如何保证缓存数据的一致性:数据库和缓存数据一致性,本地缓存和Redis缓存怎么保证数据一致性
多级缓存,本地缓存和Redis缓存怎么保证数据一致性?
设置本地缓存短时间内失效
设置本地缓存短时间内失效,短的存活周期,保证了数据的时效性比较高,当数据失效之后,再次访问数据就会拉取新的数据了,这样能尽可能的保证数据的一致性。
它的特点是:代码实现简单,不需要写多余的代码;缺点是,效果不是很明显,不适合高并发的系统。
本地缓存自动更新功能
使用本地缓存框架的自动更新功能,例如 Caffeine 中的 refresh 功能来自动刷新缓存,这样就可以设置很短的时间来更新最新的数据,从而也能尽可能的保证数据的一致性。
| 更新策略 | refreshAfterWrite | expireAfterWrite |
|---|---|---|
| 触发时机 | 访问时延迟刷新 | 到期立即失效 |
| 数据可用性 | 始终有数据(旧或新) | 可能短暂无数据 |
| 性能影响 | 异步无阻塞 | 同步加载可能阻塞 |
refreshAfterWrite执行过过程
写入数据A(time=0s)
→ 5秒后(time=5s)数据仍在缓存中
→ 第6秒访问时触发异步刷新
→ 立即返回旧数据A
→ 后台加载新数据A'
→ 加载完成后替换缓存中的A
refreshAfterWrite的底层实现原理是采用惰性触发+异步加载的机制。具体实现可分为先步骤:
一、时间标记与条件检查
-
写入时间记录
每个缓存项会记录最后一次写入时间戳,作为刷新时间计算的基准。 -
访问时阈值判断
当访问缓存时,比较当前时间与写入时间+refresh间隔:- 若未达到阈值:直接返回现有值
- 若达到阈值:触发异步刷新流程
二、异步刷新控制
-
非阻塞式加载
通过后台线程池(如ForkJoinPool)异步执行刷新任务,避免阻塞用户请求线程。 -
单线程防抖
对同一key的并发刷新请求会合并,确保只有一个加载操作执行(通过细粒度锁或CAS控制)。 -
新旧数据隔离(采用类似
ConcurrentHashMap的分段锁设计)- 刷新过程中继续返回旧数据
- 新数据加载完成后原子性替换
通过配置中心协调和同步
通过微服务中的配置中心(例如 Nacos)来协调,因为所有服务器都会连接到配置中心,所以当数据修改之后,可以修改配置中心的配置,然后配置中心再把配置变更的事件推送给各个服务,各个服务感知到配置中心的配置发生更改之后,再更新自己的本地缓存,这样就实现了本地缓存的数据一致性。
具体的流程描述
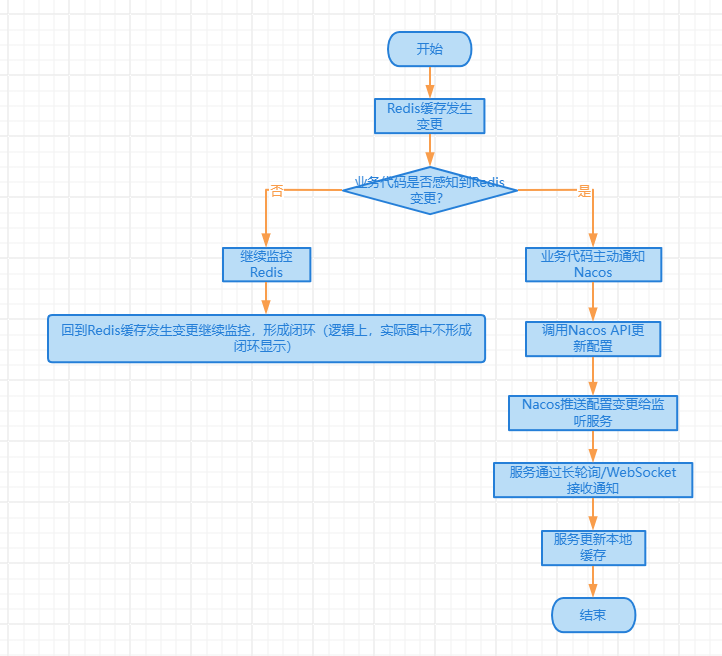
Redis缓存发生变更(比如:某个业务修改了Redis里的数据)
→ 但Nacos本身不会监控Redis的变化,需要业务代码主动通知Nacos。业务代码感知到Redis变更后,主动更新Nacos配置
→ 比如调用Nacos的API,更新一个特定的配置项(例如:cache_version=2)。Nacos将配置变更推送给所有监听的服务
→ 各个微服务通过长轮询(Long Polling)或WebSocket实时接收Nacos的配置变更通知。各服务收到Nacos的通知后,主动更新本地缓存
→ 比如:
- 直接清空本地缓存(下次访问时重新加载)
- 或者调用Redis获取最新数据,更新本地缓存
高频问题
1. Nacos配置监听机制
- 核心问题:如何通过Nacos监听配置变更?
