海思3516cv610 NPU学习
 AIPP
AIPP
AIPP用于在 模式识别 Core上完成图像预处理,包括色域转换(转换图像格式)、图像归一化(减均值/乘系数)和抠图(指定抠图起始点,抠出 图像分析工具 需要大小的图片)等。
AIPP区分为静态AIPP和动态AIPP。只能选择静态AIPP或动态AIPP方式来处理图片,不能同时配置静态AIPP和动态AIPP两种方式。
● 静态AIPP:模型转换时设置AIPP模式为静态,同时设置AIPP参数,模型生成后,AIPP参数值被保存在离线模型(*.om)中,每次模型推理过程采用固定的AIPP预处理参数(无法修改)。
● 动态AIPP:模型转换时仅设置 AI PP模式为动态,每次模型推理前,根据需求,在执行模型前设置动态AIPP参数值,然后在模型执行时可使用不同的AIPP参数。可调用svp_acl_mdl_aipp数据类型下的操作接口设置动态AIPP参数值。
● 如果使用AIPP功能,多Batch情况下共用同一份AIPP参数
动态Batch/动态分辨率
在某些场景下,模型每次输入的Batch数或分辨率是不固定的,如检测出目标后再执行目标识别网络,由于目标个数不固定导致目标识别网络输入BatchSize不固定。
● 动态Batch:用户执行推理时,其Batch数是动态可变的。
● 动态分辨率:用户执行推理时,每张图片的分辨率H*W是动态可变的;如果和动态Batch一起使用,则一次多Batch推理的多张图片需要使用相同的分辨率。
动态维度(ND格式)
为了支持Transformer等网络在输入格式的维度不确定的场景,需要支持ND格式下任意维度的动态设置。ND表示支持任意格式,当前N≠4。
通道
在RGB色彩模式下,图像通道就是指单独的红色R、绿色G、蓝色B部分。也就是说,一幅完整的图像,是由红色绿色蓝色三个通道组成的,它们共同作用产生了完整的图像。
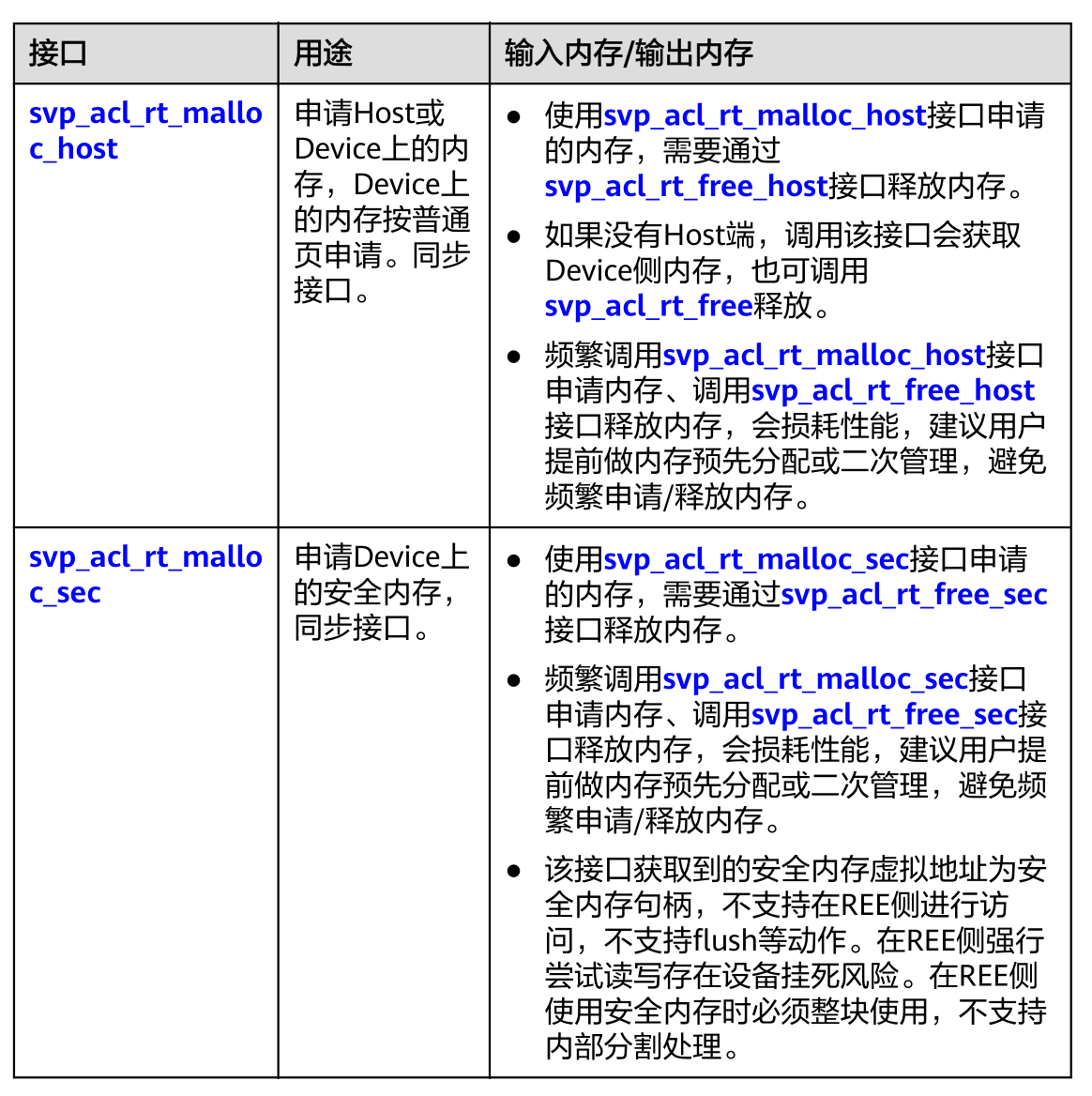
