Dify:在MacOS系统下Dify的本地部署与使用
目录
一、Dify介绍
Dify的功能
为什么使用Dify?
Dify与LangChain的区别
Dify与Coze的区别
二、Dify的本地部署
安装Dify依赖环境
三、Dify的使用
1、模型配置
2、知识库
四、Dify的实战
简单的聊天模式
总结
一、Dify介绍
Dify 一词源自 Define + Modify,意指定义并且持续的改进你的 AI 应用,它是为你而做的(Do it for you)
Dify 是一个专注于 AI 应用开发的平台,旨在帮助开发者快速构建、部署和管理基于大语言模型(LLM)的应用程序。其核心功能涵盖从开发到运维的全流程,大幅降低了 AI 应用的开发门槛。
官方地址: Dify.AI · 生成式 AI 应用创新引擎
官方文档地址:产品简介 - Dify Docs

Dify的功能
关于Dify的核心功能其实就一个:那就是创建智能体,但是有5种模式:

看起来很厉害的样子,但其实最常用就是Chatflow
为什么使用Dify?
你或许可以把 LangChain 这类的开发库(Library)想象为有着锤子、钉子的工具箱。与之相比,Dify 提供了更接近生产需要的完整方案,Dify 好比是一套脚手架,并且经过了精良的工程设计和软件测试。
重要的是,Dify 是开源的,它由一个专业的全职团队和社区共同打造。你可以基于任何模型自部署类似 Assistants API 和 GPTs 的能力,在灵活和安全的基础上,同时保持对数据的完全控制
Dify与LangChain的区别
Dify的特点
