深入理解程序链接机制:静态链接、ELF加载与动态库实现原理
目录
一、静态链接
1、静态链接的基本概念
1. 静态链接实例分析
2. 目标文件分析
3. 关键观察
4. 重定位机制
5. 注意事项
2、静态链接过程详解
1. 目标文件反汇编分析(上面已分析)
2. 符号表分析
code.o 符号表
hello.o 符号表
3. 链接后的可执行文件分析
可执行文件符号表
可执行文件段信息
4. 链接地址修正验证
5. 静态链接过程总结
二、ELF加载与进程地址空间
1、虚拟地址/逻辑地址
核心问题探讨
平坦模式 vs. 分段模式(历史对比)
2、进程虚拟地址空间再认识
ELF入口地址机制
关键技术要点
3、使用图来说明过程
1. 磁盘存储阶段(右侧)
2. 加载过程(箭头)
3. 物理内存管理(中部)
4. CPU执行机制(左侧)
5. 地址转换关键路径
三、动态链接与动态库加载
1、进程如何访问动态库
1. 进程与内存管理结构
2. 虚拟地址到物理内存的映射
3. 动态库的加载过程
4. 进程访问动态库的流程
5. 关键特性
图示总结
2、进程间如何共享动态库
基本原理
详细过程解析
1. 进程结构
2. 动态库加载过程
3. 内存管理细节
4. 优势
实际应用示例
3、动态链接机制详解
1. 动态链接概述
为什么默认使用动态链接而非静态链接?
2、动态链接工作原理
3、可执行文件中的动态链接痕迹
4、程序启动流程与动态链接
5. 动态库中的地址编址方案
动态库反汇编示例
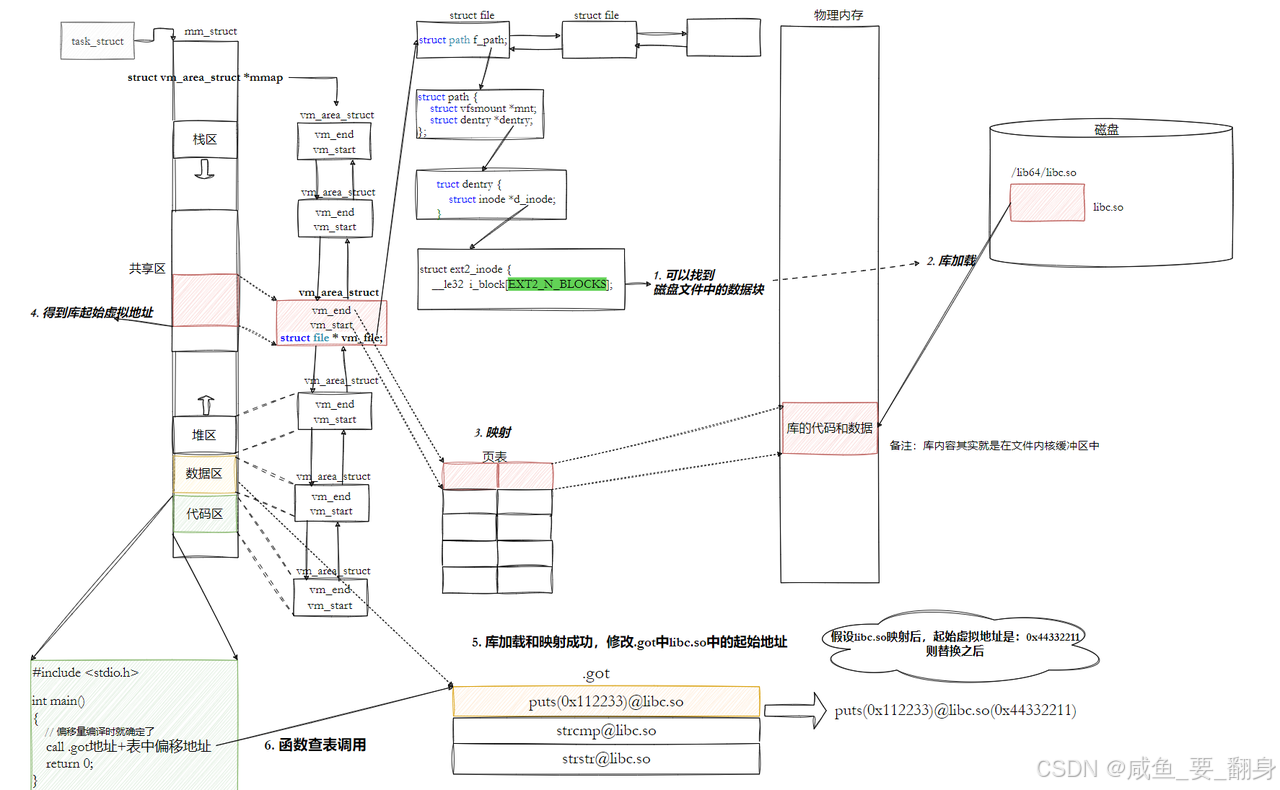
6. 程序与动态库的映射机制
关键实现原理
技术实现要点
1. 进程虚拟地址空间布局(左侧起点)
2. 文件系统定位库文件(右侧起点)
3. 库加载与映射流程(核心箭头方向)
4. 关键机制与数据结构
总结
7. 库函数调用机制详解
调用前提条件
调用原理
调用过程特征
8. 全局偏移量表(GOT)机制详解
GOT基本概念
动态链接的必要条件
地址重定位机制
GOT的创新设计
ELF文件中的GOT
加载特性
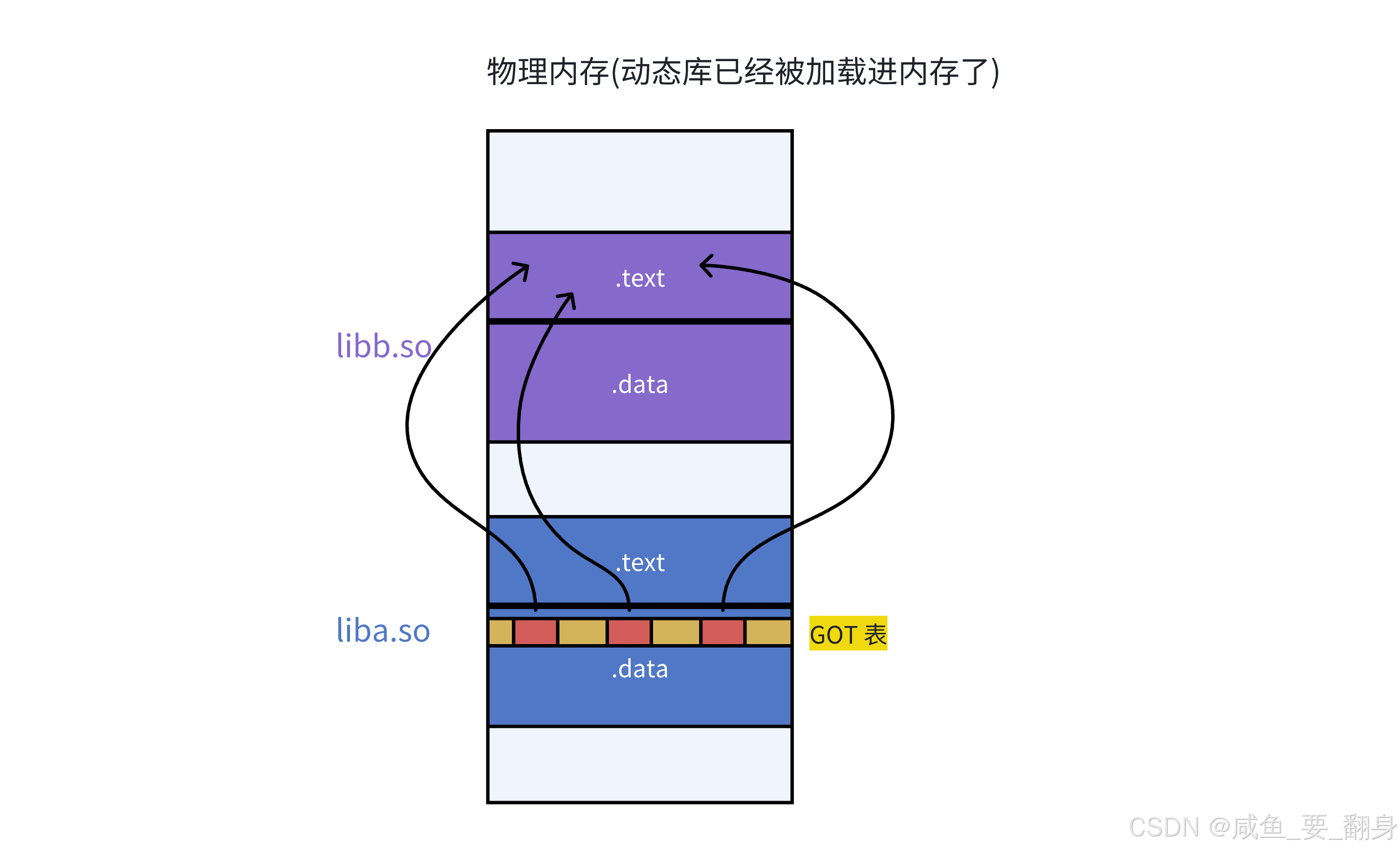
9. 全局偏移量表(GOT)与位置无关代码(PIC)机制详解
GOT表的进程隔离特性
GOT表的定位机制
动态链接调用流程
位置无关代码(PIC)原理
实例分析
PLT(过程链接表)说明
10. 库间依赖关系
动态链接中的库依赖
动态链接的优势
依赖关系的解析
四、总结:静态链接与动态链接对比
1、静态链接
2、动态链接
3、核心区别
一、静态链接
