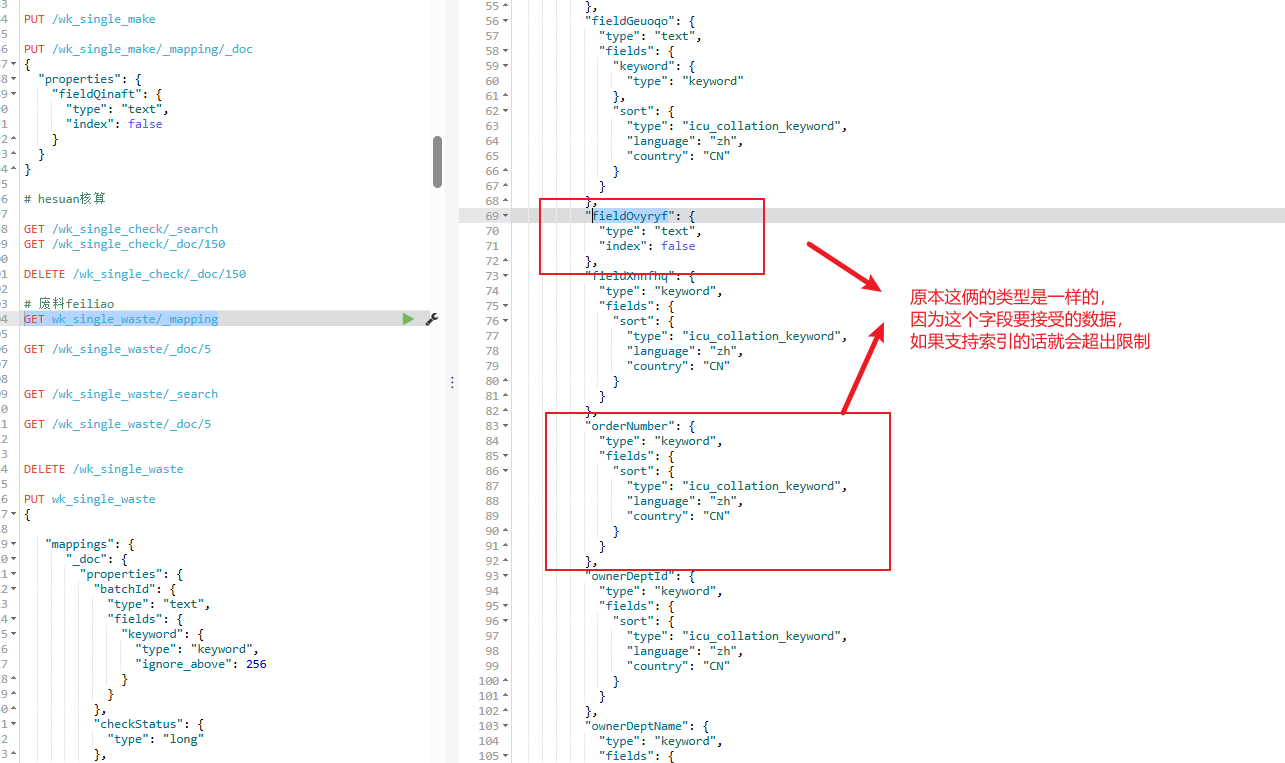
问题现象:
项目中使用 Spring Boot + Elasticsearch(ES 7.x)进行数据索引,当向某个索引插入一条数据时,报出了如下错误:
org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [fieldOvyryf] of type [text]
进一步查看日志详情,发现错误信息中提示:
Document contains at least one immense term in field="fieldOvyryf" (whose UTF8 encoding is longer than the max length 32766)
也就是说,fieldOvyryf 字段的内容超长,已经超过了 ES 默认允许的最大长度(32,766 字节)
我使用kibana查看索引发现一开始这个字段的类型
2.问题排查过程
在 Elasticsearch 中,字段长度受限于底层 Lucene 索引存储结构,对于 text 类型的字段,一般最大允许的单个 term 是 32766 字节。这个限制并不针对字符串本身的字符数,而是它在 UTF-8 编码下的字节长度。
一、确认异常字段
在请求报错时,明确了是 fieldOvyryf 字段导致的问题。
二、检查字段映射
我查询了该字段的索引 mapping 映射配置:
"fieldOvyryf": {
"type": "text"
}
默认情况下,text类型会被 ES 拿去做全文检索,因此会经过分词器处理,并写入反向索引。这就会对字段长度做出严格限制。
三、分析数据来源
fieldOvyryf 实际上是某个业务模块里的备注或富文本字段,用户有可能粘贴大量内容甚至整个文档、表格 HTML 等,这种内容一旦超过 32766 字节就会报错。
3.最终解决方案
由于该字段我们并不需要对它做搜索功能,仅用于存储展示,因此决定禁用它的索引:
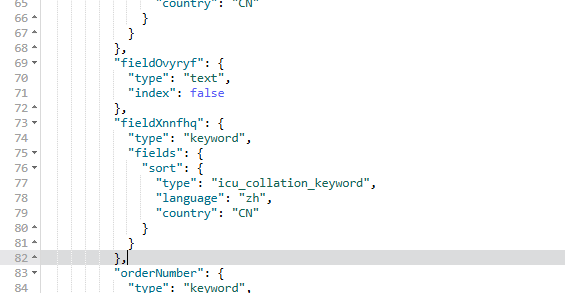
由于的我的索引是创建过的不能直接在基础上可以删除后重新添加,我是先查询来原有的字段,然后赋值下来 把旧的删掉 然后重新创建了一个新的。这是一个笨方法
4.总结与建议
| 项 | 内容 |
|---|---|
| 错误原因 | text 类型字段内容超出 Lucene 限制的 32766 字节 |
| 导致后果 | 文档无法索引写入,抛出 MapperParsingException |
| 关键字段 | "fieldOvyryf" |
| 解决方法 | 设置 "index": false 禁止该字段建索引 |
| 适用场景 | 对于备注、大段文本、富文本字段,仅展示、不搜索的情况 |