- 低代码/无代码:通过界面拖拽即可构建AI应用(如客服机器人、内容生成工具),无需深入编程。
- 内置功能:直接集成模型管理、数据标注、API发布等,适合非技术或全栈开发者。
- 快速上线:从设计到部署可能只需几小时,适合中小企业和个人开发者
LangChain的特点
- 高灵活性:通过Python/JavaScript代码连接LLM、数据库、工具链,适合定制化需求(如自主Agent、复杂工作流)。
- 模块化设计:提供链(Chains)、代理(Agents)等组件,开发者需自行组装和优化。
- 技术门槛高:需熟悉编程和LLM技术栈,适合工程师或研究团队
适用场景对比
- 选择Dify:需要快速搭建一个功能明确的AI应用(如智能写作助手),且希望减少运维和开发成本。
- 选择LangChain:需要深度控制模型行为(如结合私有数据构建问答系统),或开发实验性AI功能(如多模型协作)
Dify vs LangChain
- Dify:适合快速生产级部署,降低工程复杂度。
- LangChain:适合深度定制(如多模型协作),需较高技术门槛
Dify与Coze的区别
顺带提一下Coze,Coze也是目前市场上主流的Agent开发工具,Coze更注重开箱即用的体验,适合快速部署轻量级Agent
Coze官方地址:扣子
Dify和Coze均为AI应用开发平台,但定位和功能侧重点不同:
-
目标用户:
Dify面向开发者及企业,提供全流程的AI应用开发工具,支持复杂业务场景的定制化需求。
Coze更侧重无代码/低代码用户,适合快速构建聊天机器人等轻量级应用。 -
技术栈:
