Redis原理之集群
上篇文章:
Redis原理之哨兵机制(Sentinel)![]() https://blog.csdn.net/sniper_fandc/article/details/149141196?fromshare=blogdetail&sharetype=blogdetail&sharerId=149141196&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
https://blog.csdn.net/sniper_fandc/article/details/149141196?fromshare=blogdetail&sharetype=blogdetail&sharerId=149141196&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
目录
1 集群的概念
2 数据分片算法
2.1 哈希求余算法
2.2 一致性哈希算法
2.3 哈希槽分区算法
3 搭建Redis集群
3.1 创建目录和配置文件
3.2 配置docker-compose.yml
3.3 启动容器并构建集群关系
3.4 使用集群
3.5 主节点故障
3.6 集群扩容
1 集群的概念
主从复制+哨兵模式解决的是系统的可用性问题,但是每个节点存储的都是全量数据,由于单个物理机的容量有限,因此面对大数据环境存储就出现问题了。而集群就是解决系统的存储容量的问题。
广义上的集群是指多个物理机组成的分布式系统,因此主从复制、哨兵模式都算广义上的集群。
狭义上的集群就是Redis的集群模式,是指通过多对主从结构,每对主从结构存储部分数据,从而构成Redis集群。
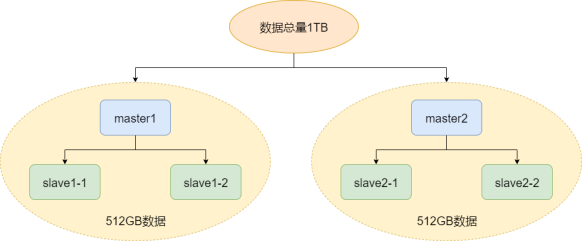
假设存在1TB的数据,就可以用2对master和slave节点,每对存储一半的数据(称之为分片sharding)。每对的slave作为master的备份,如果master故障则由slave代替。
如果有一个查询的key,如何确定这个键值对存储在哪个分片?这就需要数据分片算法:
2 数据分片算法
2.1 哈希求余算法
假设有N个分片,编号分别为0、1、...、N-1,则把key求得hash值(比如md5算法),再把hash值求N的余,余多少就把该key放到哪个分片:
hash(key) % N = 分片编号
优点:简单高效,数据分布均匀。
缺点:分片扩容(N变化),原来的key的映射规则发生变化,而哈希求余得到的结果具有离散性(连续的数不会分到同一个分片,而是分到各不相同的分片),因此需要进行大量数据搬运(不止master要搬运,slave也要搬运),开销大。
2.2 一致性哈希算法
1.按照md5算法,如果生成32位hash值,那么数据总量就是232,将这些数据按顺时针方向平均分布在一个圆上(如果数据量增加,就按顺时针方向增加)。
2.假设当前有三个分片,就在圆的三个合适的位置插入分片。
3.数据按hash值在圆上的分布位置顺时针寻找第一个遇到的分片位置,遇到哪个分片就把该数据存储到哪个分片(查询同理)。
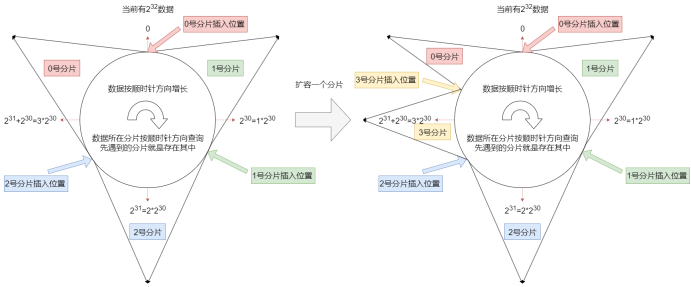
4.如果发生扩容,就在两个分片之间再插入一个分片,假设是3号分片插入2号和0号之间,那么只用把原来0号分片的一半数据搬运到3号分片中,其它分片的数据不用变化。
优点:大大减少了扩容时数据搬运次数(因为这种哈希求余的方式是连续的,连续的数据会被分配到同一个分片中),提高扩容效率。
缺点:数据分布不均匀(数据倾斜)。
2.3 哈希槽分区算法
为了解决哈希求余算法的大量数据搬运问题和一致性哈希算法的数据倾斜问题,Redis集群引入哈希槽分区算法结合了两种算法的优点。具体而言,将键值对放入哈希槽(hash slots)中,共有16384个槽(214=16k):
crc16(key) % 16384 = hash slots
这里crc16也是一种计算hash值的方法,即key映射到哈希槽使用了哈希求余算法。哈希槽的编号采用“位图”数据结构(16348个bit位)表示,因此需要2KB的空间存储一个哈希槽。
在对所有的哈希槽使用一致性哈希算法,假设有3个分片,则每个分片存储5461个槽(有一个存储5462个,近似均匀)。比0号存储[0,5460]区间内的5461个槽,1号存储[5461,10922]区间内的5462个槽,2号存储[10923,16383]区间内的5461个槽。
注意:每个分片存储的槽不一定连续。
如果要扩容,假设新增3号分片,则从每个槽平均取1365个槽(2号分片取1366个槽)来分配给3号分片,那么数据搬运也就只需要搬运这些移动的槽。因此该算法既解决了大量数据搬运问题又实现了数据均匀分布。