Device 、Context 、Stream 之间的关系
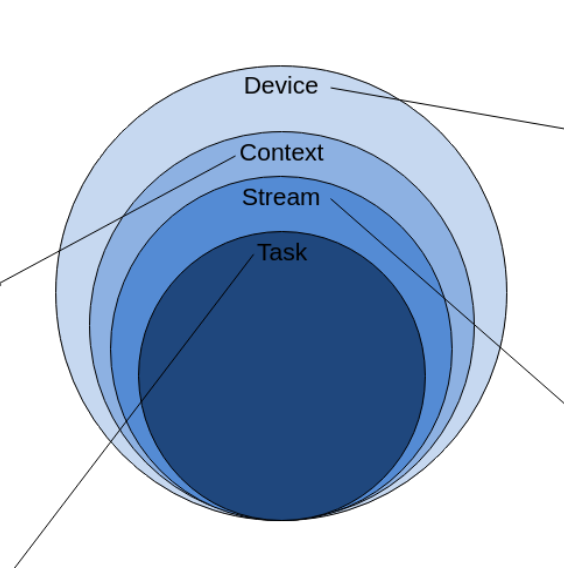
task:

stream:

context:

Device:


线程、Context 、Stream 之间的关系
一个用户线程一定会绑定一个Context,所有Device的资源使用或调度,都必须基于Context。
一个线程中当前会有一个唯一的Context在用,Context中已经关联了本线程要使用的Device。
可以通过svp_acl_rt_set_current_context进行Device的快速切换。示例代码如下,仅供参考,不可以直接拷贝编译运行:
…
svp_acl_rt_create_context(&ctx1, 0);
svp_acl_mdl_execute(mdl1, input1, output1);
svp_acl_rt_create_context(&ctx2,1);
/*在当前线程中,创建ctx2后,当前线程对应的Context切换为ctx2,对应在Device 1进行后续的计算任务,本例中将在Device 1上进行mdl2的执行调用 */
svp_acl_mdl_execute(mdl2, input2, output2);
svp_acl_rt_set_current_context(ctx1);
/*在当前线程中,通过Context切换,使后续模型计算任务在对应的Device 0上进行*/
svp_acl_mdl_execute(mdl3, input3, output3);
…
一个线程中可以创建多个Stream,不同的Stream上计算任务是可以并行执行;多线程场景下,也可以每个线程创建一个Stream,线程之间的Stream在Device上相互独立,每个Stream内部的任务是按照Stream下发的顺序执行。
多线程的调度依赖于运行应用的操作系统调度,Device侧多Stream调度,由Device上调度组件进行调度。
一个进程内多个线程间的 Context 迁移
● 一个进程中可以创建多个Context,但一个线程同一时刻只能使用一个Context。
● 线程中创建的多个Context,线程缺省使用最后一次创建的Context。
● 进程内创建的多个Context,可以通过svp_acl_rt_set_current_context设置当前需要使用的Context。
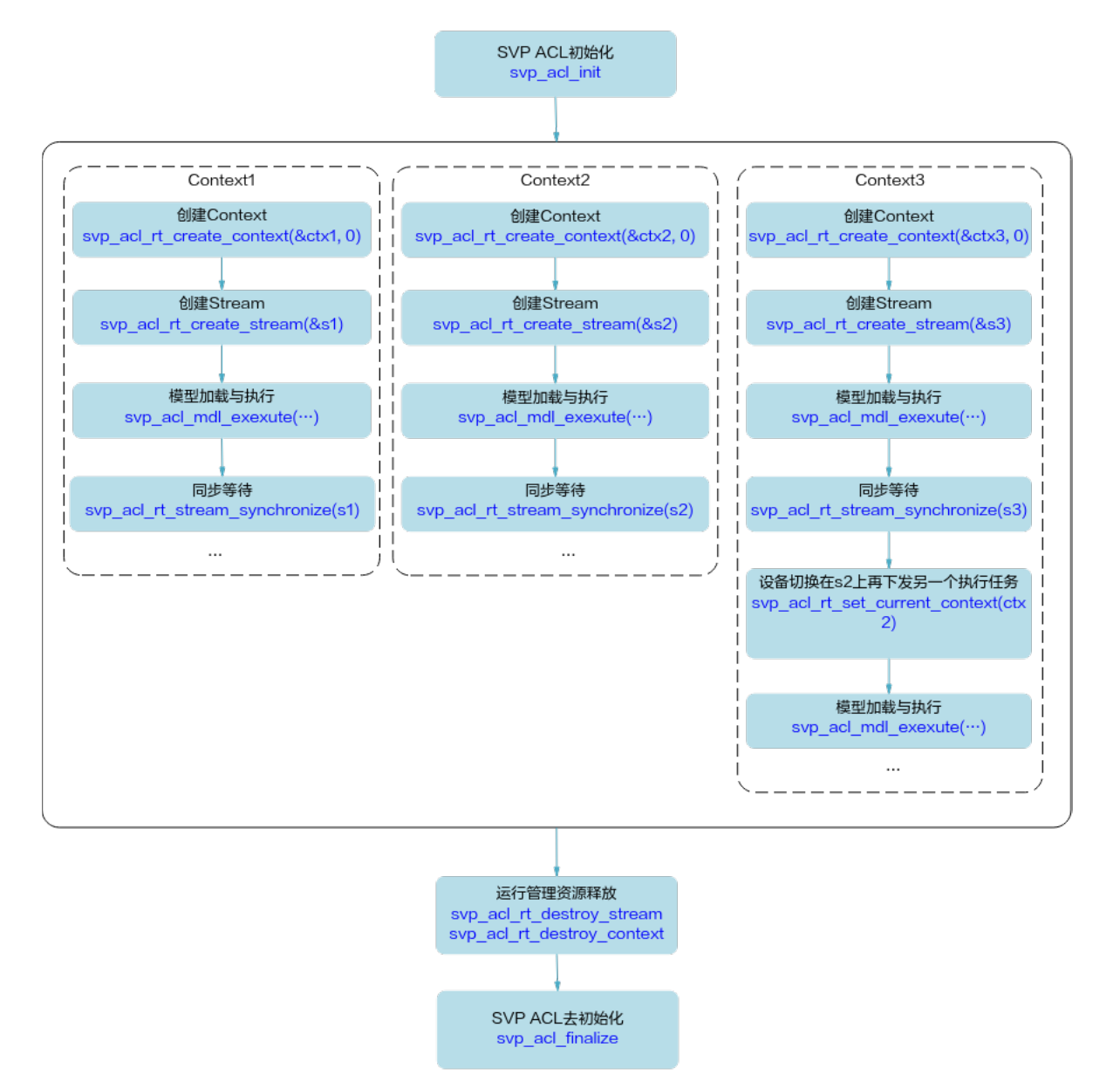
默认 Context 和默认 Stream 的使用场景
● Device上执行操作下发前,必须有Context和Stream,这个Context、Stream可以显式创建,也可以隐式创建。隐式创建的Context、Stream就是默认Context、默认Stream。默认Stream作为接口入参时,直接传NULL。
● 默认Context不允许用户执行svp_acl_rt_get_current_context或svp_acl_rt_set_current_context操作,也不允许执行svp_acl_rt_destroy_context操作。
● 默认Context、默认Stream一般适用于简单应用,用户仅仅需要一个Device的计算场景下。多线程应用程序建议全部使用显式创建的Context和Stream。
示例代码如下,仅供参考,不可以直接拷贝编译运行:
…
svp_acl_init(...);
svp_acl_rt_set_device(0);
/*已经创建了一个default ctx,并且在当前线程可用*/
…
/*在推理过程如果没有记录的default stream, 会在default ctx中创建了一个default stream, 并且在当
前线程可用*/