1、静态链接的基本概念
静态链接的本质是将目标文件(.o)进行连接的过程,无论是用户自己编译的.o文件还是静态库中的.o文件。因此,研究静态链接的核心就是理解.o文件是如何被链接的。
1. 静态链接实例分析
下面通过一个具体示例演示静态链接过程,源代码如下:
// hello.c
#include<stdio.h>
void run();
int main()
{printf("hello world!\n");run();return 0;
}// code.c
#include<stdio.h>
void run()
{printf("running...\n");
}-
首先查看源代码文件:

-
编译生成目标文件:
gcc -c *.c -
链接生成可执行文件:
gcc *.o -o main.exe -
查看生成的文件:
2. 目标文件分析
使用objdump工具查看目标文件的反汇编代码:
-
code.o的反汇编结果:
objdump -d code.o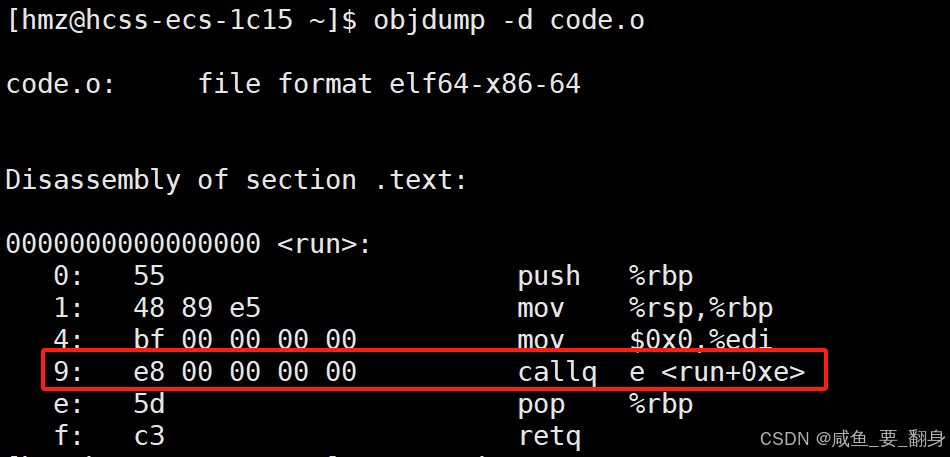
-
hello.o的反汇编结果:
objdump -d hello.o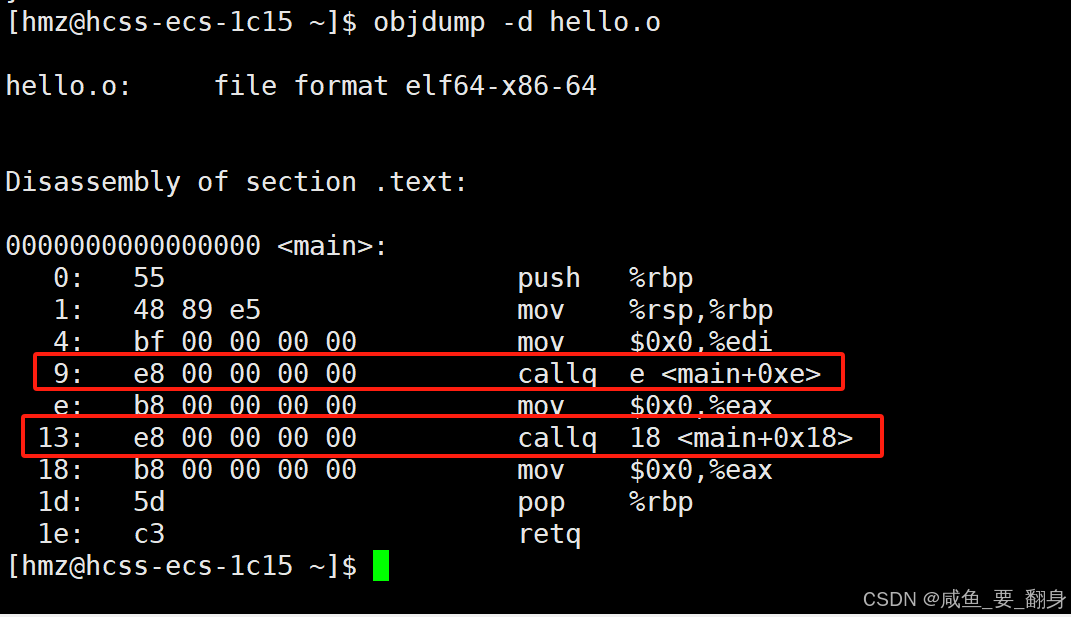
3. 关键观察
-
使用
objdump -d命令可以查看目标文件的代码段(.text)的反汇编结果。 -
如图,在hello.o中,main函数调用了printf和run函数,但在编译阶段并不知晓这些函数的具体位置,所以call对应的跳转地址全都被临时设置为0。
-
如图,在code.o中,run函数调用了printf函数,同样不知道其具体位置,call对应的跳转地址全都被临时设置为0。
4. 重定位机制
从反汇编结果可以看到,call指令的跳转地址都被临时设置为0。这是因为:
-
在编译阶段,编译器无法知道外部函数(如printf和run)的内存地址。
-
编译器会生成重定位表(.rela.text),记录需要修正的地址位置。
-
链接器在链接阶段会根据重定位表修正这些地址。
5. 注意事项
-
printf函数涉及到动态链接库,其最终解析会在程序加载时完成(动态链接)。
-
静态链接主要处理用户定义的函数和静态库中的函数。
2、静态链接过程详解
1. 目标文件反汇编分析(上面已分析)
关键观察:
-
在编译阶段,编译器无法确定外部函数(如printf和run)的具体地址
-
call指令的跳转地址被临时设置为0
-
编译器会生成重定位表(.rela.text),记录需要修正的地址位置