注意1:Redis集群是最多能有16384个分片吗?不能,如果这样,就意味每个分片只存储一个槽,而各个槽中的数据分布不均衡,也就意味着各个分片数据分布不均衡(如果一个分片有多个槽,那么各个分片较大概率大槽和小槽都有,因此平均来讲就比较均衡)。其次,16384个分片就意味至少有16384个master,每个master又有多个slave,至少几万台主机,集群的可用性难以保证。Redis官方建议不超过1000个分片。
注意2:为什么选择16384作为哈希槽个数?哈希槽的编号采用位图表示,就意味16384需要2KB空间才能存储。而节点之间通信使用心跳包机制,其中节点拥有哪些哈希槽是必须要传的数据,KB级的大小引起的网络开销不小(周期性通信)。加上16384对于1000个分片来讲足够分配,因此这个数字是综合考虑位图体积引起的网络开销和分片个数这两个因素得到的较合适的结果。
3 搭建Redis集群
这里搭建3个分片,每个分片包括1主2从,同时额外准备2个节点用于扩容。
3.1 创建目录和配置文件

generate.sh是shell脚本文件,包括了批量的执行命令,用于创建11个Redis节点对应的配置文件,内容如下:
for port in $(seq 1 9); \do \mkdir -p redis${port}/touch redis${port}/redis.confcat << EOF > redis${port}/redis.confport 6379bind 0.0.0.0protected-mode noappendonly yescluster-enabled yescluster-config-file nodes.confcluster-node-timeout 5000cluster-announce-ip 172.30.0.10${port}cluster-announce-port 6379cluster-announce-bus-port 16379EOFdone# 注意 cluster-announce-ip 的值有变化.for port in $(seq 10 11); \do \mkdir -p redis${port}/touch redis${port}/redis.confcat << EOF > redis${port}/redis.confport 6379bind 0.0.0.0protected-mode noappendonly yescluster-enabled yescluster-config-file nodes.confcluster-node-timeout 5000cluster-announce-ip 172.30.0.1${port}cluster-announce-port 6379cluster-announce-bus-port 16379EOFdonebash generate.sh执行该shell脚本:

其中,cluster-enabled表示是否开启集群模式,cluster-config-file由Redis自动生成集群节点的配置文件,cluster-node-timeout表示超时时间,cluster-announce-ip是节点的ip(这里分别是172.30.0.101-172.30.0.111),cluster-announce-port表示节点的业务端口(读写请求都是通过这个端口的),cluster-announce-bus-port表示管理端口(管理操作是通过这个端口进行)。
3.2 配置docker-compose.yml
该文件除了容器的配置外(尤其注意ip和端口号要和shell脚本创建的conf文件配置一致),还需要创建一个网段(内网)172.30.0.0/24,在该网段内的集群节点都可以互相通信。文件内容如下:
version: '3.7'networks:mynet:ipam:config:- subnet: 172.30.0.0/24services:redis1:image: 'redis:5.0.9'container_name: redis1restart: alwaysvolumes:- ./redis1/:/etc/redis/ports:- 6371:6379- 16371:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.101redis2:image: 'redis:5.0.9'container_name: redis2restart: alwaysvolumes:- ./redis2/:/etc/redis/ports:- 6372:6379- 16372:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.102redis3:image: 'redis:5.0.9'container_name: redis3restart: alwaysvolumes:- ./redis3/:/etc/redis/ports:- 6373:6379- 16373:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.103redis4:image: 