动态库加载(可执行程序和地址空间)
首先,不论是可执行程序还是动静态库,本质都是磁盘上的文件。
其次,不管是加载还是运行,第一步都是要先找到文件,所以在运行可执行程序时,前面需要加 ./ ,加载库时,都需要路径来帮助编译器/程序找到那个库。
动态库使用的整体轮廓: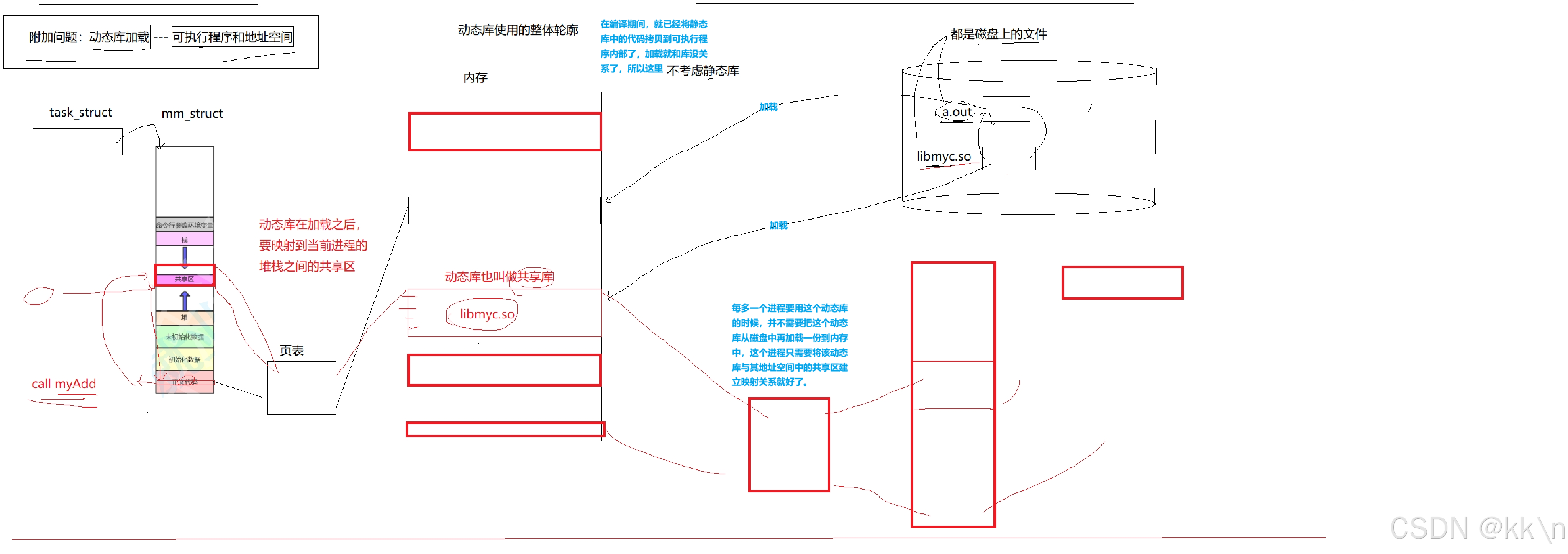
动态库在加载之后,要映射到当前进程地址空间上的堆栈之间的共享区。
每多一个进程要用这个动态库的时候,并不需要把这个动态库从磁盘中再加载一份到内存中,这个进程只需要将该动态库与其地址空间中的共享区建立映射关系就好了。
补充:动态库也叫做共享库。
我们的可执行程序,编译成功后,没有加载运行时,它的二进制代码中,也是包含了“地址”的。-- 可用 objdump -S 可执行程序名 命令查看该可执行程序的汇编代码。
补充:我们用语言(C、C++...)编写的程序,它的源代码中的 变量名、函数名 ,在它被翻译成二进制的代码之后,这些 变量名、函数名 就都不在了,变成了“地址”。
补充:我们一般在 Linux 当中形成的可执行程序,它的格式叫做:ELF格式的可执行程序。
二进制是有自己的固定格式的,它一定要有它对应的elf可执行程序的头部,头部有着很多可执行程序的属性。
可执行程序编译之后,会变成很多行的汇编语句,每条汇编语句都有它的地址。
问题:程序未加载时,这些地址是什么地址?编译器又是如何对这些汇编语句进行编址的?
答:首先,编址一定要有编址范围,目前认为我们的编址范围就是:000...000 ~ fff...fff。以 000...000 ~ fff...fff 进行按顺序编址的方式叫做绝对编址。(注:如果是用偏移量的方式编的址,这种方式叫做相对编址)。把一个可执行程序进行绝对编址的做法,称之为叫做:平坦模式。严格意义上讲,一个可执行程序,在没有被加载的时候,它里面的地址,我们称之为逻辑地址。(注:在平坦模式中,逻辑地址 = 虚拟地址 )
补充:ELF + 加载器 可以让OS找到一个可执行程序 各个区域的起始和结束地址 和 main函数的入口地址。
问题:mm_struct(地址空间) 是一个结构体对象,它里面的各种成员变量(一个个地址用来维护各个区域)的初始值是哪来的呢?