Dify支持多模型集成(如GPT、Claude、开源模型),提供API、工作流和数据集管理。
Coze深度集成字节跳动生态(如豆包),模型选择相对有限,但内置丰富插件和知识库功能。 -
部署与控制:
Dify支持私有化部署,企业可完全掌控数据和模型;Coze主要为云托管服务,灵活性较低。
Dify vs Coze
- Coze:侧重开箱即用,适合轻量级 Agent。
- Dify:提供更灵活的自主控制与数据管理。
二、Dify的本地部署
安装Dify依赖环境
确保Mac OS系统已安装Python 3.8或更高版本。可通过终端输入python3 --version检查版本。推荐使用Homebrew安装Python:
brew install pythonMac系统安装Docker Desktop或者OrbStack,用于容器化部署,个人使用的OrbStack
Docker Desktop安装地址:Docker Desktop: The #1 Containerization Tool for Developers | Docker
OrbStack安装地址:Download OrbStack · Fast, light, simple Docker Desktop alternative
修改OrbStack的Docker镜像地址:
vim /etc/docker/daemon.json 添加如下配置
{"registry-mirrors" : ["https://docker.registry.cyou","https://docker-cf.registry.cyou","https://dockercf.jsdelivr.fyi","https://docker.jsdelivr.fyi","https://dockertest.jsdelivr.fyi","https://mirror.aliyuncs.com","https://dockerproxy.com","https://mirror.baidubce.com","https://docker.m.daocloud.io","https://docker.nju.edu.cn","https://docker.mirrors.sjtug.sjtu.edu.cn","https://docker.mirrors.ustc.edu.cn","https://mirror.iscas.ac.cn","https://docker.rainbond.cc","https://do.nark.eu.org","https://dc.j8.work","https://dockerproxy.com","https://gst6rzl9.mirror.aliyuncs.com","https://registry.docker-cn.com","http://hub-mirror.c.163.com","http://mirrors.ustc.edu.cn/","https://mirrors.tuna.tsinghua.edu.cn/","http://mirrors.sohu.com/"],"insecure-registries" : ["registry.docker-cn.com","docker.mirrors.ustc.edu.cn"],"debug": true,"experimental": false
}然后重启OrbStack后,使用docker info,如果出现 Registry Mirrors,则镜像配置成功
Client:Version: 27.5.1Context: orbstackDebug Mode: false……Registry Mirrors:https://docker.registry.cyou/https://docker-cf.registry.cyou/https://dockercf.jsdelivr.fyi/https://docker.jsdelivr.fyi/https://dockertest.jsdelivr.fyi/……进入到Dify源码的docker目录中,我们需要先把 .env.example 修改为 .env
mv .env.example .env在当前目录执行
docker-compose up -d
下载完毕后,访问:http://localhost/install
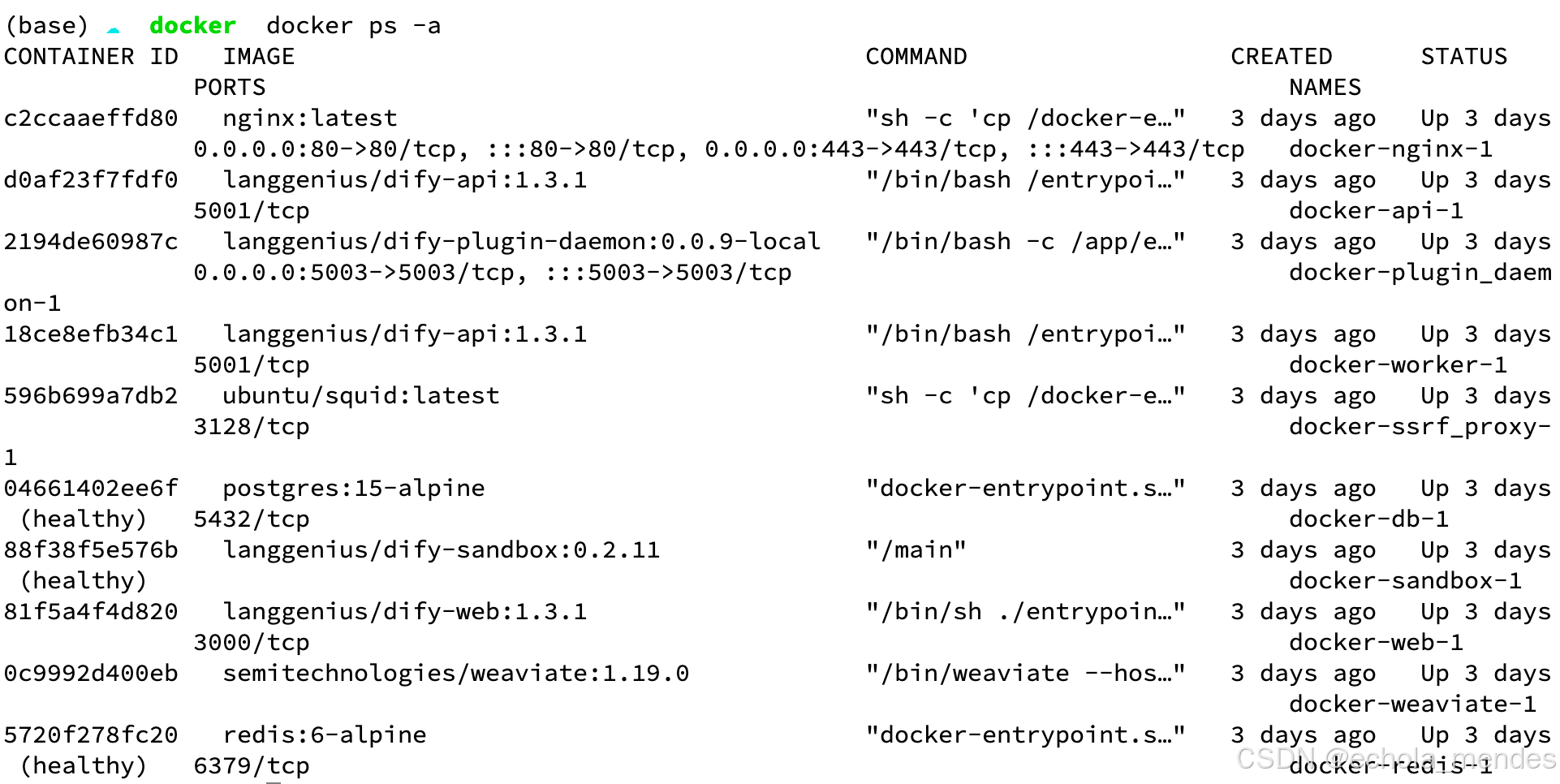
使用docker ps -a,查看启动的进程
⚠️注意:Dify升级时,要备份Docker目录下volumes文件夹,因为Dify上的所有数据存储在此。升级后还原备份的volumes即可
三、Dify的使用
注册完账号,进入Dify主页后,配置下模型厂商
1、模型配置
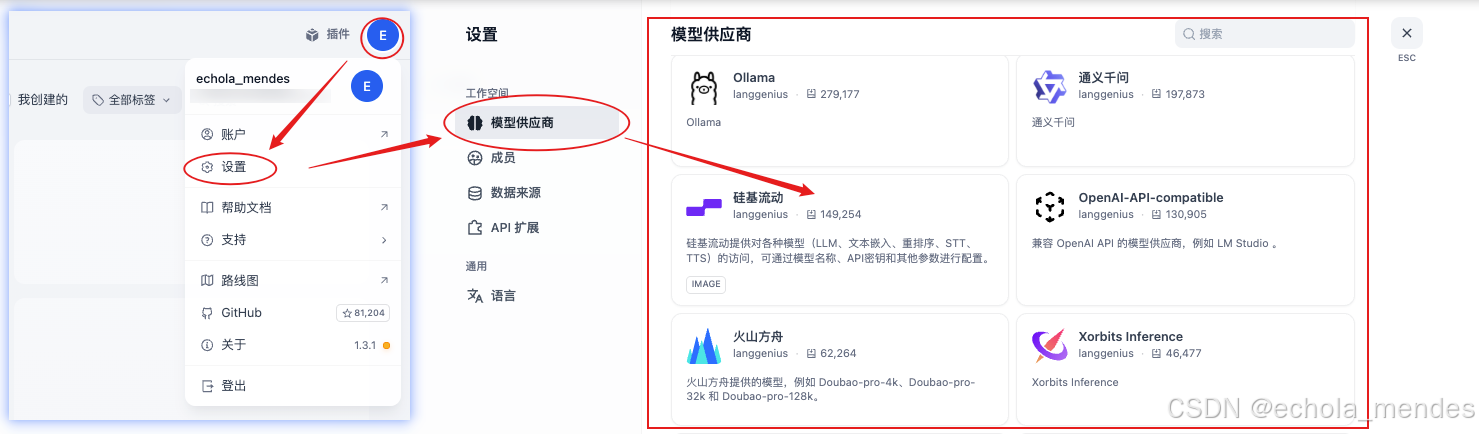
在Dify主页选择账号头像,选择【设置】-【模型供应商】,即可添加Dify中使用的模型,并【安装】
Dify默认支持基本上所有主流的模型厂商,添加时只需要提供对应的模型的 API Key ,可以选择熟悉的模型厂商,例如:百度的文心一言、阿里的通义千问,本地的Ollama即可,可以去对应的网站获取API Key
因为众多API Key都是收费的,此处还是选择硅基流动的模型,是有免费2000 万 Tokens额度
硅基流动地址:硅基流动统一登录
进入硅基流动,选择 DeepSeek R1 模型
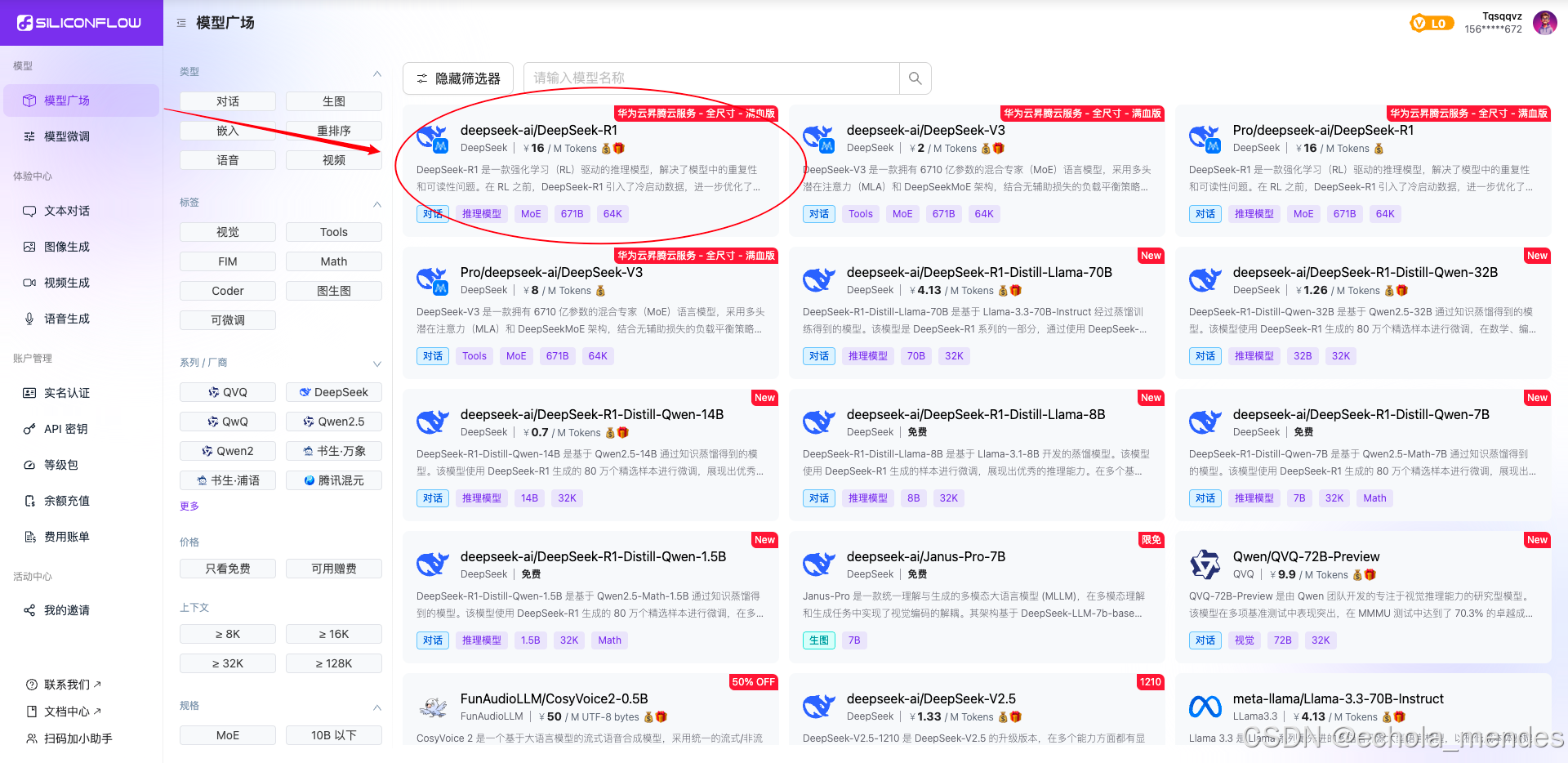
点击“在线体验”后,选择API密钥,选择“新建API密钥”,则可生成硅基流动的API Key
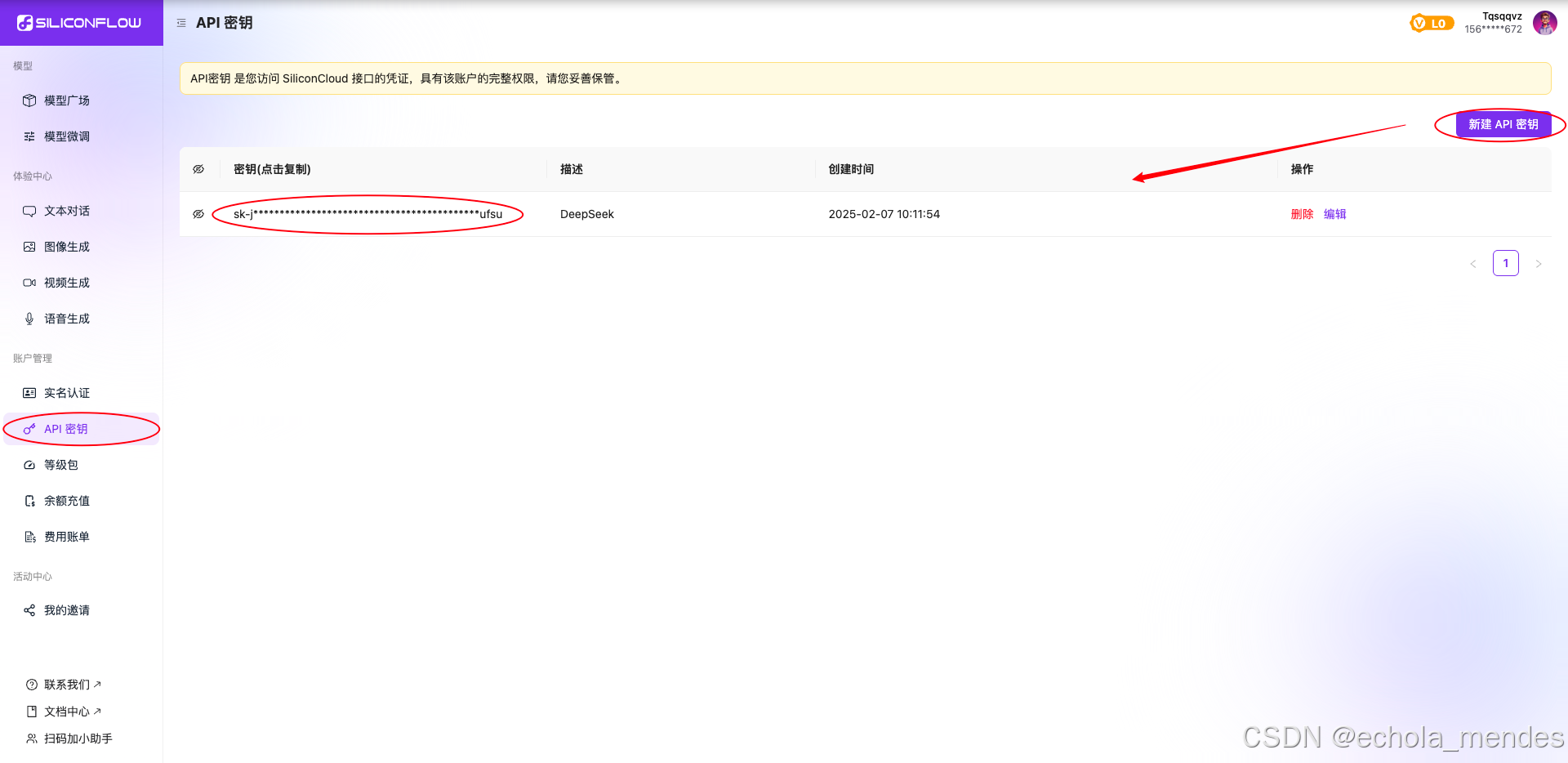
安装【硅基流动】
 安装成功后,刷新当前页面,点击【设置】,将上面硅基流动中的API Key添加到配置中
安装成功后,刷新当前页面,点击【设置】,将上面硅基流动中的API Key添加到配置中
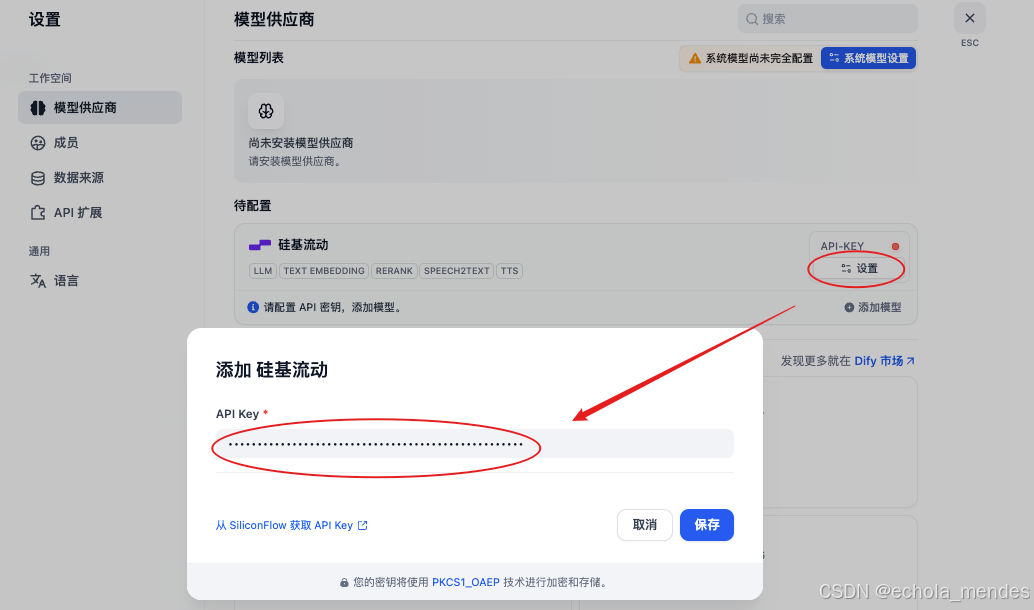
点击【系统模型设置】,根据个人需求选择对应的模型
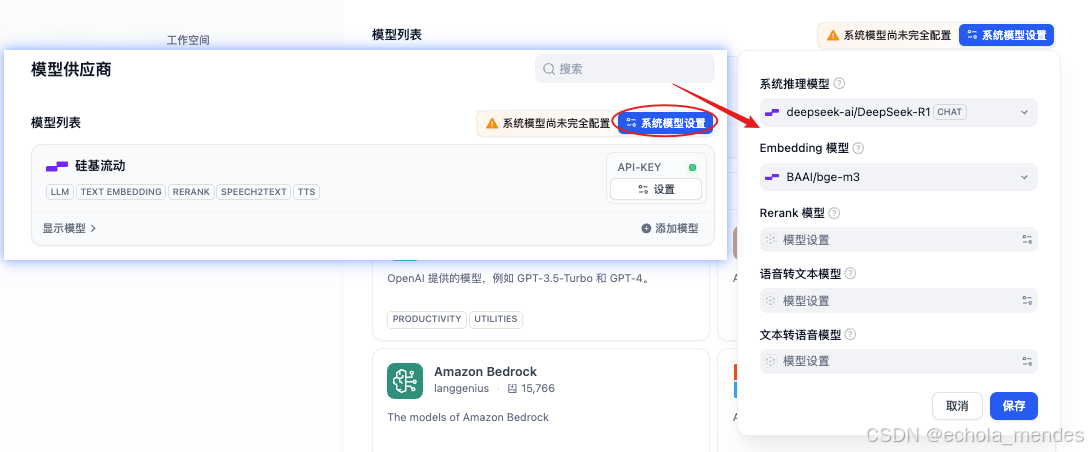
2、知识库
选择【知识库】,默认支持2种方式:
①创建本地知识库:如果是简单场景,可以直接在Dify中创建知识库,后续直接引用,但功能有限
②连接外部知识库:复杂场景推荐这种方式,企业中一般外接RAGFlow知识库
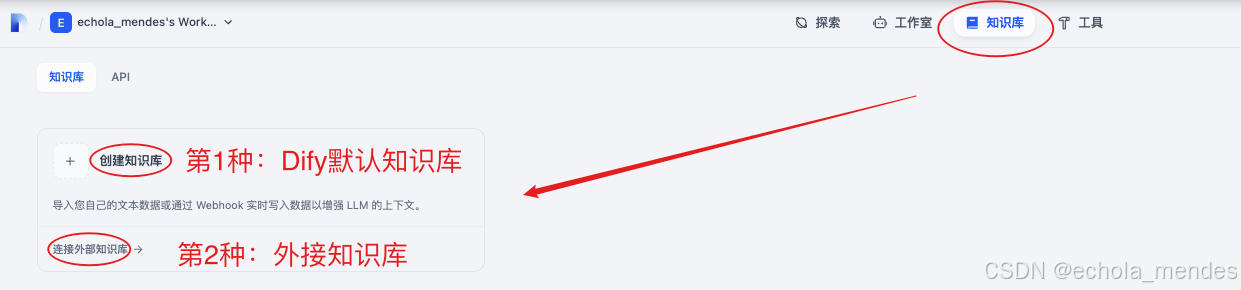