'redis:5.0.9'container_name: redis4restart: alwaysvolumes:- ./redis4/:/etc/redis/ports:- 6374:6379- 16374:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.104redis5:image: 'redis:5.0.9'container_name: redis5restart: alwaysvolumes:- ./redis5/:/etc/redis/ports:- 6375:6379- 16375:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.105redis6:image: 'redis:5.0.9'container_name: redis6restart: alwaysvolumes:- ./redis6/:/etc/redis/ports:- 6376:6379- 16376:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.106redis7:image: 'redis:5.0.9'container_name: redis7restart: alwaysvolumes:- ./redis7/:/etc/redis/ports:- 6377:6379- 16377:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.107redis8:image: 'redis:5.0.9'container_name: redis8restart: alwaysvolumes:- ./redis8/:/etc/redis/ports:- 6378:6379- 16378:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.108redis9:image: 'redis:5.0.9'container_name: redis9restart: alwaysvolumes:- ./redis9/:/etc/redis/ports:- 6379:6379- 16379:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.109redis10:image: 'redis:5.0.9'container_name: redis10restart: alwaysvolumes:- ./redis10/:/etc/redis/ports:- 6380:6379- 16380:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.110redis11:image: 'redis:5.0.9'container_name: redis11restart: alwaysvolumes:- ./redis11/:/etc/redis/ports:- 6381:6379- 16381:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.1113.3 启动容器并构建集群关系
启动之前,一定确保所有的Redis和docker启动的Redis进程全部都没有,否则可能引起端口冲突。
使用命令redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2来创建集群的结构,--cluster create表示创建集群,后面跟节点ip和端口号(port是容器内的),--cluster-replicas表示每个节点跟几个从节点,2则表示每个节点2个从节点,也就间接说明了该集群有3个分片,每个分片1主2从(主从关系由Redis自动分配):
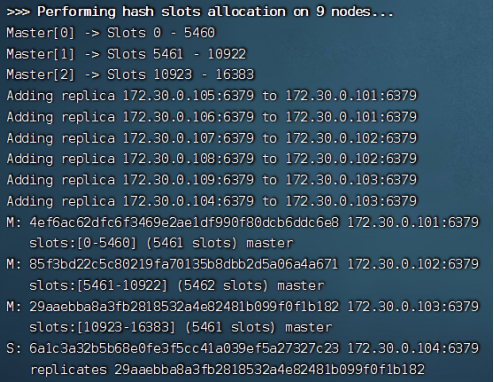
该图是运行结果图,说明了ip主机号为101、102、103的节点是master,而其余节点是slave,三个分片的哈希槽分别有5461、5462、5461个,其余信息也说明了具体的主从关系,不再展示。
3.4 使用集群
命令:redis-cli -h 172.30.0.101 -p 6379 -c
该命令可以连接上指定ip和端口号的节点,连接集群的某一个节点(主从都可以连接和操作)就等于连接整个集群。-h可以指定ip,-p指定端口号,-c选项可以自动把请求重定向到指定分片的节点上(如果不加-c,key计算的哈希槽编号不在当前ip的节点上时,无法进行操作。比如不加-c,当前客户端是101,计算的哈希槽在102,则无法操作)。
注意:cluster nodes可以在客户端内查看集群的情况。
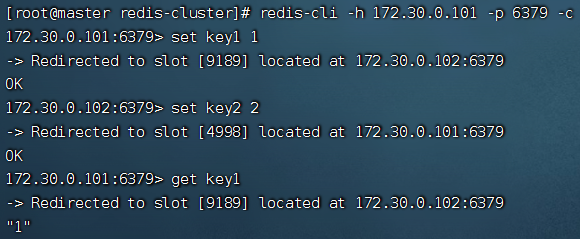
