Java并发编程——并发容器
文章目录
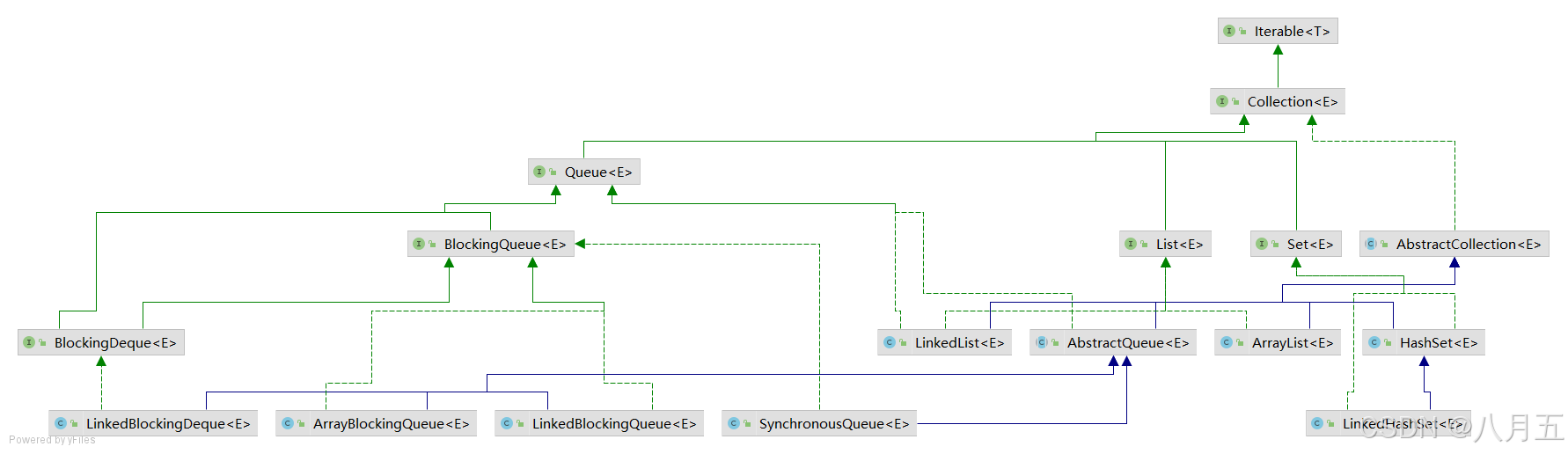
- 一、JDK 提供的并发容器总结
- 二、ConcurrentHashMap
- 三、CopyOnWriteArrayList
- 3.1 简介
- 3.2 CopyOnWriteArrayList 是如何做到的?
- 3.3 CopyOnWriteArrayList 读取和写入源码简单分析
- 3.3.1 读取操作的实现
- 3.3.2 写入操作的实现
- 四、ConcurrentLinkedQueue
- 五、BlockingQueue
- 5.1 简介
- 5.2 ArrayBlockingQueue
- 5.3 LinkedBlockingQueue
- 5.4 PriorityBlockingQueue
- 六、ConcurrentSkipListMap
- 6.1 跳表的基本概念:
- 6.2 跳表查找过程:
- 6.3 跳表与平衡树的对比:
- 6.4 并发环境下的优势:
- 6.5 ConcurrentSkipListMap:
一、JDK 提供的并发容器总结
JDK 提供了一系列用于并发编程的容器,主要位于 java.util.concurrent 包中
- ConcurrentHashMap: 线程安全的
HashMap - CopyOnWriteArrayList: 线程安全的
List,在读多写少的场合性能非常好,远远好于Vector. - ConcurrentLinkedQueue: 高效的并发队列,使用链表实现。可以看做一个线程安全的
LinkedList,这是一个非阻塞队列。 - BlockingQueue: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
- ConcurrentSkipListMap: 跳表的实现。这是一个
Map,使用跳表的数据结构进行快速查找。
二、ConcurrentHashMap
ConcurrentHashMap 是一个线程安全的 HashMap,在多线程环境下提供了高效的性能。传统的 HashMap 在并发环境下不安全,因此我们通常会使用 Collections.synchronizedMap() 来保证线程安全,但这种方式会通过全局锁来同步访问,导致性能瓶颈。
ConcurrentHashMap 采用了 锁分段技术,它将 HashMap 划分为多个段(segment),每个段内部独立加锁,这样在多个线程同时访问不同段的数据时,不会相互干扰,从而减少了锁的粒度,提高了并发性能。
- 读操作: 读操作几乎不需要加锁,因此读性能非常高。
- 写操作: 写操作时,只有对应的段会加锁,这避免了全局锁的性能瓶颈,使得并发写操作能够有效进行。
这种设计使得
ConcurrentHashMap在并发环境下非常适合用于大量并发读写的场景。
三、CopyOnWriteArrayList
3.1 简介
public class CopyOnWriteArrayList<E>
extends Object
implements List<E>, RandomAccess, Cloneable, Serializable
CopyOnWriteArrayList 是一个线程安全的 List 实现,它实现了 List<E> 接口,同时也支持 RandomAccess、Cloneable 和 Serializable 等接口。它的设计思想主要是为了解决多线程场景中,读操作远大于写操作时,如何避免因加锁导致性能浪费的问题。
在并发场景中,如果采用传统的加锁方式来保证线程安全,读操作就需要加锁,这会导致性能降低。CopyOnWriteArrayList 采用了 写时复制(Copy-on-Write) 策略,来避免对原有数据的修改,从而提升读操作的性能。
具体来说,读操作是完全不加锁的,多个线程可以并发读取
List的内容,这使得读取操作非常高效。而写操作也不会阻塞其他的读操作,因为它不会直接修改原有数据,而是通过创建数据的新副本来实现。
与 ReentrantReadWriteLock 的读写锁机制(读读共享、写写互斥、读写互斥、写读互斥)不同,CopyOnWriteArrayList 采用的是一种写操作与写操作之间同步的方式,并且读操作不会受到任何同步的影响。这样一来,读操作的性能就会大幅度提升。那它是怎么做的呢?
3.2 CopyOnWriteArrayList 是如何做到的?
CopyOnWriteArrayList 的实现通过写时复制(Copy-on-Write)机制,确保了每次写入操作不会直接修改原始数据。具体来说,它的可变操作(如 add、set 等)都是通过创建底层数组的新副本来实现的。
- 当需要修改
List时,CopyOnWriteArrayList不会直接在原数组上进行修改,而是复制原数组,进行修改,并用新的副本替换掉原数组。 - 这种方式确保了读操作在任何时候都能读取到一个完整的数据副本,从而避免了并发读写时的数据不一致问题。
简单来说,
CopyOnWrite的思想就是在内存修改时,首先复制一份原内存块,修改新的内存块,修改完成后再将指针指向新内存块,原内存块可以被垃圾回收。
3.3 CopyOnWriteArrayList 读取和写入源码简单分析
3.3.1 读取操作的实现
读取操作没有任何同步控制和锁操作,理由就是内部数组 array 不会发生修改,只会被另外一个 array 替换,因此可以保证数据安全。
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
public E get(int index) {
return get(getArray(), index);
}
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}
final Object[] getArray() {
return array;
}
- 读取操作通过
getArray()方法获取底层的数组,并直接返回指定索引的元素。getArray()方法返回的是array数组,array变量是volatile的,保证了多个线程能够看到最新的数组副本。- 由于读取时不会改变数组的内容,因此不需要加锁,多个线程可以并发执行读取操作。
3.3.2 写入操作的实现
CopyOnWriteArrayList 的写入操作(例如 add)会进行加锁,以确保线程安全。每次写操作,都会复制一个新的数组,将修改后的数据写入新的副本,并用新的副本替换旧的数组。
以 add 方法为例:
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 加锁,确保写操作的线程安全
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); // 复制一个新的数组
newElements[len] = e; // 将新元素添加到新数组的末尾
setArray(newElements); // 用新数组替换原数组
return true;
} finally {
lock.unlock(); // 释放锁
}
}
add方法首先获取一个ReentrantLock,然后加锁,确保只有一个线程可以进行写操作。- 获取当前底层数组
elements,然后通过Arrays.copyOf创建一个新的数组 newElements,并将新元素添加到该数组的末尾。- 最后,通过 setArray(newElements) 替换掉原来的数组。
- 在整个过程中,只有写操作和写操作之间会加锁,避免了多个写操作同时复制新数组的情况。
四、ConcurrentLinkedQueue
