【AI论文】EXAONE 4.0:融合非推理模式与推理模式的统一大语言模型
摘要:本技术报告介绍了EXAONE 4.0,该模型融合了非推理模式与推理模式,既保留了EXAONE 3.5的卓越易用性,又具备EXAONE Deep的先进推理能力。为迎接智能体(Agentic)人工智能时代的到来,EXAONE 4.0融入了智能体工具使用等关键特性,其多语言能力也得到拓展,除支持英语和韩语外,还新增了对西班牙语的支持。EXAONE 4.0模型系列包含两种规模:一种是针对高性能进行优化的中型320亿参数(32B)模型,另一种是专为设备端应用设计的小型12亿参数(1.2B)模型。与同类开源权重模型相比,EXAONE 4.0展现出卓越性能,即便与前沿模型相比也颇具竞争力。这些模型已公开发布,供研究使用,可通过访问Huggingface。Huggingface链接:Paper page,论文链接:2507.11407
研究背景和目的
研究背景:
随着人工智能技术的快速发展,大语言模型(Large Language Models, LLMs)已成为自然语言处理(NLP)领域的核心驱动力。早期的大语言模型主要聚焦于提升模型的指令跟随能力和综合世界知识,如EXAONE 3.5版本,通过强化综合指令跟随能力来支持多样化的实际应用。然而,随着应用场景的复杂化,对模型推理能力的要求也日益增高。为了应对这一挑战,一些研究开始专注于提升模型的推理性能,特别是在数学和编程领域,如EXAONE Deep模型的出现,标志着大语言模型在推理能力上的显著进步。
与此同时,智能体(Agentic)人工智能的兴起,预示着未来AI系统不仅需要具备强大的语言理解和生成能力,还需能够自主使用外部工具,进行复杂任务的规划和执行。这一趋势对大语言模型提出了更高的要求,即模型需在同一架构内无缝集成快速响应的非推理模式与深度思考的推理模式。在此背景下,EXAONE 4.0的研究应运而生,旨在通过统一非推理与推理模式,推动大语言模型向更加智能、灵活的方向发展。
研究目的:
EXAONE 4.0的研究目的主要有以下几点:
- 统一非推理与推理模式:通过在同一模型中集成非推理模式和推理模式,使模型既能快速响应简单指令,又能进行深度思考以解决复杂问题。
- 提升多语言支持:在原有英语和韩语支持的基础上,增加对西班牙语的支持,提升模型的国际适用性。
- 增强工具使用能力:为模型配备智能体工具使用能力,为智能体AI时代奠定基础。
- 优化模型性能:通过增加预训练数据量、扩展上下文长度以及改进模型架构,提升模型在各类任务上的表现,使其在同类开源模型中保持领先,并与前沿模型形成竞争力。
研究方法
1. 模型架构设计:
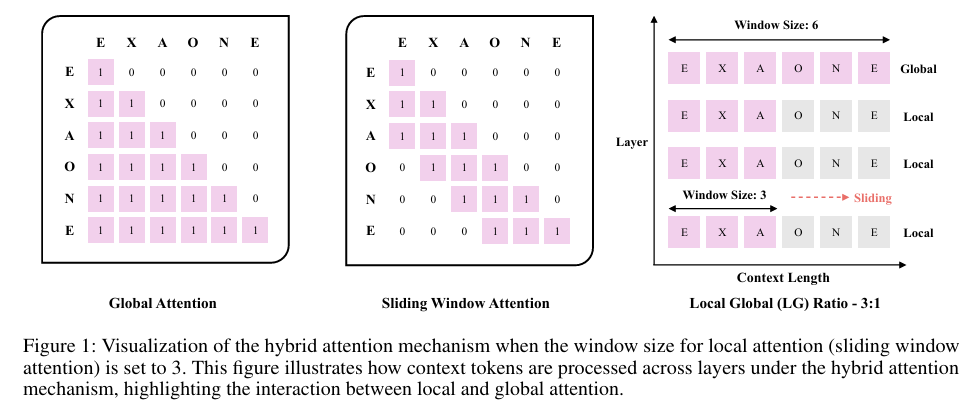
EXAONE 4.0在模型架构上进行了多项创新。首先,模型采用了混合注意力机制(Hybrid Attention Mechanism),结合了局部注意力(Local Attention)和全局注意力(Global Attention),以在保持长文本处理能力的同时降低计算成本。具体而言,模型在每四层中使用一层全局注意力,其余三层使用局部滑动窗口注意力,窗口大小设为4K,以在短文本和长文本任务中均保持优异性能。
其次,模型对层归一化(Layer Normalization)的位置进行了调整,采用QK-Reorder-LN方法,在输入查询和键之后以及注意力输出之后应用层归一化,以提升下游任务的性能。此外,模型继续使用RMSNorm作为归一化类型,以保持训练的稳定性。
2. 预训练数据与计算资源:
EXAONE 4.0显著增加了预训练数据量,320亿参数模型使用了14万亿个token进行预训练,几乎是EXAONE 3.5的两倍。这一举措旨在增强模型的世界知识,提升在各类知识密集型任务上的表现。同时,模型还扩展了最大上下文长度至128K token,通过两阶段扩展过程(先从4K扩展至32K,再扩展至128K),并使用Needle In A Haystack (NIAH)测试进行验证,确保模型在处理长文本时的性能不受影响。
3. 后训练阶段:
EXAONE 4.0的后训练阶段主要包括三个步骤:大规模监督微调(Large-scale Supervised Fine-tuning, SFT)、推理强化学习(Reasoning Reinforcement Learning, RL)以及偏好学习(Preference Learning)。在SFT阶段,模型使用包含非推理和推理数据的多样化数据集进行微调,数据集涵盖世界知识、数学/编程/逻辑、智能体工具使用、长文本处理以及多语言等领域。RL阶段则通过在线强化学习提升模型的推理能力,采用新提出的AGAPO算法,该算法在奖励函数设计、采样策略以及梯度更新方面进行了优化。最后,在偏好学习阶段,模型通过直接学习人类偏好,进一步细化模型在非推理和推理模式下的表现。
研究结果
1. 综合性能提升:
EXAONE 4.0在多个基准测试中展现了卓越的性能。在数学和编程领域,EXAONE 4.0的320亿参数模型在所有相关基准测试中均超越了Qwen3235B模型,无论是推理模式还是非推理模式下。同时,12亿参数模型在多数基准测试中也表现优异,仅在推理模式下略逊于EXAONE Deep 24亿参数模型。
2. 长文本处理能力:
通过扩展最大上下文长度至128K token,EXAONE 4.0在长文本处理任务中展现了强大的能力。在HELMET、RULER和LongBench等长文本基准测试中,模型在文档问答(Document QA)、检索增强生成(RAG)等任务上均取得了优异成绩,证明了模型在处理复杂长文本时的有效性和稳定性。
3. 多语言支持:
EXAONE 4.0在原有英语和韩语支持的基础上,成功增加了对西班牙语的支持。在多语言基准测试中,模型在西班牙语和韩语上的表现均优于或等同于同类基线模型,展示了模型在多语言处理方面的强大能力。
4. 工具使用能力:
EXAONE 4.0在工具使用任务上也表现不俗。在BFCL-V3和TAU-BENCH等基准测试中,模型的320亿参数版本在推理模式下展示了与R1-0528等强大基线模型相当的性能,证明了模型在智能体工具使用方面的潜力。
研究局限
尽管EXAONE 4.0在多个方面取得了显著进展,但仍存在一些局限性:
1. 数据偏差与伦理问题:
尽管研究团队在数据收集和处理过程中采取了多项措施以减少个人、有害及偏见信息的包含,但模型仍可能生成包含不当内容的响应。这主要源于训练数据中可能存在的潜在偏差和伦理问题,需通过持续的数据清洗和模型优化来解决。
2. 推理预算与性能平衡:
在控制推理预算(即推理过程中使用的token数量)时,研究发现随着推理预算的减少,模型性能会有所下降。尽管EXAONE 4.0在较低推理预算下仍能保持竞争力,但如何在有限资源下进一步优化模型性能,仍是未来研究的重要方向。
3. 实时知识与最新信息:
由于模型的知识主要来源于预训练数据,其生成的响应可能无法反映最新的信息或实时变化。这在一定程度上限制了模型在需要最新信息场景下的应用,需通过结合外部知识库或实时检索技术来改进。
未来研究方向
针对EXAONE 4.0的研究局限,未来研究可从以下几个方面展开:
1. 数据治理与伦理优化:
进一步改进数据收集和处理流程,采用更严格的数据过滤和清洗策略,以减少训练数据中的偏差和不当信息。同时,加强模型生成内容的伦理审查,确保模型输出的合规性和社会责任感。
2. 高效推理算法研究:
探索更加高效的推理算法,以在有限推理预算下保持模型性能。这包括优化注意力机制、改进梯度更新策略以及开发新的模型压缩和量化技术,以降低推理过程中的计算成本。
3. 实时知识与外部知识融合:
研究如何将外部知识库或实时检索技术与大语言模型相结合,以增强模型在需要最新信息场景下的应用能力。这可通过开发新的知识融合算法或构建混合智能系统来实现,使模型能够动态获取并整合外部知识。
4. 多模态与跨模态研究:
随着多模态大语言模型的发展,未来研究可探索如何将视觉、音频等多模态信息融入EXAONE系列模型中,以提升模型在跨模态任务上的表现。这包括开发新的多模态预训练任务、优化跨模态注意力机制以及构建大规模多模态数据集等。
5. 模型可解释性与安全性研究:
加强模型可解释性研究,探索模型决策背后的逻辑和依据,以提升模型的可信度和可靠性。同时,研究模型安全性问题,防止模型被恶意利用或生成有害内容,确保模型在安全可控的环境下运行。
总之,EXAONE 4.0的研究不仅推动了