注意:使用集群模式后,一次性操作多个key的命令就很大概率失败了。因为多个key计算后可能分配在不同的分片上,此时操作无法成功。
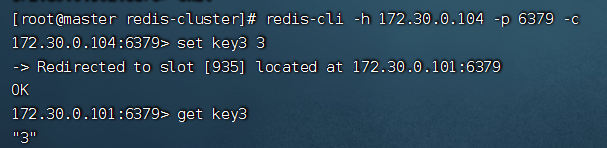
由于分片内也是主从结构,因此从节点也是没有办法进行写操作的。观察上图,当在104节点上进行写操作时,会被重定向到master节点101上。
3.5 主节点故障
当某个分片的master节点出现故障时,就需要选举slave作为新的master来保证系统的可用性。具体的流程如下:
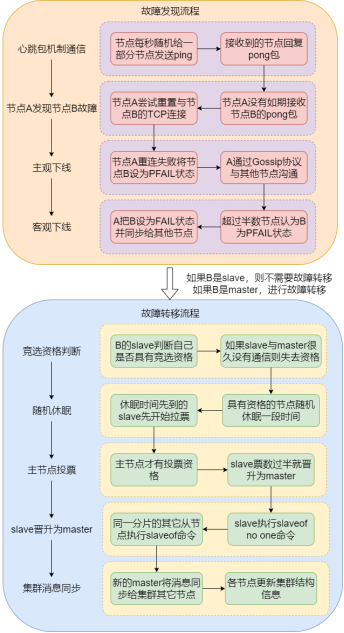
在故障发现过程中,各节点的ping包和pong包都包含着集群的配置信息(节点id。节点所属分片,节点是主还是从,如果是从所属谁,持有哪些slots的位图)。并且在节点每秒钟不是向集群所有的节点都发送ping包,而是随机向一部分没发过的节点发送,这样防止网络上出现大量的心跳包从而造成网络拥塞。
每个节点使用Gossip协议进行某故障节点确认,节点之间交换下线列表(每个节点都会维护的表,记录了其它节点的状态,各节点之间的表可能不一样)信息。
在故障转移过程中,slave如果与master很久没有通信(超过阈值),就说明该slave与原master的数据差异较大,因此不适合做master就没有竞选资格。
注意:随机休眠时间=500ms+[0,500ms]随机时间+排名*1000ms。这里的排名由offset决定,offset越大排名越靠前(值越小),因此休眠时间越短,就较大概率先苏醒(由于还有随机时间,因此不一定100%先苏醒)。为什么要随机休眠?防止某一瞬间多个slave节点(同一分片)都发现master节点故障,几乎同时发起成为新的master的投票,从而使投票局面混乱,影响系统可用性和数据一致性。由了随机休眠时间,各想成为master的节点会有先后顺序苏醒(基本上谁先醒谁较大概率成为master),从而让投票流程更可靠。
出现以下三种情况,就会判定整个集群都宕机:1.某个分片master和slave都故障。2.某个分片只有master没有slave,但是master故障。3.超过半数的master都故障。
3.6 集群扩容
下面演示把节点10(主机号110)和节点11(主机号111)作为第4个分片加入到集群中,其中110作为master:
第一步:命令redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:6379,add-node表示向集群中添加节点,第一个ip是要加入的节点,第二个ip是集群中任意一个节点(因为只要在集群中,每个节点都代表了这个集群)。
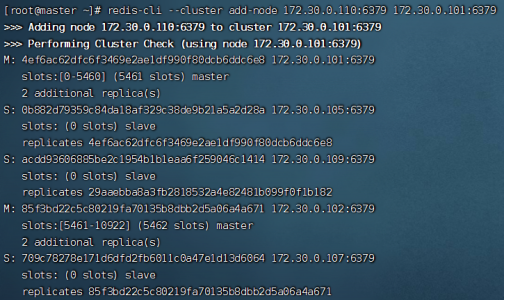
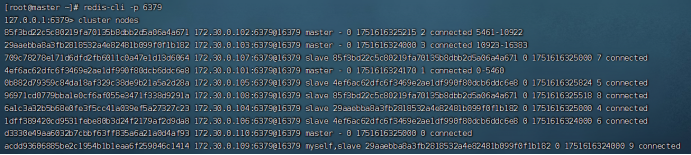
上图可以发现,110这个节点现在已经加入到集群中了,但是还没有分配slots,因此下一步就是为该节点分配slots。
第二步:命令redis-cli --cluster reshard 172.30.0.101:6379进行slots分配,reshard表示重新切分,后面的ip是集群中任意节点。
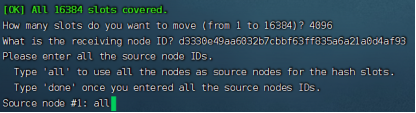
在命令执行过程中,需要确认手动输入三个选项:
How many slots do you want to move (from 1 to 16384)?表示希望移动多少slots,由于是4个分片,每个分片平均4096个slots,因此这里输入4096。
What is the receiving node ID?表示需要哪个节点来接收这些slots,输入节点ID,110节点的ID为d3330e49aa6032b7cbbf63ff835a6a21a0d4af93
Please enter all the source node IDs.表示希望以哪种策略移动:all表示每个分片都平均移动一部分;done表示指定哪几个节点平均移动一部分(先输入ID,再以done为结尾)。
之后会让输入是否确认的预移动方案,输入yes,等待一段时间即可移动完成。
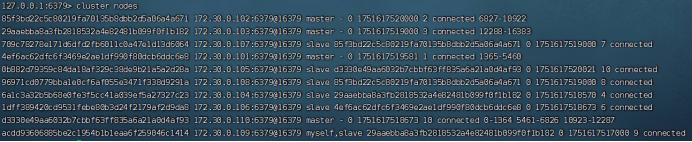
注意:在搬运slots过程中,客户端访问被搬运的部分有可能会出错;而访问其它key正常。待搬运结束后,所有的key的访问恢复正常。
第三步:命令redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id [110节点的ID]进行分片内主从关系的构建,第一个ip表示要把哪个节点加入到集群中,第二个ip表示集群中任意节点,--cluster-slave表示当前节点是slave类型,--cluster-master-id表示该slave从属哪个master。
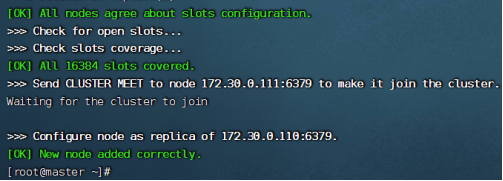
命令执行结束,节点也就成功加入到集群中了。
下篇文章: