中国2771个县级行政区的月度CO₂排放数据(2013–2021)
中国2771个县级行政区的月度CO₂排放数据(2013–2021)

传统自上而下(Top-down)的县级CO₂排放估算方法过度依赖单一夜间灯光总亮度作为工具变量,默认省内所有区域CO₂排放与灯光亮度呈正相关,忽略了区域异质性(如产业结构升级、减排技术应用导致的碳排放与经济增长脱钩现象)。
现有县级排放数据集存在时空分辨率不足(如时间跨度短、非月度数据)或校准方法缺陷(如夜间灯光数据连续性校正导致“持续增长偏差”)。
本研究提供中国2771个县级行政区的月度CO₂排放数据(2013–2021),为县级“双碳”战略实施提供高精度基础数据。方法可推广至全球其他地区,支持精细化减排政策制定。
核心创新点
数据资源:中国2771个县级行政区的月度CO₂排放数据(2013–2021)
多源特征变量构建
整合改进的夜间灯光数据(NPP/VIIRS)、城乡人居环境数据(7类分区:城市中心、密集城区等)及社会经济指标(产业结构、绿色技术专利、碳交易政策等37项变量),突破单一变量局限。
混合回归模型(DNN+CatBoost)
特征筛选:通过皮尔逊相关性、统计检验、自编码器特征选择等多方法筛选关键变量(最终选用前20个重要变量)。
模型优势:
深度神经网络(DNN):提取特征间非线性关系。
CatBoost算法:高效处理分类变量,避免传统方法因引入大量虚拟变量导致的过拟合。
性能对比:测试集拟合优度(R²=0.99)、均方根误差(RMSE=0.06)显著优于传统方法(如Chen et al.的RMSE=0.13)。
夜间灯光数据精细化校准
传统缺陷:整体区域校正导致“灯光持续增长”偏差,无法反映衰退区域。
改进方案:基于7类城乡分区分别校正,仅对缺失月份使用前值插补,避免全局连续性假设。
验证:校准后灯光数据与城市GDP半年度统计数据显著正相关(R²≈0.80)。
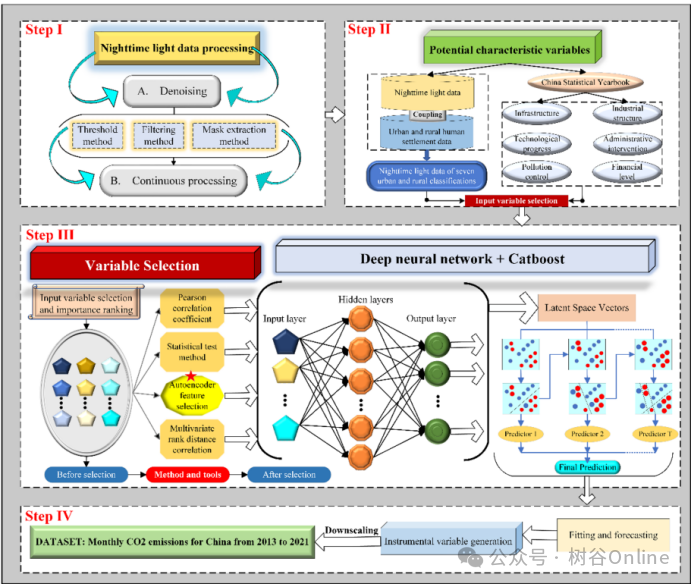
数据生成方法
工具变量构建流程
步骤1:省级CO₂排放数据(CEADS)与多维特征变量(灯光、社会经济指标)训练混合回归模型。
步骤2:模型输出县级“潜在排放预测值”作为新工具变量,其与省级排放相关性优于夜间灯光总亮度。
步骤3:以新工具变量为权重,通过自上而下算法分配省级排放至县级。
不确定性控制
模型误差通过RMSE量化(0.06),避免宏观统计数据与微观数据聚合偏差。
数据验证与对比
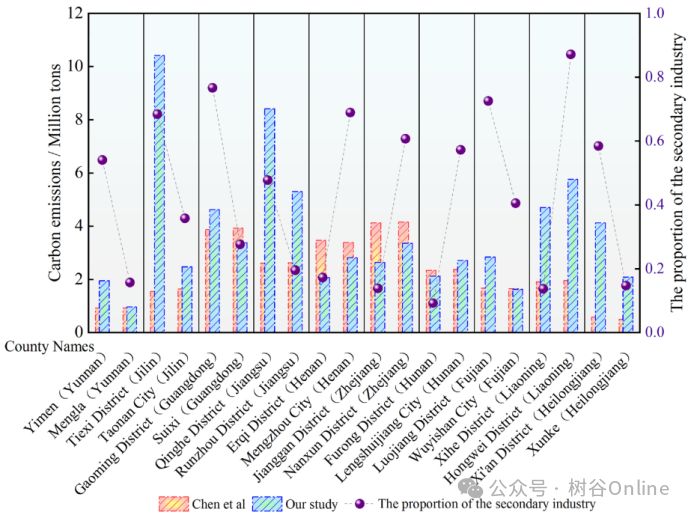
与传统方法对比
Chen et al.的数据库在相似CO₂排放水平的县中,出现产业结构比例矛盾(如工业占比差异显著但排放估值相近),而本研究结果符合经济逻辑(见图6)。
时空分布特征
排放呈现东高西低、核心城市集聚模式(见图3–4),且月度波动反映季节性经济活跃度变化。

局限性与应用
当前局限
社会经济变量仅覆盖城市级,未体现市内县级异质性。
依赖省级能源消耗数据自上而下分配,可能引入微观误差。
使用建议
适用场景:县级减排目标分解、政策效果评估、区域碳排放动态监测。
总结
本研究通过多源数据融合、混合机器学习模型及城乡分区的灯光校准方法,构建了中国首个高时空分辨率的县级月度CO₂排放数据库,解决了传统方法的系统性偏差,为精细化碳管理提供科学支撑。
数据信息
本研究共获取了中国2771个县级行政区2013–2021年的月度二氧化碳排放数据记录。数据单位为百万吨,数据格式xlsx,共计299269条数据。
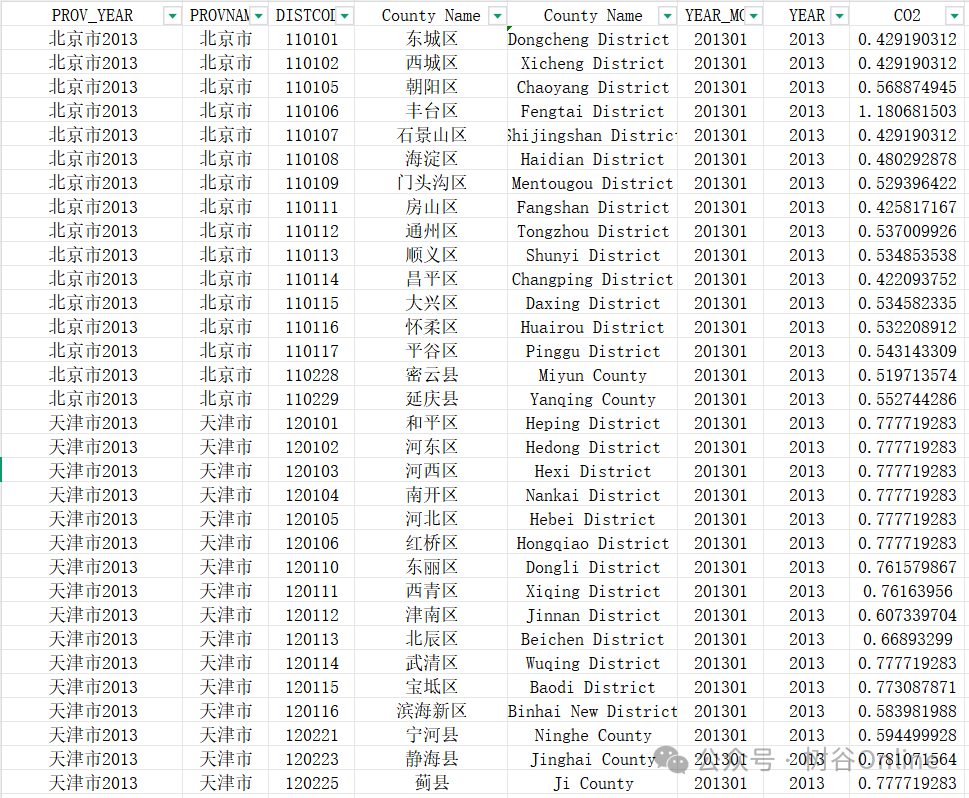
此外,我们还提供了数据计算过程的全部文件与代码。具体包括:
-
文件"country_x_20241118_02.xlsx":收录了37项社会经济特征指标,用于反映潜在影响因素;
-
文件"typeC20_catmodel_1109_3p01joint_scaler.pkl":包含特征变量标准化处理的代码;
-
文件"country_pred.py"和"country_pred.pdf":提供县级工具变量预测的代码实现;
-
文件"pre_model_weights.h5":存储预测模型的权重参数,这些参数用于计算输入数据的线性变换和非线性激活函数,包含模型中所有可训练参数(如各层神经元间的连接强度及各层神经元的偏置项);
-
文件"typeC20_catmodel_1108_3p01joint.cbm":定义预测模型的结构,包括数据流向、层级连接方式等架构信息(如网络层类型、神经元数量及激活函数等)。

数据格式:xlsx
数据容量:131MB(压缩包内含数据来源、引用方法)