Linux的进程管理源码相关内容梳理
注意:不要以为Linux源码本身可以直接运行,而不需要依赖额外的环境,Linux源码其实就和我们自己写的代码一样,也得需要编译和运行环境的支持。
Linux 的进程管理是内核的核心功能之一,涉及进程的创建、调度、同步和终止等操作。以下从源码角度梳理其核心机制和关键数据结构:
进程管理相关目录和文件
在 Linux 内核源码中,进程管理相关的实现分散在多个目录和文件中,核心逻辑围绕进程的创建、调度、生命周期管理等展开。以下是最关键的目录和文件:
一、核心数据结构与进程管理(
include/linux/和kernel/)
进程描述符定义
include/linux/sched.h定义了进程的核心数据结构
struct task_struct(包含进程 ID、状态、优先级、调度信息、内存管理、文件描述符等所有进程属性),以及进程管理的核心函数声明(如fork()、schedule()等)。
include/linux/sched/task_struct.h(较新内核版本拆分出的文件)专门存放
struct task_struct的详细定义,包含进程状态(state)、调度类(sched_class)、PID 相关字段、信号处理等。进程创建与销毁
kernel/fork.c实现进程创建的核心逻辑,包括
sys_fork()、sys_clone()、sys_vfork()系统调用,以及关键函数copy_process()(复制父进程资源)、do_fork()(统筹进程创建流程)。
kernel/exit.c处理进程退出逻辑,包括
do_exit()(释放进程资源)、exit_notify()(通知父进程和等待队列)、wait4()等等待机制。PID 管理
kernel/pid.c实现 PID 的分配、释放和管理,包括
alloc_pid()(分配 PID 结构体)、put_pid()、get_pid()等函数,以及 PID 命名空间相关逻辑。
include/linux/pid.h定义
struct pid结构体(管理不同命名空间的 PID)和相关操作函数。二、进程调度(
kernel/sched/)调度器是进程管理的核心组件,相关代码集中在
kernel/sched/目录:
调度核心逻辑
kernel/sched/core.c实现调度器主函数
schedule()、__schedule()(上下文切换核心),以及调度类(struct sched_class)的定义。
kernel/sched/sched.h包含调度器内部数据结构(如运行队列
struct rq、调度实体struct sched_entity)和函数声明。CFS 调度器(普通进程)
kernel/sched/fair.c
实现完全公平调度器(CFS)的逻辑,包括fair_sched_class调度类、vruntime计算、进程选择(pick_next_task_fair)等。实时调度器
kernel/sched/rt.c
实现实时调度策略(SCHED_FIFO、SCHED_RR),包括rt_sched_class调度类、实时优先级管理、时间片轮转逻辑。其他调度相关
kernel/sched/deadline.c实现
SCHED_DEADLINE调度策略(截止时间驱动调度)。
kernel/sched/debug.c提供调度器调试接口(如
/proc/sched_debug信息输出)。三、信号处理(
kernel/signal/)信号是进程间通信的重要机制,相关实现:
kernel/signal.c
实现信号的发送(send_signal())、接收(do_signal())、处理(handle_signal())等逻辑,以及信号掩码、pending 队列管理。
include/linux/signal.h
定义信号相关数据结构(struct k_sigaction)、信号编号(如SIGINT、SIGKILL)和函数声明。四、进程间通信(IPC)
进程间通信机制(如管道、共享内存、信号量)相关代码:
ipc/目录
ipc/msg.c:消息队列ipc/sem.c:信号量ipc/shm.c:共享内存ipc/pipe.c:管道(匿名管道)
fs/pipe.c
实现管道的创建和 I/O 操作(与文件系统结合)。五、命名空间与资源隔离(
kernel/nsproxy.c和include/linux/nsproxy.h)进程命名空间(PID、UTS、Mount 等)用于实现容器等隔离场景:
kernel/nsproxy.c
管理进程的命名空间代理(struct nsproxy),负责命名空间的复制和释放。
include/linux/nsproxy.h和include/linux/pid_namespace.h
定义命名空间相关数据结构,特别是 PID 命名空间的管理。六、系统调用接口(
arch/[架构]/kernel/syscalls/)进程管理相关的系统调用入口(如
fork、execve、waitpid)通常在架构相关目录中定义:
- 例如 x86 架构:
arch/x86/kernel/sys_x86_64.c或arch/x86/kernel/syscall_64.c
定义系统调用表,将用户态的sys_fork等映射到内核态的实现函数。总结
Linux 进程管理的核心代码集中在:
kernel/fork.c(进程创建)、kernel/exit.c(进程销毁)、kernel/pid.c(PID 管理);kernel/sched/目录(调度器实现,尤其是core.c、fair.c、rt.c);kernel/signal.c(信号处理)和ipc/目录(IPC 机制)。这些文件相互配合,实现了从进程创建到调度、通信、销毁的全生命周期管理,是理解 Linux 进程模型的关键。
进程管理的核心数据结构
struct task_struct(进程描述符)
- 位置:
include/linux/sched.h- 作用:表示一个进程或线程的所有状态信息,被称为 “进程的身份证”。
核心字段:
struct task_struct {pid_t pid; // 进程IDstruct mm_struct *mm; // 内存描述符(用户空间内存映射)struct list_head tasks; // 进程链表节点struct plist_node run_list; // 运行队列节点unsigned int state; // 进程状态(TASK_RUNNING、TASK_SLEEPING等)int exit_state; // 退出状态struct task_struct *parent; // 父进程指针struct list_head children; // 子进程链表struct files_struct *files; // 文件描述符表struct signal_struct *signal; // 信号处理结构/* 调度相关字段 */struct sched_entity se; // 调度实体(用于CFS调度器)struct sched_rt_entity rt; // 实时调度实体/* 上下文切换相关 */unsigned long stack; // 内核栈指针struct thread_info *thread_info; // 线程信息/* 时间统计 */cputime_t utime, stime; // 用户态/内核态CPU时间 };在 Linux 中,进程控制块(PCB) 和 进程描述符(process descriptor) 本质上指的是同一个概念,只是不同语境下的表述方式:
进程控制块(PCB) 是操作系统理论中的通用术语,指内核中用于管理进程的核心数据结构,存储了进程的所有关键信息(如 PID、状态、内存映射、文件描述符等),是内核调度和控制进程的基础。
进程描述符(process descriptor) 是 Linux 内核中对 PCB 的具体实现,在代码中对应
struct task_struct结构体(定义于<linux/sched.h>)。它是 Linux 内核管理进程的核心数据结构,包含了进程的所有元数据,完全承担了 PCB 的角色。
thread_info
另外,还有个跟task_struct息息相关的结构体thread_info需要了解下
在 Linux 内核中,
thread_info是一个与进程(或线程)相关的关键数据结构,主要用于存储线程的轻量级信息,尤其与内核栈和硬件上下文紧密关联。它是内核管理线程的重要辅助结构,与进程描述符task_struct配合工作。
thread_info的核心功能
内核栈与进程描述符的桥梁
Linux 内核为每个进程(或线程)分配了独立的内核栈(通常为 8KB 或 16KB),而
thread_info就位于内核栈的底部(或顶部,取决于 CPU 架构)。通过thread_info,内核可以快速从当前栈指针(sp)定位到对应的进程描述符task_struct。存储轻量级线程状态
包含与线程运行相关的基础信息,例如:
- 进程的抢占计数(
preempt_count):控制内核抢占机制(0 表示可抢占)。- 线程标志(
flags):如是否有未处理信号(TIF_SIGPENDING)、是否需要调度(TIF_NEED_RESCHED)等。- 地址空间限制(
addr_limit):区分用户态(USER_DS)和内核态(KERNEL_DS)的地址访问范围。- 系统调用重启信息(
restart_block):用于中断后重启系统调用。数据结构定义(简化版)
不同 CPU 架构(如 x86、ARM)的
thread_info定义略有差异,但核心字段类似(以 x86 为例)struct thread_info {struct task_struct *task; // 指向所属进程的 task_struct(进程描述符)unsigned long flags; // 线程状态标志(如 TIF_SIGPENDING、TIF_NEED_RESCHED)int preempt_count; // 抢占计数(0 表示可被抢占)mm_segment_t addr_limit; // 地址空间限制(用户态/内核态)struct restart_block restart_block; // 系统调用重启数据// 其他架构相关字段(如 CPU 寄存器上下文、调试信息等) };与
task_struct的关系
task_struct是进程的 “完整档案”,存储了进程的所有核心信息(PID、内存映射、文件描述符、信号处理等),体积较大。thread_info是 “轻量级辅助结构”,依附于内核栈,通过task指针关联到task_struct。
内核中通过current_thread_info()函数可从当前栈指针快速获取thread_info,再通过thread_info->task得到task_struct(这也是current宏的实现原理,用于获取当前运行进程的task_struct)。为什么需要
thread_info?
高效访问进程信息
在内核中断或异常处理时,通过栈指针可直接定位thread_info,进而快速找到task_struct,避免全局查找,提升效率。分离架构相关数据
将与硬件架构紧密相关的信息(如栈布局、寄存器状态)放入thread_info,而task_struct存储架构无关的通用信息,便于内核跨架构移植。内核栈管理
thread_info与内核栈绑定,确保每个进程的内核栈与关键元数据一一对应,简化栈的分配与回收。总结
thread_info是 Linux 内核中连接内核栈与进程描述符的 “轻量级桥梁”,主要用于存储线程的基础状态和架构相关信息,是内核实现进程调度、中断处理和内存管理的重要支撑结构。注意:
在 Linux 内核中,每个进程(或线程)都有独立的
thread_info结构体。
内核栈
我们来理解下这句话:内核为每个进程(或线程)分配了独立的内核栈(用于内核态代码执行)
在 Linux 中,每个进程(包括线程)除了用户态栈(用户栈),还必须分配独立的内核态栈(内核栈)。这是由内核的工作机制和安全性要求决定的,二者的作用和使用场景完全不同。
1. 两种栈的核心区别
维度 用户栈(User Stack) 内核栈(Kernel Stack) 使用场景 用户态代码执行(如 main函数、库函数)内核态代码执行(如系统调用、中断处理) 所属空间 进程用户虚拟地址空间 内核虚拟地址空间(但每个进程独立分配) 大小管理 动态增长(通常默认几 MB,可配置) 固定大小(通常 8KB 或 16KB,架构相关) 访问权限 用户态代码可直接访问 仅内核态代码可访问(用户态访问会触发异常) 2. 为什么需要独立的内核栈?
(1)安全性与隔离性
- 内核栈存储内核态执行时的关键数据(如函数调用栈帧、寄存器状态、敏感操作参数),若与用户栈共用,可能导致用户态代码恶意篡改内核数据,引发安全漏洞。
- 独立内核栈确保内核操作的完整性,不受用户态代码的干扰。
(2)内核态执行的独立性
- 当进程执行系统调用(如
open、read)或触发中断(如时钟中断、IO 中断)时,CPU 会从用户态切换到内核态,此时必须使用内核栈:
- 保存用户态寄存器上下文(如
rip、rsp等),以便后续恢复用户态执行。- 内核函数调用的栈帧(参数、返回地址、局部变量)必须存储在 kernel 栈中,与用户栈严格分离。
(3)多进程 / 线程的并发管理
- 内核是多任务共享的,多个进程可能同时进入内核态(如通过中断嵌套)。每个进程的内核栈独立,确保不同进程的内核态操作不会相互干扰。
- 例如,进程 A 正在执行系统调用,此时发生中断并切换到进程 B 的内核处理逻辑,由于内核栈独立,二者的栈帧不会混乱。
(4)栈大小的严格控制
- 内核栈大小固定且较小(如 8KB),这是为了避免内核态操作消耗过多内存(内核资源需要严格管控)。
- 用户栈则可动态增长(受限于
RLIMIT_STACK限制),适合用户态程序的灵活需求。3. 内核栈的分配与管理
- 分配时机:进程创建时(
fork或clone),内核会为新进程分配内核栈,并在栈的固定位置(底部或顶部)初始化thread_info结构体。- 与
thread_info绑定:如前所述,thread_info位于内核栈的固定位置,通过栈指针可快速定位,进而关联到进程的task_struct。- 线程共享与独立:同一进程内的多个线程(轻量级进程)会共享用户栈(可选),但每个线程必须有独立的内核栈,因为线程可能同时进入内核态执行。
总结
用户栈和内核栈是进程在不同运行状态(用户态 / 内核态)下使用的两套独立栈:
- 用户栈服务于用户态代码,灵活且可动态增长;
- 内核栈服务于内核态代码,强调安全隔离和严格的资源控制。
内核栈的存在是 Linux 内核多任务管理、特权级隔离的基础,确保了内核操作的安全性和可靠性。
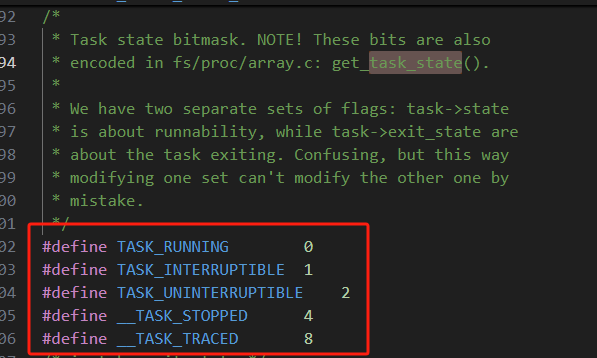
进程状态
进程状态定义在
include/linux/sched.h中,主要状态包括:
TASK_RUNNING:运行中或就绪状态(在运行队列中)。TASK_INTERRUPTIBLE:可中断睡眠(能被信号唤醒)。TASK_UNINTERRUPTIBLE:不可中断睡眠(仅由特定事件唤醒)。__TASK_ZOMBIE:僵尸进程(已终止,但父进程未回收资源)。__TASK_DEAD:死亡进程(即将被销毁)。
进程的创建和终止
Linux 创建进程的源码流程涉及多个关键步骤,从用户态的系统调用到底层内核的实现,是理解进程管理的核心。以下从源码角度梳理其核心流程:
一、用户态接口与系统调用
用户态通过
fork()、vfork()或clone()创建进程,最终都会触发系统调用进入内核:系统调用号(以 x86_64 为例):
fork()→ 系统调用号__NR_forkvfork()→ 系统调用号__NR_vforkclone()→ 系统调用号__NR_clone系统调用入口:
内核通过sys_call_table映射到对应的处理函数:// arch/x86/entry/syscalls/syscall_64.tbl 1 common fork sys_fork 2 common vfork sys_vfork 3 common clone sys_clone简化的调用链如下:
用户态调用 fork() → sys_fork() → do_fork(SIGCHLD, ...) 用户态调用 vfork() → sys_vfork() → do_fork(CLONE_VFORK | ..., ...) 用户态调用 clone() → sys_clone() → do_fork(clone_flags, ...)可以看到,
fork()、vfork()、clone()最终都调用do_fork(),只是传入的clone_flags不同。二、内核核心流程:
do_fork()所有进程创建最终调用
kernel/fork.c中的do_fork():long do_fork(unsigned long clone_flags,unsigned long stack_start,unsigned long stack_size,int __user *parent_tidptr,int __user *child_tidptr) {// 1. 复制进程描述符(浅拷贝,共享资源)struct task_struct *p = copy_process(clone_flags, ...);// 2. 分配进程IDstruct pid *pid = get_task_pid(p, PIDTYPE_PID);// 3. 处理vfork特殊逻辑(父进程等待子进程执行exec)if (clone_flags & CLONE_VFORK) {p->vfork_done = &vfork;wait_for_completion(&vfork);}// 4. 将新进程添加到调度队列wake_up_new_task(p);return pid_vnr(pid); // 返回子进程PID给父进程 }关键步骤解析:
copy_process():复制父进程的task_struct并初始化新进程的资源。get_task_pid():分配唯一的 PID(通过pid命名空间管理)。wake_up_new_task():将新进程标记为可运行,加入 CPU 调度队列。三、核心子函数:
copy_process()
copy_process()是创建进程的核心逻辑,位于kernel/fork.c:static struct task_struct *copy_process(...) {// 1. 分配新的task_struct和内核栈struct task_struct *p = dup_task_struct(current);// 2. 初始化进程状态(TASK_NEW)sched_fork(clone_flags, p);// 3. 复制各种资源(根据clone_flags决定是否共享)copy_files(clone_flags, p); // 文件描述符表copy_fs(clone_flags, p); // 文件系统信息(工作目录等)copy_sighand(clone_flags, p); // 信号处理函数copy_signal(clone_flags, p); // 信号掩码copy_mm(clone_flags, p); // 内存空间(虚拟地址映射)// 4. 设置子进程的执行上下文copy_thread(clone_flags, stack_start, p);// 5. 建立进程关系(父子关系)attach_pid(p, PIDTYPE_PID);nr_threads++;return p; }关键步骤解析:
dup_task_struct():分配新的task_struct和内核栈,并复制父进程的基本信息。sched_fork():初始化调度相关信息,设置进程状态为TASK_NEW(不可运行)。- 资源复制:根据
clone_flags决定复制或共享父进程的资源(如CLONE_FILES表示共享文件描述符)。copy_thread():设置子进程的寄存器状态,确保子进程从ret_from_fork开始执行。四、核心子函数:
copy_thread()
copy_thread()负责设置子进程的执行上下文(寄存器状态),位于arch/x86/kernel/process.c:int copy_thread(unsigned long clone_flags, unsigned long sp, ...) {// 1. 获取子进程的寄存器结构体struct pt_regs *childregs = task_pt_regs(p);// 2. 复制父进程的寄存器状态*childregs = *current_pt_regs();// 3. 修改返回值:子进程返回0,父进程返回子进程PIDchildregs->ax = 0; // 子进程的fork返回值为0// 4. 设置子进程的栈指针和指令指针childregs->sp = sp; // 用户栈指针p->thread.ip = (unsigned long)ret_from_fork; // 从ret_from_fork开始执行// 5. 架构相关的初始化(如设置内核栈)p->thread.sp = (unsigned long)childregs;... }五、进程调度与上下文切换
新进程创建后,通过
wake_up_new_task()加入调度队列,最终通过schedule()被执行:static void wake_up_new_task(struct task_struct *p) {// 1. 设置进程状态为TASK_RUNNINGp->state = TASK_RUNNING;// 2. 将进程添加到CPU的就绪队列enqueue_task(p->sched_class, p, false);// 3. 如果新进程优先级更高,触发调度check_preempt_curr(p->sched_class, p, WF_FORK); }上下文切换关键函数:
schedule():选择下一个要执行的进程,并触发上下文切换。context_switch():切换虚拟地址空间(switch_mm())和内核栈(switch_to())。switch_to():架构相关的汇编代码,切换寄存器状态(如rsp、rip)。六、父子进程的不同返回值
fork()在父子进程中的不同返回值由copy_thread()实现:
- 子进程:寄存器
ax被设置为 0,因此fork()返回 0。- 父进程:
do_fork()返回子进程的 PID,因此fork()返回子进程的 PID。七、流程图总结
用户态: fork() → 系统调用陷入内核 → sys_fork()↓ 内核态: do_fork() → copy_process() → dup_task_struct() // 复制task_struct| || → sched_fork() // 初始化调度信息| || → copy_xxx() // 复制各种资源| || → copy_thread() // 设置执行上下文|→ get_task_pid() // 分配PID|→ wake_up_new_task() → enqueue_task() // 加入调度队列|→ schedule() → context_switch() → switch_to() // 上下文切换八、关键数据结构
struct task_struct:进程描述符,包含进程的所有状态信息。struct mm_struct:内存描述符,管理进程的虚拟地址空间。struct files_struct:文件描述符表,管理进程打开的文件。struct pt_regs:寄存器状态,保存进程的 CPU 寄存器值。总结
Linux 创建进程的源码流程体现了 “写时复制(Copy-on-Write)” 和 “延迟分配” 的设计思想:
- 资源复制:初始只复制
task_struct和少量资源,其他资源通过 COW 延迟复制。- 上下文切换:通过精心设计的寄存器设置,确保父子进程从
fork()后不同的逻辑分支返回。- 模块化设计:进程创建、调度、内存管理等功能分离,通过接口协作,保证系统的可扩展性。
理解这一流程,对调试多进程程序、优化系统性能至关重要。
我们举个例子来看看进程创建的过程:
linux中,当使用./hello 执行一个可执行程序时,内部过程是什么样的?
在 Linux 中执行
./hello这样的命令时,背后涉及 Shell 解析、系统调用和程序加载等一系列复杂过程。以下是详细的内部流程:1. Shell 解析命令
- 当你在终端输入
./hello并按下回车时,当前 Shell(如 bash、zsh 等)首先接收并解析这个命令:
- 路径识别:
./表示当前工作目录,hello是要执行的文件名,Shell 会拼接出完整路径(如/home/user/hello)。- 检查文件类型:Shell 调用
stat系统调用检查文件是否存在,以及是否为可执行文件(即文件权限中包含x标志)。- 处理别名与内置命令:Shell 会先判断
hello是否为内置命令(如cd、echo)或别名,此处显然是外部程序,继续下一步。2. 创建新进程(fork)
- Shell 决定执行外部程序时,会通过
fork()系统调用 创建一个新的进程:
- 新进程是 Shell 进程的副本(基于 Copy-On-Write 机制,初始时共享内存页,修改时才复制)。
- 新进程继承 Shell 的环境变量(如
PATH、USER)、文件描述符(标准输入 / 输出 / 错误)等。- 内核为新进程分配唯一的 PID(进程 ID),并维护其进程控制块(
task_struct)。3. 加载可执行程序(execve)
- 新进程创建后,并不会立即执行
hello程序,而是通过execve()系统调用 加载并替换当前进程的代码和数据:
- 参数传递:
execve接收三个关键参数:
- 可执行文件路径(如
/home/user/hello)。- 命令行参数数组(如
["./hello", NULL])。- 环境变量数组(如
["PATH=/usr/bin", ...])。- 解析可执行文件格式:
- 内核检查文件的 ELF 头部(Linux 下可执行文件通常为 ELF 格式),验证其合法性(如是否为可执行类型、机器架构是否匹配)。
- 读取程序的段表(Segment Table),根据
PT_LOAD段的信息,将代码段(.text)、数据段(.data)、只读数据段(.rodata)等加载到进程的虚拟地址空间。- 清除旧进程资源:
- 新进程原有的代码、数据、堆、栈等被丢弃,替换为
hello程序的内容。- 保留进程 ID(PID)、文件描述符、信号处理方式等内核级属性。
4. 初始化程序运行环境
- 加载完成后,内核为程序设置初始运行环境:
- 栈初始化:在用户态栈中布置命令行参数(
argv)和环境变量(envp),并设置栈指针(%rsp)。- 动态链接器介入(若需要):
- 如果
hello是动态链接的程序(依赖libc.so等共享库),ELF 头部会指定动态链接器路径(如/lib64/ld-linux-x86-64.so.2)。- 内核会先启动动态链接器,由它负责加载所有依赖的共享库,并完成重定位(符号解析、地址修正)。
- 跳转到程序入口点:
- 对于静态链接程序,直接跳转到 ELF 头部指定的入口地址(通常是
_start函数,由编译器生成)。- 对于动态链接程序,由动态链接器完成初始化后,再跳转到
_start。5. 程序执行与用户态初始化
_start函数是程序的真正起点(由 C 运行时库crt0.o提供),它会执行一系列初始化:
- 调用
__libc_start_main(glibc 函数),完成:
- 初始化标准 I/O、线程库等。
- 注册程序退出时的清理函数。
- 最终调用用户编写的
main函数,并传递argc(参数数量)和argv(参数数组)。- 此时,
hello程序正式开始执行main函数中的逻辑。6. 程序退出与资源回收
- 当
main函数执行完毕(或调用exit()),程序进入退出流程:
- 执行所有通过
atexit()注册的清理函数。- 关闭打开的文件描述符,释放动态分配的内存等。
- 调用
exit_group()系统调用通知内核进程终止。- 内核回收进程的资源(虚拟地址空间、页表、
task_struct等)。- 若 Shell 正在等待(通过
waitpid()),则会收到子进程退出的信号,继续等待用户输入下一个命令。关键总结
./hello的执行过程是 “创建进程(fork)→ 替换程序(execve)→ 初始化环境 → 执行用户代码 → 退出回收” 的完整链条,涉及用户态(Shell、动态链接器)与内核态(进程管理、内存映射)的紧密协作。其中,fork+execve是 Linux 中启动新程序的核心机制,体现了 “先复制进程,再替换内容” 的设计思想。
进程终止:
exit()系统调用核心函数:
kernel/exit.c中的do_exit()void do_exit(long code) {struct task_struct *tsk = current;// 设置进程状态为EXIT_ZOMBIEtsk->exit_state = EXIT_ZOMBIE;// 释放大部分资源(内存、文件描述符等)exit_mm(tsk);exit_files(tsk);exit_fs(tsk);exit_sighand(tsk);exit_signal(tsk);// 通知父进程if (tsk->parent)ptrace_event_pid(tsk, PTRACE_EVENT_EXIT, task_pid(tsk));// 调用exit_notify()将子进程交给init进程exit_notify(tsk, false);// 调度其他进程执行schedule();// 不会执行到这里(进程已终止)BUG(); }这个函数也比较长,具体可自行查看源码。
更多待补充。
进程调度
调度器核心(
kernel/sched/目录)
CFS 调度器(Completely Fair Scheduler):Linux 默认调度器,位于
kernel/sched/fair.c。
- 核心思想:通过虚拟运行时间(vruntime)实现公平调度,确保每个进程获得公平的 CPU 时间。
- 数据结构:使用红黑树(
struct rb_root_cached)维护就绪进程,按 vruntime 排序。实时调度器:位于
kernel/sched/rt.c,支持 FIFO 和 RR两种策略。
关键调度函数
schedule()(kernel/sched/core.c):asmlinkage __visible void __sched schedule(void) {struct task_struct *tsk = current;sched_submit_work(tsk);do {__schedule();} while (need_resched()); }我们重点关注do循环里的行为,如果判断need_resched,那就执行调度__schedule()。
注意:这里用的是循环执行
在 Linux 内核的调度器实现中,这段循环(
do-while结构)的作用是确保进程调度完成后,系统处于 “无需再次调度” 的稳定状态,避免因调度过程中产生的新调度需求而导致的不完整调度。核心原因:调度过程可能触发新的调度需求
__schedule()是内核实际执行调度逻辑的函数(选择下一个要运行的进程并完成上下文切换)。但在调度过程中,可能出现以下情况导致 “新的调度需求”:
被唤醒的进程优先级更高:
在__schedule()执行期间,可能有高优先级进程(如实时进程)被唤醒,此时内核会设置TIF_NEED_RESCHED标志(表示需要重新调度)。调度过程中发生了抢占:
上下文切换过程中,可能触发某些事件(如中断、信号处理),导致当前选择的 “下一个进程” 不再是最优选择,需要重新调度。内核抢占机制的影响:
若内核支持抢占(CONFIG_PREEMPT开启),__schedule()执行期间可能被更高优先级的任务打断,打断后需要重新检查调度需求。循环的作用:确保 “彻底完成调度”
do-while (need_resched())循环的逻辑是:
- 先执行
__schedule()完成一次调度(切换到某个进程)。- 调用
need_resched()检查是否存在新的调度需求(即TIF_NEED_RESCHED标志是否被设置)。- 若存在新需求(
need_resched()返回真),则再次执行__schedule(),直到不再需要调度为止。这种 “执行 - 检查 - 再执行” 的循环,保证了最终运行的进程是 “当前系统中最应该运行的进程”,避免一次调度后立即出现新的调度需求而导致的频繁切换或优先级反转。
举例说明
假设系统中存在三个进程,优先级从高到低为
A(实时)> B(普通)> C(普通):
- 初始时
C正在运行,A和B处于休眠状态。A被唤醒,内核设置TIF_NEED_RESCHED标志,触发调度。- 第一次
__schedule()执行,选择A运行,但在切换过程中,B也被唤醒(优先级高于A以外的进程,但低于A)。need_resched()检查发现:虽然A已运行,但可能存在其他调度需求(例如B的唤醒不影响A,但假设此时又有更高优先级的事件触发),循环继续。- 第二次
__schedule()执行,确认A仍是最高优先级,无新需求,循环退出。最终确保
A稳定运行,不会因一次调度不彻底而导致错误。总结
do-while循环的核心目的是处理调度过程中可能出现的 “新调度需求”,通过反复执行调度逻辑直到系统处于 “无需再调度” 的状态,保证调度结果的正确性和稳定性。这是内核应对复杂并发场景(多进程竞争、中断、抢占等)的重要机制。
__schedule();
接下来就重点看下这个函数
/** __schedule() is the main scheduler function.** The main means of driving the scheduler and thus entering this function are:** 1. Explicit blocking: mutex, semaphore, waitqueue, etc.** 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return* paths. For example, see arch/x86/entry_64.S.** To drive preemption between tasks, the scheduler sets the flag in timer* interrupt handler scheduler_tick().** 3. Wakeups don't really cause entry into schedule(). They add a* task to the run-queue and that's it.** Now, if the new task added to the run-queue preempts the current* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets* called on the nearest possible occasion:** - If the kernel is preemptible (CONFIG_PREEMPT=y):** - in syscall or exception context, at the next outmost* preempt_enable(). (this might be as soon as the wake_up()'s* spin_unlock()!)** - in IRQ context, return from interrupt-handler to* preemptible context** - If the kernel is not preemptible (CONFIG_PREEMPT is not set)* then at the next:** - cond_resched() call* - explicit schedule() call* - return from syscall or exception to user-space* - return from interrupt-handler to user-space** WARNING: all callers must re-check need_resched() afterward and reschedule* accordingly in case an event triggered the need for rescheduling (such as* an interrupt waking up a task) while preemption was disabled in __schedule().*/ static void __sched __schedule(void) {struct task_struct *prev, *next;unsigned long *switch_count;struct rq *rq;int cpu;preempt_disable();cpu = smp_processor_id();rq = cpu_rq(cpu);rcu_note_context_switch();prev = rq->curr;schedule_debug(prev);if (sched_feat(HRTICK))hrtick_clear(rq);/** Make sure that signal_pending_state()->signal_pending() below* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)* done by the caller to avoid the race with signal_wake_up().*/smp_mb__before_spinlock();raw_spin_lock_irq(&rq->lock);rq->clock_skip_update <<= 1; /* promote REQ to ACT */switch_count = &prev->nivcsw;if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {if (unlikely(signal_pending_state(prev->state, prev))) {prev->state = TASK_RUNNING;} else {deactivate_task(rq, prev, DEQUEUE_SLEEP);prev->on_rq = 0;/** If a worker went to sleep, notify and ask workqueue* whether it wants to wake up a task to maintain* concurrency.*/if (prev->flags & PF_WQ_WORKER) {struct task_struct *to_wakeup;to_wakeup = wq_worker_sleeping(prev, cpu);if (to_wakeup)try_to_wake_up_local(to_wakeup);}}switch_count = &prev->nvcsw;}if (task_on_rq_queued(prev))update_rq_clock(rq);next = pick_next_task(rq, prev);clear_tsk_need_resched(prev);clear_preempt_need_resched();rq->clock_skip_update = 0;if (likely(prev != next)) {rq->nr_switches++;rq->curr = next;++*switch_count;rq = context_switch(rq, prev, next); /* unlocks the rq */cpu = cpu_of(rq);} elseraw_spin_unlock_irq(&rq->lock);post_schedule(rq);sched_preempt_enable_no_resched(); }
__schedule()是 Linux 内核调度器的核心实现函数,负责完成进程调度的核心逻辑:从运行队列中选择下一个要执行的进程,并完成与当前进程的上下文切换。它是schedule()函数的内部实现(通常schedule()会做一些前置检查,再调用__schedule())。核心功能
__schedule()的核心任务可以概括为:
- 暂停当前进程:保存当前进程的上下文(CPU 寄存器、栈指针等)。
- 选择下一个进程:调用当前调度类(
sched_class)的pick_next_task方法,从运行队列中选出 “最应该运行” 的进程(如 CFS 会选vruntime最小的进程,实时调度器会选优先级最高的进程)。- 切换进程上下文:恢复下一个进程的上下文,使其获得 CPU 执行权。
- 维护调度状态:更新运行队列、进程状态等信息(如将当前进程从运行队列移除,添加下一个进程到运行队列)。
关键流程拆解
1. 准备工作
- 关闭内核抢占(通过
preempt_disable()),避免调度过程被打断。- 保存当前进程的状态(如
current指针指向的task_struct)。- 检查当前进程是否需要让出 CPU(如状态为
TASK_INTERRUPTIBLE且等待的事件已发生)。2. 选择下一个进程
- 调用
pick_next_task(rq, current):根据当前进程的调度类(sched_class),从 CPU 的运行队列(rq,runqueue)中选择下一个进程(next)。
- 对于 CFS 调度类:通过
fair_sched_class.pick_next_task选择vruntime最小的进程。- 对于实时调度类:通过
rt_sched_class.pick_next_task选择优先级最高的实时进程。3. 上下文切换
- 若下一个进程(
next)与当前进程(current)不同,调用context_switch(rq, current, next)完成切换:
- 切换进程的地址空间(
switch_mm):更新页表,使 CPU 访问新进程的内存。- 切换进程的内核栈和寄存器(
switch_to):通过汇编指令保存当前进程的栈指针、程序计数器等,恢复next进程的寄存器状态。4. 收尾工作
- 更新调度统计信息(如进程的运行时间、切换次数)。
- 开启内核抢占(
preempt_enable()),允许新进程被更高优先级的进程抢占。关键特性
- 与调度类解耦:
__schedule()不直接实现调度算法,而是通过调用不同调度类(sched_class)的方法(如pick_next_task、enqueue_task)实现对普通进程、实时进程等的统一调度,体现了内核的模块化设计。- 原子性:执行过程中关闭内核抢占,确保调度逻辑不会被中断或其他进程干扰,保证状态一致性。
- 上下文切换的核心:
context_switch函数是进程切换的 “临门一脚”,通过硬件级别的寄存器切换,实现 CPU 执行权的转移。总结
__schedule()是 Linux 调度器的 “心脏”,它连接了调度策略(通过调度类)和硬件执行(通过上下文切换),实现了进程从 “让出 CPU” 到 “新进程获得 CPU” 的完整流程。无论是普通进程的公平调度,还是实时进程的优先级抢占,最终都依赖__schedule()完成实际的切换工作。
在Linux中,./hello 执行一个进程时,默认是采用什么样的调度策略以及对应的优先级值?
在 Linux 中,当你执行
./hello这样的普通用户进程时,默认采用的调度策略和优先级如下:1. 默认调度策略:
SCHED_OTHER(也称为SCHED_NORMAL)这是 Linux 中普通进程的默认调度策略,属于分时调度策略(time-sharing)。其核心特点是:
- 基于优先级的动态优先级调度:内核会根据进程的运行情况动态调整优先级(如长时间运行的进程优先级会降低,休眠等待 I/O 的进程优先级会适当提高)。
- 公平性:调度器(CFS,Completely Fair Scheduler)会尽量保证每个进程获得公平的 CPU 时间片,优先级高的进程获得的 CPU 时间比例更大。
- 适用于绝大多数用户态应用(如命令行程序、文本编辑器、后台服务等),不需要实时响应保证。
2. 默认优先级值
在
SCHED_OTHER策略下,优先级通过静态优先级(用户可配置)和动态优先级(内核动态调整)共同决定:
- 静态优先级:默认值为 120(范围是 100~139)。
这个值对应nice值为 0(nice值范围是 -20~19,静态优先级 = 120 + nice 值)。- 动态优先级:由内核根据进程行为动态调整(如 I/O 密集型进程可能被提高优先级),但始终在静态优先级附近波动。
补充说明
- 如果需要修改进程的优先级,可通过
nice命令(启动时设置)或renice命令(运行时调整)修改nice值。例如:nice -n 5 ./hello # 启动时设置 nice 值为 5(静态优先级 125) renice +10 -p 1234 # 将 PID 为 1234 的进程 nice 值改为 10nice值越小(可低至 -20),进程优先级越高(静态优先级低至 100);nice值越大(高至 19),优先级越低(静态优先级高至 139)。总结
./hello这样的普通进程默认使用SCHED_OTHER(分时)调度策略,静态优先级为 120(对应nice值 0),由 CFS 调度器进行公平调度。
为什么nice值还有个静态优先级?
在 Linux 中,
nice值与 “静态优先级” 紧密关联但又有所区别,这种设计是为了平衡用户态优先级调整的便捷性和内核调度的高效性。理解它们的关系需要从调度系统的分层设计说起:1.
nice值:用户态可见的 “优先级调整接口”
nice值是用户态程序能直接感知和调整的优先级参数,范围是 -20(最高)~19(最低),默认值为 0。它的作用是:
- 提供一个直观、简单的优先级调整方式(用户无需了解内核细节,通过
nice/renice命令即可调整)。- 反映进程 “谦让度”:
nice值越大(如 19),进程越 “谦让”(愿意让出 CPU 给其他进程);值越小(如 -20),进程越 “积极”(更渴望获得 CPU)。2. 静态优先级:内核内部的 “基础优先级”
静态优先级是内核内部使用的优先级数值,范围是 100~139(对应
SCHED_NORMAL调度策略的进程),它与nice值存在固定映射关系:
静态优先级 = 120 + nice 值
例如:
nice=0→ 静态优先级 120(默认值)nice=-20→ 静态优先级 100(最高)nice=19→ 静态优先级 139(最低)静态优先级的作用是:
- 作为内核调度器(如 CFS)的基础计算参数,直接参与
vruntime(虚拟运行时间)的计算(优先级越高,vruntime增长越慢,获得 CPU 时间越多)。- 屏蔽用户态与内核态的优先级表示差异,让内核可以用统一的数值体系处理调度逻辑。
3. 为什么需要 “静态优先级” 这一层?
(1)隔离用户态与内核态的优先级表示
用户态需要简单直观的参数(
nice值范围小,语义明确),而内核态需要更精细、更符合调度算法的数值体系(静态优先级范围与实时优先级不重叠,便于区分)。
例如:实时优先级是 1~99,静态优先级是 100~139,内核可通过数值大小直接判断 “实时进程优先级高于普通进程”,无需额外逻辑。(2)为动态优先级调整提供 “基准”
内核会根据进程行为(如 I/O 密集型还是 CPU 密集型)动态调整优先级(动态优先级),但动态调整必须以静态优先级为基准(不能超出静态优先级的范围)。
例如:一个nice=0(静态优先级 120)的 I/O 密集型进程,动态优先级可能暂时提高到 115(仍在 100~139 范围内),但不会超过静态优先级的上限。(3)兼容历史设计与调度算法
早期 Linux 调度器(如 O (1) 调度器)直接使用静态优先级进行调度决策,CFS 虽然引入了
vruntime,但仍保留静态优先级作为权重计算的基础(nice值通过静态优先级转换为 CFS 中的 “权重”)。4. 总结:
nice值与静态优先级的关系
nice值是用户态接口,用于直观调整进程优先级,范围 -20~19。- 静态优先级是内核态实现,是
nice值的 “内核表示形式”,范围 100~139,与nice值一一对应。- 静态优先级是内核调度的 “锚点”,既关联了用户态的调整需求,又为内核的动态优先级计算和调度决策提供了稳定的基础。
这种分层设计既保证了用户操作的简洁性,又满足了内核调度的复杂性需求,是 Linux 兼顾易用性和高效性的典型实现。
CFS的公平性体现在哪?
Linux 的 CFS(Completely Fair Scheduler,完全公平调度器)是针对普通进程(
SCHED_NORMAL策略)的默认调度器,其 “公平性” 核心体现在让每个进程获得与其优先级成正比的 CPU 时间,避免单个进程长期占用 CPU 而导致其他进程饥饿。具体实现上,CFS 的公平性通过以下机制保证:1. 基于 “虚拟运行时间” 的调度决策
CFS 引入了
vruntime(虚拟运行时间) 概念,作为衡量进程 “已占用 CPU 资源” 的核心指标:
- 每个进程的
vruntime会随其实际运行时间增长,但增长速度与优先级相关:
- 优先级高的进程:
vruntime增长 slower(相同实际时间下,vruntime增加更少),因此能获得更多 CPU 时间。- 优先级低的进程:
vruntime增长 faster(相同实际时间下,vruntime增加更多),获得的 CPU 时间更少。- 调度器始终选择
vruntime最小的进程 运行,确保 “欠账”(获得 CPU 时间少)的进程优先得到调度。2. 动态调整时间片,避免 “一刀切”
CFS 不采用固定时间片,而是根据系统中可运行进程的数量动态分配 CPU 时间:
- 当可运行进程少(如 1~2 个):每个进程可获得较长的连续运行时间(减少切换开销)。
- 当可运行进程多(如数十个):每个进程获得的时间片按比例缩小,但仍保证 “按优先级分配比例”。
- 例如:若系统中有 2 个相同优先级的进程,理想情况下各获得 50% 的 CPU 时间;若有 4 个,则各获得 25%。
3. 优先级与 “权重” 的映射:比例公平
CFS 将进程的
nice值(用户态优先级,范围 -20~19)转换为 “权重”(weight):
nice值越小(优先级越高),权重越大(如nice=0对应权重 1024,nice=-20对应权重 88761)。- 进程获得的 CPU 时间比例与其权重成正比:若进程 A 权重是进程 B 的 2 倍,则 A 获得的 CPU 时间约为 B 的 2 倍。
- 这种 “比例公平” 机制确保高优先级进程获得更多资源,但低优先级进程也不会被完全饿死(仍能获得与其权重匹配的时间)。
4. 抢占机制:防止长时占用
当正在运行的进程
vruntime增长到超过系统中其他进程的vruntime时,CFS 会触发抢占:
- 暂停当前进程,将 CPU 分配给
vruntime更小的进程。- 这种 “按需抢占” 避免了单个进程长时间独占 CPU,确保所有进程能及时得到调度。
5. 对 I/O 密集型进程的友好性
CFS 会通过动态优先级调整间接优化 I/O 密集型进程(如等待键盘输入、磁盘读写的进程):
- I/O 密集型进程大部分时间处于休眠状态(不消耗 CPU),
vruntime增长缓慢,因此唤醒后更容易因vruntime较小而被优先调度。- 这使得用户交互类程序(如文本编辑器、浏览器)即使优先级不高,也能快速响应输入,提升用户体验。
总结
CFS 的公平性并非 “平均分配 CPU 时间”,而是 **“按优先级比例分配资源”**:
- 通过
vruntime追踪进程的 “资源消耗”,确保 “欠账” 进程优先调度;- 用权重映射优先级,保证高优先级进程获得更高比例的 CPU 时间;
- 动态调整时间片和抢占机制,避免单个进程垄断资源。
这种设计在兼顾效率(减少切换开销)的同时,最大化了普通进程的调度公平性,是 Linux 对多任务环境的核心优化。
Linux什么时候需要使用实时调度?
在 Linux 中,实时调度(Real-Time Scheduling)适用于对响应时间有严格要求的场景,即需要进程在确定的时间内完成操作,不允许因调度延迟导致任务超时。这类场景通常涉及实时控制、嵌入式系统、高性能数据处理等领域,核心需求是 **“确定性响应”**(确保任务在 deadline 前完成)。
以下是需要使用实时调度的典型场景:
1. 工业控制与自动化
- 例如:生产线机器人控制、数控机床、工业传感器数据采集。
这类系统要求对外部事件(如传感器信号、机械触发)做出微秒级或毫秒级响应,否则可能导致生产事故或设备损坏。
例:机器人焊接时,若控制程序因调度延迟未能及时调整焊枪位置,可能造成焊接偏差。2. 嵌入式实时系统
- 例如:汽车电子(防抱死刹车系统 ABS、发动机控制单元 ECU)、航空航天设备(飞行控制系统)。
这类场景中,任务必须在严格的时间窗口内完成(如 ABS 需在毫秒内响应车轮转速变化),否则可能危及安全。3. 多媒体与数据采集
- 例如:实时音频处理(如音频混音、降噪)、高速数据采集(如雷达信号处理、医疗设备监测)。
若处理延迟超过数据生成速度,会导致数据丢失或音视频卡顿(如实时直播中音频与视频不同步)。4. 实时通信
- 例如:高频交易系统、实时视频会议的信令控制、工业以太网协议处理。
高频交易中,毫秒级的延迟可能导致交易机会错失;实时通信中,信令处理延迟会影响通话质量。实时调度与普通调度的核心区别
维度 普通调度(如 CFS) 实时调度(如 SCHED_FIFO/SCHED_RR) 目标 公平分配 CPU 时间 确保高优先级任务优先执行,满足时间约束 优先级范围 低(nice 值 -20~19,对应 100~139) 高(1~99,值越大优先级越高) 调度策略 动态调整优先级,分时共享 严格按优先级抢占,低优先级任务可被高优先级任务打断 响应时间 不确定(可能因负载波动延迟) 确定(可通过优先级保证最大延迟) Linux 中的实时调度策略
Linux 提供了两种主要的实时调度策略(优先级 1~99):
SCHED_FIFO(先进先出实时调度):
高优先级任务一旦获得 CPU,会一直运行直到主动放弃(如调用sleep)或被更高优先级的实时任务抢占。SCHED_RR(时间片轮转实时调度):
同优先级的实时任务按时间片轮转执行,确保同优先级任务公平分配 CPU,但仍会被更高优先级任务抢占。总结
当系统需要确定性的响应时间(而非 “公平共享 CPU”),且任务延迟可能导致功能失效、安全风险或数据丢失时,就需要使用 Linux 的实时调度策略。实时调度通过严格的优先级抢占机制,确保关键任务优先执行,满足实时性要求。
如何让程序以实时调度的策略来运行?
在 Linux 中,要让程序以实时调度策略运行,需要通过系统调用或命令行工具指定实时调度策略(如
SCHED_FIFO或SCHED_RR)及相应优先级。以下是具体实现方法:一、前提条件
- 权限要求:实时调度策略需要
CAP_SYS_NICE权限(通常需要 root 权限,或通过setcap给程序赋予特定权限)。- 优先级范围:实时优先级为 1~99(值越大优先级越高,注意:实时优先级高于所有普通进程)。
二、方法 1:通过命令行工具
chrt运行程序
chrt是 Linux 自带的命令行工具,可直接指定程序的调度策略和优先级,适合快速测试。常用语法:
chrt [选项] 优先级 程序 [程序参数]示例:
以
SCHED_FIFO策略(优先级 50)运行./realtime_app:sudo chrt -f 50 ./realtime_app以
SCHED_RR策略(优先级 30)运行./realtime_app:sudo chrt -r 30 ./realtime_app选项说明:
-f:使用SCHED_FIFO调度策略(先进先出,高优先级任务可抢占低优先级任务,直到主动放弃 CPU)。-r:使用SCHED_RR调度策略(时间片轮转,同优先级任务轮流执行,时间片用完后切换)。三、方法 2:在程序代码中通过系统调用设置
在 C/C++ 程序中,可通过
sched_setscheduler系统调用在运行时设置调度策略和优先级,更灵活可控。核心步骤:
- 定义
sched_param结构体,设置实时优先级。- 调用
sched_setscheduler函数,指定调度策略(SCHED_FIFO或SCHED_RR)。示例代码:
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sched.h> #include <errno.h>int main() {struct sched_param param;int policy;// 1. 配置实时优先级(1~99,值越大优先级越高)memset(¶m, 0, sizeof(param));param.sched_priority = 50; // 设置优先级为 50// 2. 设置调度策略为 SCHED_FIFO(或 SCHED_RR)policy = SCHED_FIFO; // 可选:SCHED_FIFO 或 SCHED_RRif (sched_setscheduler(0, policy, ¶m) == -1) {perror("sched_setscheduler failed");fprintf(stderr, "请确保程序以 root 权限运行,或具有 CAP_SYS_NICE 权限\n");exit(EXIT_FAILURE);}// 3. 验证设置是否生效int current_policy = sched_getscheduler(0);if (current_policy == -1) {perror("sched_getscheduler failed");exit(EXIT_FAILURE);}struct sched_param current_param;if (sched_getparam(0, ¤t_param) == -1) {perror("sched_getparam failed");exit(EXIT_FAILURE);}printf("实时调度策略设置成功:\n");printf("策略:%s\n", current_policy == SCHED_FIFO ? "SCHED_FIFO" : (current_policy == SCHED_RR ? "SCHED_RR" : "未知"));printf("优先级:%d\n", current_param.sched_priority);// 4. 实时任务逻辑(示例:循环打印信息)for (int i = 0; i < 5; i++) {printf("实时任务运行中...(%d/5)\n", i+1);sleep(1); // 模拟任务执行}return 0; }设置实时调度策略的示例程序
编译与运行:
gcc realtime_demo.c -o realtime_demo sudo ./realtime_demo # 需要 root 权限四、方法 3:给非 root 程序赋予实时调度权限
如果不想用 root 运行程序,可通过
setcap命令给程序赋予CAP_SYS_NICE权限sudo setcap cap_sys_nice+ep ./realtime_demo # 赋予权限 ./realtime_demo # 非 root 也可运行五、验证实时调度是否生效
查看进程调度信息:
ps -eo comm,pid,pri,policy | grep 程序名
policy列中,FF表示SCHED_FIFO,RR表示SCHED_RR。pri列显示实时优先级(1~99)。通过
chrt查看进程当前调度策略:chrt -p 进程PID注意事项
- 实时进程会抢占普通进程(包括内核线程),滥用可能导致系统响应缓慢(如高优先级实时进程长期占用 CPU,导致其他任务饿死)。
- 实时任务应尽可能短,避免长时间占用 CPU(可通过
sched_yield()主动让出 CPU)。SCHED_FIFO适合需要连续执行的任务(如工业控制),SCHED_RR适合同优先级任务需要公平轮转的场景。通过以上方法,可让程序以实时调度策略运行,满足对响应时间有严格要求的场景(如实时控制、高频数据处理等)。
相关字段
关于进程调度,进程描述符里有如下字段:
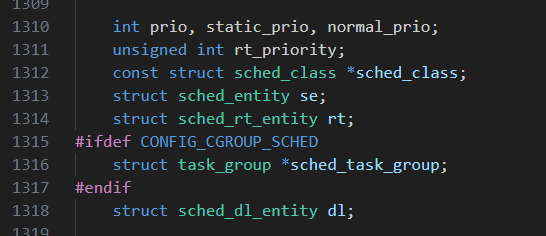
prio
static_prio
normal_prio
rt_priority;
这里有四个优先级
在 Linux 内核的进程描述符(
struct task_struct)中,这几个字段用于表示进程的优先级信息,分别对应不同场景下的优先级类型,核心作用是支撑内核调度器的决策。以下是每个字段的具体含义:1.
static_prio(静态优先级)
- 定义:
int static_prio;- 作用:存储进程的基础优先级,一旦设置后不会被内核动态修改(除非用户主动调整)。
- 对于普通进程(
SCHED_NORMAL),取值范围是 100~139,与nice值直接对应(static_prio = 120 + nice值)。- 实时进程(
SCHED_FIFO/SCHED_RR)也有static_prio,但实际调度中不依赖该值(实时进程优先级由rt_priority决定)。- 是进程优先级的 “基准线”,决定了进程在 CFS 调度器中的初始权重(优先级越高,权重越大,获得 CPU 时间越多)。
2.
rt_priority(实时优先级)
- 定义:
unsigned int rt_priority;- 作用:仅用于实时进程,表示实时调度策略下的优先级。
- 范围:1~99(值越大,优先级越高),0 表示非实时进程(普通进程的
rt_priority为 0)。- 特点:
- 实时进程的
rt_priority高于所有普通进程(普通进程最高静态优先级 100 仍低于实时进程最低优先级 1)。- 决定实时进程之间的抢占关系:高
rt_priority的进程可以抢占低rt_priority的进程。3.
normal_prio(常规优先级)
- 定义:
int normal_prio;- 作用:表示进程在当前调度策略下的实际基础优先级,是调度器决策的核心参考之一。
- 计算逻辑:
- 对于普通进程:
normal_prio = static_prio(与静态优先级一致)。- 对于实时进程:
normal_prio = MAX_RT_PRIO - rt_priority(MAX_RT_PRIO为 100,因此实时进程的normal_prio范围是 1~99)。- 特点:
- 统一了普通进程和实时进程的优先级数值体系(实时进程
normal_prio1~99,普通进程 100~139),便于调度器快速比较优先级。4.
prio(动态优先级)
- 定义:
int prio;- 作用:表示进程的当前实际优先级,可能在
normal_prio基础上被内核动态调整。- 调整场景:
- 内核会根据进程行为临时调整
prio(如 I/O 密集型进程可能被提高优先级,CPU 密集型进程可能被降低)。- 处理信号、进程唤醒等场景时,也可能临时调整
prio以保证响应性。- 特点:
- 是调度器最终使用的优先级(
prio越小,优先级越高)。- 动态调整不会改变
static_prio和normal_prio,调整后会逐渐恢复到normal_prio。总结:四者的关系与调度意义
这四个字段从不同维度描述了进程优先级,核心作用是让调度器快速判断 “哪个进程更应该获得 CPU”:
static_prio是普通进程的 “基准值”,由用户通过nice控制。rt_priority是实时进程的 “特权值”,决定实时任务的抢占顺序。normal_prio是调度器的 “统一参考值”,让普通进程和实时进程的优先级可直接比较。prio是 “当前有效值”,反映进程在动态调整后的实时优先级。通过这四个字段的配合,Linux 内核实现了对普通进程(公平调度)和实时进程(优先级抢占)的统一管理,兼顾了系统的公平性和实时性。
继续看剩余的几个字段
调度类与调度实体
const struct sched_class *sched_class;
- 核心作用:指向进程所属的调度类,是 Linux 调度器 “模块化” 设计的核心。
- 调度类:内核将不同调度策略(如普通进程、实时进程、 deadline 进程)封装为不同的
sched_class,包含调度器回调函数(如如何选择下一个进程、如何入队 / 出队等)。- 常见调度类:
&fair_sched_class:对应普通进程(SCHED_NORMAL/SCHED_BATCH),由 CFS 调度器管理。&rt_sched_class:对应实时进程(SCHED_FIFO/SCHED_RR)。&dl_sched_class:对应 deadline 进程(SCHED_DEADLINE),用于强实时场景。&idle_sched_class:对应 idle 进程(系统空闲时运行的进程)。
struct sched_entity se;
- 作用:用于普通进程(CFS 调度器) 的调度实体,存储 CFS 调度所需的核心信息。
- 关键字段:
vruntime:虚拟运行时间,CFS 调度的核心指标(值越小,越先被调度)。run_node:连接到 CFS 运行队列(cfs_rq)的链表节点。weight:进程权重(由static_prio转换而来,决定 CPU 时间分配比例)。- 本质:CFS 调度器不直接操作
task_struct,而是通过sched_entity抽象进程的调度状态,简化调度逻辑。
struct sched_rt_entity rt;
- 作用:用于实时进程(
SCHED_FIFO/SCHED_RR) 的调度实体,存储实时调度所需信息。- 关键字段:
run_list:连接到实时运行队列(rt_rq)的链表节点。time_slice:SCHED_RR策略下的时间片(用完后触发同优先级进程切换)。prio:实时优先级(与task_struct的rt_priority对应)。
struct sched_dl_entity dl;
- 作用:用于 ** deadline 进程(
SCHED_DEADLINE)** 的调度实体,支持 “截止时间驱动” 的实时调度。- 关键字段:
deadline:任务的截止时间(必须在此之前完成)。runtime:每次周期内可使用的 CPU 时间。period:任务的运行周期。- 适用场景:对任务完成时间有严格要求的场景(如工业控制中的周期性任务),调度器会确保任务在
deadline前完成。控制组调度相关
#ifdef CONFIG_CGROUP_SCHED struct task_group *sched_task_group; #endif
- 作用:当内核启用控制组调度(
CONFIG_CGROUP_SCHED)时,该字段指向进程所属的任务组(task group)。- 任务组:是控制组(cgroup)在调度层面的抽象,用于实现 “按组分配 CPU 资源”(如限制某个容器内所有进程的总 CPU 使用率)。
- 功能:通过任务组,内核可将一组进程视为一个整体进行资源分配,实现更精细的资源隔离(如容器场景)。
总结
这些字段共同构成了 Linux 进程的 “调度属性集”,核心作用是:
- 通过
sched_class绑定进程到对应的调度器(CFS / 实时 /deadline)。- 通过
se/rt/dl存储不同调度器所需的具体调度状态(如vruntime用于 CFS,deadline用于 deadline 调度)。- 通过优先级字段(
prio/rt_priority等)决定进程的调度顺序和资源分配比例。- 通过
sched_task_group支持基于控制组的资源隔离。这种设计使 Linux 内核能够灵活支持多种调度策略,兼顾普通进程的公平性、实时进程的确定性和容器场景的资源隔离需求。
进程同步机制
信号量(Semaphore)
实现:
kernel/locking/semaphore.cstruct semaphore {raw_spinlock_t lock;unsigned int count;struct list_head wait_list; };// 初始化信号量 void sema_init(struct semaphore *sem, int val);// 申请信号量(可能睡眠) void down(struct semaphore *sem);// 释放信号量 void up(struct semaphore *sem);互斥锁(Mutex)
实现:
kernel/locking/mutex.cstruct mutex {atomic_t count;spinlock_t wait_lock;struct list_head wait_list; };// 初始化互斥锁 void mutex_init(struct mutex *mutex);// 加锁(可能睡眠) void mutex_lock(struct mutex *mutex);// 解锁 void mutex_unlock(struct mutex *mutex);自旋锁(Spinlock)
实现:
include/linux/spinlock.htypedef struct spinlock {union {struct raw_spinlock rlock; #ifdef CONFIG_DEBUG_LOCK_ALLOC# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))struct {u8 __padding[LOCK_PADSIZE];struct lockdep_map dep_map;}; #endif}; } spinlock_t;// 加锁(忙等待,不睡眠) void spin_lock(spinlock_t *lock);// 解锁 void spin_unlock(spinlock_t *lock);如下图:
注意,这里是进程间通信,不是信号signal的实现。
进程间通信(IPC)
信号(Signal)
核心文件:
kernel/signal.c关键函数:
// 发送信号 int kill_pid_info(int sig, struct siginfo *info, struct pid *pid);// 信号处理注册 int do_sigaction(int sig, const struct k_sigaction *act,struct k_sigaction *old);// 信号处理流程 void handle_signal(struct pt_regs *regs, int signr,sigset_t *oldset, int syscall);共享内存、消息队列、信号量(System V IPC)
实现:
ipc/目录
- 共享内存:
shm.c- 消息队列:
msg.c- 信号量:
sem.c
kernel/locking目录下的信号量和ipc目录下的信号量有啥区别?
Linux 内核中
kernel/locking/目录下的信号量与ipc/目录下的信号量虽然名称相同,但其设计目标、使用场景和实现机制有本质区别,核心差异体现在作用范围和使用对象上:
特性 kernel/locking/信号量(内核信号量)ipc/目录信号量(System V IPC 信号量)定义位置 kernel/locking/semaphore.cipc/sem.c核心目标 用于内核态代码的同步(如驱动、内核线程) 用于用户态进程间的同步与互斥 接口暴露方式 仅内核函数调用(如 down()、up())通过系统调用( semget()、semop()等)向用户态暴露两者的核心区别可概括为:
kernel/locking/信号量是内核态的同步工具,用于解决内核内部的并发访问问题,接口仅对内可见。ipc/信号量是用户态进程间的同步工具,通过系统调用提供服务,用于协调用户进程对共享资源的访问。简单说,前者是 “内核自己用的同步锁”,后者是 “给用户进程用的同步锁”,二者属于不同层次的机制,互不干扰但都依赖内核的调度和等待队列机制实现。
为什么IPC下没有POSIX的IPC,都是system V的IPC?
在 Linux 内核源码中,
ipc/目录主要存放 System V IPC 的实现(如消息队列、信号量、共享内存),而 POSIX IPC 的实现并未放在该目录下,这并非因为 Linux 不支持 POSIX IPC,而是由历史原因、实现机制差异和内核代码组织逻辑共同决定的。1. 历史背景:System V IPC 更早进入内核
- System V IPC 是 Unix 系统早期(1980 年代 System V 版本)引入的进程间通信机制,Linux 作为类 Unix 系统,早期为了兼容 Unix 生态,优先实现了 System V IPC,并将其集中放在
ipc/目录下。这部分代码是 Linux 内核早期设计的一部分,形成了固定的目录结构。- POSIX IPC 是 1990 年代 POSIX 标准(如 IEEE Std 1003.1)提出的新一代 IPC 机制,其设计目标是解决 System V IPC 的一些缺陷(如接口复杂、权限管理繁琐等)。Linux 对 POSIX IPC 的支持是后来逐步添加的(1990 年代末至 2000 年代),此时内核代码结构已相对稳定,因此没有将其归入传统的
ipc/目录。2. POSIX IPC 在 Linux 内核中的实际存放位置
POSIX IPC 并非不存在于 Linux 内核中,只是实现位置分散在其他目录,原因是其实现依赖于更底层的内核子系统(如文件系统、命名空间),而非独立的 “IPC 专属目录”:
- POSIX 消息队列:实现位于
fs/mqueue/(依赖文件系统机制,通过虚拟文件系统mqueuefs暴露接口)。- POSIX 信号量:分为两种:
- 进程间信号量(命名信号量):实现依赖于文件系统,部分逻辑在
fs/semaphore.c或ipc/目录外的同步机制中。- 线程间信号量(无名信号量):本质是用户态库实现(基于
pthread库,依赖内核的futex机制,无需内核单独目录)。- POSIX 共享内存:通过
tmpfs(临时文件系统)实现,代码主要在mm/shmem.c(依赖内存管理子系统)。3. 核心差异:实现机制与内核耦合度
System V IPC 和 POSIX IPC 的实现机制差异,决定了它们在代码目录中的位置:
System V IPC:
是独立于文件系统的 “传统 IPC 机制”,有自己的命名空间(通过键值key_t标识)、权限管理和生命周期管理,实现逻辑相对封闭,因此被集中放在ipc/目录,形成一个独立的子系统。POSIX IPC:
设计上更贴近 “文件系统语义”(例如,POSIX 消息队列通过路径名/mqname标识,类似文件),其实现严重依赖 虚拟文件系统(VFS) 和 命名空间 机制。例如:
- POSIX 消息队列通过
mqueuefs虚拟文件系统挂载到/dev/mqueue,用户态通过open()/read()/write()等文件操作接口访问(而非专用系统调用)。- POSIX 共享内存本质是
tmpfs中的文件,通过mmap()映射到进程地址空间,依赖内存管理子系统。
因此,POSIX IPC 的代码自然分散到fs/(文件系统)、mm/(内存管理)等目录,与这些子系统的代码耦合,而非单独放在ipc/目录。4. 内核代码组织的逻辑:按 “功能子系统” 划分,而非 “IPC 标准”
Linux 内核代码的组织原则是按功能子系统划分(如文件系统、内存管理、进程调度),而非按 “符合哪个标准”(System V 或 POSIX)划分:
ipc/目录的定位是 “存放与文件系统无关的传统 IPC 机制”,而 System V IPC 恰好符合这一特征。- POSIX IPC 因依赖文件系统和内存管理,被归入对应的功能子系统目录(
fs/、mm/),更符合 “功能内聚” 的代码组织逻辑。5. 总结
Linux 内核
ipc/目录只放 System V IPC,而 POSIX IPC 不在其中,核心原因是:
- 历史原因:System V IPC 更早实现,占据了
ipc/目录作为传统 IPC 子系统的位置。- 实现机制:POSIX IPC 依赖文件系统和 VFS,与
fs/、mm/等子系统耦合,因此代码分散在对应目录。- 代码组织逻辑:内核按 “功能子系统” 划分目录,而非 “标准类型”,因此不同标准的 IPC 机制会因实现依赖不同而分布在不同位置。
简言之,
ipc/目录是 System V IPC 的 “专属区域”,而 POSIX IPC 因设计上更贴近文件系统,被整合到了内核的文件和内存管理框架中。
总结
Linux 的进程管理源码通过
task_struct数据结构和模块化设计,实现了复杂而高效的进程管理系统。其核心机制包括进程创建、调度、同步和终止,这些功能分布在kernel/、include/linux/等目录中。理解这些源码是深入掌握 Linux 内核工作原理的关键,也为开发高性能应用和内核模块提供了基础。