嵌入式学习-PyTorch(8)-day24
torch.optim 优化器
torch.optim 是 PyTorch 中用于优化神经网络参数的模块,里面实现了一系列常用的优化算法,比如 SGD、Adam、RMSprop 等,主要负责根据梯度更新模型的参数。
🏗️ 核心组成
1. 常用优化器
| 优化器 | 作用 | 典型参数 |
|---|---|---|
torch.optim.SGD | 标准随机梯度下降,支持 momentum | lr, momentum, weight_decay |
torch.optim.Adam | 自适应学习率,效果稳定 | lr, betas, weight_decay |
torch.optim.RMSprop | 平滑梯度,常用于RNN | lr, alpha, momentum |
torch.optim.AdamW | 改进版Adam,解耦正则化 | lr, weight_decay |
torch.optim.Adagrad | 稀疏特征场景,自动调整每个参数的学习率 | lr, lr_decay, weight_decay |
演示代码
import torch
import torch.nn as nn
import torch.optim as optimmodel = nn.Linear(10, 1) # 一个简单的线性层
optimizer = optim.Adam(model.parameters(), lr=0.001)for epoch in range(100):output = model(torch.randn(4, 10)) # 模拟一个输入loss = (output - torch.randn(4, 1)).pow(2).mean() # 假设是 MSE 损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 更新参数
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2ddataset = torchvision.datasets.CIFAR10(root='./data_CIF', train=False, download=True, transform=torchvision.transforms.ToTensor())
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1)class Tudui(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)self.maxpool1 = nn.MaxPool2d(kernel_size=2)self.conv2 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)self.maxpool2 = nn.MaxPool2d(kernel_size=2)self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)self.maxpool3 = nn.MaxPool2d(kernel_size=2)self.flatten = nn.Flatten()self.linear1 = nn.Linear(in_features=1024, out_features=64)self.linear2 = nn.Linear(in_features=64, out_features=10)self.model1 = nn.Sequential(Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=1024, out_features=64),nn.Linear(in_features=64, out_features=10))def forward(self, x):x = self.model1(x)return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01 )
for epoch in range(100):running_loss = 0.0for data in dataloader:imgs,targets = dataoutputs = tudui(imgs)result_loss = loss(outputs, targets)#梯度置零optim.zero_grad()#反向传播result_loss.backward()#更新参数optim.step()running_loss += result_lossprint(running_loss) 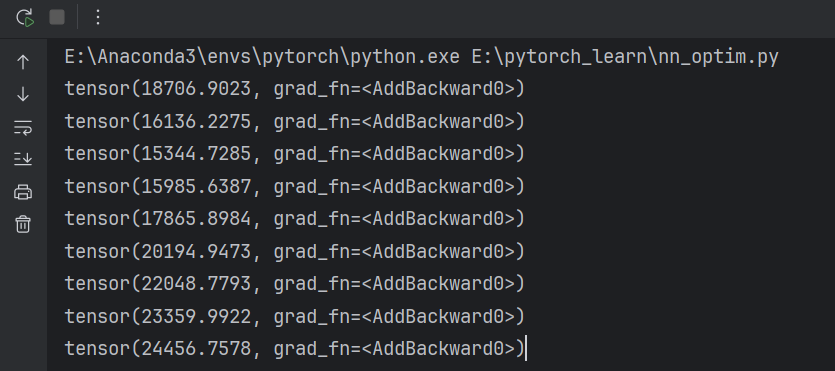
对网络模型的修改
import torchvision
from torch import nn# train_data = torchvision.datasets.ImageNet(root='./data_IMG',split="train", transform=torchvision.transforms.ToTensor())
#学习如何改变现有的网络结构
vgg16_false = torchvision.models.vgg16(pretrained=False)vgg16_true = torchvision.models.vgg16(pretrained=True)train_data = torchvision.datasets.CIFAR10(root='./data_CIF',train=True,transform=torchvision.transforms.ToTensor(),download=True)
#加一个线性层
vgg16_true.add_module('add_linear',nn.Linear(in_features=1000,out_features=10))
vgg16_true.classifier.add_module('add_linear',nn.Linear(in_features=1000,out_features=10))
#修改一个线性层
vgg16_false.classifier[6] = nn.Linear(in_features=4096,out_features=10)
print(vgg16_false)网络模型的保存与读取
#model_save.pyimport torch
import torchvision
from torch import nnvgg16 = torchvision.models.vgg16(pretrained=False)
#保存方式一:模型结构+模型参数
torch.save(vgg16,"vgg16.pth")#保存方式二:模型参数(官方推荐)
torch.save(vgg16.state_dict(),"vgg16_state_dict.pth")#陷阱
class Tudui(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(3,64,kernel_size=3)def forward(self, x):x = self.conv1(x)return xtudui = Tudui()
torch.save(tudui,"tudui_method1.pth")
#model_load.pyimport torch
import torchvisionfrom torch import nn#保存方式一,加载模型
# model = torch.load("vgg16.pth",weights_only=False)
# print(model)#方式二,加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
# model = torch.load("vgg16_state_dict.pth")
vgg16.load_state_dict(torch.load("vgg16_state_dict.pth"))
# print(vgg16)#陷阱
#陷阱
class Tudui(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(3,64,kernel_size=3)def forward(self, x):x = self.conv1(x)return x#如果直接这么调用的话,机器会找不到类在哪里
# 当你 torch.save(model) 保存整个模型时,它会把整个类的信息序列化。如果加载时当前文件找不到 Tudui 类,自然就炸了。
#可以将定义写到这个类来,也可以在开头写from model_save import *
#!!!更推荐一下模式:
"""
# 保存
torch.save(model.state_dict(), "tudui_method2.pth")# 加载
model = Tudui()
model.load_state_dict(torch.load("tudui_method2.pth"))优点:不管类在哪个文件,只要 Tudui() 存在就能加载;避免因为 class 变动导致报错;更加灵活,适合后期修改网络结构。
"""
model = torch.load("tudui_method1.pth",weights_only=False)
print(model)