答:首先,因为每个可执行程序的源代码部分肯定是不一样的,可能还会差很多(比如一个就 5 行,一个却有 50万 行),所以这个初始值肯定不是 OS 进行分配的。这些信息(代码有多少,有多大...)只有可执行程序本身知道,所以通过读取可执行程序的头部,来获取这些信息,去初始化这个结构体。
补充:虚拟地址空间这个概念,不是 OS 独有的,它还需要有 编译器支持、加载器支持。
当代码被加载到内存里时,每行代码不仅有自己的虚拟地址,还需要有自己实际的物理地址。
注:页表就存放着 虚拟地址 和 物理地址 之间的映射关系。
cpu 中有一个寄存器叫做:pc指针,它会保存当前正在执行指令的下一条指令的地址(虚拟地址)。pc 指向哪里,cpu 就去执行哪里的代码。
注:cpu 从 pc 指针中拿到虚拟地址之后,然后就去页表中查该虚拟地址对应的物理地址,然后再根据物理地址去内存中执行相应的代码。
可执行程序的加载: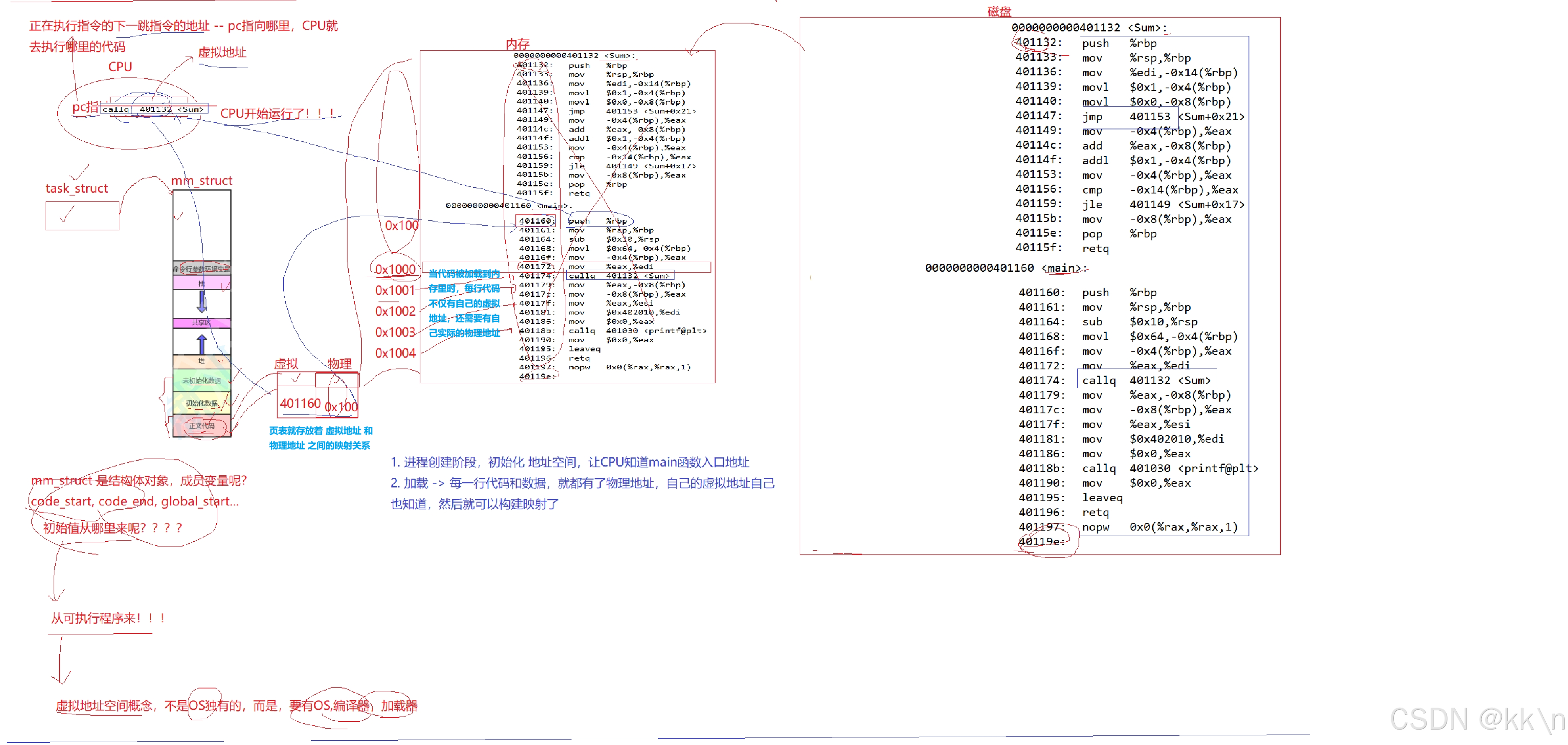
进程创建阶段,初始化地址空间,让 cpu 知道 main函数 的入口地址。
库被映射到虚拟地址空间的什么位置,根本不重要,因为主要是靠偏移量来找到那些方法的。
注:知道起始地址和偏移量就够了。
补充:库函数调用,其实也是在进程自己的地址空间内来回跳转。
问题:怎么知道一个库有没有被加载呢?
答:一个可执行程序可能需要使用多个库,多个可执行程序可能需要使用更多的库,这些库被加载到内存里之后,也是需要被管理起来的。所以,先描述,再组织!!!OS 为了管理这些库,肯定也是弄了一个结构体用来描述这些库的信息,哪些是被加载了,哪些是没被加载的,它的物理和虚拟的映射关系...所以,OS 可以让进程知道,一个库到底有没有被加载到内存里了。
注:库也要被 先描述,再组织!!! 被 OS 管理。
总结:要运行一个可执行程序时,先把这个可执行程序加载到内存里,运行代码,当发现要用到某个动态库里的方法时,再去加载那个方法所在的动态库。
注:上面的一大堆操作和静态库都没有关系。因为静态库的内容早已都拷贝到了可执行程序内部了。