正则表达式:文本处理的强大工具
 在计算机编程和文本处理的广阔领域中,正则表达式犹如一把瑞士军刀,发挥着至关重要的作用。无论是数据清洗、信息提取,还是模式匹配与验证,正则表达式都展现出了其无与伦比的强大功能。它能够帮助开发者高效地处理文本数据,极大地提高编程效率和代码质量。
在计算机编程和文本处理的广阔领域中,正则表达式犹如一把瑞士军刀,发挥着至关重要的作用。无论是数据清洗、信息提取,还是模式匹配与验证,正则表达式都展现出了其无与伦比的强大功能。它能够帮助开发者高效地处理文本数据,极大地提高编程效率和代码质量。
一、正则表达式基础
1.1 什么是正则表达式
正则表达式(Regular Expression,简称 Regex 或 Regexp)是一种用于描述字符串模式的工具。它通过特定的字符和符号组合,定义了一种规则,用于匹配、查找、替换符合该规则的字符串。例如,你想要从一段文本中找出所有的邮箱地址,或者验证用户输入的电话号码是否符合规范,正则表达式都能轻松胜任。
1.2 正则表达式的历史渊源
正则表达式的起源可以追溯到 20 世纪 40 年代至 50 年代。当时,神经学家 Warren McCulloch 和数学家 Walter Pitts 在研究人类神经系统如何工作时,提出了一种用数学方式描述神经网络的模型,这为正则表达式的发展奠定了理论基础。1951 年,数学家 Stephen Cole Kleene 在他们的研究基础上,发表了关于正则集代数的论文,正式引入了正则表达式的概念。
到了 1968 年,UNIX 操作系统之父 Kenneth Lane Thompson 将正则表达式应用到了 UNIX 的 QED 编辑器的搜索算法中,随后又引入了 UNIX 下的文本编辑器 ed。从此,正则表达式开始在非技术领域大规模使用,并逐渐成为文本编辑器和搜索工具的重要组成部分。此后,随着计算机技术的不断发展,正则表达式被广泛应用于各种编程语言和文本处理工具中,成为了计算机科学中不可或缺的一部分。
1.3 正则表达式的应用场景
1.3.1 数据验证
在用户注册、登录等场景中,需要对用户输入的数据进行验证,确保其符合特定的格式要求。比如,验证邮箱地址是否合法、手机号码是否正确等。使用正则表达式可以快速有效地进行数据格式验证,提高数据的准确性和安全性。
1.3.2 文本搜索与替换
在处理大量文本数据时,常常需要查找特定的字符串模式,并进行替换操作。例如,在一篇文章中,将所有的英文单词 “color” 替换为 “colour”,或者将所有的 URL 链接提取出来等。正则表达式能够精准地定位符合模式的字符串,实现高效的文本搜索和替换。
1.3.3 数据提取
从非结构化的文本数据中提取有用的信息,是正则表达式的另一个重要应用场景。比如,从网页源代码中提取出所有的图片链接、从日志文件中提取出特定的事件信息等。通过编写合适的正则表达式,可以快速准确地从复杂的文本中提取出所需的数据。
二、正则表达式语法详解
2.1 普通字符
普通字符是正则表达式中最基本的组成部分,它们代表其字面意义。例如,正则表达式 “abc” 将匹配字符串中出现的 “abc” 子串。字母、数字、标点符号等都属于普通字符。在匹配时,普通字符必须与目标字符串中的字符完全一致(区分大小写)。
2.2 元字符
元字符是正则表达式中具有特殊含义的字符,它们赋予了正则表达式强大的功能。以下是一些常见的元字符:
- 点号(.):匹配除换行符(\n)以外的任意单个字符。例如,正则表达式 “a.c” 可以匹配 “abc”、“a1c”、“a c” 等字符串,但不能匹配 “a\nc”。
- 星号(*):匹配前面的字符或子表达式零次或多次。例如,“a*” 可以匹配空字符串、“a”、“aa”、“aaa” 等。“ab*c” 可以匹配 “ac”(此时 “b” 出现 0 次)、“abc”(“b” 出现 1 次)、“abbc”(“b” 出现 2 次)等。
- 加号(+):匹配前面的字符或子表达式一次或多次。与星号不同,加号要求前面的元素至少出现一次。例如,“a+” 可以匹配 “a”、“aa”、“aaa” 等,但不能匹配空字符串。“ab+c” 可以匹配 “abc”、“abbc”、“abbbc” 等,但不能匹配 “ac”。
- 问号(?):匹配前面的字符或子表达式零次或一次。例如,“a?” 可以匹配空字符串或 “a”。“ab?c” 可以匹配 “ac”(“b” 出现 0 次)或 “abc”(“b” 出现 1 次)。
- 花括号({}):用于指定重复次数。例如,“a {3}” 表示 “a” 必须连续出现 3 次,即匹配 “aaa”。“a {3,5}” 表示 “a” 出现 3 到 5 次,可匹配 “aaa”、“aaaa”、“aaaaa”。“a {3,}” 表示 “a” 至少出现 3 次,可匹配 “aaa”、“aaaa”、“aaaaa” 等。
- 方括号([]):用于定义字符类。在方括号内的字符表示一个字符集合,匹配其中任意一个字符。例如,“[abc]” 可以匹配 “a”、“b” 或 “c”。“[a-z]” 表示匹配任意小写字母,“[0-9]” 表示匹配任意数字。方括号内还可以使用 “^” 表示取反,例如 “[^a-z]” 表示匹配除小写字母以外的任意字符。
- 竖线(|):表示多选结构,用于匹配多个模式中的一个。例如,“a|b” 可以匹配 “a” 或 “b”。“(ab|cd)” 可以匹配 “ab” 或 “cd”。
- 圆括号(()):用于分组,可以将多个字符或子表达式组合成一个整体,以便对其进行统一的操作,如重复、应用量词等。例如,“(ab)+” 表示 “ab” 重复一次或多次,可匹配 “ab”、“abab”、“ababab” 等。
2.3 转义字符
当需要匹配元字符本身时,就需要使用转义字符反斜杠(\)。例如,要匹配 “.” 字符,不能直接使用 “.”,因为它是元字符,具有特殊含义,此时应使用 “.”。同样,要匹配 “*” 字符,应使用 “*”。另外,反斜杠还用于一些特殊字符的表示,如 “\n” 表示换行符,“\t” 表示制表符,“\r” 表示回车符等。
2.4 字符类与范围
2.4.1 预定义字符类
除了自定义字符类,正则表达式还提供了一些预定义的字符类,方便我们进行常见字符类型的匹配:
- \d:匹配任意数字,等同于 [0-9]。例如,“\d {3}” 可以匹配三位数字,如 “123”、“456” 等。
- \D:匹配任意非数字字符,等同于 [^0-9]。例如,“\D {2}” 可以匹配两个非数字字符,如 “ab”、“#@” 等。
- \s:匹配任意空白字符,包括空格、制表符、换行符等。例如,“\s+” 可以匹配一个或多个空白字符。
- \S:匹配任意非空白字符,等同于 [^\s]。例如,“\S {3}” 可以匹配三个非空白字符,如 “abc”、“12#” 等。
- \w:匹配字母、数字、下划线或汉字等单词字符,等同于 [a-zA-Z0-9_]。例如,“\w {4}” 可以匹配四个单词字符,如 “abcd”、“1234”、“_abc” 等。
- \W:匹配非单词字符,等同于 [^a-zA-Z0-9_]。例如,“\W {2}” 可以匹配两个非单词字符,如 “@#”、“ ” 等。
2.4.2 字符范围
在字符类中,可以使用连字符(-)来指定字符范围。例如,“[a-z]” 表示从 “a” 到 “z” 的所有小写字母,“[A-Z]” 表示从 “A” 到 “Z” 的所有大写字母,“[0-9]” 表示从 “0” 到 “9” 的所有数字。还可以组合多个范围,如 “[a-zA-Z0-9]” 表示所有字母和数字。
2.5 锚点
锚点用于匹配字符串中的特定位置,而不是具体的字符。常见的锚点有:
- ^:匹配字符串的开头。例如,“^abc” 表示字符串必须以 “abc” 开头才能匹配,对于 “abcdef” 可以匹配,但对于 “defabc” 则不能匹配。
- ****:匹配字符串的结尾。例如,“abc” 表示字符串必须以 “abc” 结尾才能匹配,对于 “defabc” 可以匹配,但对于 “abcdef” 则不能匹配。
- \b:匹配单词边界。单词边界是指单词与非单词字符之间的位置,或者字符串的开头和结尾处的单词位置。例如,“\bcat\b” 可以匹配 “the cat is cute” 中的 “cat”,但不能匹配 “category” 中的 “cat”。
- \B:匹配非单词边界。与 \b 相反,\B 匹配的是单词内部的位置或非单词字符之间的位置。例如,“\Bcat\B” 可以匹配 “category” 中的 “cat”,但不能匹配 “the cat is cute” 中的 “cat”。
2.6 分组与反向引用
2.6.1 分组
通过使用圆括号(())将多个字符或子表达式括起来,可以将它们作为一个整体进行操作,这就是分组。分组可以应用量词、进行多选结构等操作。例如,“(ab)+” 表示 “ab” 作为一个整体重复一次或多次,可匹配 “ab”、“abab”、“ababab” 等。“(abc|def)” 表示匹配 “abc” 或 “def”。
2.6.2 反向引用
反向引用是指在正则表达式中引用之前分组匹配到的内容。通过使用反斜杠加上分组的编号(从 1 开始),可以实现反向引用。例如,“(\w+) \1” 可以匹配两个连续相同的单词,如 “hello hello”、“world world” 等。这里的 “(\w+)” 是第一个分组,“\1” 表示引用第一个分组匹配到的内容。
2.7 贪婪与非贪婪匹配
2.7.1 贪婪匹配
默认情况下,正则表达式中的量词(如 *、+、?、{n,m} 等)是贪婪的,即它们会尽可能多地匹配字符。例如,对于字符串 “aaaab”,正则表达式 “a+” 会匹配整个 “aaaa”,因为它会一直匹配到无法再匹配更多的 “a” 为止。
2.7.2 非贪婪匹配
如果希望量词尽可能少地匹配字符,即一旦找到满足条件的最短匹配就停止匹配,可以在量词后面加上问号(?),使其变为非贪婪模式。例如,对于字符串 “aaaab”,正则表达式 “a+?” 只会匹配一个 “a”,因为它在找到一个 “a” 满足条件后就停止匹配了。
2.8 零宽断言
零宽断言是一种特殊的匹配方式,它用于在特定位置进行匹配,但不消耗字符。常见的零宽断言有:
- 正向先行断言(?=):匹配某个位置后面跟着指定的模式,但不包含该模式。例如,“a (?=b)” 表示匹配 “a”,但要求 “a” 后面必须紧跟着 “b”,对于字符串 “ab” 可以匹配 “a”,但对于 “ac” 则不能匹配。
- 负向先行断言(?!):匹配某个位置后面不跟着指定的模式。例如,“a (?!b)” 表示匹配 “a”,但要求 “a” 后面不能紧跟着 “b”,对于字符串 “ac” 可以匹配 “a”,但对于 “ab” 则不能匹配。
- 正向后行断言(?<=):匹配某个位置前面跟着指定的模式,但不包含该模式。例如,“(?<=a) b” 表示匹配 “b”,但要求 “b” 前面必须是 “a”,对于字符串 “ab” 可以匹配 “b”,但对于 “cb” 则不能匹配。
- 负向后行断言(?<!):匹配某个位置前面不跟着指定的模式。例如,“(?<!a) b” 表示匹配 “b”,但要求 “b” 前面不能是 “a”,对于字符串 “cb” 可以匹配 “b”,但对于 “ab” 则不能匹配。
三、Python 中的正则表达式
3.1 re 模块概述
在 Python 中,通过内置的 re 模块来支持正则表达式操作。re 模块提供了一系列函数,用于编译正则表达式、进行匹配、搜索、替换等操作。在使用 re 模块之前,需要先导入它:
| import re |
3.2 常用函数介绍
3.2.1 re.match()
re.match () 函数用于从字符串的开头开始匹配正则表达式。如果匹配成功,则返回一个匹配对象;如果匹配失败,则返回 None。其语法如下:
| re.match(pattern, string, flags=0) |
其中,pattern 是要匹配的正则表达式字符串,string 是要匹配的目标字符串,flags 是可选参数,用于指定匹配模式,如 re.I(忽略大小写)、re.M(多行模式)等。
例如:
| result = re.match(r'hello', 'hello world') if result: print("匹配成功") else: print("匹配失败") |
在这个例子中,正则表达式 “hello” 与字符串 “hello world” 的开头部分匹配,因此会输出 “匹配成功”。
3.2.2 re.search()
re.search () 函数用于在整个字符串中搜索正则表达式的第一个匹配项。如果找到匹配项,则返回一个匹配对象;如果未找到,则返回 None。其语法与 re.match () 类似:
| re.search(pattern, string, flags=0) |
例如:
| result = re.search(r'world', 'hello world') if result: print("匹配成功") else: print("匹配失败") |
在这个例子中,正则表达式 “world” 在字符串 “hello world” 中被找到,因此会输出 “匹配成功”。与 re.match () 不同的是,re.search () 会在整个字符串中进行搜索,而不仅仅是从开头开始。
3.2.3 re.findall()
re.findall () 函数用于在字符串中查找所有符合正则表达式的子串,并以列表的形式返回。其语法如下:
| re.findall(pattern, string, flags=0) |
例如:
| result = re.findall(r'\d+', 'abc123def456') print(result) |
在这个例子中,正则表达式 “\d+” 用于匹配一个或多个数字,re.findall () 函数在字符串 “abc123def456” 中找到了 “123” 和 “456” 两个匹配项,并以列表形式返回,输出结果为 ['123', '456']。
3.2.4 re.sub()
re.sub () 函数用于在字符串中用指定的替换字符串替换所有符合正则表达式的子串。其语法如下:
| re.sub(pattern, repl, string, count=0, flags=0) |
其中,pattern 是正则表达式字符串,repl 是替换字符串,string 是要进行替换操作的目标字符串,count 是可选参数,指定最多替换的次数,默认为 0,表示替换所有匹配项,flags 是匹配模式。
例如:
| result = re.sub(r'\d+', 'X', 'abc123def456') print(result) |
在这个例子中,正则表达式 “\d+” 匹配的数字将被替换为 “X”,输出结果为 “abcXdefX”。
3.2.5 re.compile()
re.compile () 函数用于将正则表达式字符串编译成一个正则表达式对象,以便在后续的匹配操作中重复使用,提高效率。其语法如下:
| re.compile(pattern, flags=0) |
例如:
| pattern = re.compile(r'\d+') result1 = pattern.findall('abc123def') result2 = pattern.findall('ghi456jkl') print(result1) print(result2) |
在这个例子中,首先使用 re.compile () 将正则表达式 “\d+” 编译成一个对象 pattern,然后通过该对象多次调用 findall () 方法进行匹配操作。这样可以避免每次都重新编译正则表达式,提高程序运行效率。
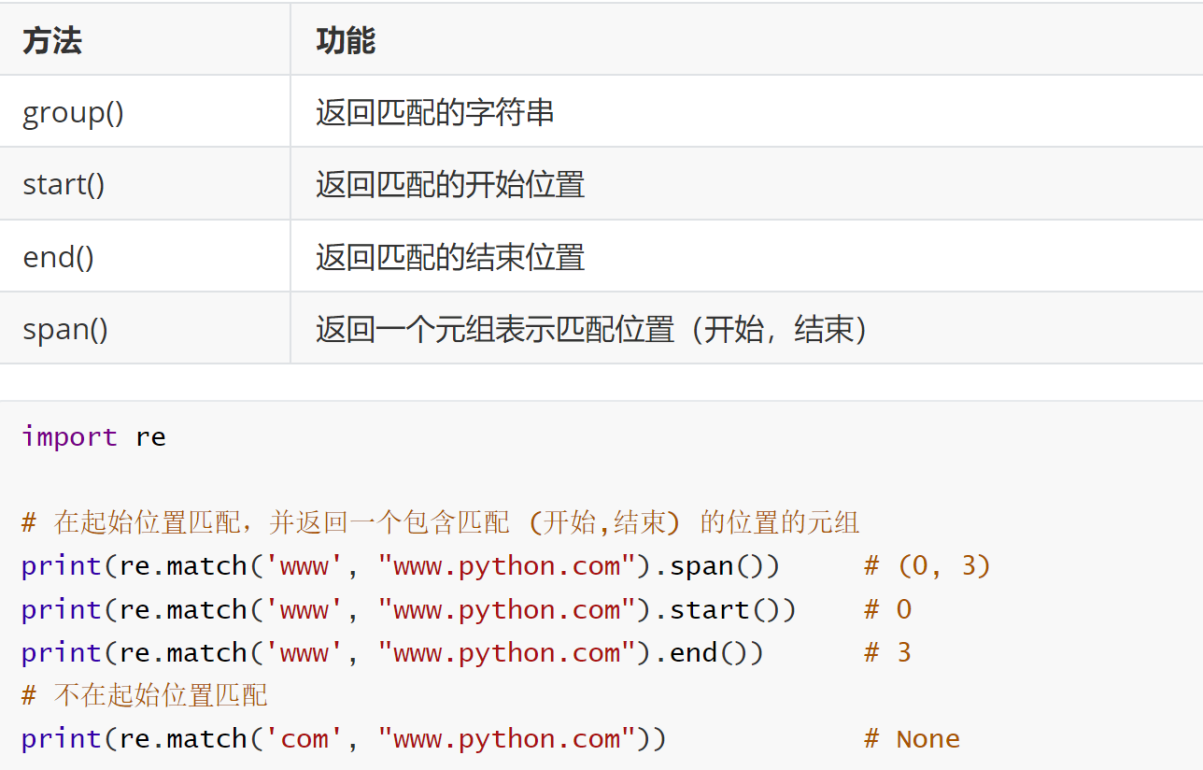
3.3 匹配对象的使用
当使用 re.match ()、re.search () 等函数进行匹配操作并成功匹配时,会返回一个匹配对象。匹配对象提供了一些方法和属性,用于获取匹配的相关信息:
3.4 标志位(Flags)的使用
在使用re模块的函数时,可以通过flags参数来修改正则表达式的匹配行为。常见的标志位有:
re.I(忽略大小写):使匹配对大小写不敏感。例如:
| result = re.search(r'hello', 'Hello World', re.I) if result: print("匹配成功") else: print("匹配失败") |
这里使用re.I标志位,即使正则表达式是小写的 "hello",也能匹配到字符串中大写的 "Hello"。
re.M(多行模式):改变^和$的行为,使其不仅匹配字符串的开头和结尾,还能匹配每一行的开头和结尾。例如:
| text = "hello\nworld\npython" pattern = re.compile(r'^world$', re.M) result = pattern.search(text) if result: print("匹配成功") else: print("匹配失败") |
在没有re.M标志位时,^world$无法匹配到文本中的 "world",因为它默认只匹配整个字符串的开头和结尾。而加上re.M后,^和$可以匹配每一行的开头和结尾,所以能找到 "world" 这一行并匹配成功。
re.S(使点号匹配包括换行符在内的所有字符):默认情况下,点号(.)不匹配换行符。使用re.S标志位后,点号可以匹配任意字符,包括换行符。例如:
| text = "hello\nworld" pattern = re.compile(r'.+', re.S) result = pattern.match(text) if result: print("匹配成功,匹配结果:", result.group(0)) else: print("匹配失败") |
这里使用re.S标志位,.+能够匹配包含换行符的整个字符串 "hello\nworld"。如果没有re.S,.+只会匹配到 "hello",因为它遇到换行符就停止匹配了。
re.X(详细模式):允许编写更具可读性的正则表达式。在详细模式下,可以在正则表达式中添加注释和空白字符,这些注释和空白字符会被忽略(除非它们在字符类中或被转义)。例如:
| pattern = re.compile(r""" \d+ # 匹配一个或多个数字 \. # 匹配一个点号 \d+ # 匹配一个或多个数字 """, re.X) result = pattern.match("12.34") if result: print("匹配成功") else: print("匹配失败") |
通过re.X标志位,将原本紧凑的正则表达式\d+\.\d+拆分成多行,并添加了注释,使代码的可读性大大提高。
3.5 正则表达式的贪婪与非贪婪模式在 Python 中的表现
在 Python 的正则表达式中,贪婪模式是默认的匹配方式。例如,对于字符串 "aaaaa",正则表达式a+会尽可能多地匹配 "a",结果会匹配整个 "aaaaa"。而非贪婪模式则通过在量词后加上?来实现,例如a+?,对于同样的字符串 "aaaaa",它会尽可能少地匹配 "a",每次只匹配一个 "a"。下面通过具体例子来展示:
| text = "aaaaa" greedy_pattern = re.compile(r'a+') non_greedy_pattern = re.compile(r'a+?') greedy_result = greedy_pattern.findall(text) non_greedy_result = non_greedy_pattern.findall(text) print("贪婪模式匹配结果:", greedy_result) print("非贪婪模式匹配结果:", non_greedy_result) |
输出结果为:
| 贪婪模式匹配结果: ['aaaaa'] 非贪婪模式匹配结果: ['a', 'a', 'a', 'a', 'a'] |
可以看到,贪婪模式下a+一次性匹配了所有的 "a",而非贪婪模式下a+?逐个匹配了 "a"。在实际应用中,需要根据具体需求选择合适的匹配模式。比如在提取 HTML 标签内的文本时,如果使用贪婪模式可能会导致匹配到错误的内容,此时非贪婪模式可能更合适。例如,对于字符串<p>hello</p><p>world</p>,如果想分别提取两个<p>标签内的文本:
| html_text = "<p>hello</p><p>world</p>" pattern = re.compile(r'<p>(.*?)</p>') results = pattern.findall(html_text) for result in results: print(result) |
这里使用非贪婪模式.*?,能够正确地分别提取出 "hello" 和 "world"。如果使用贪婪模式.*,则会匹配到<p>hello</p><p>world</p>整个内容,不符合需求。
四、复杂正则表达式示例与解析
4.1 匹配邮箱地址
邮箱地址的格式较为复杂,通常由用户名、@符号和域名组成,域名又包含顶级域名等部分。下面是一个匹配常见邮箱地址格式的正则表达式及解析:
| email_pattern = re.compile(r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$') |
- ^和$:表示匹配整个字符串的开头和结尾,确保整个字符串都是符合邮箱格式的。
- [a-zA-Z0-9_.+-]+:匹配用户名部分,用户名可以包含字母、数字、下划线、点号、加号和减号,并且至少出现一次。
- @:匹配 @符号,这是邮箱地址的固定组成部分。
- [a-zA-Z0-9-]+:匹配域名的主体部分,域名主体可以包含字母、数字和减号,至少出现一次。
- \.:匹配点号,由于点号在正则表达式中有特殊含义,所以需要转义。
- [a-zA-Z0-9-.]+:匹配顶级域名部分,顶级域名可以包含字母、数字、减号和点号,至少出现一次。
例如,对于字符串 "example@domain.com",使用上述正则表达式进行匹配:
| email = "example@domain.com" if email_pattern.match(email): print("邮箱地址格式正确") else: print("邮箱地址格式错误") |
4.2 匹配 URL
URL 的格式也有多种变化,下面是一个较为通用的匹配 URL 的正则表达式及解析:
| url_pattern = re.compile(r'^(https?|ftp)://[^\s/$.?#].[^\s]*$') |
- ^和$:同样表示匹配整个字符串的开头和结尾。
- (https?|ftp):匹配协议部分,https?表示匹配 "http" 或 "https",|表示或的关系,所以也能匹配 "ftp" 协议。
- ://:匹配协议和域名之间的分隔符。
- [^\s/$.?#]:匹配域名的起始字符,不能是空白字符、斜杠、美元符号、点号、问号和井号。
- [^\s]*:匹配域名的其余部分,直到字符串结尾,不能包含空白字符。
例如,对于字符串 "https://www.example.com/path?query=value#fragment",使用该正则表达式进行匹配:
| url = "https://www.example.com/path?query=value#fragment" if url_pattern.match(url): print("URL格式正确") else: print("URL格式错误") |
4.3 匹配日期格式(YYYY-MM-DD)
匹配日期格式(以 "YYYY-MM-DD" 为例)的正则表达式及解析如下:
| date_pattern = re.compile(r'^(\d{4})-(0[1-9]|1[0-2])-(0[1-9]|[12]\d|3[01])$') |
- ^和$:匹配整个字符串的开头和结尾。
- (\d{4}):第一个分组,匹配 4 位数字的年份。
- -:匹配日期分隔符 "-"。
- (0[1-9]|1[0-2]):第二个分组,匹配月份,范围是 01 到 12。
- -:再次匹配日期分隔符 "-"。
- (0[1-9]|[12]\d|3[01]):第三个分组,匹配日期,范围是 01 到 31。
例如,对于字符串 "2024-10-05",使用该正则表达式进行匹配:
| date = "2024-10-05" if date_pattern.match(date): print("日期格式正确") else: print("日期格式错误") |
4.4 从 HTML 代码中提取链接
在处理网页数据时,经常需要从 HTML 代码中提取链接。下面是一个使用正则表达式从简单 HTML 代码中提取链接的示例及解析:
| html = '<a href="https://www.example.com">Example Link</a>' link_pattern = re.compile(r'<a href="([^"]+)">') links = link_pattern.findall(html) for link in links: print(link) |
- <a href=":匹配<a href="这部分 HTML 标签开头。
- ([^"]+):分组部分,[^"]+表示匹配除双引号以外的一个或多个字符,这里用于提取链接的 URL 部分。
- >:匹配 HTML 标签的结束符号 ">"。
通过上述正则表达式,能够从给定的 HTML 代码中提取出链接 "Example Domain"。在实际应用中,HTML 代码可能更为复杂,还需要考虑更多的情况,比如链接可能使用单引号包裹、标签可能有其他属性等,但基本的思路是类似的。
五、正则表达式的性能优化与注意事项
5.1 性能优化
- 使用re.compile()进行预编译:当需要多次使用同一个正则表达式时,使用re.compile()将其编译成正则表达式对象,然后重复使用该对象进行匹配操作。这样可以避免每次调用匹配函数时都重新编译正则表达式,从而提高性能。例如:
| import re pattern = re.compile(r'\d+') for i in range(1000): result = pattern.findall('abc123def456') |
在这个例子中,如果不使用re.compile(),每次循环调用re.findall()时都要重新编译正则表达式\d+,而使用re.compile()预编译后,只在第一次编译,后续循环中直接使用已编译的对象,大大提高了效率。
2. 简化正则表达式:尽量编写简洁、高效的正则表达式。避免使用过于复杂或不必要的分组、量词等。复杂的正则表达式不仅可读性差,而且匹配时需要更多的计算资源和时间。例如,对于匹配一个或多个数字,使用\d+就比(\d){1,}更简洁高效。
3. 减少回溯:回溯是正则表达式匹配过程中的一种机制,当匹配失败时,正则表达式引擎会尝试回溯到之前的状态重新匹配。过多的回溯会导致性能下降。可以通过合理使用量词(如避免过度使用贪婪量词)、明确分组等方式减少回溯的发生。例如,对于字符串 "aaaab",如果使用a*b匹配,由于a*是贪婪的,它会先匹配所有的 "a",然后发现后面没有 "b",就会进行回溯,逐个减少 "a" 的匹配数量,直到找到匹配的 "b"。如果能确定 "a" 的数量范围,使用a{1,3}b这样更明确的表达式就可以减少回溯。
5.2 注意事项
- 转义字符的使用:在正则表达式中,很多字符都有特殊含义,如果要匹配这些字符本身,需要使用转义字符\。同时,在 Python 字符串中,\本身也有转义作用,所以在定义正则表达式字符串时,为了避免混淆,通常使用原始字符串(在字符串前加上r)。例如,要匹配点号.,正则表达式应为r'\.',如果写成'.',在 Python 字符串解析时会将\转义,导致正则表达式错误。
- 边界条件的处理:在编写正则表达式时,要充分考虑边界条件。比如匹配数字时,要考虑是否包含负数、小数,匹配字符串时要考虑字符串的开头和结尾情况等。例如,匹配一个单词时,如果不使用\b(单词边界),可能会误匹配到单词的一部分。如正则表达式re.search(r'cat', 'category')会匹配成功,但如果使用re.search(r'\bcat\b', 'category')则不会匹配,因为 "category" 中的 "cat" 不是一个独立的单词。
- 测试与调试:由于正则表达式的语法较为复杂,编写完成后一定要进行充分的测试。可以使用不同的测试用例来验证正则表达式是否能正确匹配预期的字符串,以及是否会误匹配不期望的字符串。Python 的re模块提供了丰富的函数和方法来进行测试,如re.match()、re.search()、re.findall()等。同时,如果出现匹配错误或不符合预期的情况,可以通过打印中间结果、添加注释等方式进行调试。
- 安全性考虑:在处理用户输入的字符串时,使用正则表达式要注意安全性。恶意用户可能通过输入特殊的字符串来利用正则表达式的漏洞,进行攻击,如正则表达式拒绝服务(ReDoS)攻击。为了防止这种情况,要对用户输入进行严格的验证和过滤,避免使用用户输入直接构建复杂的正则表达式。
六、总结
正则表达式是一种功能强大且灵活的文本处理工具,在 Python 以及众多其他编程语言和文本处理场景中都有着广泛的应用。通过本文,我们从正则表达式的基础概念入手,详细介绍了其语法规则,包括普通字符、元字符、字符类、锚点、分组与反向引用、贪婪与非贪婪匹配、零宽断言等重要内容。同时,深入探讨了 Python 中re模块对正则表达式的支持,涵盖了常用函数如re.match()、re.search()、re.findall()、re.sub()、re.compile()的使用方法,以及匹配对象的相关操作和标志位的应用。通过复杂正则表达式示例,如匹配邮箱地址、URL、日期格式和从 HTML 代码中提取链接等,展示了正则表达式在实际场景中的强大功能。最后,还强调了正则表达式的性能优化技巧和使用过程中的注意事项。
掌握正则表达式需要不断的实践和积累经验,希望读者通过本文的学习,能够对正则表达式有更深入的理解和认识,并在今后的编程和文本处理工作中熟练运用正则表达式,提高工作效率,解决各种复杂的文本处理问题。