- 回答要点:
- 客户端通过
addListener订阅配置(Data ID + Group) - 采用长轮询(Long Polling)机制,默认30秒超时,配置变更后立即推送
- 监听器
Listener接口实现receiveConfigInfo方法处理变更逻辑
- 客户端通过
- 回答要点:
2. 数据一致性保障
- 核心问题:如何保证Redis与本地缓存的数据一致性?
- 回答要点:
- 版本号设计:通过Nacos配置中的版本号(如时间戳)标记变更
- 最终一致性:依赖Nacos的AP模式(Distro协议)实现异步同步
- 本地缓存更新策略:清空缓存或主动拉取最新数据
- 回答要点:
3. 多级缓存协同
- 核心问题:Redis、Nacos、本地缓存如何协同工作?
- 回答要点:
- Redis变更 → 业务代码主动更新Nacos版本号
- Nacos推送变更 → 服务更新本地缓存(如Caffeine)
- 降级策略:本地缓存未命中时回源Redis
- 回答要点:
4. 性能与可靠性
- 核心问题:如何避免频繁更新导致的性能问题?
- 回答要点:
- 批量更新:合并短时间内的多次变更,减少推送频率
- 本地缓存过期时间:设置合理的TTL(如30分钟)
- 容错机制:Nacos集群故障时降级为读取本地缓存
- 回答要点:
5. 对比其他方案
- 核心问题:与直接监听Redis的Pub/Sub有何区别?
- 回答要点:
- Nacos优势:解耦业务逻辑,支持配置版本管理
- Pub/Sub劣势:需维护Redis连接,无历史版本回溯能力
- 回答要点:
分布式缓存与数据库如何保证一致性
四大同步策略
| 策略顺序 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 先更新缓存再更新数据库 | 缓存命中率高 | 第二步失败导致缓存脏数据 | 不推荐使用 |
| 先更新数据库再更新缓存 | 相对安全 | 第二步失败导致缓存旧数据 | 低并发场景 |
| 先删除缓存再更新数据库 | 操作简单 | 缓存击穿风险,数据不一致 | 不推荐使用 |
| 先更新数据库再删除缓存(推荐) | 影响最小 | 删除失败导致旧数据 | 大多数场景 |
延时双删
针对上面这种情况,我们有一种延时双删的方法
1)删除缓存
2)更新数据库
3)休眠 500ms(这个时间,依据读取数据的耗时而定)
4)再次删除缓存
这时候唯一存在的一个问题就是,在(更新据库 + 休眠 500 ms) 这个时间窗口中,依旧能读取到旧值,而这个短暂时间控制的好的话,是可以接受的。
基于消息队列的异步同步(如Canal+MQ)
- 工作原理
- 通过监听数据库的binlog(如MySQL的ROW模式),使用Canal捕获增删改事件并推送至消息队列(Kafka/RocketMQ)。
- 消费者服务订阅消息,根据事件类型删除或更新缓存,实现最终一致性