2. 符号表分析
使用readelf查看符号表信息:
code.o 符号表
readelf -s code.o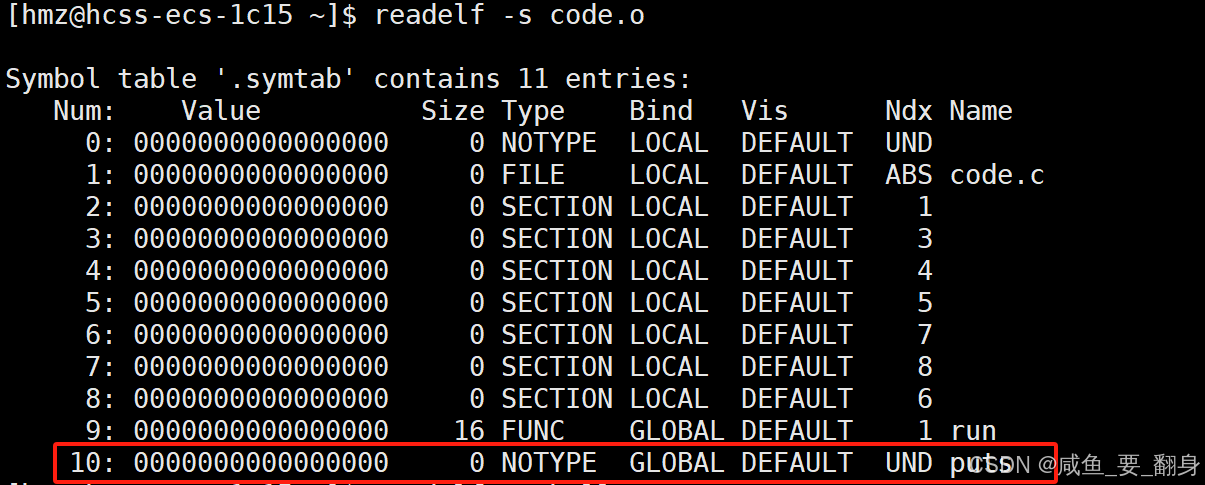
hello.o 符号表
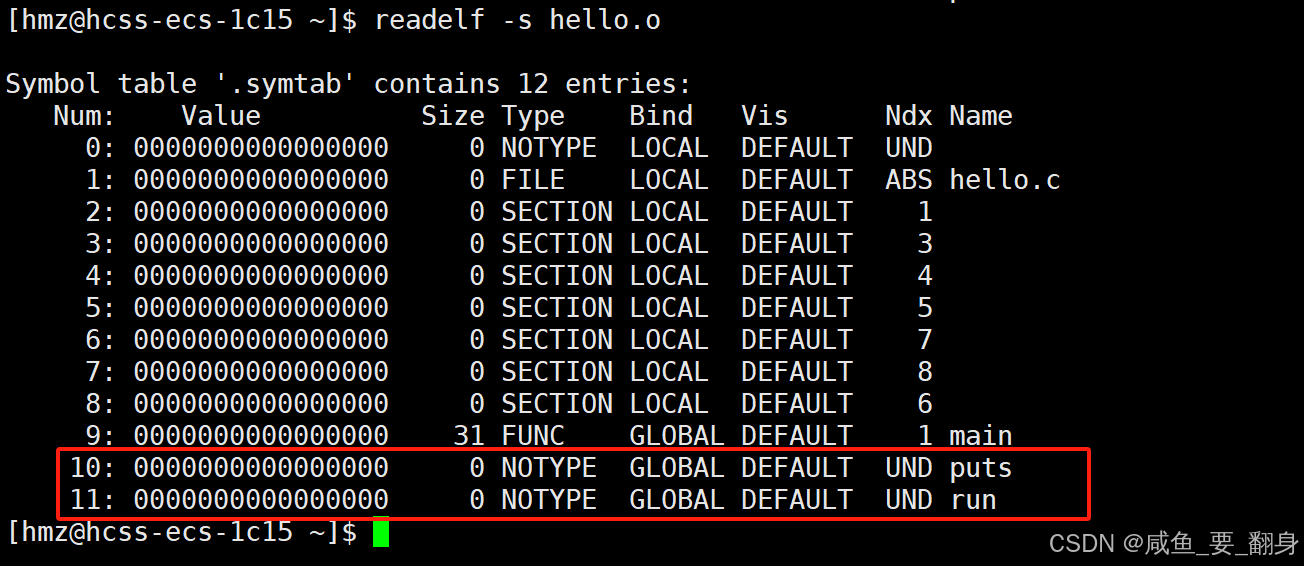
符号表关键信息:
-
UND (undefine) 表示该符号在当前目标文件中未定义
-
puts是printf的实际实现
-
run函数在hello.o中未定义(定义在code.o中)
3. 链接后的可执行文件分析
可执行文件符号表
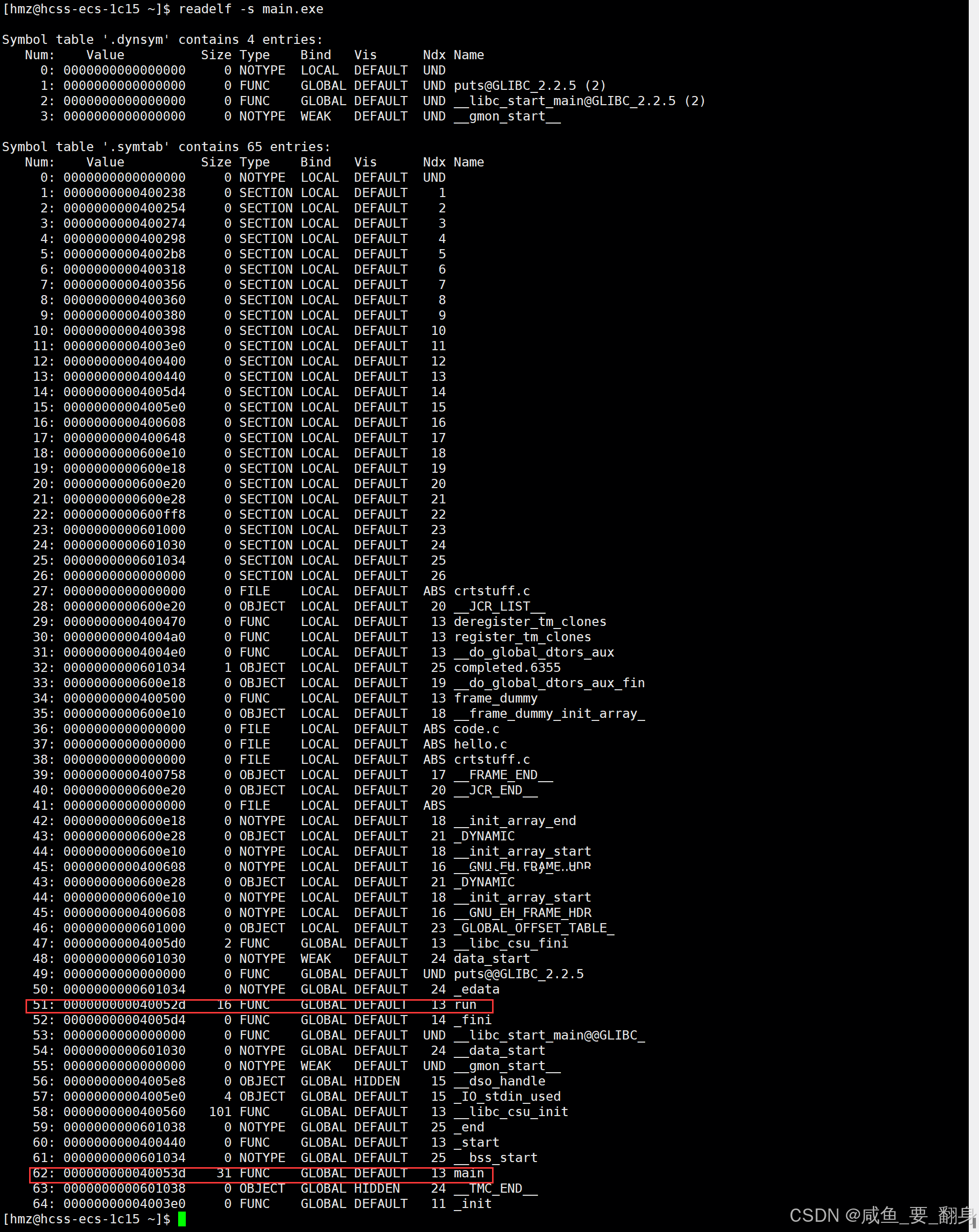
所有符号都有了确定的内存地址,将两个.o文件合并后,在最终的可执行程序中,可以定位到run函数的内存地址000000000040052d,main函数地址为000000000040053d。这里的"FUNC"标记表明run是一个函数符号。数字13表示run函数所在的section在合并后被分配到的最终section索引。
可执行文件段信息
readelf -S main.exe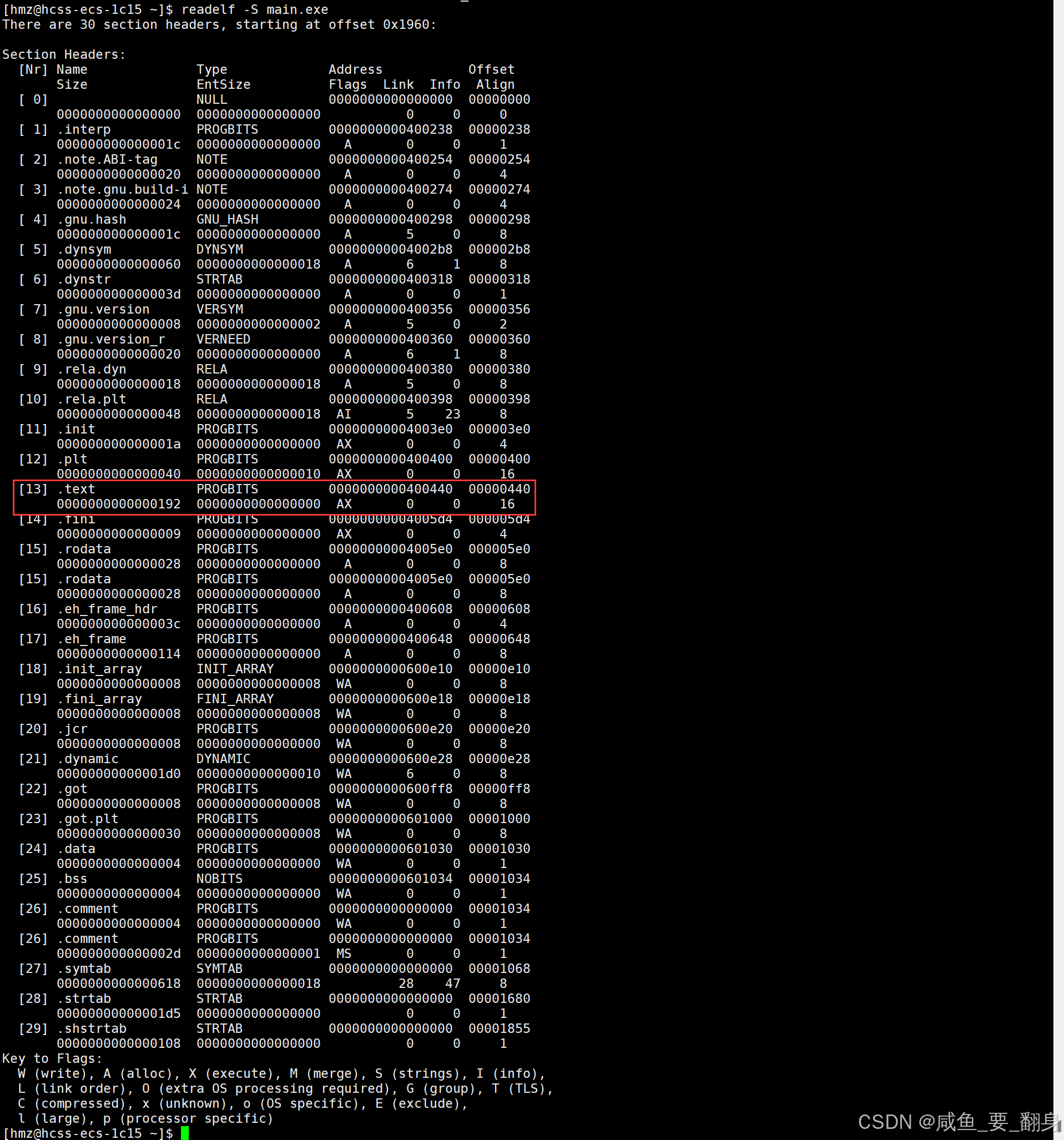
关键发现:两个.o文件的.text段被合并到了可执行文件的第16个section中
4. 链接地址修正验证
查看可执行文件反汇编代码:# 反汇编main.exe只查看代码段信息,包含源代码
objdump -d main.exe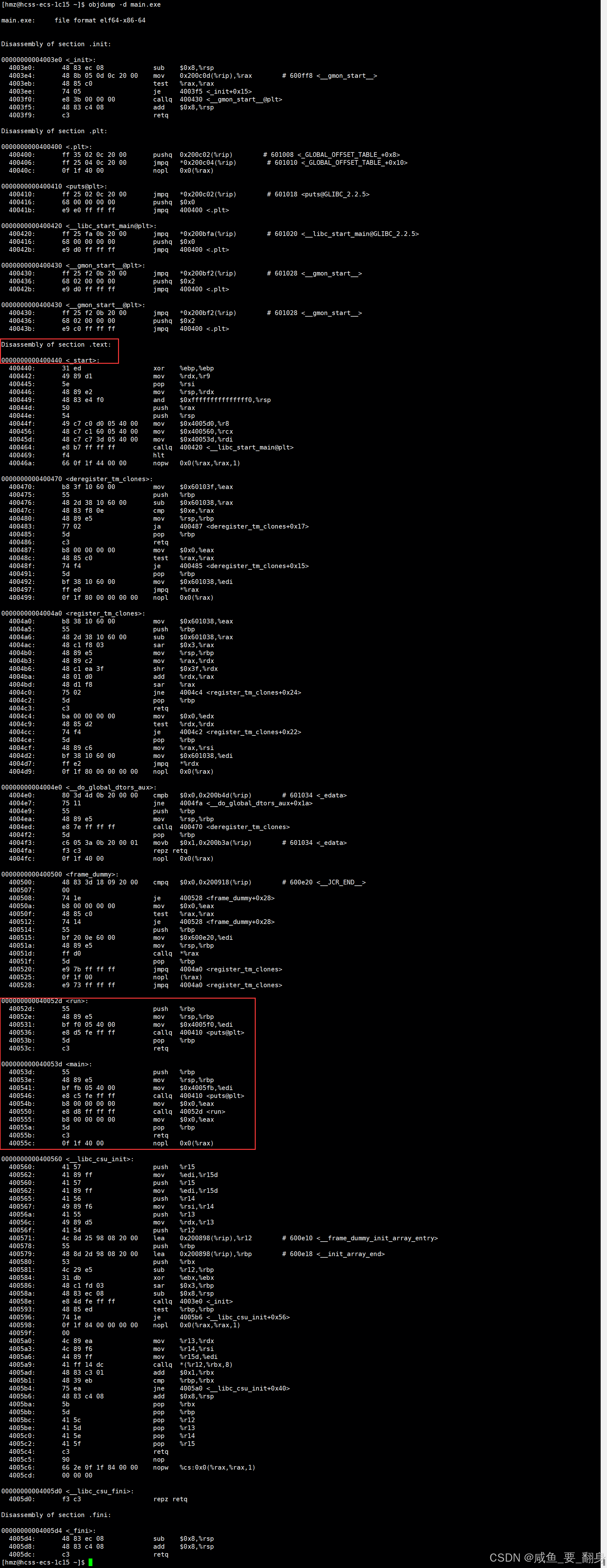
关键修正:
-
main函数中调用run的地址被修正为40052d
-
run函数中调用puts的地址被修正为400410
-
所有函数调用都有了正确的跳转地址
5. 静态链接过程总结
-
段合并:链接器将多个.o文件的相同段(.text, .data等)合并到一起
-
符号解析:确定所有符号的最终内存地址
-
地址修正:根据重定位表修正所有需要重定位的地址
-
最终布局:生成具有统一地址空间的可执行文件
静态链接的核心是将多个独立编译的目标文件合并为一个完整的可执行文件,并解决所有跨文件引用的问题。通过符号解析和重定位,链接器确保了程序各部分能够正确协同工作。
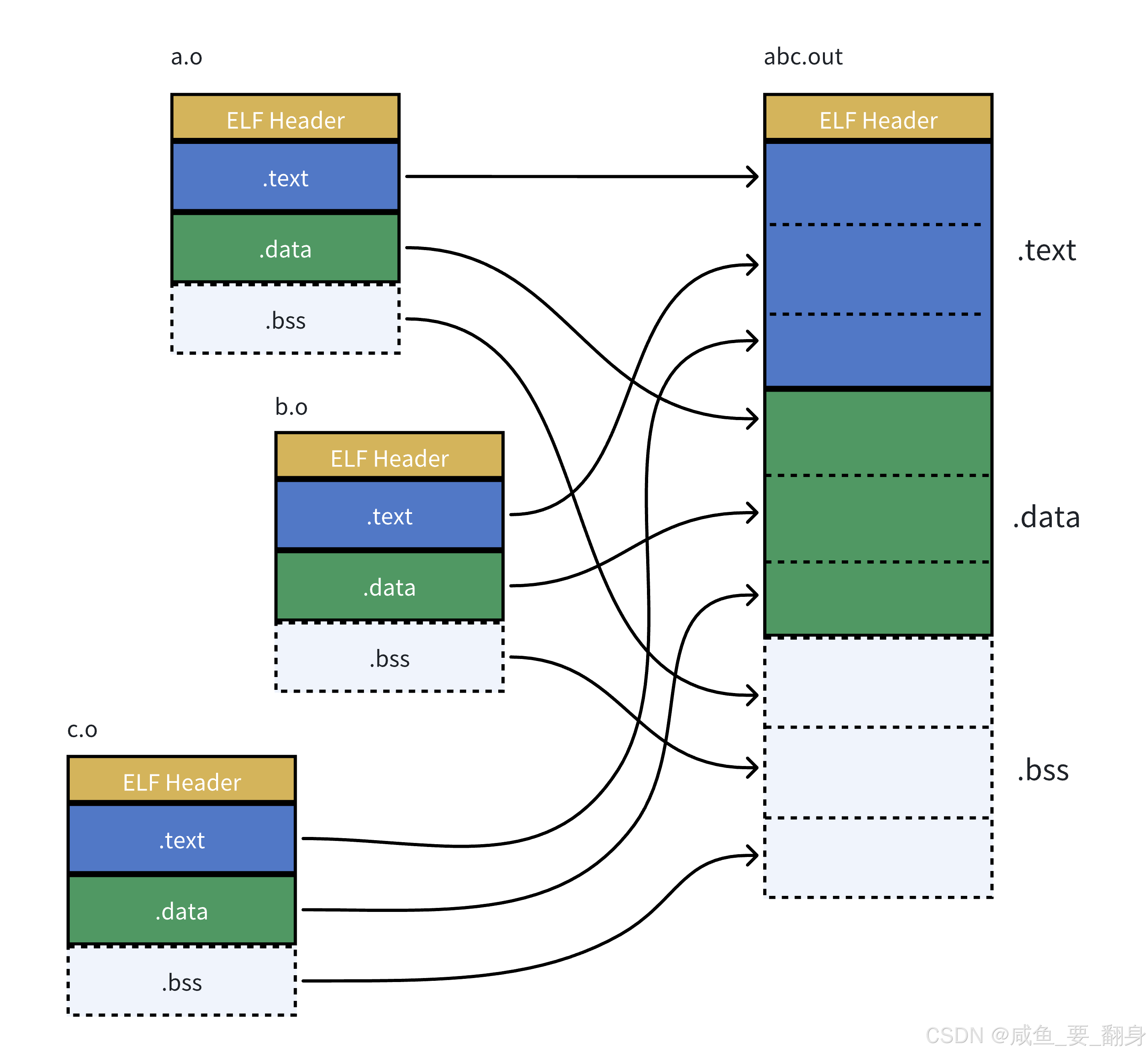
在链接过程中,程序会对目标文件(.o)中的外部符号进行地址重定位。
二、ELF加载与进程地址空间
1、虚拟地址/逻辑地址
核心问题探讨
问题一:一个ELF程序在未被加载到内存时是否具有地址?