svp_acl_mdl_execute_async(mdl1,input1,output1,NULL); //最后一个NULL表示在default stream上
执行模型mdl1
svp_acl_mdl_execute_async(mdl2,input2,output2,NULL); //最后一个NULL表示在default stream上
执行模型mdl2
svp_acl_rt_synchronize_stream(NULL);
/*等待计算任务全部完成(mdl1、mdl2执行结束),用户根据需要获取计算任务的输出结果*/
…
svp_acl_rt_reset_device(0); //释放计算设备0,对应的default ctx及default stream生命周期也终止
多线程、多 stream 的性能说明
● 线程调度依赖运行的操作系统,Stream上下发了任务后,Stream的调度由Device的调度单元调度,但如果一个进程内的多Stream上的任务在Device存在资源争抢的时候,性能可能会比单Stream低。
● 当前芯片有不同的执行部件,如 模式识别 Core、 模式识别 CPU等,对应使用不同执行部件的任务,建议多Stream的创建按照算子执行引擎划分。
● 单线程多Stream与多线程多Stream(进程属于多线程,每个线程中一个Stream)性能上哪个更优,具体取决于应用本身的逻辑实现,一般来说前者性能略好,原因是相对后者,应用层少了线程调度开销。
SVP ACL 内存申请使用说明
用户内存管理有两种管理方式:
1. 独立内存管理,根据需要单独申请所需的内存,内存不做拆分或者二次分配。
2. 内存池管理内存,用户一次性申请一块较大内存,并在使用时从这块较大内存中二次分配所需内存。
在内存二次分配时,使用如下接口从内存池申请对应内存,由于接口对申请的内存地址、大小有约束,在内存池管理时,需要关注,否则容易出现内存越界。