此处暂时使用本地知识库,点击【创建知识库】,选择文件上传
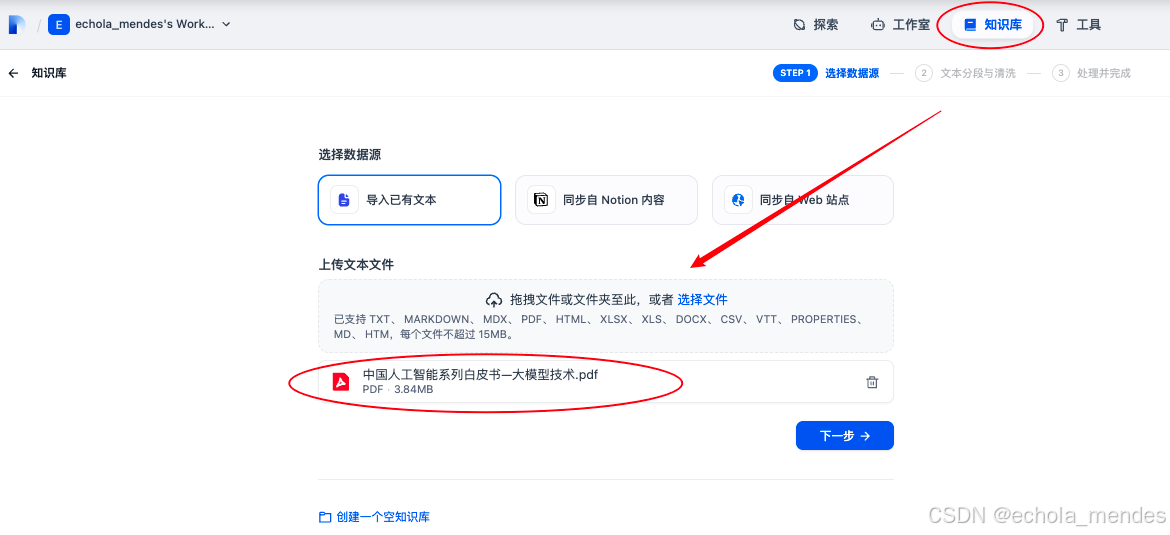
点击【下一步】进入文本分段与清洗,可以全部默认设置后进行【保存并处理】,就可以直接进入智能体的创建,不再需要进行详细配置
如果有RAG基础,可以看看以下配置,
先大概复习一下RAG原理:
RAG就是将文档切分后,通过嵌入模型转换为高位向量,导入向量数据库,然后将用户的输入信息,也转换为向量,再在向量数据库中匹配最相似的向量,最后由大模型总结检索到的内容,以此响应用户
配置分为三个部分:分段设置(文本切分)、索引方式、检索方式
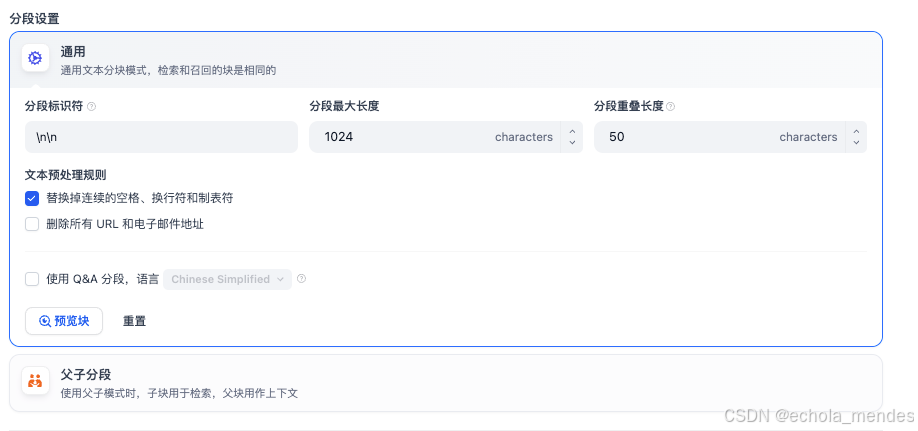
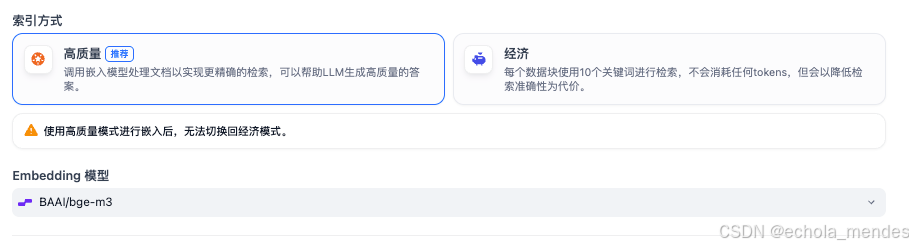
知识库检索就是从向量数据库中进行检索,此处选择【混合检索】检索出来的结果会更加准确
三种检索方式:
向量检索:通过生成查询嵌入并查询与其向量表示最相似的文本分段
全文检索:索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段
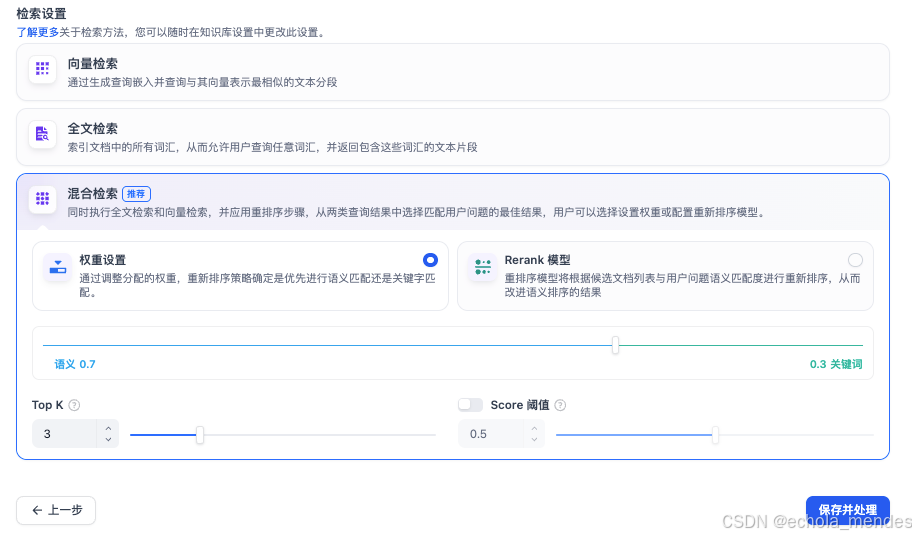
混合检索:同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,用户可以选择设置权重或配置重新排序模型
其中混合检索中可以选择【权重设置】或【Rerank】模型
权重设置:通过调整语义和关键字的比例来对内容进行检索
Rerank模型:可以根据候选候选列表与用户问题语义匹配度进行重新排序,从而改进语义排序的结果,简而言之就是从检索结果中,把更符合问题的那些chunk片段排在最前面展示出来
配置完成后点击【保存并处理】,开始文档向量化, 可以看到已经嵌入完成
点击【前往文档】,点击上传的文档,可以发现文档已经Chunk分段成功,知识库就创建成功了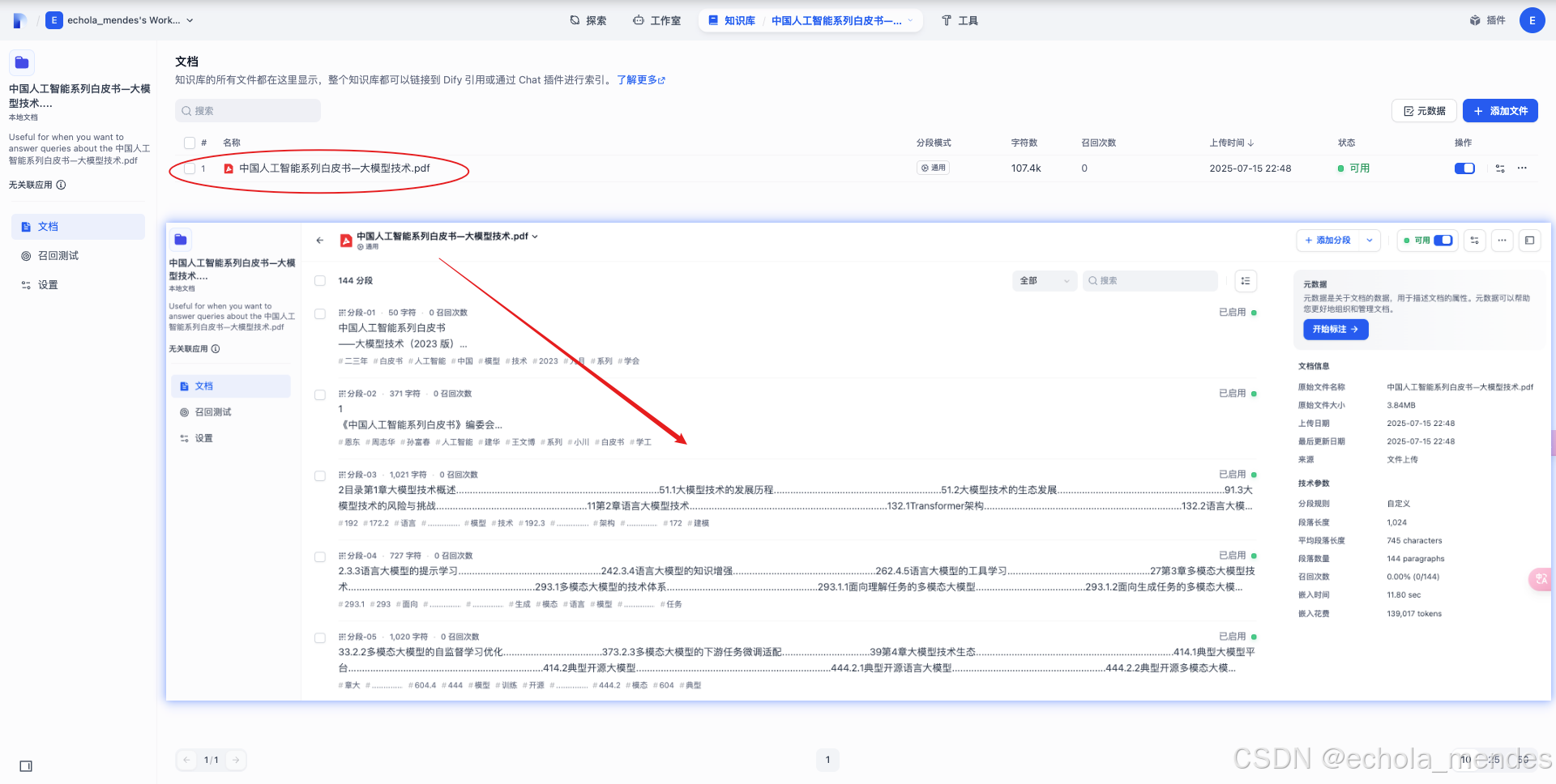
知识库默认只有创建人可见,如果设置团队人员可见范围,需要去【设置】修改知识库权限
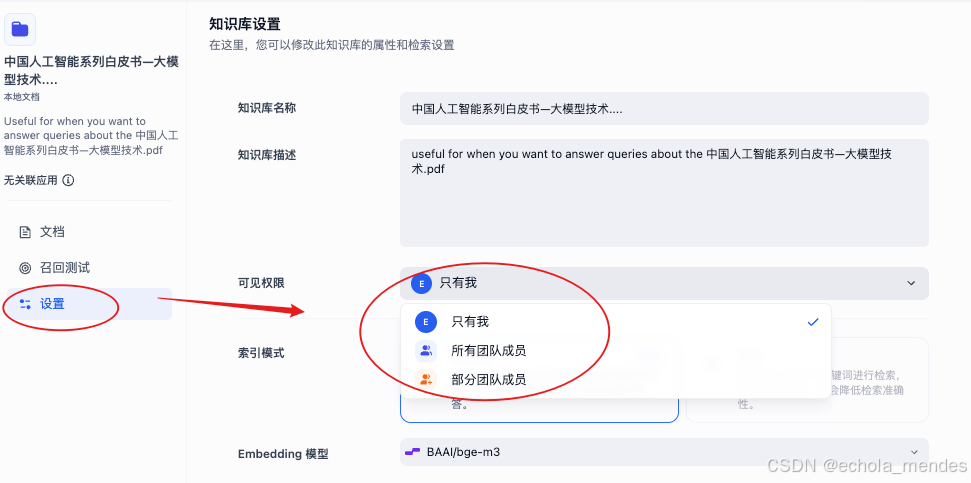
下面就可以进入智能体的创建部分,先从简单的聊天模式的智能体
四、Dify的实战
简单的聊天模式
可以创建【聊天助手】的智能体,也可以根据Dify提供的应用模版创建聊天智能体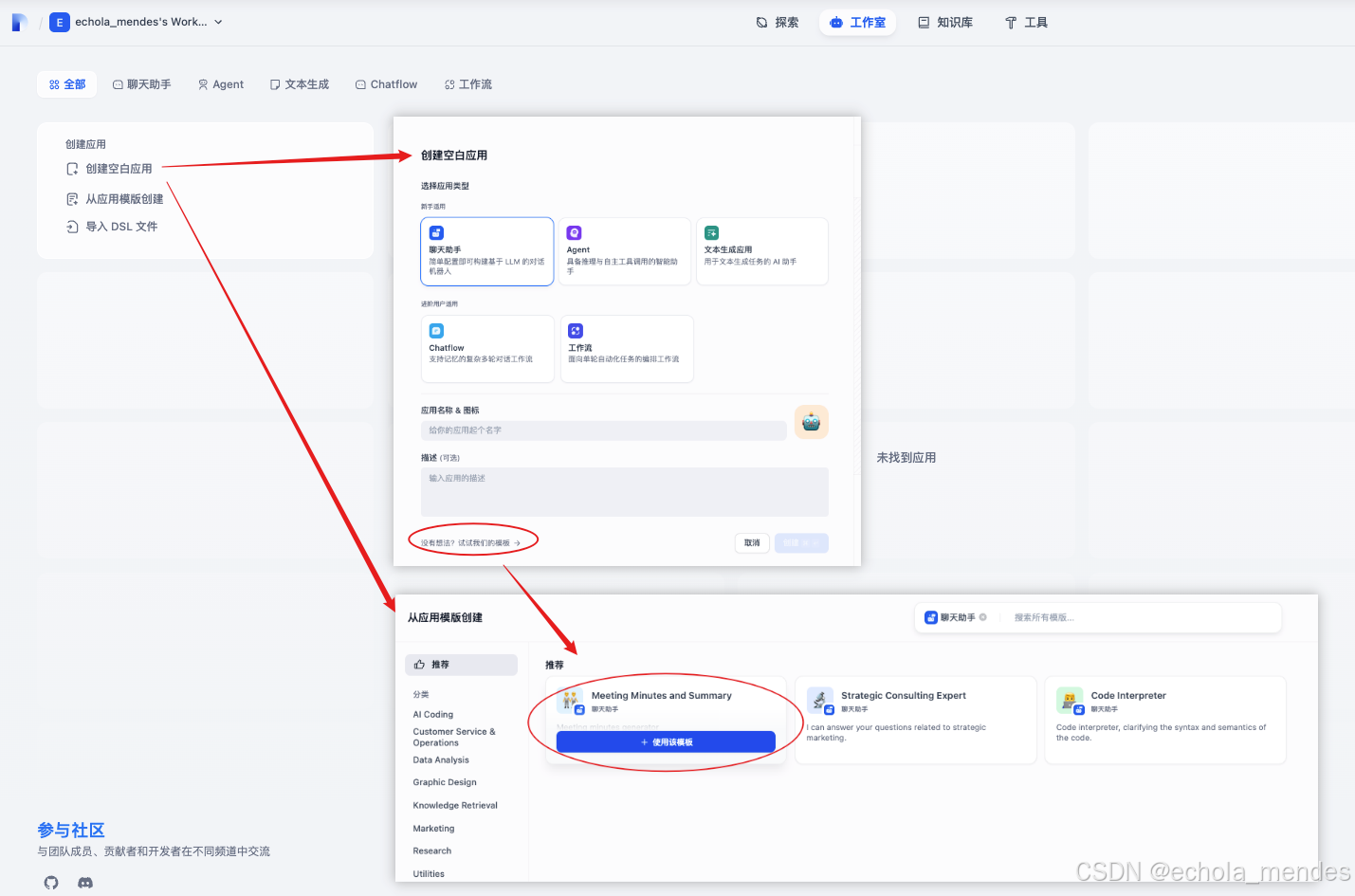
此处选择智能体:【会议纪要】添加到工作区,切换右上角的模型就可以使用了,点击【发布】选择【发布更新】进行保存
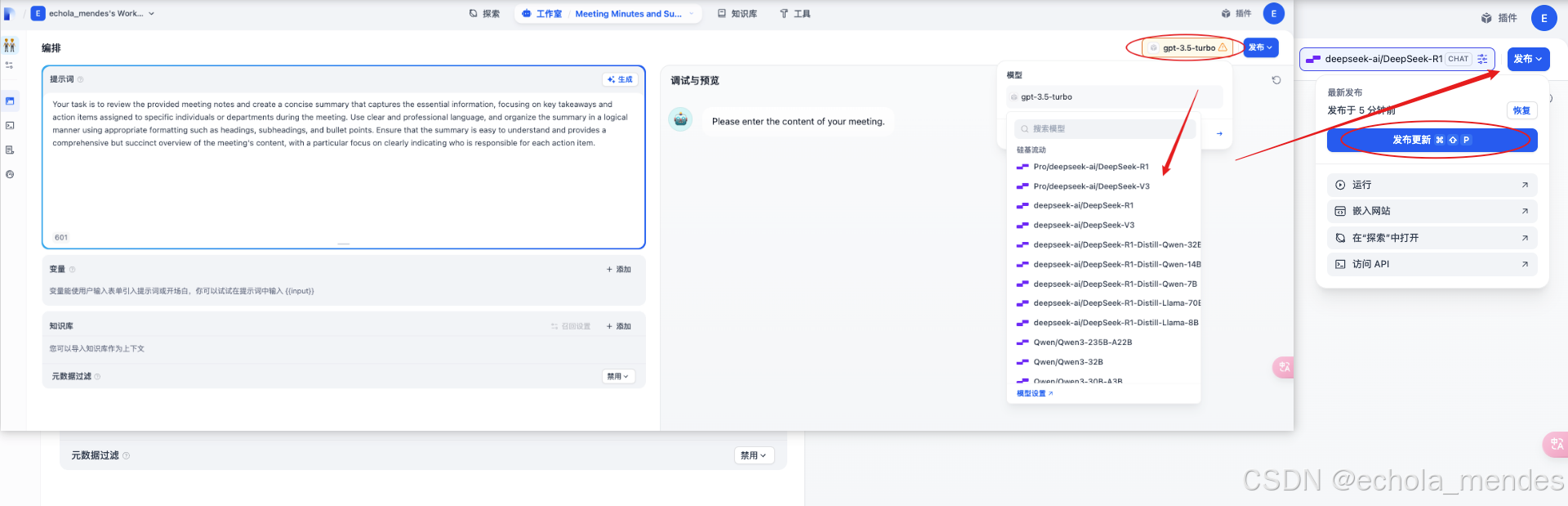
现在就测试一下,点击【运行】就进入到了使用页面,输入会议内容,可以看到会议纪要的聊天智能体已经整理出了会议纪要,第一个智能体完结撒花🎉……
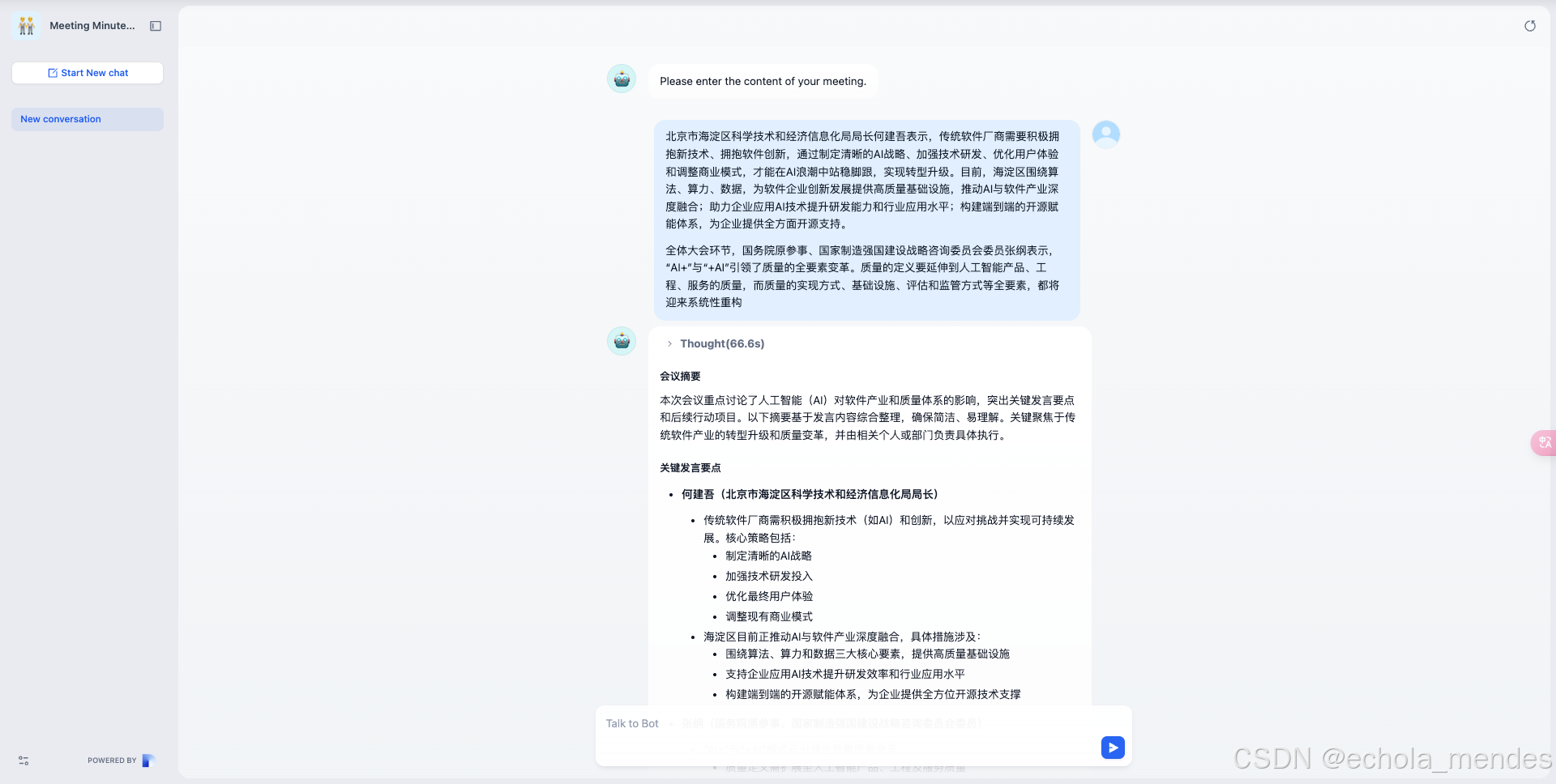
总结
Dify 通过模块化设计和低代码交互,显著缩短了 AI 应用从开发到上线的周期。其核心优势在于平衡了灵活性与易用性,尤其适合中小团队或个人开发者实现垂直场景的 AI 解决方案