深入解析:
-
现代计算机采用"平坦模式"工作,要求ELF文件在编译时就对自身的代码和数据进行了统一编址
平坦模式 vs. 分段模式(历史对比)
特性 平坦模式(现代) 分段模式(传统 x86 实模式) 地址计算 直接使用线性地址(如 0x12345678)段寄存器 << 4 + 偏移(如DS:SI=DS×16 + SI)内存管理 分页(Paging)为主 分段(Segmentation)为主 寄存器使用 通用寄存器直接寻址(如 MOV RAX, [RDI])必须指定段寄存器(如 MOV AX, [ES:DI])地址空间 连续、统一(如 64 位程序可访问 2⁶⁴ Bytes) 受限(16 位实模式仅 1MB,保护模式分段复杂) 典型应用 现代操作系统(Windows/Linux/macOS) 早期 DOS、16 位实模式程序 -
通过
objdump -S反汇编可以看到,最左侧显示的地址就是ELF的逻辑地址(严格来说是起始地址+偏移量)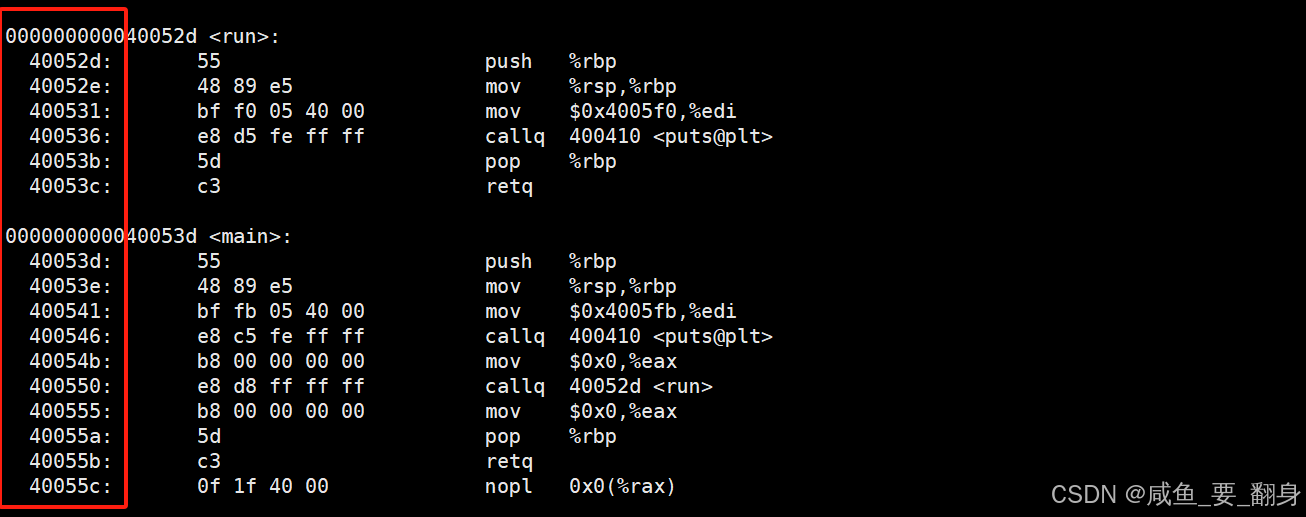
-
这些地址以0为基准,在程序加载前就已确定,我们称之为虚拟地址
问题二:进程的mm_struct、vm_area_struct在进程创建时的初始化数据来源?
关键发现:
-
初始化数据来源于ELF文件的各个segment
-
每个segment包含自己的起始地址和长度信息
-
内核使用这些信息初始化内存管理结构中的[start, end]范围数据
-
详细地址信息最终会填充到页表中
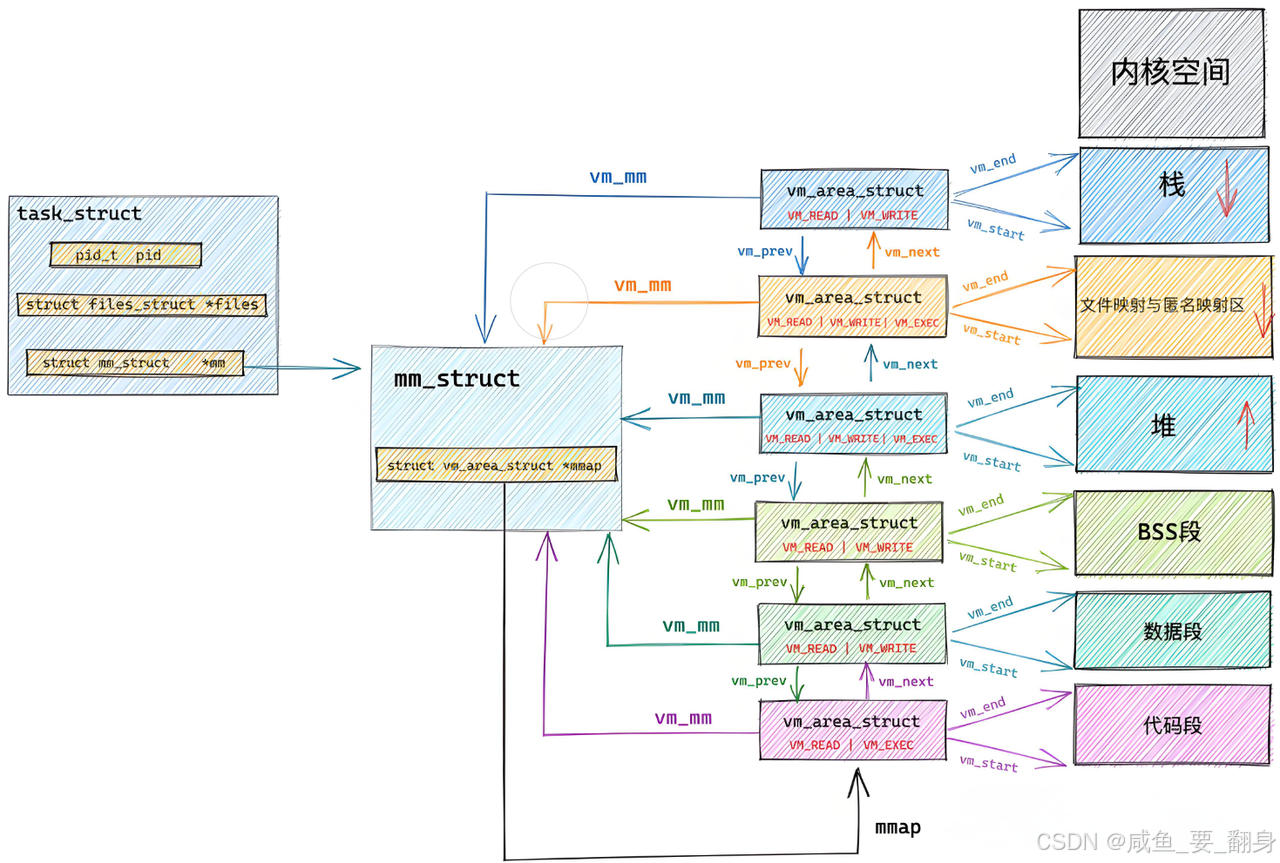
重要结论:
虚拟地址机制不仅需要操作系统支持,编译器也必须提供相应的支持,两者协同工作才能实现完整的内存管理功能。
2、进程虚拟地址空间再认识
ELF入口地址机制
ELF文件编译完成后,会将程序入口地址记录在ELF header的Entry字段中:
gcc *.o
readelf -h a.out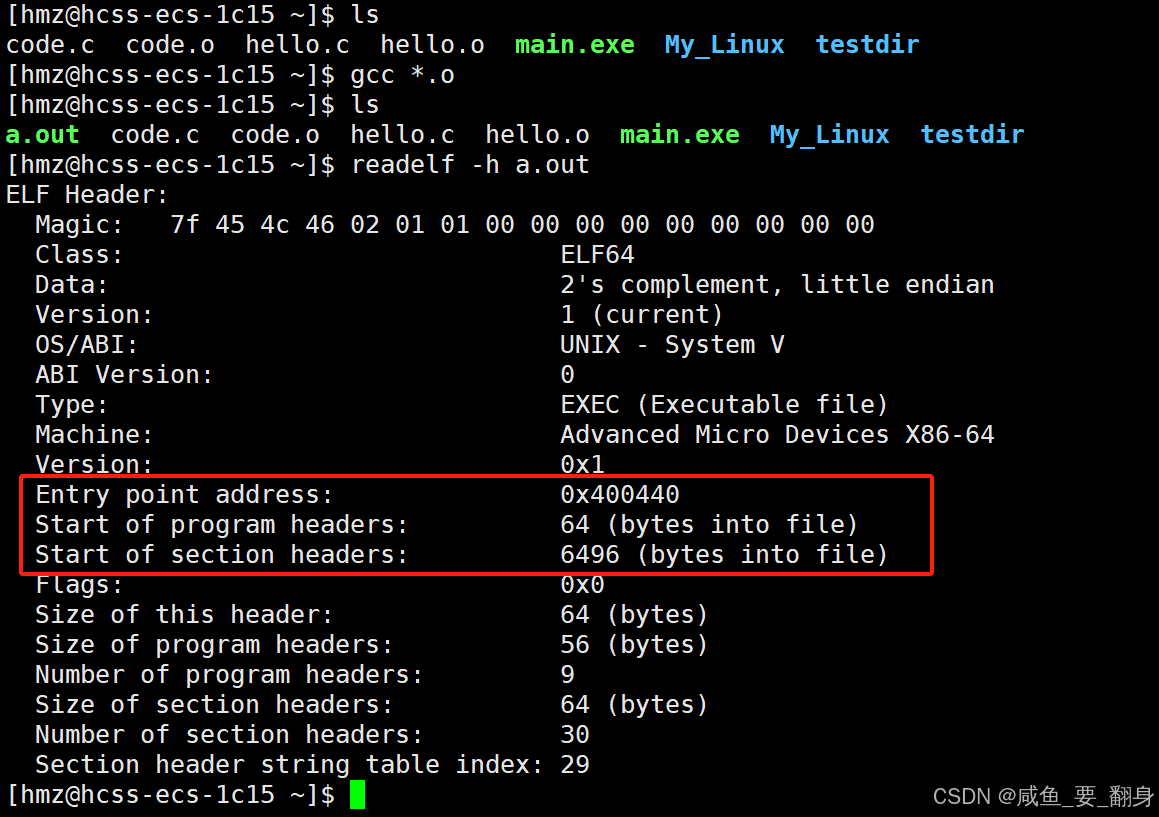
关键技术要点
-
入口地址意义:
-
Entry point address (0x1060) 表示程序执行的起始位置
-
这个地址在链接阶段由链接器确定
-
操作系统加载程序时会从这个地址开始执行
-
-
地址空间建立:
-
程序头部表(program headers)描述了如何将各个segment映射到进程地址空间
-
每个segment的加载地址在编译时就已经确定
-
操作系统根据这些信息建立进程的虚拟内存布局
-
-
动态链接特性:
-
Type字段显示为"DYN"表示这是一个动态链接的可执行文件
-
动态链接会影响最终的内存布局和地址解析方式
-
这种设计使得程序可以在编译时确定逻辑地址布局,同时保持加载时的灵活性,是现代操作系统内存管理的重要基础。
3、使用图来说明过程

该图清晰地展示了程序从磁盘加载到内存并最终被CPU执行的全过程,涉及操作系统、内存管理和CPU硬件的关键机制。以下是对图中各环节的深度技术分析:
1. 磁盘存储阶段(右侧)
- 可执行程序以二进制形式存储(ELF格式),Entry point address 0x1060指明程序入口虚拟地址
- 汇编代码(如_start)以高级语言形式展示,实际存储为机器码(如0x55对应push ebp)
- 浅紫色圆柱体象征非易失性存储,需注意此处代码尚未被操作系统处理
2. 加载过程(箭头)
- 动态链接器(ld-linux.so)根据程序头表(Program Headers)将.text/.data段映射到内存
- 实际发生的是内存映射(mmap)而非物理拷贝,图中"加载"应理解为虚拟地址空间的建立
- 可能触发缺页异常(Page Fault),此时才真正从磁盘读取数据到物理页
3. 物理内存管理(中部)
- 问题二中说明了对应进程的mm_struct、vm_area_struct在进程创建时的初始化数据来源
- 代码被加载到0x1060(虚拟地址),经页表转换对应物理地址(联想下面的红色字)
- 需注意.text段被标记为RX(读执行),.data段为RW(读写)权限
4. CPU执行机制(左侧)
- EIP(x86)/RIP(x64)寄存器形成指令指针流水线:
- 取指阶段:通过MMU查询页表(CR3→PML4→PDP→PD→PT)
- 执行阶段:ALU运算时会检查代码段(CS)权限
- CR3寄存器存储顶级页表物理地址,实现进程地址空间隔离(每个进程独立的CR3)
- CR3寄存器存储PML4表的物理基地址
- 一句话来说就是EIP拿到页表中的虚拟地址,然后CPU处理后放真实的物理地址在CR3中!!!最后放到页表中!!!
5. 地址转换关键路径
虚拟地址0x1060 → CR3定位PML4 → 各级页表查询 → 物理地址 → L1/L2缓存 → 执行单元
三、动态链接与动态库加载
1、进程如何访问动态库
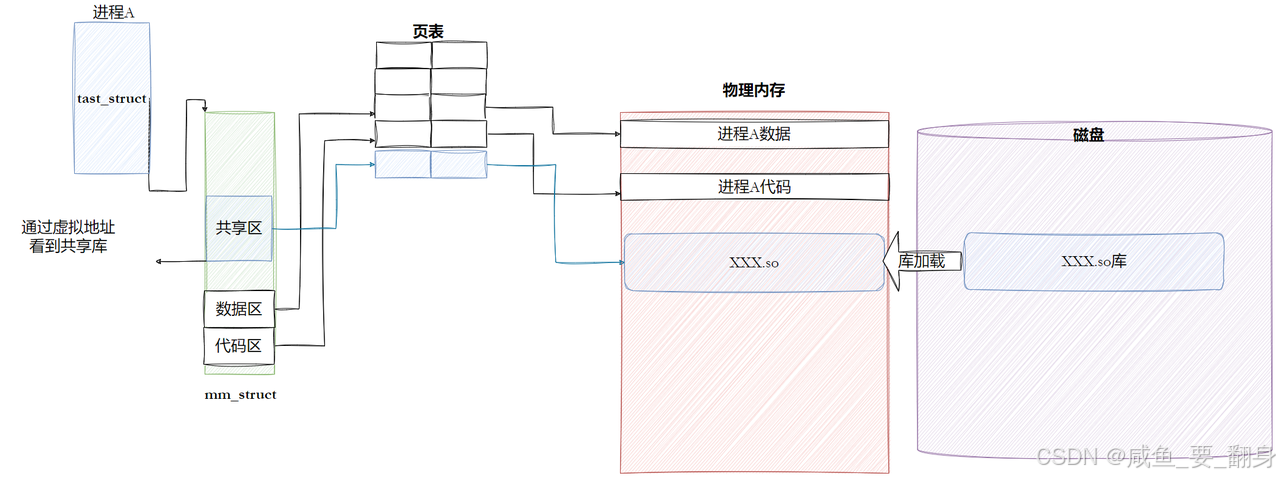
1. 进程与内存管理结构
- 进程描述符(task_struct)
每个进程在Linux内核中由一个task_struct结构体表示,包含进程的所有元信息(如PID、优先级等)。图中的"进程A"即通过task_struct标识。 - 内存描述符(mm_struct)
mm_struct是进程虚拟内存的核心管理结构,图中以浅绿色标注。它定义了进程的虚拟地址空间布局,包括:- 代码区:存放可执行指令(如动态库的代码段)。
- 数据区:存放全局变量、静态变量等(如动态库的数据段)。
- 共享区:专门映射共享库的区域,通过虚拟地址访问动态库。
2. 虚拟地址到物理内存的映射
- 页表机制
进程通过页表(Page Table)将虚拟地址转换为物理地址。图中"页表"是连接mm_struct与物理内存的关键:- 当进程访问共享库的虚拟地址时,CPU通过页表查询对应的物理页帧。
- 若物理内存中已加载库(如
XXX.so),页表直接指向该位置;若未加载,触发缺页异常。
- 共享区的特殊性
动态库的代码段(.text)在多个进程间可共享同一物理内存副本,而数据段(.data)可能因写时复制(Copy-On-Write)为每个进程创建私有副本。
3. 动态库的加载过程
- 从磁盘到物理内存
- 库加载请求:进程首次调用动态库函数时,通过
ld.so(动态链接器)发起加载请求。 - 磁盘读取:内核从"磁盘"(图中浅紫色区域)读取
XXX.so文件,解析其代码段和数据段。 - 物理内存映射:将库的代码段映射到物理内存(浅红色区域),数据段按需加载。
- 库加载请求:进程首次调用动态库函数时,通过
- 内存映射优化
动态库通常以mmap方式映射到进程地址空间,避免完全加载,仅在实际访问时触发缺页异常加载对应页。
4. 进程访问动态库的流程
- 虚拟地址访问
进程通过共享区的虚拟地址(如调用XXX.so中的函数)发起访问。 - 页表查询
CPU查询页表:
- 命中:直接访问物理内存中的XXX.so代码或数据。
- 未命中:触发缺页异常,内核将库的对应部分从磁盘加载到物理内存,更新页表。 - 执行或读写
- 代码段:CPU从物理内存读取指令执行。
- 数据段:读写操作可能触发写时复制(COW),确保进程间隔离。
5. 关键特性
- 共享性:多个进程的"共享区"可指向同一物理内存中的库代码段,节省内存。
- 延迟加载:动态库的物理内存加载是惰性的,减少启动开销。
- 写时复制:数据段的修改会为进程创建私有副本,保证安全性。
图示总结
图中从左到右的流程清晰展示了:
- 进程通过
mm_struct管理虚拟地址空间。 - 页表作为桥梁,将共享区的虚拟地址映射到物理内存中的
XXX.so。 - 物理内存作为缓存,磁盘作为持久化存储,共同支撑动态库的运行时访问。
这种机制高效平衡了性能(减少拷贝)与隔离性(COW),是现代操作系统的重要设计。
2、进程间如何共享动态库
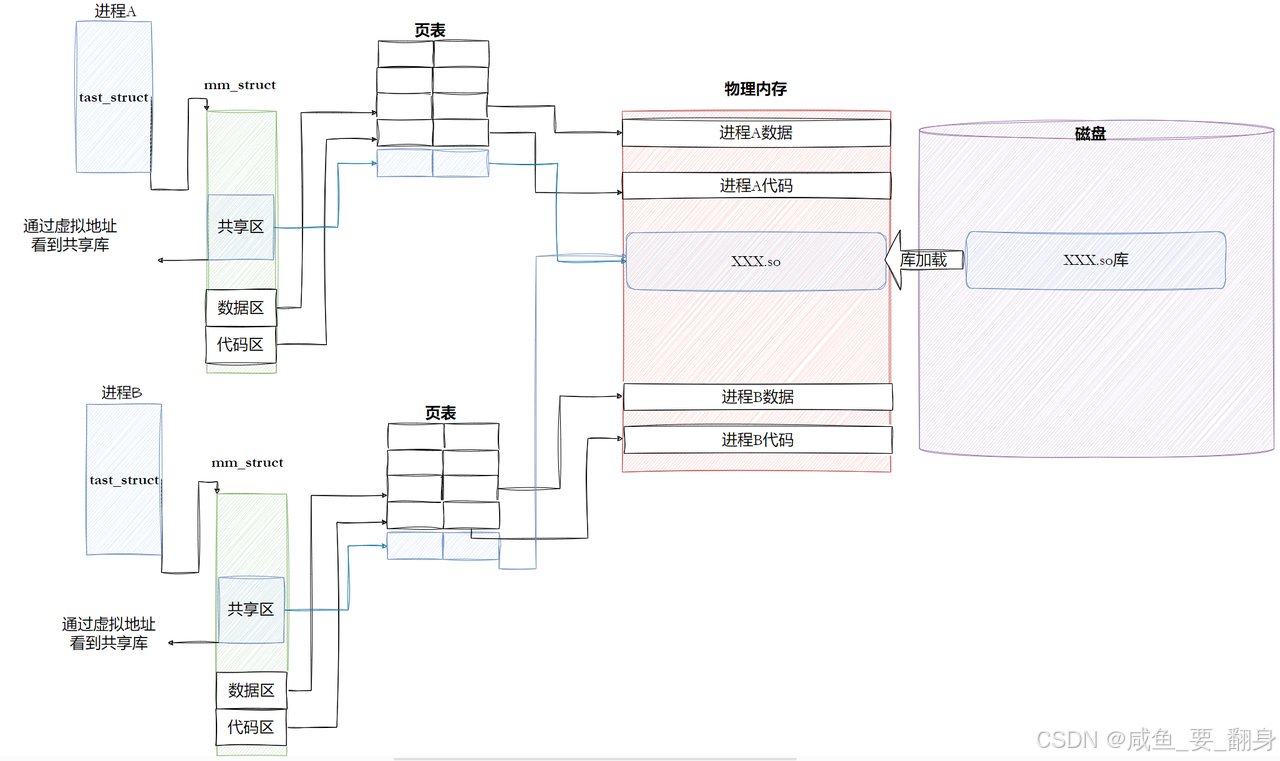
基本原理
动态库(共享库)在内存中只需要加载一次,就可以被多个进程共享使用,这是通过以下机制实现的:
- 虚拟内存映射:每个进程都有自己的虚拟地址空间,但可以映射到相同的物理内存区域
- 写时复制(Copy-On-Write):共享库的只读部分(代码段)可以被多个进程共享,而可写部分(数据段)在修改时会为每个进程创建副本
详细过程解析
1. 进程结构
每个进程都有:
task_struct:内核中表示进程的数据结构mm_struct:管理进程内存空间的数据结构- 代码区(text segment):存放进程专有代码
- 数据区(data segment):存放进程专有数据
- 共享区:用于映射共享库
2. 动态库加载过程
-
首次加载:
- 当第一个进程(如进程A)需要使用动态库(XXX.so)时
- 操作系统将磁盘上的XXX.so文件读入物理内存
- 在进程A的虚拟地址空间中建立映射关系(通过页表)
-
后续进程共享:
- 当另一个进程(如进程B)也需要使用同一个动态库时
- 操作系统不会再次从磁盘加载库文件
- 而是让进程B的虚拟地址空间映射到已经存在于物理内存中的库代码
- 通过页表建立新的虚拟-物理地址映射关系
3. 内存管理细节
- 页表作用:每个进程有自己的页表,将虚拟地址转换为物理地址
- 共享机制:
- 库的代码段(只读)在物理内存中只有一份副本
- 所有进程的页表中对应部分都指向相同的物理页
- 数据段处理:
- 库的全局数据区通常使用写时复制技术
- 初始时所有进程共享相同的物理页
- 当有进程尝试修改数据时,内核会为该进程创建私有副本
4. 优势
- 节省内存:多个进程共享同一份库代码,减少物理内存占用
- 提高性能:避免重复加载相同的库文件
- 简化更新:更新库文件时,只需替换磁盘上的文件,新启动的进程会自动使用新版本
实际应用示例
当运行多个使用同一动态库(如libc.so)的程序时:
- 第一个程序启动时,libc.so被加载到物理内存
- 后续启动的程序直接共享已加载的libc.so代码
- 每个程序有自己的数据段副本(如果需要修改全局数据)
这种机制是现代操作系统高效管理内存资源的重要手段之一。
3、动态链接机制详解
1. 动态链接概述
在现代操作系统中,动态链接已成为比静态链接更为常用的链接方式。通过分析一个简单程序a.out的动态库依赖关系,我们可以看到它主要依赖于C语言运行时库:
ldd a.out
技术说明:
ldd命令用于显示程序或库文件所依赖的共享库列表。
libc.so是C语言的运行时库,提供了标准输入输出、文件操作、字符串处理等基础功能。
为什么默认使用动态链接而非静态链接?
静态链接会将所有目标文件和使用的库合并为一个独立的可执行文件,虽然具有无需额外依赖的优势,但存在两个主要问题:
-
文件体积膨胀:生成的二进制文件体积显著增大
-
内存资源浪费:相同功能的代码会在不同进程的内存空间中重复加载
随着软件复杂度提升,静态链接会导致操作系统臃肿化,不同软件包含相同功能代码会造成大量存储空间浪费。
动态链接通过以下方式解决这些问题:
-
将共享代码提取为独立的动态链接库
-
在程序运行时才加载所需库到内存
-
同一库在内存中仅保留一份副本,供多个进程共享
2、动态链接工作原理
动态链接的核心机制是将链接过程推迟到程序加载时进行。具体流程如下:
-
程序启动时,操作系统首先加载程序代码和数据
-
同时加载程序依赖的所有动态库到内存
-
操作系统根据当前地址空间使用情况,为每个动态库动态分配内存地址
-
动态库加载地址确定后,系统会修正库中所有函数的跳转地址
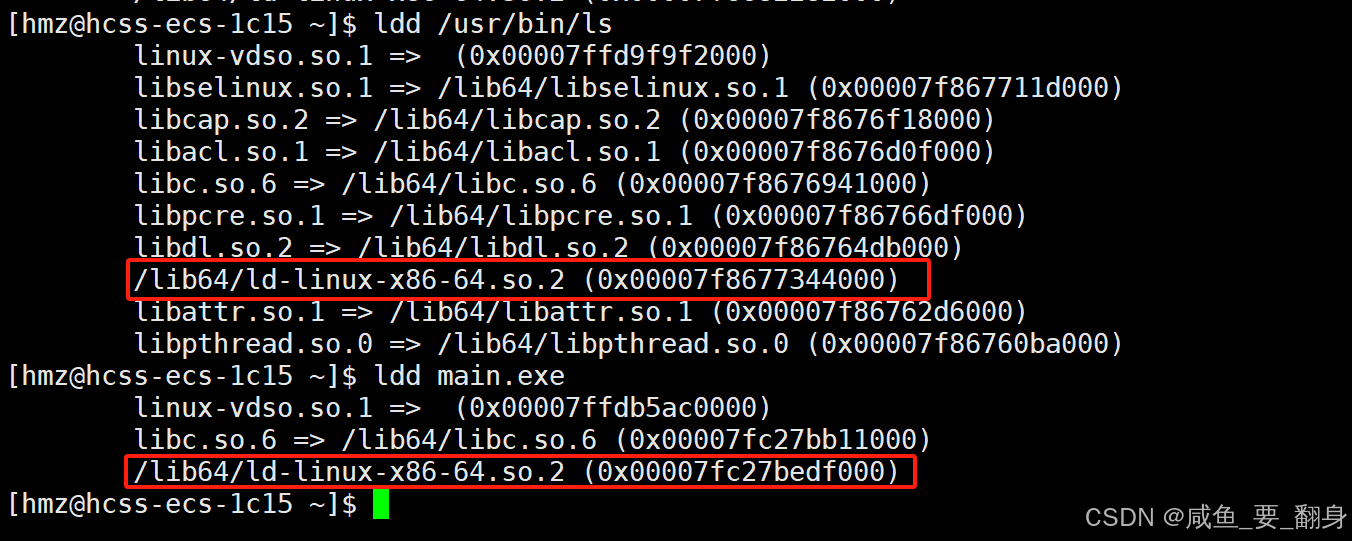
3、可执行文件中的动态链接痕迹
通过分析常见工具ls和示例程序main.exe的依赖关系:
4、程序启动流程与动态链接
在C/C++程序中,执行流程并非直接从main函数开始,而是遵循以下顺序:
-
入口点_start:
-
由C运行时库(glibc)或链接器(ld)提供
-
执行关键初始化操作:
-
设置程序堆栈环境
-
初始化数据段(全局/静态变量)
-
动态链接处理:调用动态链接器解析和加载依赖库
-
-
-
动态链接器(ld-linux.so):
-
解析程序动态库依赖关系
-
加载所需库到内存
-
处理符号解析和地址重定位
-
-
库搜索机制:
-
通过
LD_LIBRARY_PATH环境变量指定搜索路径 -
读取
/etc/ld.so.conf配置文件 -
使用
/etc/ld.so.cache缓存提高加载效率
-
-
移交控制权:
-
调用
__libc_start_main完成额外初始化-
设置信号处理器
-
初始化线程库(如使用多线程)
-
-
最终调用用户
main函数 -
处理
main返回值并调用_exit终止程序
-
开发者须知:虽然这些底层细节对大多数开发者透明(即不可见),了解此流程有助于深入理解程序执行机制和调试复杂问题。
5. 动态库中的地址编址方案
动态库为了实现灵活加载并映射到任意进程地址空间,对其内部方法采用相对地址编址方案。这种设计使得动态库可以被加载到进程地址空间的任意位置,同时保持内部引用关系的正确性。
技术说明:实际上可执行文件也采用类似的平坦内存模式(Flat Memory Model),只是可执行文件通常被直接加载到固定地址。
动态库反汇编示例
在Linux系统中,可以使用objdump工具查看动态库的反汇编代码:
# Ubuntu系统示例
objdump -S /lib/x86_64-linux-gnu/libc-2.31.so | less# CentOS系统示例
objdump -S /lib64/libc-2.17.so | less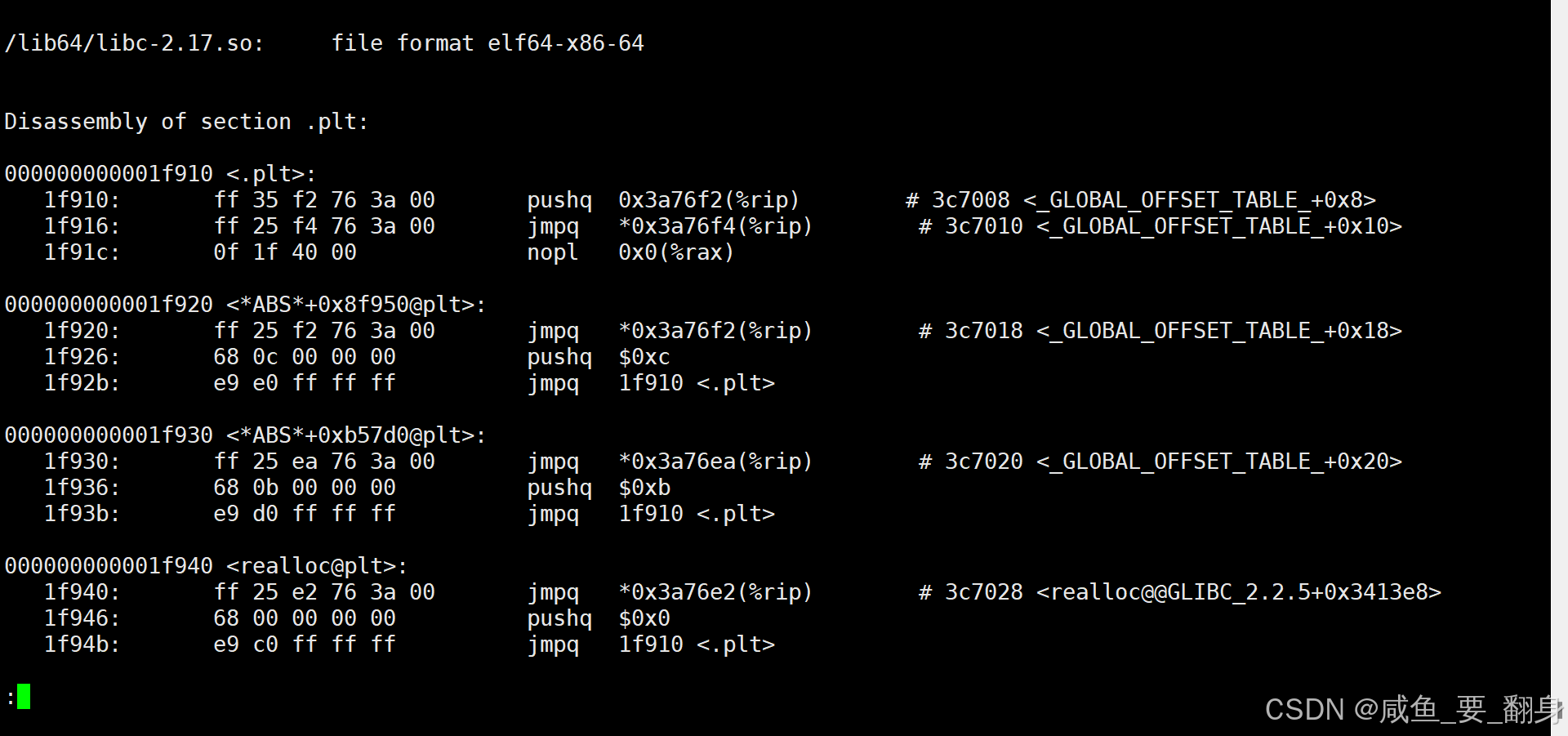
6. 程序与动态库的映射机制
关键实现原理
-
动态库的文件本质:
-
动态库本质上是特殊格式的二进制文件
-
使用前必须像普通文件一样被加载到内存
-
-
映射关系建立:
-
进程通过文件操作定位并加载动态库
-
动态链接器将库内容映射到进程的虚拟地址空间
-
函数调用通过虚拟地址跳转实现
-
-
地址转换过程:

技术实现要点
-
文件映射:使用
mmap系统调用将库文件映射到进程地址空间 -
地址重定位:动态链接器在加载时处理所有重定位项
-
延迟绑定:通过PLT(Procedure Linkage Table)和GOT(Global Offset Table)实现高效符号解析
性能提示:现代系统采用地址空间布局随机化(ASLR)增强安全性,这要求动态库必须支持位置无关代码(PIC)才能正常工作。
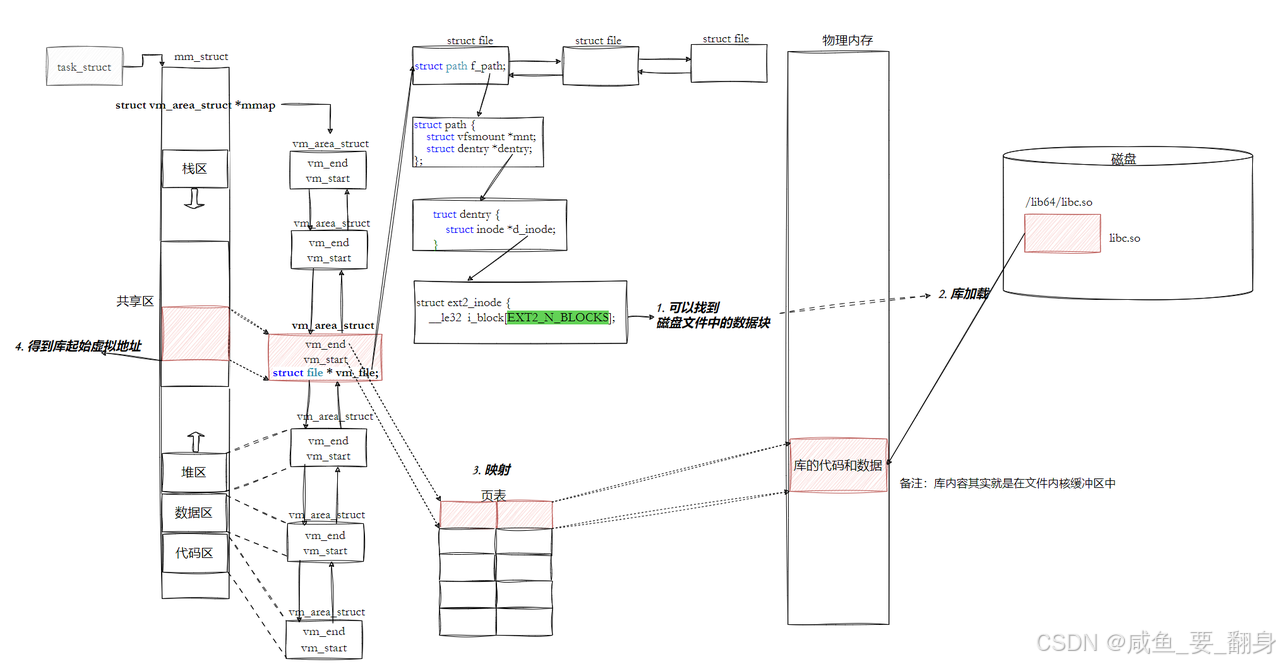
这张图详细展示了Linux系统中动态链接库(如libc.so)从磁盘加载到进程虚拟地址空间的完整流程,涉及内存管理、文件系统和页表映射等核心机制。
1. 进程虚拟地址空间布局(左侧起点)
-
task_struct:代表进程的PCB(进程控制块),内含内存管理结构体mm_struct。 -
mm_struct:管理进程的虚拟内存,核心成员mmap是一个链表,链表中每个节点是一个vm_area_struct(VMA),描述一段连续的虚拟内存区域(如代码区、数据区、堆、栈、共享库映射区等)。 - VMA划分:图中标注了典型的进程地址空间区域:
- 代码区(
.text):存放程序指令。 - 数据区(
.data/.bss):存放全局/静态变量。 - 堆区(向上增长):动态内存分配(
malloc)。 - 共享区:映射共享库(如
libc.so)。 - 栈区(向下增长):局部变量和函数调用栈。
- 代码区(
2. 文件系统定位库文件(右侧起点)
- 磁盘文件路径:如
/lib64/libc.so,通过文件系统(如ext2)的inode定位数据块。-
struct file:内核中表示打开的文件,包含struct path。 -
struct dentry:目录项,关联到inode(如ext2_inode),通过i_block数组找到文件数据在磁盘上的物理块。
-
3. 库加载与映射流程(核心箭头方向)
-
步骤1:从磁盘读取库数据
- 通过
dentry→inode→i_block链,定位磁盘上libc.so的数据块。 - 数据首先被读入内核的页缓存(图中备注“文件内缓冲区”)。
- 通过
-
步骤2:物理内存加载
内核将库文件的代码和数据从页缓存加载到物理内存(图中“库的代码和数据”区域)。 -
步骤3:页表映射
- 内核为进程创建页表项,将物理内存中的库数据映射到进程虚拟地址空间的共享区(VMA的
vm_start~vm_end)。 - 映射通过
vm_area_struct完成:其vm_file指向struct file,关联到库文件。
- 内核为进程创建页表项,将物理内存中的库数据映射到进程虚拟地址空间的共享区(VMA的
-
步骤4:返回虚拟地址
进程通过vm_area_struct获取库映射的起始地址(vm_start),后续可通过该地址访问库函数。
4. 关键机制与数据结构
- 共享内存优化:多个进程映射同一库文件时,物理内存中只需一份副本,通过不同进程的页表映射到各自的虚拟地址空间(节省内存)。
- 延迟加载:实际代码/数据可能在首次访问时通过缺页异常触发加载(图中未明确体现)。
- 颜色高亮:红色标注的
vm_area_struct和共享区,强调动态库映射的核心路径。
总结
该图清晰地串联了从文件系统到内存管理的完整链路:
进程访问库函数 → 通过VMA找到共享区映射 → 页表指向物理内存 → 若未加载则从磁盘读取 → 最终执行库代码。
这一流程是Linux动态链接和共享库运行的基础。
7. 库函数调用机制详解
调用前提条件
-
库映射完成:目标库已被映射到当前进程的地址空间中
-
地址信息已知:
-
已知库的虚拟起始地址
-
已知库中每个方法的偏移量地址
-
调用原理
访问库中的任意方法只需进行简单地址计算:方法实际地址 = 库的起始虚拟地址 + 方法偏移量
调用过程特征
-
地址空间内跳转:整个调用过程完全在进程地址空间内完成
-
两阶段执行流:
-
从代码区跳转到共享区(执行库函数)
-
执行完毕后返回到代码区继续执行
-
这种机制实现了高效的动态库调用,同时保持了进程地址空间的隔离性和安全性。
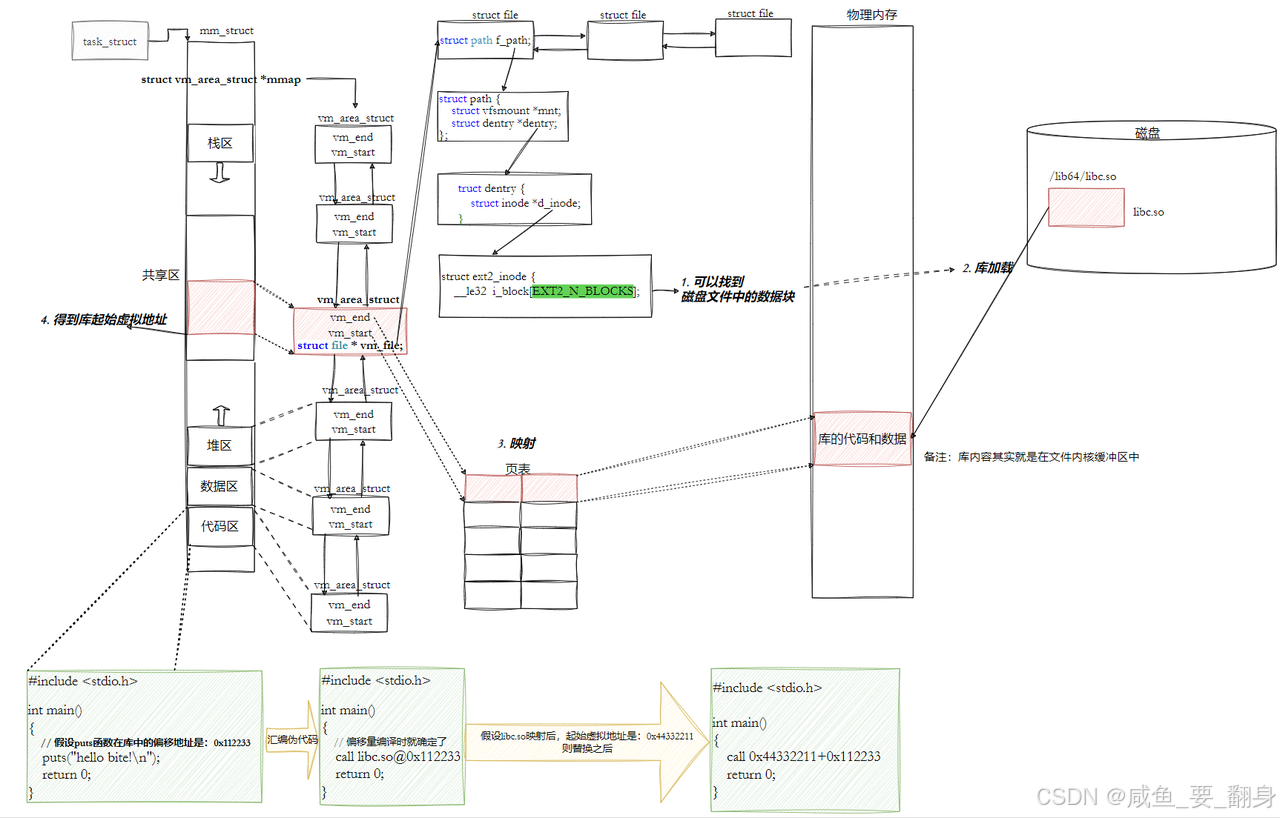
8. 全局偏移量表(GOT)机制详解
GOT基本概念
全局偏移量表(Global Offset Table, GOT)是动态链接过程中的核心数据结构,用于解决共享库函数地址的动态解析问题。
动态链接的必要条件
-
预先加载:程序运行前,所有依赖的库必须完成加载和地址空间映射
-
地址预知:所有库的起始虚拟地址需要在程序运行前确定
地址重定位机制
-
加载时重定位:在内存中对程序的库函数调用地址进行二次设置
-
技术挑战:
-
代码区(.text)通常是只读的,无法直接修改
-
直接修改代码段会违反内存保护机制
-
GOT的创新设计
-
专用数据区域:
-
在.data段(或库自身)中专门预留可读写区域
-
用于存储函数和全局变量的跳转地址
-
-
关键特性:
-
位于可读写内存区域(.data)
-
支持运行时动态修改
-
每个表项对应一个需要引用的全局符号地址
-
ELF文件中的GOT
通过工具可以查看GOT相关信息:
readelf -S a.out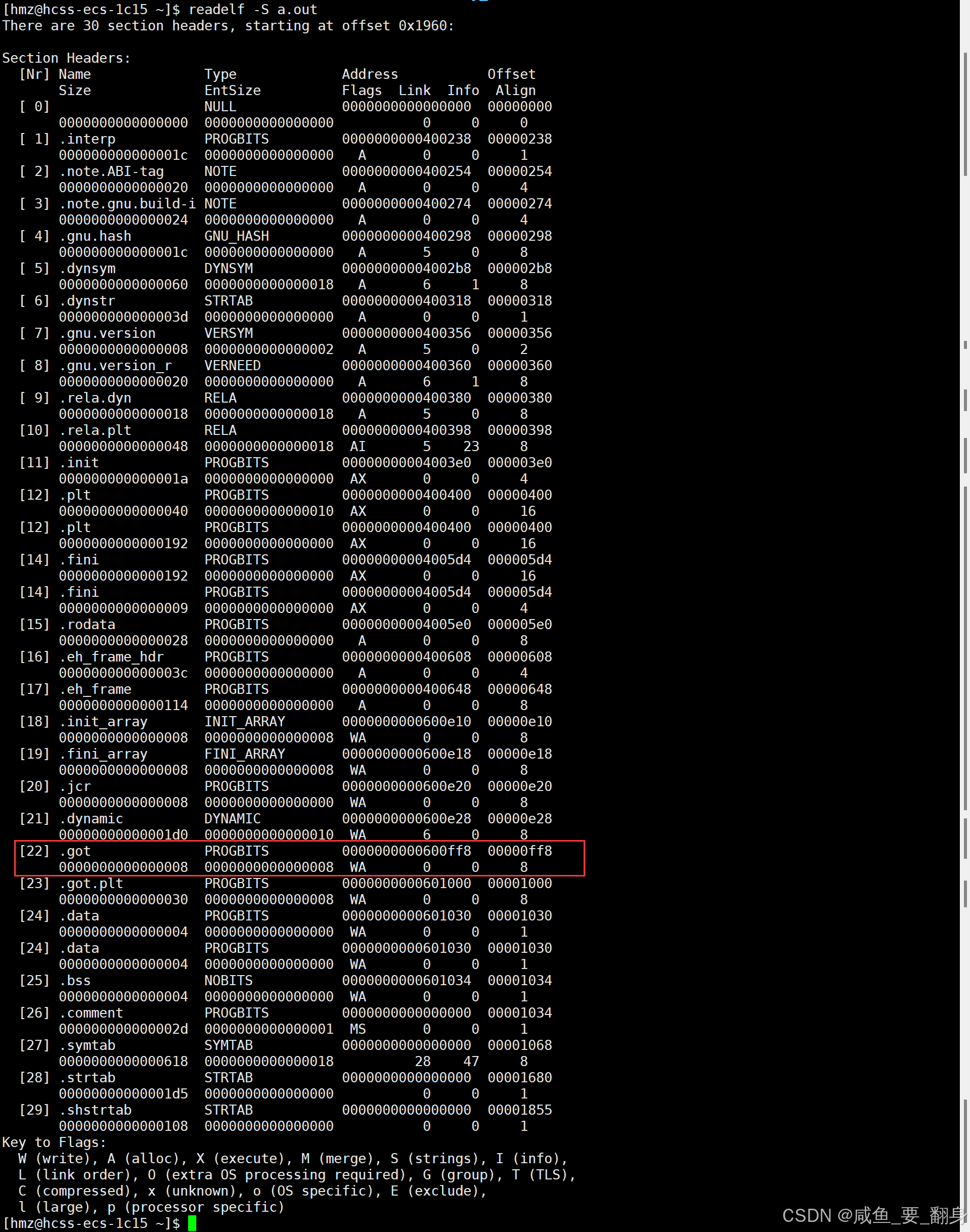
readelf -l a.out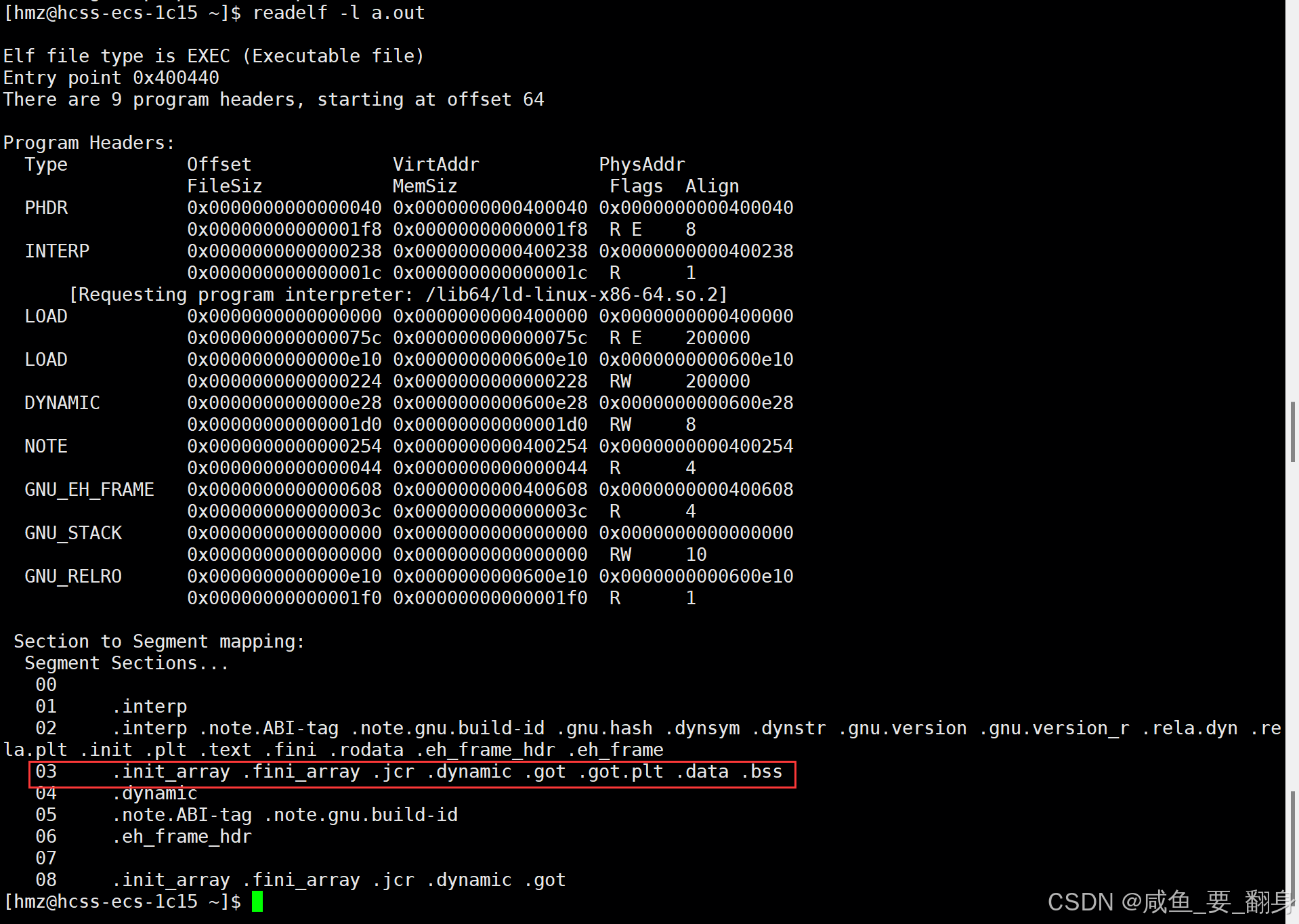
加载特性
-
GOT在加载时会与.data段合并为一个可读写内存段
-
这种设计既保持了代码段的只读属性,又实现了地址的动态解析
9. 全局偏移量表(GOT)与位置无关代码(PIC)机制详解
GOT表的进程隔离特性
-
代码段共享性:由于代码段(.text)是只读的,可以被所有进程共享
-
GOT表私有性:
-
不同进程中动态库的加载地址各不相同
-
每个进程需要维护独立的GOT表副本
-
进程间不能共享GOT表,确保地址空间的隔离
-
GOT表的定位机制
相对寻址优势:
-
在单个共享对象(.so)内部,GOT表与代码段的相对位置固定
-
可通过CPU的相对寻址指令(如RIP相对寻址)高效定位GOT表
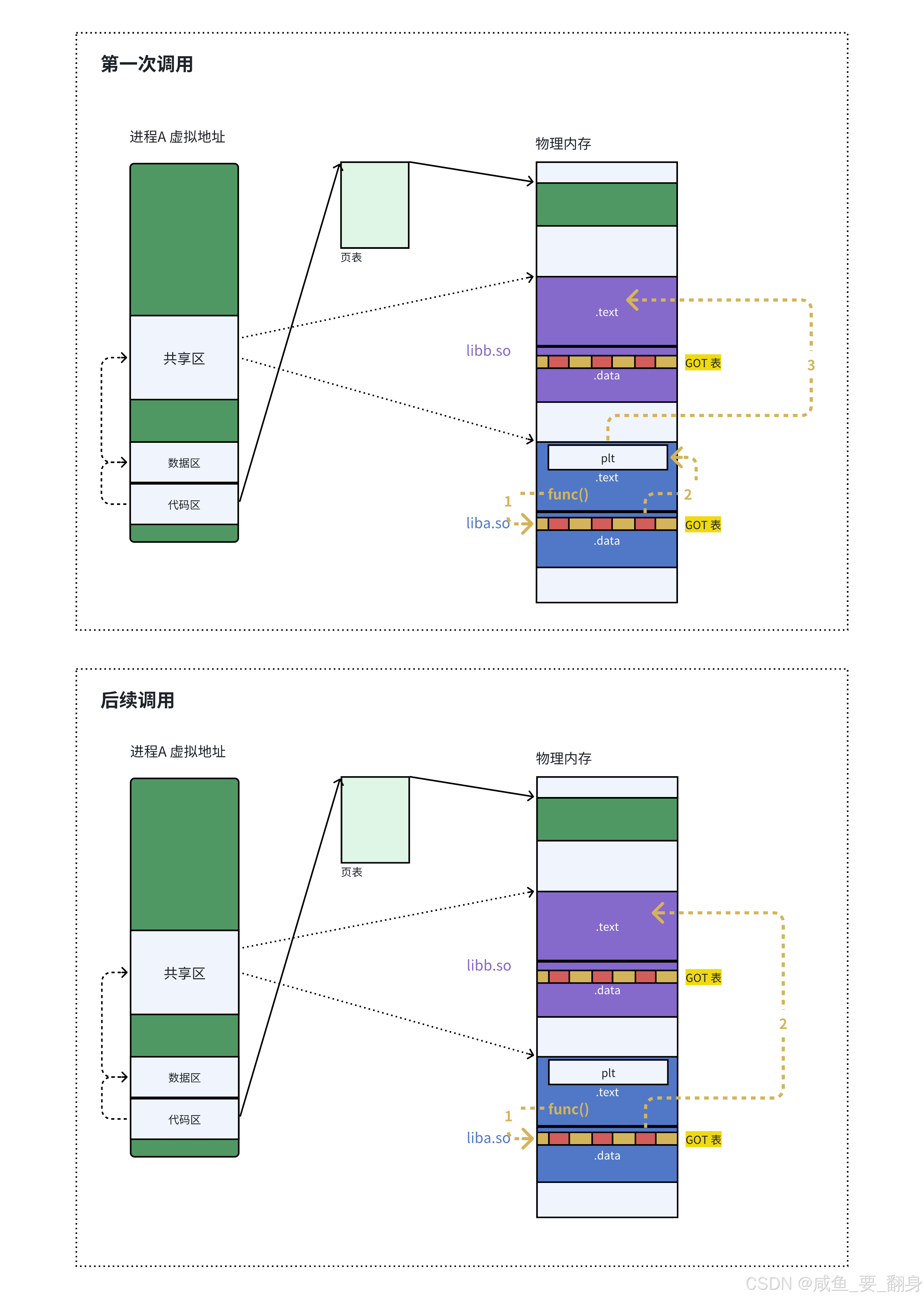
动态链接调用流程
-
间接跳转机制:
call puts@plt // 1. 调用PLT桩代码 // 在PLT中: jmp *GOT[puts_offset] // 2. 跳转到GOT表中存储的地址 -
地址延迟绑定:
-
首次调用时,GOT表项指向动态链接器解析例程
-
解析完成后,动态链接器将真实函数地址回填到GOT表
-
后续调用直接跳转到目标函数
-
位置无关代码(PIC)原理
-
核心思想:
-
代码不包含绝对地址引用
-
所有外部引用通过GOT表间接访问
-
使用相对偏移量进行内部访问
-
-
技术优势:
-
动态库可加载到任意内存地址
-
代码段可被多个进程共享
-
编译时需指定
-fPIC选项(PIC = 相对编址 + GOT)
-
实例分析
通过objdump查看PLT/GOT交互:
objdump -S a.out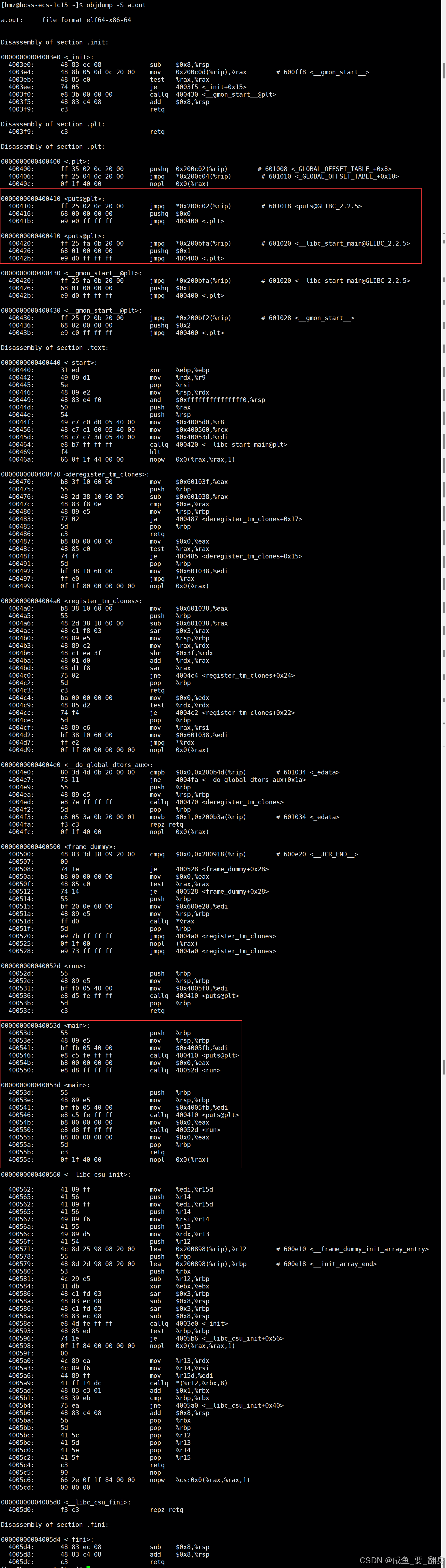
PLT(过程链接表)说明
PLT(Procedure Linkage Table)是:
-
延迟绑定的关键组件
-
包含调用外部函数的桩代码(stub)
-
首次调用时触发动态链接器进行符号解析
-
后续调用直接通过GOT表跳转
-
与GOT表配合实现"惰性绑定"优化
10. 库间依赖关系
动态链接中的库依赖
动态链接不仅涉及可执行程序对库的调用,还包括库与库之间的相互调用。为了实现库之间的地址无关性(Position-Independent Code, PIC),动态链接采用了以下机制:
-
全局偏移表(GOT)
-
每个动态库和可执行文件都包含自己的GOT(Global Offset Table),用于存储外部函数和变量的实际地址。
-
GOT在运行时由动态链接器填充,确保库之间的调用能够正确跳转到目标地址。
-
可以通过GDB调试观察GOT表地址的变化。推荐下面的博客:通过GDB学透PLT与GOT_plt got-CSDN博客
-
-
延迟绑定(PLT机制)
-
为了优化性能,动态链接采用了延迟绑定(Lazy Binding)技术,通过过程链接表(Procedure Linkage Table, PLT)实现。
-
GOT中的跳转地址默认会指向⼀段辅助代码,它也被叫做桩代码/stup。
-
在函数第一次被调用时,动态链接器才会解析其实际地址并更新GOT表,后续调用直接跳转到目标函数。
-
这种机制避免了程序启动时对所有函数进行重定位的开销,尤其适合动态库中较少被调用的函数。
-
动态链接的优势
动态链接将符号解析和地址重定位推迟到运行时,虽然牺牲了一定的加载性能,但带来了以下显著优势:
-
节省资源:多个程序可以共享同一动态库的代码段,减少磁盘和内存占用。
-
便于维护:库的更新无需重新编译可执行文件,只需替换动态库文件。
-
代码复用:实现了二进制级别的模块化,支持灵活的库依赖关系。
依赖关系的解析
动态链接器在加载程序时,会递归解析所有依赖的库,并完善各模块的GOT表,确保库之间的调用能够正确跳转。
四、总结:静态链接与动态链接对比
1、静态链接
-
模块化开发:允许开发者独立编译和测试模块,最终通过静态链接合并为单一可执行文件。
-
静态重定位:在编译时修正模块间的函数和变量地址,生成完全独立的可执行文件。
2、动态链接
-
运行时重定位:将链接过程推迟到程序加载时,动态库的加载地址不固定,但通过GOT实现地址无关调用。
-
性能权衡:虽然增加了加载时间,但显著提升了资源利用率和维护便利性。
3、核心区别
-
静态链接在编译时完成所有地址绑定,生成自包含的可执行文件。
-
动态链接在运行时通过GOT和PLT机制实现灵活、高效的库调用,支持代码共享和动态更新。