Java 提供的线程安全的 Queue 可以分为两类:
- 阻塞队列(如 BlockingQueue):通过加锁来实现线程安全。
- 非阻塞队列(如 ConcurrentLinkedQueue):通过 CAS(比较并交换)操作实现线程安全。
从名字可以看出,ConcurrentLinkedQueue 使用链表作为其数据结构。它在高并发环境中表现优异,被认为是性能最好的队列之一,其优异性能得益于内部复杂的实现。
ConcurrentLinkedQueue 主要依靠 CAS 非阻塞算法来实现线程安全。关于其内部代码细节,此处不做深入分析,只需了解其核心思想即可。
应用场景:
- 适用于对性能要求较高的场景,尤其是在队列的读写需要由多个线程同时进行时。
- 当对队列加锁的成本较高时,采用无锁的
ConcurrentLinkedQueue更为合适。
五、BlockingQueue
5.1 简介
BlockingQueue 是一种线程安全的阻塞队列,阻塞队列广泛应用于“生产者-消费者”问题。它提供了可阻塞的插入和移除操作,具体表现如下:
- 当队列已满时,生产者线程会被阻塞,直到队列有空间。
- 当队列为空时,消费者线程会被阻塞,直到队列非空。
BlockingQueue 是一个接口,继承自 Queue,因此其实现类也可以作为 Queue 的实现来使用,而 Queue 又继承自 Collection 接口。常见的 BlockingQueue 实现类包括:ArrayBlockingQueue、LinkedBlockingQueue 和 PriorityBlockingQueue。
下面主要介绍一下:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,这三个 BlockingQueue 的实现类。
5.2 ArrayBlockingQueue
ArrayBlockingQueue 是一个有界队列,底层采用数组实现,一旦创建,容量不可改变。其并发控制使用可重入锁,所有的插入和读取操作都需要获取锁。具体行为:
- 当队列已满时,插入操作会被阻塞。
- 当队列为空时,取出操作会被阻塞。
ArrayBlockingQueue 默认不保证线程访问的公平性,即不按照线程等待的顺序进行访问。如果保证公平性,通常会降低吞吐量。如果需要保证公平性,可以通过如下方式创建公平的队列:
private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<>(10, true);
5.3 LinkedBlockingQueue
LinkedBlockingQueue 是基于单向链表实现的阻塞队列,既可以作为有界队列使用,也可以作为无界队列使用。与 ArrayBlockingQueue 相比,LinkedBlockingQueue 提供了更高的吞吐量。为了防止内存浪费,通常会在创建时指定队列的大小,若未指定,容量默认为 Integer.MAX_VALUE。
构造方法:
/**
*某种意义上的无界队列
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
/**
*有界队列
* Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity.
*
* @param capacity the capacity of this queue
* @throws IllegalArgumentException if {@code capacity} is not greater
* than zero
*/
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
5.4 PriorityBlockingQueue
PriorityBlockingQueue 是一个支持优先级的无界阻塞队列。元素按照自然顺序排序,或者可以通过自定义 compareTo() 方法或使用构造函数中的 Comparator 来指定排序规则。
- 它的并发控制采用
ReentrantLock,是一个无界队列(与ArrayBlockingQueue和LinkedBlockingQueue不同,后两者可以指定最大容量)。 PriorityBlockingQueue不允许插入null值,且队列中的元素必须是可比较的(实现了Comparable接口),否则会抛出ClassCastException异常。- 该队列的插入操作
put不会被阻塞(因为它是无界队列),但取出操作take在队列为空时会阻塞。
总结:
PriorityBlockingQueue是PriorityQueue的线程安全版本,适用于需要根据优先级排序的场景。
六、ConcurrentSkipListMap
6.1 跳表的基本概念:
为了引出 ConcurrentSkipListMap,先带着大家简单理解一下跳表。
- 跳表(Skip List)是一种高效的数据结构,用于支持快速的查找、插入和删除操作。它的查找效率是 O(log n),相比单链表的 O(n),效率大大提高。
- 跳表的核心思想是使用多个层级的链表(索引层),每一层链表都维护着一个子集,从而加速查找过程。最高层的链表包含的元素最少,最低层包含所有的元素。
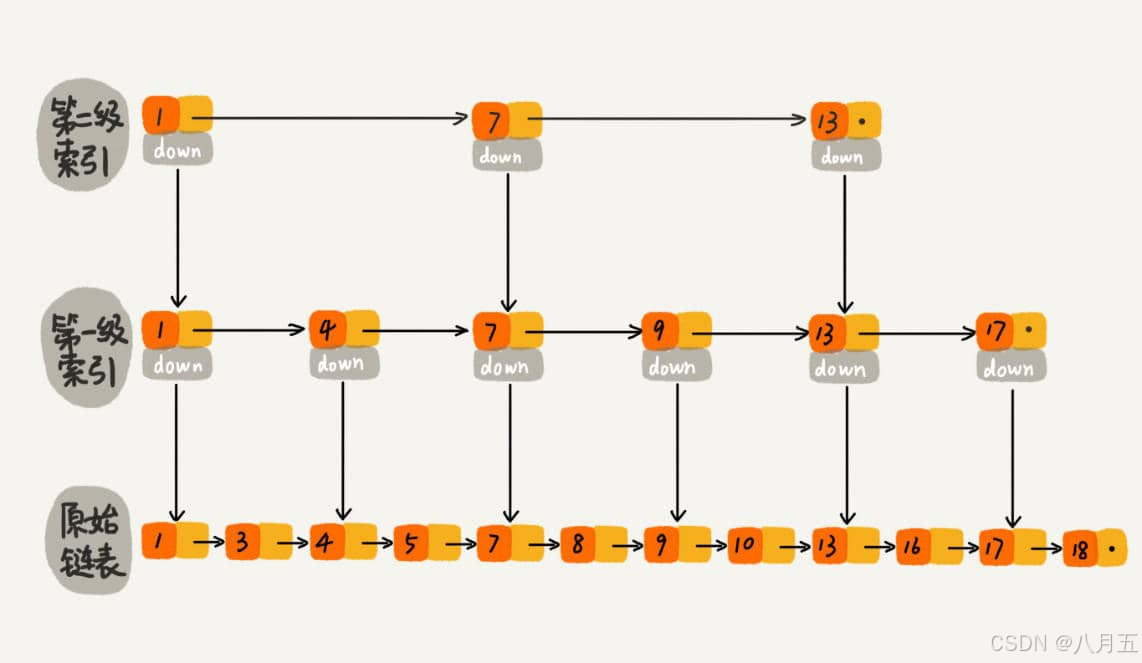
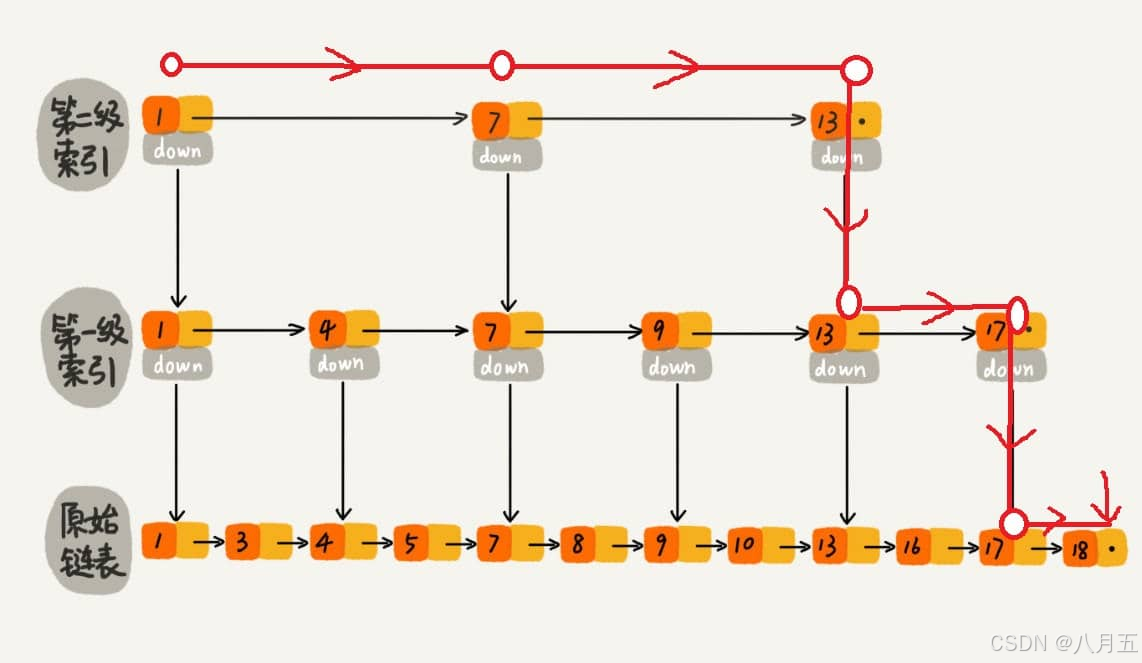
6.2 跳表查找过程:
在查找一个元素时,首先从跳表的顶层开始,如果当前层的元素比目标元素小,则跳到下一层继续查找。这种“跳跃式”的查找能够显著减少遍历的次数。
如上图所示,在跳表中查找元素 18。
6.3 跳表与平衡树的对比:
- 跳表与平衡树类似,都能够提供快速的查找操作,但它们的操作方式有所不同。
- 平衡树 在进行插入或删除时,可能需要全局的调整来保持平衡。而 跳表 的插入和删除操作只会影响局部结构,因此在高并发的情况下,跳表比平衡树更加高效,因为跳表只需要部分锁而不是全局锁。
6.4 并发环境下的优势:
- 在高并发环境下,跳表 比传统的 平衡树 更具优势。跳表可以采用 部分锁 来保证线程安全,避免了对整个数据结构的全局锁定,从而提高了性能。
- 由于跳表中元素是有序的,可以方便地进行遍历,这与 哈希表(如 HashMap)的无序性不同。如果应用场景中需要保持元素的顺序,跳表提供了很好的解决方案。
6.5 ConcurrentSkipListMap:
ConcurrentSkipListMap 是 JDK 中实现跳表的类,它实现了 Map 接口,并且支持并发操作。
它不仅提供了排序功能,而且能够保证线程安全,适用于多线程环境中的数据存储和操作。
